
谷歌翻譯整合神經網路:機器翻譯實現顛覆性突破
選自Google Research
作者:Quoc V. Le、Mike Schuster
機器之心編譯
參與:吳攀
昨日,谷歌在 ArXiv.org 上發表論文《Google`s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation》介紹谷歌的神經機器翻譯系統(GNMT),當日機器之心就對該論文進行了摘要翻譯並推薦到網站(www.jiqizhixin.com)上。今日,谷歌 Research Blog 釋出文章對該研究進行了介紹,還宣佈將 GNMT 投入到了非常困難的漢語-英語語言對的翻譯生產中,引起了業內的極大的關注。
十年前,我們釋出了 Google Translate(谷歌翻譯),這項服務背後的核心演算法是基於短語的機器翻譯(PBMT:Phrase-Based Machine Translation)。自那時起,機器智慧的快速發展已經給我們的語音識別和影象識別能力帶來了巨大的提升,但改進機器翻譯仍然是一個高難度的目標。
今天,我們宣佈釋出谷歌神經機器翻譯(GNMT:Google Neural Machine Translation)系統,該系統使用了當前最先進的訓練技術,能夠實現到目前為止機器翻譯質量的最大提升。我們的全部研究結果詳情請參閱我們的論文《Google`s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation》(見文末)[1]。
幾年之前,我們開始使用迴圈神經網路(RNN:Recurrent Neural Networks)來直接學習一個輸入序列(如一種語言的一個句子)到一個輸出序列(另一種語言的同一個句子)的對映 [2]。其中基於短語的機器學習(PBMT)將輸入句子分解成詞和短語,然後很大程度上對它們進行獨立地翻譯,而神經機器翻譯(NMT)則將整個輸入句子視作翻譯的基本單元。這種方法的優點是:相比於之前的基於短語的翻譯系統,這種方法所需的工程設計更少。當其首次被提出時,NMT 在中等規模的公共基準資料集上就達到了可與基於短語的翻譯系統媲美的準確度。
自那以後,研究者已經提出了很多改進 NMT 的技術,其中包括模擬外部對準模型(external alignment model)來處理罕見詞 [3],使用注意(attention)來對準輸入詞和輸出詞 [4] 以及將詞分解成更小的單元以應對罕見詞 [5,6]。儘管有這些進步,但 NMT 的速度和準確度還沒能達到成為 Google Translate 這樣的生產系統的要求。我們的新論文 [1] 描述了我們怎樣克服了讓 NMT 在非常大型的資料集上工作的許多挑戰,以及我們如何打造了一個在速度和準確度上都已經足夠能為谷歌的使用者和服務帶來更好的翻譯的系統。

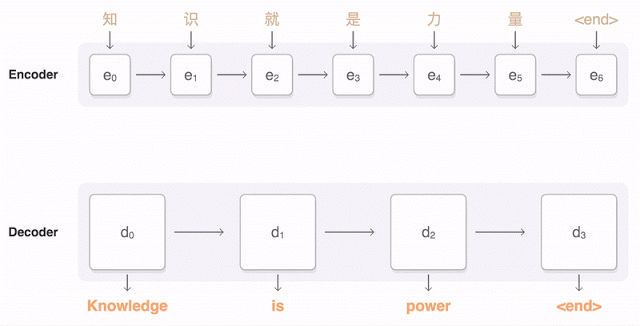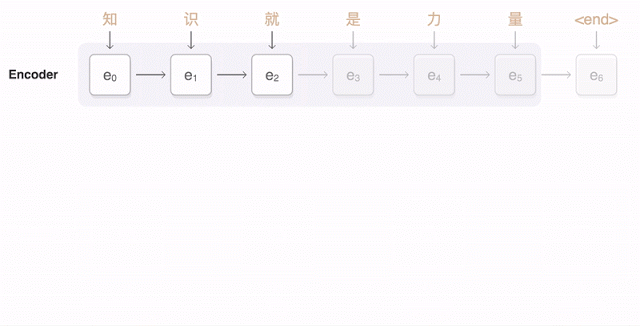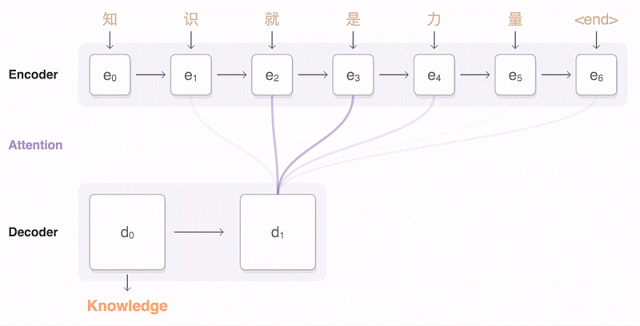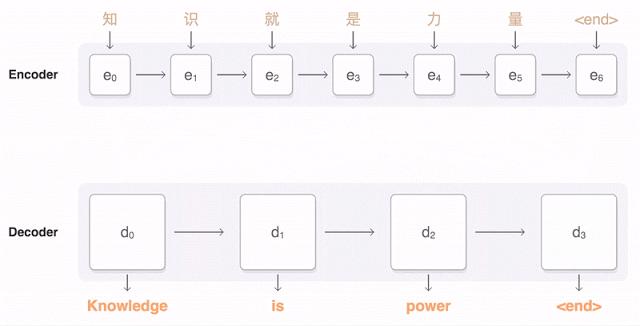
下面的視覺化圖展示了 GNMT 將一個漢語句子翻譯成英語句子的過程。首先,該網路將該漢語句子的詞編碼成一個向量列表,其中每個向量都表徵了到目前為止所有被讀取到的詞的含義(「編碼器(Encoder)」)。一旦讀取完整個句子,解碼器就開始工作——一次生成英語句子的一個詞(「解碼器(Decoder)」。為了在每一步都生成翻譯正確的詞,解碼器重點注意了與生成英語詞最相關的編碼的漢語向量的權重分佈(「注意(Attention)」,藍色連結的透明度表示解碼器對一個被編碼的詞的注意程度)。
使用人類評估的並排比較作為一項標準,GNMT 系統得出的翻譯相比於之前的基於短語的生產系統實現了極大的提升。在雙語人類評估者的幫助下,我們在來自維基百科和新聞網站的樣本句子上測定發現:GNMT 在多個主要語言對的翻譯中將翻譯誤差降低了 55%-85% 以上。

今天除了釋出這份研究論文之外,我們還宣佈將 GNMT 投入到了一個非常困難的語言對(漢語-英語)的翻譯的生產中。現在,移動版和網頁版的 Google Translate 的漢英翻譯已經在 100% 使用 GNMT 機器翻譯了——每天大約 1800 萬條翻譯。GNMT 的生產部署是使用我們公開開放的機器學習工具套件 TensorFlow 和我們的張量處理單元(TPU:Tensor Processing Units),它們為部署這些強大的 GNMT 模型提供了足夠的計算算力,同時也滿足了 Google Translate 產品的嚴格的延遲要求。漢語到英語的翻譯是 Google Translate 所支援的超過 10000 種語言對中的一種,在未來幾個月,我們還將繼續將我們的 GNMT 擴充套件到遠遠更多的語言對上。
機器翻譯還遠未得到完全解決。GNMT 仍然會做出一些人類翻譯者永遠不出做出的重大錯誤,例如漏詞和錯誤翻譯專有名詞或罕見術語,以及將句子單獨進行翻譯而不考慮其段落或頁面的上下文。為了給我們的使用者帶來更好的服務,我們還有更多的工作要做。但是,GNMT 代表著一個重大的里程碑。我們希望與過去幾年在這個研究方向上有所貢獻的許多研究者和工程師一起慶祝它——不管是來自谷歌還是更廣泛的社群。
Google Brain 團隊和 Google Translate 團隊都參與了該專案。Nikhil Thorat 和 Big Picture 也幫助了該專案的視覺化工作。
論文:Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation

摘要:神經機器翻譯(NMT: Neural Machine Translation)是一種用於自動翻譯的端到端的學習方法,該方法有望克服傳統的基於短語的翻譯系統的缺點。不幸的是,眾所周知 NMT 系統的訓練和翻譯推理的計算成本非常高。另外,大多數 NMT 系統都難以應對罕見詞。這些問題阻礙了 NMT 在實際部署和服務中的應用,因為在實際應用中,準確度和速度都很關鍵。我們在本成果中提出了 GNMT——谷歌的神經機器翻譯(Google's Neural Machine Translation)系統來試圖解決許多這些問題。我們的模型由帶有 8 個編碼器和 8 個解碼器的深度 LSTM 網路組成,其使用了注意(attention)和殘差連線(residual connections)。為了提升並行性從而降低訓練時間,我們的注意機制將解碼器的底層連線到了編碼器的頂層。為了加速最終的翻譯速度,我們在推理計算過程中使用了低精度運算。為了改善對罕見詞的處理,我們將詞分成常見子詞(sub-word)單元(詞的元件)的一個有限集合,該集合既是輸入也是輸出。這種方法能提供「字元(character)」-delimited models 的靈活性和「詞(word)」-delimited models 的有效性之間的平衡、能自然地處理罕見詞的翻譯、並能最終提升系統的整體準確度。我們的波束搜尋技術(beam search technique)使用了一個長度規範化(length-normalization)過程,並使用了一個覆蓋度懲罰(coverage penalty),其可以激勵很可能能覆蓋源句子中所有的詞的輸出句子的生成。在 WMT' 14 英語-法語和英語-德語基準上,GNMT 實現了可與當前最佳結果媲美的結果。通過在一個單獨的簡單句子集合的人類對比評估中,它相比於谷歌已經投入生產的基於短語的系統的翻譯誤差平均降低了 60%。
參考文獻:
[1] Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, Jeffrey Dean. Technical Report, 2016.
[2] Sequence to Sequence Learning with Neural Networks, Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Advances in Neural Information Processing Systems, 2014.
[3] Addressing the rare word problem in neural machine translation, Minh-Thang Luong, Ilya Sutskever, Quoc V. Le, Oriol Vinyals, and Wojciech Zaremba. Proceedings of the 53th Annual Meeting of the Association for Computational Linguistics, 2015.
[4] Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. International Conference on Learning Representations, 2015.
[5] Japanese and Korean voice search, Mike Schuster, and Kaisuke Nakajima. IEEE International Conference on Acoustics, Speech and Signal Processing, 2012.
[6] Neural Machine Translation of Rare Words with Subword Units, Rico Sennrich, Barry Haddow, Alexandra Birch. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016.
來源:
http://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650719470&idx=1&sn=3368dea980517ea7d7942967da2740dc&chksm=871b0090b06c89863620be4e75c757940d03d8a43cd3c1d9a8309b6594c1bccd769cab193177&scene=21#wechat_redirect
相關推薦
谷歌翻譯整合神經網路:機器翻譯實現顛覆性突破
選自Google Research作者:Quoc V. Le、Mike Schuster機器之心編譯參與:吳攀昨日,谷歌在 ArXiv.org 上發表論文《Google`s Neural Machine Translation System: Bridging the Gap
使用谷歌翻譯讓你的網站也實現多國語言版
我們經常會看到訪問一些外國網站的時候,會在網站底部或者頂部出現您當前網頁的網頁需要翻譯的工具條,讓你很輕鬆的翻譯成自己熟悉的語言,這樣的網站使用者體驗絕對是非常讚的,所以呢,當你發現自己的網站只有簡體中文,但卻被不同語言的使用者訪問,他們很苦惱,你網站上有大篇大篇精彩的文章,他們卻不知所云。你是不是自己也很鬱
谷歌開源整合學習工具AdaNet:2017年提出的演算法終於實現了
曉查 編譯整理量子位 報道 | 公眾號 QbitAI 最近,谷歌在GitHub上釋出了用TensorFlow實現的AutoML框架——AdaNet,它改進了整合學習的方法,能以最少的專家干預實現自動習得高質量模型。 谷歌AI研究團曾在2017年的ICML上提出了AdaNet:人
從整合方法到神經網路:自動駕駛技術中的機器學習演算法有哪些?
來源:機器之心 編譯:Lj Linjing、蔣思源 物聯網智庫 原創 轉載請註明來源和出處 ------ 【導讀】------ 機器學習演算法可以融合來自車體內外不同感測器的資料,從而評估駕駛員狀況或者對駕駛場景進行分類。本文將粗略講解一下各類用於自動駕駛技術的演算法。 如今,機器
親歷谷歌翻譯,論機器翻譯之淺薄。
授權自AI科技大本營(ID: rgznai100)翻譯: shawn本文共1W+字,建議閱讀10
C#調用谷歌翻譯API
str following cep jscript coo values single blog var 原資料為網上找到的原稿為:http://www.cnblogs.com/marso/p/google_translate_api.html(此處只做個人筆記參考) 主要
谷歌推出備份新工具:Google Drive將同步計算機文件
tps 辦公 steam 得到 同步 content nan upd syn Google 正在將雲端硬盤 Drive 轉變成更強大的文件備份工具。很快,Google Drive 將能監測並備份你電腦上的(幾乎)所有文件,只要是你勾選的文檔,Drive 就能同步至雲端。
Web API 2 入門——創建ASP.NET Web API的幫助頁面(谷歌翻譯)
鏈接 所有 action 解決方案 fec amp 開發人員 sharp ima 在這篇文章中 創建API幫助頁面 將幫助頁面添加到現有項目 添加API文檔 在敞篷下 下一步 作者:Mike Wasson 創建Web API時,創建幫助
使用谷歌翻譯C#版本.
pen 工作 sha 5.0 有效 sys mic 追蹤 val 工作需要,把一個程序翻譯為多語言版,很悲催的其中一個語種為土耳其語.國內開放API的翻譯均不支持.微軟的實在是麻煩.網上找到一個c#版,修修改改,湊合用.親測有效. 開發工具:VS2013 需要引用多個單元
百度谷歌蘋果們的殊途同歸:平臺化發展的必然與可能
開發套件 圖片 原因 傳統 單單 window 數據 iphone 開發平臺 一年一度的百度AI開發者大會,是下半年最值得期待的科技盛會之一。作為AI企業的龍頭,百度在開發者方面所展示出的動向,在世界範圍內都牽動著產業的神經。在這次百度AI開發者大會上,出現了一種非常有趣的
谷歌迂回入華:Waymo無人車搶先進駐上海!
開放 回歸 汽車市場 電動 負責人 要求 廣告 中國區 商務 谷歌迂回入華:Waymo無人車搶先進駐上海! https://mp.weixin.qq.com/s/d5Cw2uhykMJ9urb6Cs8aNw 谷歌又雙
改善深層神經網路:超引數除錯、正則化以及優化_課程筆記_第一、二、三週
所插入圖片仍然來源於吳恩達老師相關視訊課件。仍然記錄一下一些讓自己思考和關注的地方。 第一週 訓練集與正則化 這周的主要內容為如何配置訓練集、驗證集和測試集;如何處理偏差與方差;降低方差的方法(增加資料量、正則化:L2、dropout等);提升訓練速度的方法:歸一化訓練集;如何合理的初始化權
TensorFlow神經網路:模組化的神經網路八股
1、前向傳播: 搭建從輸入到輸出的網路結構 forward.py: # 定義前向傳播過程 def forward(x, regularizer): w = b = y = return y # 給w賦初值,並把w的正則化損失加到總損失中 def g
Java 破解谷歌翻譯 免費 api 呼叫
在公司大佬的指點下, 寫了個破解谷歌翻譯的工具類,能破解谷歌翻譯, 思路如下: 1 獲取 tkk 2 根據 tkk,和 輸入內容 獲取 tk 3 根據 word,tk ,組裝 url 訪問 谷歌翻譯 api -----------------------------
機器學習筆記(十五):TensorFlow實戰七(經典卷積神經網路:VGG)
1 - 引言 之前我們介紹了LeNet-5和AlexNet,在AlexNet發明之後,卷積神經網路的層數開始越來越複雜,VGG-16就是一個相對前面2個經典卷積神經網路模型層數明顯更多了。 VGGNet是牛津大學計算機視覺組(Visual Geometry Group)和Google
機器學習筆記(十四):TensorFlow實戰六(經典卷積神經網路:AlexNet )
1 - 引言 2012年,Imagenet比賽冠軍的model——Alexnet [2](以第一作者alex命名)。這個網路算是一個具有突破性意義的模型 首先它證明了CNN在複雜模型下的有效性,然後GPU實現使得訓練在可接受的時間範圍內得到結果,讓之後的網路模型構建變得更加複雜,並且通過
機器學習筆記(十三):TensorFlow實戰五(經典卷積神經網路: LeNet -5 )
1 - 引言 之前我們介紹了一下卷積神經網路的基本結構——卷積層和池化層。通過這兩個結構我們可以任意的構建各種各樣的卷積神經網路模型,不同結構的網路模型也有不同的效果。但是怎樣的神經網路模型具有比較好的效果呢? 下圖展示了CNN的發展歷程。 經過人們不斷的嘗試,誕生了許多有
谷歌擴充套件分享第一期:完美訪問Google搜尋,YouTube,Twitter等網站
上期回顧:上一期介紹了Google Chrome下載官方正版瀏覽器及設定瀏覽器語言。 這期則介紹使用Google Chrome最基本的擴充套件,那就是利用谷歌服務助手和谷歌訪問助手訪問Google搜尋以及登入Google賬號等谷歌產品。 一、首先介紹谷歌服務助手 谷歌服務助手可以訪問所有Goog
改善深層神經網路:超引數除錯、正則化以及優化 優化演算法 第二週
改善深層神經網路:超引數除錯、正則化以及優化 優化演算法 第二課 1. Mini-batch Batch vs Mini-batch gradient descent Batch就是將所有的訓練資料都放到網路裡面進行訓練,計算量大,硬體要求高。一次訓練只能得到一個梯
吳恩達 改善深層神經網路:超引數除錯、正則化以及優化 第一週
吳恩達 改善深層神經網路:超引數除錯、正則化以及優化 課程筆記 第一週 深度學習裡面的實用層面 1.1 測試集/訓練集/開發集 原始的機器學習裡面訓練集,測試集和開發集一般按照6:2:2的比例來進行劃分。但是傳統的機器學習