
基於tensorflow的棧式自編碼器實現
阿新 • • 發佈:2019-02-03
這周完全沒有想法要看棧式編碼器的,誰知誤入桃花源,就暫且把棧式自編碼器看了吧。由於手上有很多數值型的資料,僅僅是資料,沒有標籤,所以,迫切需要通過聚類抽出特徵。無意間看到別人家公司的推薦系統裡面用到sdae,於是,找了個ae程式,建了個sdae,跑一下自己的資料。希望sdae在後面的推薦系統中能有用。
斯坦福的這篇文章原理講的很到位了。
一.基本原理
AE的原理是先通過一個encode層對輸入進行編碼,這個編碼就是特徵,然後利用encode乘第2層引數(也可以是encode層的引數的轉置乘特徵並加偏執),重構(解碼)輸入,然後用重構的輸入和實際輸入的損失訓練引數。
對於我的應用來說,我要做的首先是抽取特徵。AE的encode的過程很簡單,是這樣的:
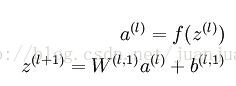
SAE是這樣的:
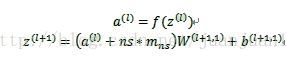
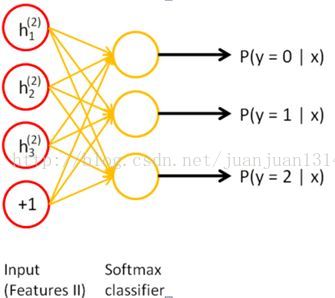
訓練過程中,兩個SAE分別訓練,第一個SAE訓練完之後,其encode的輸出作為第二個SAE的輸入,接著訓練。訓練完後,用第二層的特徵,通過softmax分類器(由於分類器 還是得要帶標籤的資料來訓練,所以,實際應用總,提取特徵後不一定是拿來分類),將所有特徵分為n類,得到n類標籤。訓練網路圖
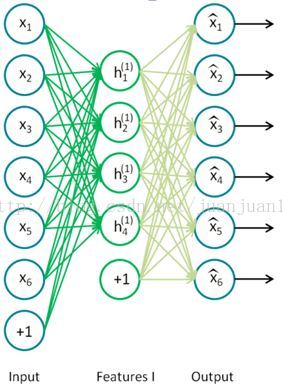
step 1
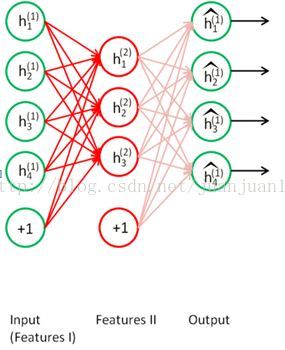
step 2
step 3
按照UFLDL的說明,在各自訓練到快要收斂的時候,要對整個網路通過反向傳播做微調,但是不能從一開始就整個網路調節。
兩個SAE訓練完後,每個encode的輸出作為兩個隱層的特徵,然後重新構建網路,新網路不做訓練,只做預測。網路如下:
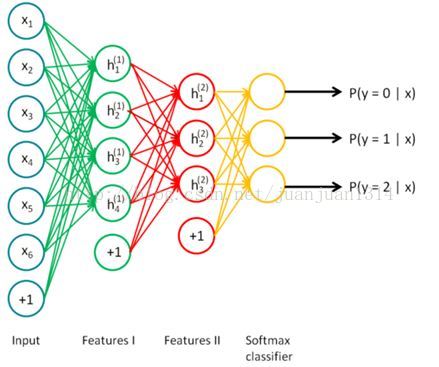
二.程式
1. 首先建立自編碼器的網路
採用新增高斯噪聲的dae,這是tensorflow 的models-master裡面提供的一種自編碼器。
#coding: utf-8 import tensorflow as tf import numpy as npimport Utilsclass AdditiveGaussianNoiseAutoencoder(object): def __init__(self, n_input, n_hidden, transfer_function = tf.nn.softplus, optimizer = tf.train.AdamOptimizer(), scale = 0.1): self.n_input = n_input self.n_hidden = n_hidden self.transfer = transfer_function self.scale = tf.placeholder(tf.float32) self.training_scale = scale network_weights = self._initialize_weights() self.weights = network_weights # model self.x = tf.placeholder(tf.float32, [None, self.n_input]) #編碼 self.hidden = self.transfer(tf.add(tf.matmul(self.x + scale * tf.random_normal((n_input,)), self.weights['w1']), self.weights['b1'])) #解碼 self.reconstruction = tf.add(tf.matmul(self.hidden, self.weights['w2']), self.weights['b2']) # cost self.cost = 0.5 * tf.reduce_sum(tf.pow(tf.sub(self.reconstruction, self.x), 2.0)) self.optimizer = optimizer.minimize(self.cost) init = tf.initialize_all_variables() self.sess = tf.Session() self.sess.run(init) def _initialize_weights(self): all_weights = dict() all_weights['w1'] = tf.Variable(Utils.xavier_init(self.n_input, self.n_hidden)) all_weights['b1'] = tf.Variable(tf.zeros([self.n_hidden], dtype = tf.float32)) all_weights['w2'] = tf.Variable(tf.zeros([self.n_hidden, self.n_input], dtype = tf.float32)) all_weights['b2'] = tf.Variable(tf.zeros([self.n_input], dtype = tf.float32)) return all_weights #優化引數 def partial_fit(self, X): cost, opt = self.sess.run((self.cost, self.optimizer), feed_dict = {self.x: X, self.scale: self.training_scale }) return cost def calc_total_cost(self, X): return self.sess.run(self.cost, feed_dict = {self.x: X, self.scale: self.training_scale }) def transform(self, X): return self.sess.run(self.hidden, feed_dict = {self.x: X, self.scale: self.training_scale }) def generate(self, hidden = None): if hidden is None: hidden = np.random.normal(size = self.weights["b1"]) return self.sess.run(self.reconstruction, feed_dict = {self.hidden: hidden}) def reconstruct(self, X): return self.sess.run(self.reconstruction, feed_dict = {self.x: X, self.scale: self.training_scale }) def getWeights(self): return self.sess.run(self.weights['w1']) def getBiases(self): return self.sess.run(self.weights['b1'])
2. sdae建立
#coding: utf-8
from __future__ import division, print_function, absolute_import
import numpy as np
import tensorflow as tf
from autoencoder_models.DenoisingAutoencoder import AdditiveGaussianNoiseAutoencoder
import prepare_data
#prepare_data.py是自己寫的資料整理檔案,通過這個檔案清理資料,並將其分成M-1份測試資料,1份測試資料
pd = prepare_data.TidyData(file1='data/dim_tv_mall_lng_lat.txt',
file2='data/ali-hdfs_2017-03-22_18-24-37.log',
M=8,
seed=12,
k=5)
pd.read_mall_location_np()
pd.calc_min_distance()
print ('data read finished!')
#定義訓練引數
training_epochs = 5
batch_size = 1000
display_step = 1
stack_size = 3 #棧中包含3個ae
hidden_size = [20, 20, 20]
input_n_size = [3, 200, 200]
def get_random_block_from_data(data, batch_size):
start_index = np.random.randint(0, len(data) - batch_size)
return data[start_index:(start_index + batch_size)]
#建立sdae圖
sdae = []
for i in xrange(stack_size):
if i == 0:
ae = AdditiveGaussianNoiseAutoencoder(n_input = 2,
n_hidden = hidden_size[i],
transfer_function = tf.nn.softplus,
optimizer = tf.train.AdamOptimizer(learning_rate = 0.001),
scale = 0.01)
ae._initialize_weights()
sdae.append(ae)
else:
ae = AdditiveGaussianNoiseAutoencoder(n_input=hidden_size[i-1],
n_hidden=hidden_size[i],
transfer_function=tf.nn.softplus,
optimizer=tf.train.AdamOptimizer(learning_rate=0.001),
scale=0.01)
ae._initialize_weights()
sdae.append(ae)
W = []
b = []
Hidden_feature = [] #儲存每個ae的特徵
X_train = np.array([0])
for j in xrange(stack_size):
#輸入
if j == 0:
X_train = np.array(pd.train_set)
X_test = np.array(pd.test_set)
else:
X_train_pre = X_train
X_train = sdae[j-1].transform(X_train_pre)
print (X_train.shape)
Hidden_feature.append(X_train)
#訓練
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(X_train.shape[1] / batch_size)
# Loop over all batches
for k in range(total_batch):
batch_xs = get_random_block_from_data(X_train, batch_size)
# Fit training using batch data
cost = sdae[j].partial_fit(batch_xs)
# Compute average loss
avg_cost += cost / X_train.shape[1] * batch_size
# Display logs per epoch step
#if epoch % display_step == 0:
print ("Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(avg_cost))
#儲存每個ae的引數
weight = sdae[j].getWeights()
#print (weight)
W.append(weight)
b.append(sdae[j].getBiases())