
Kafka實現生產者消費者 自定義partition
KafkaAPI實現生產者與消費者自定義Partition,奇數、偶數資料分在不同的Partition.
思路
建立三個類,包括Consumer、Producer、Partition在Producer端產生訊息,Consumer端接收訊息,Partition實現分割槽規則。Producer根據隨機函式隨機產生十個資料,其中包括奇數和偶數。因為是將奇數和偶數劃分到不同的partition當中去,所以在實現的分割槽的時候使用的是取模的方法。
- 設定producer的配置資訊
public Producer(String topic) {
Properties props = new Properties(); - 傳送訊息佇列,使用迴圈的方法,後面的number和runtime是鍵值對的形式
public void producerMsg() throws InterruptedException{
Random rnd = new Random();
int events = 10;
for (long nEvents = 0; nEvents < events; nEvents++) {
long runtime = new Date().getTime();
String number = String.valueOf(rnd.nextInt(255));
try {
producer.send(new ProducerRecord<>(topic, number, String.valueOf(runtime)));
System.out.println("Sent message: (" + number + ", " +runtime+ ")");
} catch (Exception e) {
e.printStackTrace();
}
}
Thread.sleep(10000);
}- Consumer讀取資訊,同樣使用迴圈將key和value以及分割槽全部打印出來
public void consumerMsg(){
try {
consumer.subscribe(Collections.singletonList(this.topic));
while(true){
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
System.out.println("Received message: (" + record.key() + ", " + record.value() + ") at partition "+record.partition()+" offset " + record.offset());
}
}
} catch (Exception e) {
e.printStackTrace();
}
}- 分割槽規則的建立
public class SimplePartitioner implements Partitioner {
public SimplePartitioner() {
}
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String k = (String) key;
if(Integer.parseInt(k) % 2 == 0)
return 0;
else
return 1;
// return Integer.parseInt(k)%2;
}
@Override
public void close() {
}
}在建立分割槽的時候,如果不建立分割槽0,系統也會自動創建出0,在下面的程式中建立的分割槽是1和2,但是也會自動建立0分割槽,即一共會有三個分割槽。
- 結果
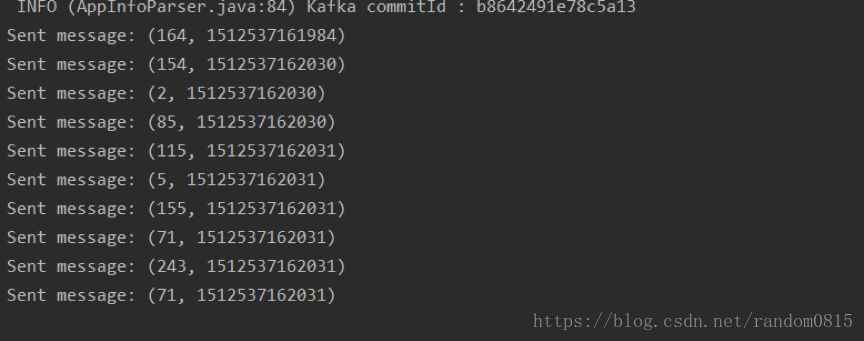
producer端產生的訊息
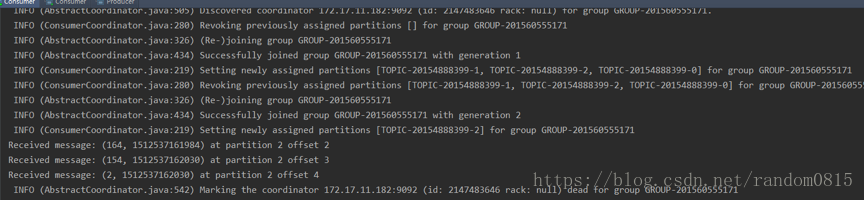
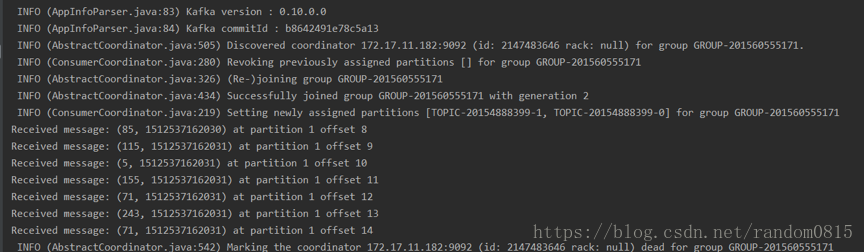
兩個consumer分別接收到的訊息
偶數
奇數
遇到的問題
1) 在使用單機模式,即Kafka的伺服器只有一個的時候,在Producer端產生訊息的速率特別慢,然後在consumer端接收不到訊息,放到前端去跑,會發現報錯。
kafka.admin.AdminOperationException: replication factor: 1 larger than available brokers: 0
解決辦法: 複製kafka/config路徑下的server.properties檔案為:server-1.properties和server-2.properties
並修改這兩個檔案的配置項:
server-1.properties
broker.id=1
port=9093
log.dir=/tmp/kafka-logs-1
host.name=localhost
server-2.properties
broker.id=2
port=9094
log.dir=/tmp/kafka-logs-2
host.name=localhost
然後重新啟動。就可以了
2) 在解決第一個問題之後,使用分割槽的時候還是出現問題,最後採用叢集的模式,但是在控制檯端執行的時候,先執行consumer,在執行producer發現consumer端並沒有分區劃分log日誌如下

解決方法:在執行的時候先執行producer、在同時執行兩個consumer、執行producer觀察開啟的consumer接收到的實時訊息。具體原因是為什麼也沒有找到,不過感覺可能是,如果先啟動consumer的話可能預先還沒有建立分割槽也就是沒有執行producer,所以找不到對應的分割槽資訊,所以先建立分割槽,第二次是用來傳遞訊息。
全部程式碼待我上傳到github上在發出來,如果現在需要直接私信我就好
相關推薦
Kafka實現生產者消費者 自定義partition
KafkaAPI實現生產者與消費者自定義Partition,奇數、偶數資料分在不同的Partition. 思路 建立三個類,包括Consumer、Producer、Partition在Producer端產生訊息,Consumer端接收訊息,Partition
kafka模擬生產者-消費者以及自定義分割槽
基本概念 kafka中的重要角色 broker:一臺kafka伺服器就是一個broker,一個叢集可有多個broker,一個broker可以容納多個topic topic:可以理解為一個訊息佇列的名字 partition:分割槽,為了實現擴充套件性,一個topic可以分佈到多
Kafka負載均衡、Kafka自定義Partition、Kafk檔案儲存機制
1、Kafka整體結構圖 Kafka名詞解釋和工作方式 Producer :訊息生產者,就是向kafka broker發訊息的客戶端。 Consumer :訊息消費者,向kafka broker取訊息的客戶端 Topic :咋們可
kafka自定義partition
自定義分割槽設定 class Partition implements Partitioner{ //設定 public void configure(Map<String, ?> configs) { } //分割槽邏輯 public int partitio
基於Kafka的生產者消費者消息處理本地調試
term 啟動 con 文件 tails console == cat 記得 (尊重勞動成果,轉載請註明出處:http://blog.csdn.net/qq_25827845/article/details/68174111冷血之心的博客)Kafka下載地址:http:
使用管程實現生產者消費者模式
dex .com 完成 ble override date 有用 mut 生產者消費者模式 生產者消費者模式是一種常見的設計模式,掌握一種完美,穩定的實現方式非常有用,下面我就使用misa管程實現生產者消費者模式。 這種實現的優點: 1.穩定,不會出現死鎖現象 2.運行速度
Queue 實現生產者消費者模型
pri join() imp 等待 tar 構造函數 nowait import 長度 Python中,隊列是線程間最常用的交換數據的形式。 Python Queue模塊有三種隊列及構造函數: 1、Python Queue模塊的FIFO隊列先進先出。 class Queue
HtmlWebpackPlugin實現資源的自定義插入
mon sin 我們 pro pack 分享圖片 static 通過 解決問題 目前碰到的問題 我們用html-webpack-plugin的inject屬性去自動插入打包後的js, css到頁面中,但是如果想給script標簽添加一個crossorigin屬性呢, 例
用Python多線程實現生產者消費者模式爬取鬥圖網的表情圖片
Python什麽是生產者消費者模式 某些模塊負責生產數據,這些數據由其他模塊來負責處理(此處的模塊可能是:函數、線程、進程等)。產生數據的模塊稱為生產者,而處理數據的模塊稱為消費者。在生產者與消費者之間的緩沖區稱之為倉庫。生產者負責往倉庫運輸商品,而消費者負責從倉庫裏取出商品,這就構成了生產者消費者模式。 生
spark源碼系列之累加器實現機制及自定義累加器
大數據 spark一,基本概念 累加器是Spark的一種變量,顧名思義該變量只能增加。有以下特點: 1,累加器只能在Driver端構建及並只能是Driver讀取結果,Task只能累加。 2,累加器不會改變Spark Lazy計算的特點。只會在Job觸發的時候進行相關累加操作。 3,現有累加器的類型。相信有很
python 歸納 (十四)_隊列Queue實現生產者消費者
() producer put consumer 啟動 produce odin gin and # -*- coding: UTF-8 -*- """ 多線程的生產者,消費者 使用隊列Queue """ import Queue import thre
多線程實現生產者消費者
sum sel item __main__ sleep port start per read 1 import threading 2 import random 3 import queue 4 import time 5 6 7 class Pro
Java實現生產者消費者模式的兩種方法
1、 利用 Object的 wait/notify,和非阻塞佇列實現 import java.util.PriorityQueue; public class Test{ private int size=10; private PriorityQueue&
Android 應用互調的實現並新增自定義許可權進行安全防護
最近在做一個安全漏洞修復的工作,場景是A應用必須由B應用調起,由於涉及到元件暴露所以我們需要考慮安全的問題,最後添加了自定義許可權進行解決。 一、A應用 作為被調起者,需要暴露元件給B應用。所以A的清單檔案中要新增自定義許可權(注意:這裡的許可權級別至少是signature或者signatu
Linux C 實現生產者消費者問題
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
大資料教程(8.6)yarn客戶端提交job的流程梳理和總結&自定義partition程式設計
上一篇部落格博主分享了mapreduce的並行原理,本篇部落格將繼續分享yarn客戶端提交job的流程和自定義partition程式設計。 一、
Asp.Net Core 輕鬆學-實現跨平臺的自定義Json資料包
前言 在前後端分離的業務開發中,我們總是需要返回各種各樣的資料包格式,一個良好的 json 格式資料包是我們一貫奉行的原則,下面就利用 Json.Net 來做一個簡單具有跨平臺的序列化資料包實現類。 1. 應用 Json.Net 1.1 首先在專案中引用 NuGet 包 1
OS:(Linux)多執行緒實現生產者-消費者問題--pthread庫
OS實驗——多執行緒實現生產者-消費者問題時,正確輸入程式碼生成檔案pthread.c,在終端執行: gcc編譯:輸入gcc -o pthread pthread.c 無法成功編譯,錯誤提示如下: CSDN查詢解決方案後,發現pthread庫並不是Linux系統預設的庫,連結時需要使
java併發之----實現生產者/消費者模式(操作值&一對一交替列印)
一、實現生產者/消費者模式 1、一生產與一消費:操作值 利用synchronized 實現,程式碼如下: public class Producer { private String lock; public Producer(String lock){ this.loc
ArcGIS for Android 100.3的學習與應用(三) 實現地圖新增自定義指北針
圖為高德地圖實現指北針的效果,那麼ArcGIS如何實現呢? 實現方式: 新增地圖的旋轉監聽: map.addMapRotationChangedListener(new MapRotationChangedListener() { @Override