
R:員工離職預測實戰
一、背景介紹
為什麼我們最好和最有經驗的員工過早離職?資料來自Kaggle中的,想並嘗試預測下一個什麼樣的有價值的員工將離開。通過分析資料,瞭解影響員工辭職的因素有哪些,以及最主要的原因,預測哪些優秀員工會離職。
變數說明:
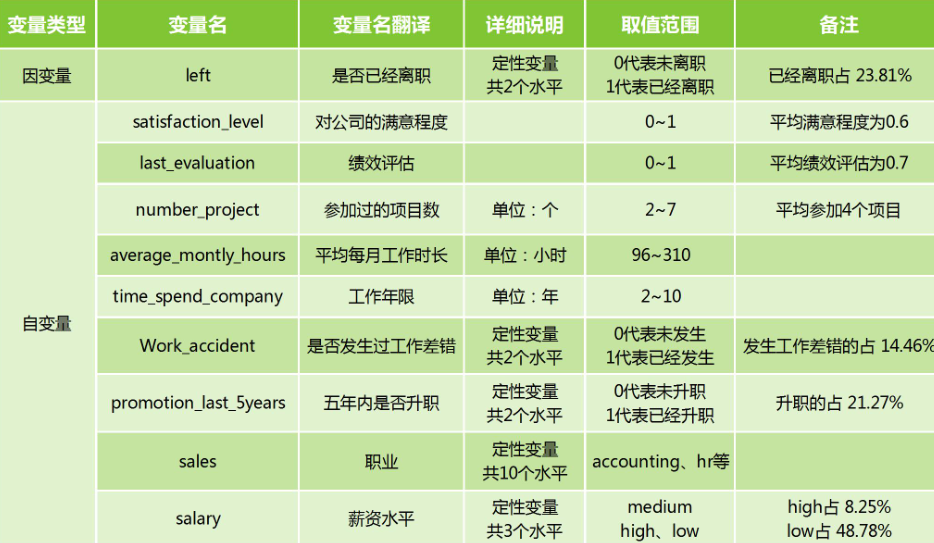
<textarea readonly="readonly" name="code" class="python"> ################### ============== 載入包 =================== ################# #檢視當前的工作目錄好匯入資料檔案 getwd() #設定工作目錄為需要匯入的資料檔案所在目錄 setwd("C:\\Users\\Administrator\\Desktop\\員工離職預測") library(plyr) # Rmisc的關聯包,若同時需要載入dplyr包,必須先載入plyr包 library(dplyr) # filter() library(ggplot2) # ggplot() library(DT) # datatable() 建立互動式資料表 library(caret) # createDataPartition() 分層抽樣函式 library(rpart) # rpart() library(e1071) # naiveBayes() 樸素貝葉斯 library(pROC) # roc() ROC曲線 library(Rmisc) # multiplot() 分割繪圖區域 ################### ============= 匯入資料 ================== ################# hr <- read.csv("HR_comma_sep.csv") #檢視資料檔案的前6行 data <- head(hr) </textarea>
二、描述性分析
- 觀察各個變數的主要描述統計量
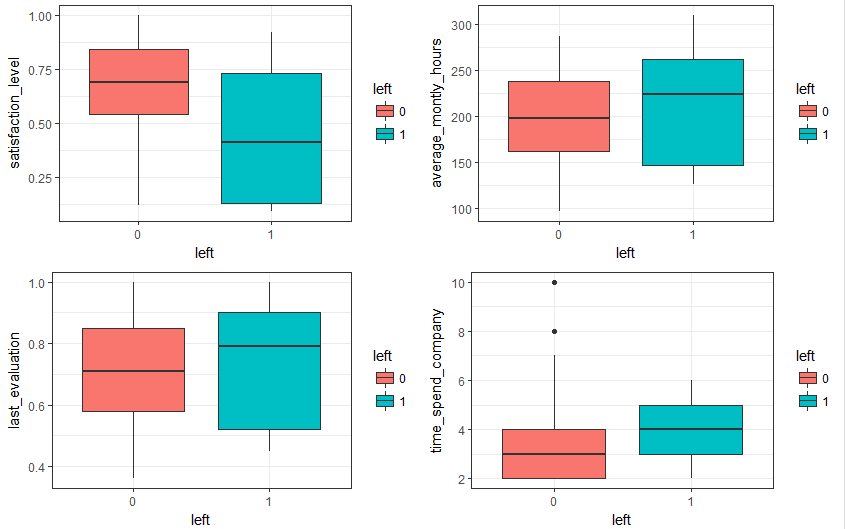
- 探索員工對公司滿意度、績效評估、月均工作時長和工作年限與離職的關係
- 探索參與專案個數、五年內有沒有升職和薪資與離職的關係
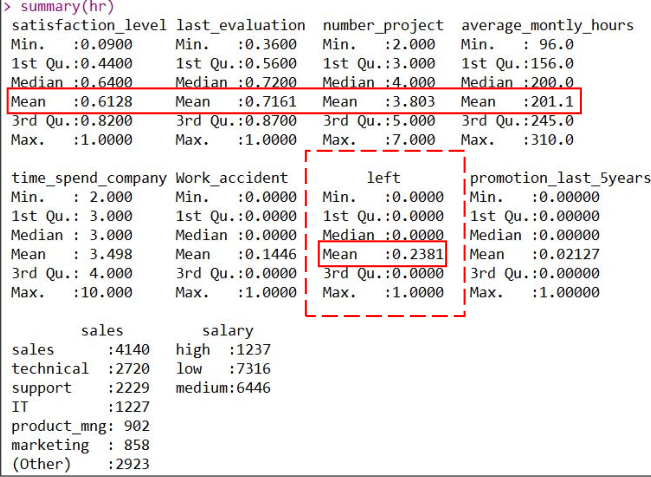

<textarea readonly="readonly" name="code" class="python"> ################### ============= 描述性分析 ================== ############### # 檢視資料的基本資料結構 str(hr) # 計算資料的主要描述統計量 summary(hr) # 後續的個別模型需要目標變數必須為因子型,我們將hr中left的型別由int轉換為因子型 hr$left <- factor(hr$left, levels = c('0', '1')) ##-----探索員工對公司滿意度、績效評估和月均工作時長與是否離職的關係----######## # 繪製對公司滿意度與是否離職的箱線圖 box_sat <- ggplot(hr, aes(x = left, y = satisfaction_level, fill = left)) + geom_boxplot() + theme_bw() + # 一種ggplot的主題 labs(x = 'left', y = 'satisfaction_level') # 設定橫縱座標標籤 box_sat </textarea>
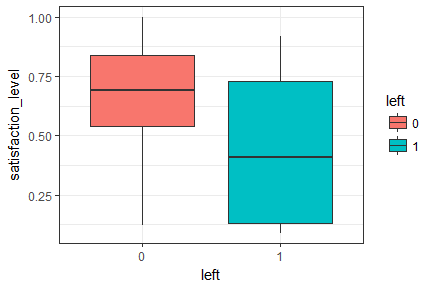
員工對公司的滿意度與員工是否離職的箱線圖
<textarea readonly="readonly" name="code" class="python"> # 繪製績效評估與是否離職的箱線圖 box_eva <- ggplot(hr, aes(x = left, y = last_evaluation, fill = left)) + geom_boxplot() + theme_bw() + labs(x = 'left', y = 'last_evaluation') box_eva </textarea>
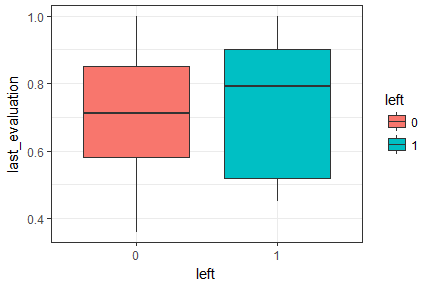
績效評估與是否離職的箱線圖
<textarea readonly="readonly" name="code" class="python">
# 繪製平均月工作時長與是否離職的箱線圖
box_mon <- ggplot(hr, aes(x = left, y = average_montly_hours, fill = left)) +
geom_boxplot() +
theme_bw() +
labs(x = 'left', y = 'average_montly_hours')
box_mon
</textarea>
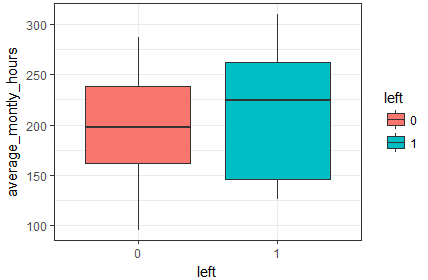
平均月工作時長與是否離職的箱線圖
<textarea readonly="readonly" name="code" class="python">
# 繪製員工在公司工作年限與是否離職的箱線圖
box_time <- ggplot(hr, aes(x = left, y = time_spend_company, fill = left)) +
geom_boxplot() +
theme_bw() +
labs(x = 'left', y = 'time_spend_company')
box_time
</textarea>
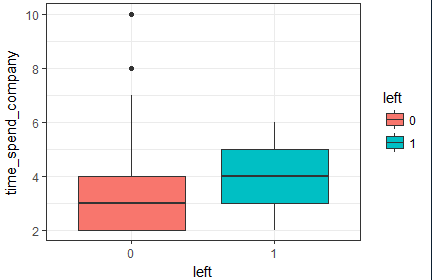
員工在公司工作年限與是否離職的箱線圖
<textarea readonly="readonly" name="code" class="python">
# 合併這些圖形在一個繪圖區域,cols = 2的意思就是排版為一行二列
multiplot(box_sat, box_eva, box_mon, box_time, cols = 2)
</textarea>- 探索員工對公司滿意度、績效評估、月均工作時長和工作年限與離職的關係

<textarea readonly="readonly" name="code" class="python">
###-------探索參與專案個數、五年內有沒有升職和薪資與離職的關係------###
# 繪製參與專案個數條形圖時需要把此變數轉換為因子型
hr$number_project <- factor(hr$number_project,
levels = c('2', '3', '4', '5', '6', '7'))
# 繪製參與專案個數與是否離職的百分比堆積條形圖
bar_pro <- ggplot(hr, aes(x = number_project, fill = left)) +
geom_bar(position = 'fill') + # position = 'fill'即繪製百分比堆積條形圖
theme_bw() +
labs(x = 'left', y = 'number_project')
bar_pro
</textarea>

參與專案個數與是否離職的百分比堆積條形圖
<textarea readonly="readonly" name="code" class="python">
# 繪製5年內是否升職與是否離職的百分比堆積條形圖
bar_5years <- ggplot(hr, aes(x = as.factor(promotion_last_5years), fill = left)) +
geom_bar(position = 'fill') +
theme_bw() +
labs(x = 'left', y = 'promotion_last_5years')
bar_5years
</textarea>

5年內是否升職與是否離職的百分比堆積條形圖
<textarea readonly="readonly" name="code" class="python">
# 繪製薪資與是否離職的百分比堆積條形圖
bar_salary <- ggplot(hr, aes(x = salary, fill = left)) +
geom_bar(position = 'fill') +
theme_bw() +
labs(x = 'left', y = 'salary')
bar_salary
</textarea>

薪資與是否離職的百分比堆積條形圖
<textarea reaonly="readonly" name="code" class="python"
# 合併這些圖形在一個繪圖區域,cols = 3的意思就是排版為一行三列
multiplot(bar_pro, bar_5years, bar_salary, cols = 3)
</textarea>
三、建模預測之迴歸樹
<textarea readonly="readonly" name="code" class="python">
############## =============== 提取優秀員工 =========== ###################
# filter()用來篩選符合條件的樣本
hr_model <- filter(hr, last_evaluation >= 0.70 | time_spend_company >= 4
| number_project > 5)
############### ============ 自定義交叉驗證方法 ========== ##################
# 設定5折交叉驗證 method = ‘cv’是設定交叉驗證方法,number = 5意味著是5折交叉驗證
train_control <- trainControl(method = 'cv', number = 5)
</textarea>
<textarea readonly="readonly" name="code" class="python">
################ =========== 分成抽樣 ============== ##########################
set.seed(1234) # 設定隨機種子,為了使每次抽樣結果一致
# 根據資料的因變數進行7:3的分層抽樣,返回行索引向量 p = 0.7就意味著按照7:3進行抽樣,
# list=F即不返回列表,返回向量
index <- createDataPartition(hr_model$left, p = 0.7, list = F)
traindata <- hr_model[index, ] # 提取資料中的index所對應行索引的資料作為訓練集
testdata <- hr_model[-index, ] # 其餘的作為測試集
##################### ============= 迴歸樹 ============= #####################
# 使用caret包中的trian函式對訓練集使用5折交叉的方法建立決策樹模型
# left ~.的意思是根據因變數與所有自變數建模;trCintrol是控制使用那種方法進行建模
# methon就是設定使用哪種演算法
rpartmodel <- train(left ~ ., data = traindata,
trControl = train_control, method = 'rpart')
# 利用rpartmodel模型對測試集進行預測,([-7]的意思就是剔除測試集的因變數這一列)
pred_rpart <- predict(rpartmodel, testdata[-7])
newtestdata <- cbind(testdata[-7],pred_rpart)#
# 建立混淆矩陣,positive=‘1’設定我們的正例為“1”
con_rpart <- table(pred_rpart, testdata$left)
con_rpart
</textarea>





四、建模預測之樸素貝葉斯
<textarea readonly="readonly" name="code" class="python">
################### ============ Naives Bayes =============== #################
nbmodel <- train(left ~ ., data = traindata,
trControl = train_control, method = 'nb')
pred_nb <- predict(nbmodel, testdata[-7])
con_nb <- table(pred_nb, testdata$left)
con_nb
</textarea>

五、模型評估+應用


<textarea readonly="readonly" name="code" class="python">
################### ================ ROC ==================== #################
# 使用roc函式時,預測的值必須是數值型
pred_rpart <- as.numeric(as.character(pred_rpart))
pred_nb <- as.numeric(as.character(pred_nb))
roc_rpart <- roc(testdata$left, pred_rpart) # 獲取後續畫圖時使用的資訊
#假正例率:(1-Specififity[真反例率])
Specificity <- roc_rpart$specificities # 為後續的橫縱座標軸奠基,真反例率
Sensitivity <- roc_rpart$sensitivities # 查全率 : sensitivities,也是真正例率
# 繪製ROC曲線
#我們只需要橫縱座標 NULL是為了宣告我們沒有用任何資料
p_rpart <- ggplot(data = NULL, aes(x = 1- Specificity, y = Sensitivity)) +
geom_line(colour = 'red') + # 繪製ROC曲線
geom_abline() + # 繪製對角線
annotate('text', x = 0.4, y = 0.5, label = paste('AUC=', #text是宣告圖層上新增文字註釋
#‘3’是round函式裡面的引數,保留三位小數
round(roc_rpart$auc, 3))) + theme_bw() + # 在圖中(0.4,0.5)處新增AUC值
labs(x = '1 - Specificity', y = 'Sensitivities') # 設定橫縱座標軸標籤
p_rpart
</textarea>
<textarea readonly="readonly" name="code" class="python">
roc_nb <- roc(testdata$left, pred_nb)
Specificity <- roc_nb$specificities
Sensitivity <- roc_nb$sensitivities
p_nb <- ggplot(data = NULL, aes(x = 1- Specificity, y = Sensitivity)) +
geom_line(colour = 'red') + geom_abline() +
annotate('text', x = 0.4, y = 0.5, label = paste('AUC=',
round(roc_nb$auc, 3))) + theme_bw() +
labs(x = '1 - Specificity', y = 'Sensitivities')
p_nb
</textarea>
總結:迴歸樹的AUC值(0.93) > 樸素貝葉斯的AUC值(0.839),最終我們選擇了迴歸樹模型做為我們的實際預測模型
<textarea readonly="readonly" name="code" class="python">
######################### ============= 應用 =============####################
# 使用迴歸樹模型預測分類的概率,type=‘prob’設定預測結果為離職的概率和不離職的概率
pred_end <- predict(rpartmodel, testdata[-7], type = 'prob')
# 合併預測結果和預測概率結果
data_end <- cbind(round(pred_end, 3), pred_rpart)
# 為預測結果表重新命名
names(data_end) <- c('pred.0', 'pred.1', 'pred')
# 生成一個互動式資料表
datatable(data_end)
</textarea>
最終我們生成了一個預測結果表:
預測結果表第一列代表:員工不離職概率(pred.0)
預測結果表第二列代表:員工離職概率(pred.1)
預測結果表第三列代表:員工是否離職(pred)
相關推薦
R:員工離職預測實戰
一、背景介紹為什麼我們最好和最有經驗的員工過早離職?資料來自Kaggle中的,想並嘗試預測下一個什麼樣的有價值的員工將離開。通過分析資料,瞭解影響員工辭職的因素有哪些,以及最主要的原因,預測哪些優秀員工會離職。變數說明:<textarea readonly="reado
R語言-邏輯迴歸+主成分分析-員工離職預測訓練賽
題目:員工離職預測訓練賽 網址:http://www.pkbigdata.com/common/cmpt/員工離職預測訓練賽_競賽資訊.html 要求: 資料主要包括影響員工離職的各種因素(工資、出差、工作環境滿意度、工作投入度、是否加班、是否升職、工資提升比例等)以及員工
R語言-決策樹-員工離職預測訓練賽
題目:員工離職預測訓練賽 網址:http://www.pkbigdata.com/common/cmpt/員工離職預測訓練賽_競賽資訊.html 要求: 資料主要包括影響員工離職的各種因素(工資、出差、工作環境滿意度、工作投入度、是否加班、是否升職、工資提升比例等)以及員工
DC比賽員工離職預測訓練賽(邏輯回歸)
watermark www htm -h shadow https com aca image 先 去掉些不要的列。 (2)Attrition:員工是否已經離職, 數量和部門的 關系。 薪酬水平與離職率的疊加條形圖 。 註意,對象為object類型,會導致 後面運行
用R語言分析與預測員工離職
在實驗室搬磚之後,繼續我們的kaggle資料分析之旅,這次資料也是答主在kaggle上選擇的比較火的一份關於人力資源的資料集,關注點在於員工離職的分析和預測,依然還是從資料讀取,資料預處理,EDA和機器學習建模這幾個部分開始進行,最後使用整合學習中比較火的random forest演算法來預
員工離職案例預測--R語言--kaggle資料
需要安裝的包: library(plyr) # Rmisc的關聯包,若同時需要載入dplyr包,必須先載入plyr包 library(dplyr) # filter() library(ggplot2) # ggplot()
R語言預測實戰原始碼 Predictive Practice With R source code
@rover這個是C++模板 --胡滿超 stack<Postion> path__;這個裡面 ”<> “符號是什麼意思?我在C++語言裡面沒見過呢? 初學者,大神勿噴。
外推預測法(R語言預測實戰-節選)
外推預測法是根據過去和現在的發展趨勢推斷未來的一類方法的總稱。因為外推預測法基於過去的行為資料,所以它是保守的。通常可以使用時間序列資料或橫截面資料進行外推預測。對於橫截面資料進行外推的情況,比如可
Logisitc Regression 預測員工離職率
Logistic Regression 基礎Logistic Regression 沿用了 Linear Regression 的思路和想法,通過使用線性關係擬合得到真實的函式關係。同樣的,如果模型結果表現不好,可能是超引數沒調好,或者是訓練集的特徵沒處理好(可以多構造一些特
人力資源員工離職原因資料分析
本專案的資料集來源kaggle競賽專案:HR-Analytics,自行下載即可! 1.提出問題 公司當中員工們離職的原因是什麼? 什麼樣的員工會離職呢? 2.讀取資料,理解資料 匯入資料分析工具包,這次我們用seaborn庫來優化我們的資料視覺化圖表! 讀取資料 檢視資料
【轉】寫在員工離職之後 一個小企業招人的胡思亂想
來自飛哥的部落格 https://www.cnblogs.com/freeflying/p/4709539.html 補充:建議將此文和《一個小企業招人的胡思亂想》一起讀,別有一番風味啊。 =========== 下午員工辭職了,我又成了“光桿司令”一枚。謹以此文記。
【轉】寫在員工離職之後
教你 矛盾 客戶 左右 也不會 出口 戰鬥力 老師 地方 來自飛哥的博客 https://www.cnblogs.com/freeflying/p/4709539.html 補充:建議將此文和《一個小企業招人的胡思亂想》一起讀,別有一番風味啊。 ===========
領導逼迫員工離職的10大套路
在職場上,一些企業為了辭退員工,往往會使用一些套路手段,逼迫員工主動離職。因為企業主動辭退員工的話,會付出很高的成本和代價。 今天總結了領導逼迫員工主動離職的10大套路,別到時候用到了你身上,還一無所知。 第一、惡性競爭法 惡性競爭法就是制定一些競爭的規則。
深度學習RNN實現股票預測實戰(附資料、程式碼)
背景知識最近再看一些量化交易相關的材料,偶然在網上看到了一個關於用RNN實現股票預測的文章,出於好奇心把文章中介紹的程式碼在本地跑了一遍,發現可以work。於是就花了兩個晚上的時間學習了下程式碼,順便把
唐宇迪機器學習之離職預測
最近在看唐宇迪機器學習視訊,這個視訊我覺得很不錯,可是我資源有限,有的視訊沒有配套的資料、資料集或者是程式碼,但還是可以看視訊瞭解其中的一些知識點。 專案介紹 該專案是通過員工對公司的滿意程度、公司對員工的評估、員工薪資水平、員工崗位、員工工作時長等特徵來推斷員
百度員工離職總結:如何做個好員工
2014年7月4日,我從百度離職了。 這是第一次,我不是因為和老闆鬧翻而離職; 這是第一次,我帶著晉升的喜悅而離職; 這是第一次,我帶著滿滿的收穫而離職。 我曾經認為,我永遠不會成為一個好員工,因為我太獨、太挑剔、不喜歡聽話的好孩子、而且討厭一切想要改變我的人。但
員工離職的幾個階段和原因
員工為什麼離職,一直是困擾中小企業的難題。如何降低員工的離職率,必須從研究員工為什麼離職開始? 員工為什麼離職?他們對什麼不滿?我們今天就來探討一下。 入職兩週離職。 說明新員工看到的實際狀況(包括公司環境、入職培訓、接待、待遇、制度等方方面面的第一感受)與預
百度員工離職忠告:你我都是平庸人,要學會適應規則…
導讀:4月18日,百度副總裁、公眾號“李叫獸”創始人李靖在朋友圈宣佈離職。李靖表示,離開是個人原
Hadoop鏈式MapReduce、多維排序、倒排索引、自連線演算法、二次排序、Join效能優化、處理員工資訊Join實戰、URL流量分析、TopN及其排序、求平均值和最大最小值、資料清洗ETL、分析氣
Hadoop Mapreduce 演算法彙總 第52課:Hadoop鏈式MapReduce程式設計實戰...1 第51課:Hadoop MapReduce多維排序解析與實戰...2 第50課:HadoopMapReduce倒排索引解析與實戰...3 第49課:Hado
百度員工離職總結:我永遠不會成為一個好員工
原文地址:https://blog.csdn.net/zhengcaihua0/article/details/80032045兩年前,我從百度離職了。我曾經認為,我永遠不會成為一個好員工,因為我太獨、太挑剔、不喜歡聽話