
棧式自動編碼器(Stacked AutoEncoder)
起源:自動編碼器
單自動編碼器,充其量也就是個強化補丁版PCA,只用一次好不過癮。
仿照stacked RBM構成的DBN,提出Stacked AutoEncoder,為非監督學習在深度網路的應用又添了猛將。
這裡就不得不提 “逐層初始化”(Layer-wise Pre-training),目的是通過逐層非監督學習的預訓練,
來初始化深度網路的引數,替代傳統的隨機小值方法。預訓練完畢後,利用訓練引數,再進行監督學習訓練。
Part I 原理
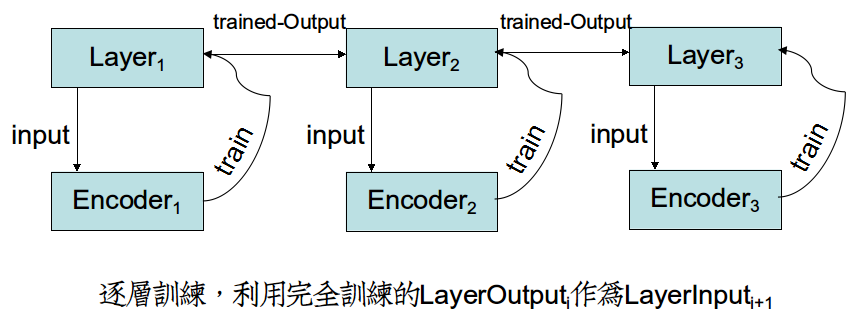
非監督學習網路訓練方式和監督學習網路的方式是相反的。
在監督學習網路當中,各個Layer的引數W受制於輸出層的誤差函式,因而Layeri
但是在非監督學習中,各個Encoder的引數W只受制於當前層的輸入,因而可以訓練完Encoderi,把引數轉給Layeri,利用優勢引數傳播到Layeri+1,再開始訓練。
形成"全部迭代-更新單層"的新訓練方式。這樣,Layeri+1效益非常高,因為它吸收的是Layeri完全訓練奉獻出的精華Input。
Part II 程式碼與實現
棧式機在建構函式中,構造出各個Layer、Encoder,並且存起來。
Theano在構建棧式機中,易錯點是Encoder、Layer的引數轉移。
我們知道,Python的列表有深淺拷貝一說。Theano所有被shared標記的變數都是淺拷貝。
因而首先有這樣的錯誤寫法:
def __init__(self,rng,input,n_in,n_out,layerSize): ...... for i in xrange(len(layerSize)): ...... da.W=hidenlayer.W da.bout=hidenlayer.b
然後你在外部為da做grad求梯度的時候就報錯了,提示說params和cost函式不符合。
這是因為cost函式的Tensor表示式在寫cost函式時就確定了,這時候da這個物件剛好構造完,因而Tensor表示式中的da.W是構造隨機值。
然後我們在da構造完了之後,手賤把da.W指向的記憶體改變了(淺拷貝相當於引用),這樣算出的grad根本就不對。
其實這樣寫反了,又改成了這樣
def __init__(self,rng,input,n_in,n_out,layerSize): ...... for i in xrange(len(layerSize)): ...... hidenlayer.W=da.W hidenlayer.b=da.bout
好吧,這樣不會報錯了,而且每訓練一個Encoder,用get_value檢視Layer的值確實改變了。但是,訓練Encoderi+1的時候,怎麼感覺沒效果?
其實是真的沒效果,因為Layeri的引數根本沒有傳播到Layeri+1去。
Theano採用Python、C雙記憶體區設計,在C程式碼中訓練完Encoderi時,引數並沒有轉到Layeri中。但是我們明明建立了淺拷貝啊?
原來updates函式在C記憶體區中,根本沒有覺察到淺拷貝關係,因為它在Python記憶體區中。
正確做法是像教程這樣,在da構造時建立淺拷貝關係,當編譯成C程式碼之後,所有Python物件要在C記憶體區重新構造,自然就在C記憶體區觸發了淺拷貝。
da=dA(rng,layerInput,InputSize,self.layerSize[i],hidenlayer.W,hidenlayer.b)
或者訓練完Encoderi,強制把Encoderi引數注入到C記憶體區的Layeri裡。
updateModel=function(inputs=[],outputs=[],updates=[(....)],
updateModel()
Theano的寫法風格近似於函式式語言,物件、函式中全是數學模型。一旦構造完了之後,就無法顯式賦值。
所以,在Python非建構函式裡為物件賦值是愚蠢的,效果僅限於Python記憶體區。但是大部分計算都在C記憶體區,所以需要updates手動把值打進C記憶體區。
updates是溝通兩區的橋樑,一旦發現Python記憶體區中有建立淺拷貝關係,就會把C記憶體區中值更新到Python記憶體區。(有利於Python中儲存引數)
但是絕對不會自動把Python記憶體區值,更新到C記憶體區當中。(這點必須小心)
這種做法可以擴充套件到,監督訓練完之後,引數的儲存與匯入。
相關推薦
棧式自動編碼器(Stacked AutoEncoder)
起源:自動編碼器 單自動編碼器,充其量也就是個強化補丁版PCA,只用一次好不過癮。 仿照stacked RBM構成的DBN,提出Stacked AutoEncoder,為非監督學習在深度網路的應用又添了猛將。 這裡就不得不提 “逐層初始化”(Layer-wise Pre-training),目的是
【模型詳解】AutoEncoder詳解(七)——棧式自編碼:Stacked AutoEncoder
更新時間:2018-12-05 前言 之前介紹了AutoEncoder及其幾種拓展結構,如DAE,CAE等,本篇部落格介紹棧式自編碼器。 模型介紹 普通的AE模型通過多層編碼解碼過程,得到輸出,最小化輸入輸出的差異從而使模型學到有用的特徵。但是這種AE結構又
基於tensorflow的棧式自編碼器實現
這周完全沒有想法要看棧式編碼器的,誰知誤入桃花源,就暫且把棧式自編碼器看了吧。由於手上有很多數值型的資料,僅僅是資料,沒有標籤,所以,迫切需要通過聚類抽出特徵。無意間看到別人家公司的推薦系統裡面用到sdae,於是,找了個ae程式,建了個sdae,跑一下自己的資料。希望sda
自動編碼器(Autoencoder)keras實現---轉載
1. 單隱含層自編碼器 建立一個全連線的編碼器和解碼器。也可以單獨使用編碼器和解碼器,在此使用Keras的函式式模型API即Model可以靈活地構建自編碼器。 50個epoch後,看起來我們的自編碼器優化的不錯了,損失val_loss: 0.1037。 from ke
自動編碼器(Autoencoder)、降噪自動編碼器(Denoising Autoencoder)詳解
在瞭解降噪自動編碼器之前,我們先了解一下自動編碼器。 自動編碼器(Autoencoder): 自動編碼器和PCA等方法都屬於降維方法。PCA降維方法有著一定侷限性,主要是隻對線性可分的資料降維效果較好。這種情況下,人們希望提出一種新的簡單的、自動的、可以對非線性可分資料進行的特徵提取方法
降噪自動編碼器(Denoising Autoencoder)
起源:PCA、特徵提取.... 隨著一些奇怪的高維資料出現,比如影象、語音,傳統的統計學-機器學習方法遇到了前所未有的挑戰。 資料維度過高,資料單調,噪聲分佈廣,傳統方法的“數值遊戲”很難奏效。資料探勘?已然挖不出有用的東西。 為了解決高維度的問題,出現的線性學習的PCA降維方法,PCA的數學理論確實無
Deep Learning(深度學習)學習筆記整理系列之(六)AutoEncoder自動編碼器
轉處:http://blog.csdn.net/zouxy09/article/details/8775524 Deep Learning(深度學習)學習筆記整理系列 作者:Zouxy version 1.0 2013-04-08 宣告: 1)該Deep
Recursive Autoencoders(遞迴自動編碼器)
1. 前言 今天主要介紹用在NLP中比較常見的AutoEncoder的模型,Recursive Autoencoders(遞迴自動編碼模型)。這篇文章主要討論RAE在序列化的資料中,如何把資料降維並且用向量表示。 2. 矩陣表示 假設我們有一個矩陣\(L\)的表示向量,一個有序的有\(m\)個元素的序列
pytorch 實現變分自動編碼器
本來以為自動編碼器是很簡單的東西,但是也是看了好多資料仍然不太懂它的原理。先把程式碼記錄下來,有時間好好研究。 這個例子是用MNIST資料集生成為例子。 # -*- coding: utf-8 -*- """ Created on Fri Oct 12 11:42:19 2018 @a
pytorch 自動編碼器
這裡主要使用自動編碼器實現生成資料,以MNIST資料為例。 # -*- coding: utf-8 -*- """ Created on Thu Oct 11 20:34:33 2018 @author: www """ import os import torch from torc
自動編碼器模型和程式碼解釋
CNN演算法與程式研究 1) 深度學習基本理論方法 http://wenku.baidu.com/view/2e630ddfc5da50e2524d7ff3
生成模型--稀疏自編碼器(sparse autoencoder,SAE)
稀疏自編碼器(sparse autoencoder,SAE) 在自動編碼的基礎上加上稀疏性限制,就可得到稀疏自動編碼器(Sparse AutoEncoder)。 用來約束自動編碼器重構的方法,是對其損失函式施加約束。比如,可對損失函式新增一個正則化約束,
生成模型--降噪自編碼器(denoising autoencoder,DAE)
降噪自編碼器(denoising autoencoder,DAE) 這裡不是通過對損失函式施加懲罰項,而是通過改變損失函式的重構誤差項來學習一些有用資訊。 向輸入的訓練資料加入噪聲,並使自編碼器學會去除這種噪聲來獲得沒有被噪聲汙染過的真實輸入。因此,這就
[TensorFlow深度學習入門]實戰十二·使用DNN網路實現自動編碼器
[TensorFlow深度學習入門]實戰十二·使用DNN網路實現自動編碼器 測試程式碼 import os os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" import tensorflow as tf from tensorflow
DenoisingAutoencoder(影象去噪自動編碼器)
本文主要介紹使用TensorFlow實現DenoisingAutoencoder(影象去噪自動編碼器)。 下面是示例程式碼: # 匯入相關模組 import numpy as np import sys import tensorflow as tf import matplotlib.
深度學習:自動編碼器基礎和型別
本文轉載自《機器之心》,原文連結:https://mp.weixin.qq.com/s/QuDa__mi1NX1wOxo5Ki94A ,如有侵權請聯絡刪除。 很顯然,深度學習即將對我們的社會產生重大顯著的影響。Mobibit 創始人兼 CEO Pramod Chandray
深度學習UFLDL教程翻譯之自動編碼器
一、自動編碼器 目前為止,我們介紹了神經網路在有標籤的訓練樣本的有監督學習中的應用.現在假設我們只有一個未標記的訓練集{x(1),x(2),x(3),…},其中x是n維的.自動編碼器神經
Keras —— 構造變分自動編碼器
變數初始化及函式定義 batch_size = 100 original_dim = 784 latent_dim = 2 intermediate_dim = 256 nb_epoch = 50
簡單易懂的自動編碼器
作者:葉虎 編輯:田旭 引言 自動編碼器是一種無監督的神經網路模型,它可以學習到輸入資料的隱含特徵,這稱為編碼(coding),同時用學習到的新特徵可以重構出原始輸入資料,稱之為解碼(decoding)。從直觀上來看,自動編碼器可以用於特徵降維,類似主成分分析PCA,但是其相比PCA其效能更強,
沒有任何公式——直觀的理解變分自動編碼器VAE
autoencoders作為一種非常直觀的無監督的學習方法是很受歡迎的,最簡單的情況是三層的神經網路,第一層是資料輸入,第二層的節點數一般少於輸入層,並且第三層與輸入層類似,層與層之間互相全連線,這種網路被稱作自動編碼器,因為該網路將輸入“編碼”成一個隱藏程式碼,