
MySQL B+樹索引和雜湊索引的區別
導讀
在MySQL裡常用的索引資料結構有B+樹索引和雜湊索引兩種,我們來看下這兩種索引資料結構的區別及其不同的應用建議。
二者區別
備註:先說下,在MySQL文件裡,實際上是把B+樹索引寫成了BTREE,例如像下面這樣的寫法:
CREATE TABLE t(
aid int unsigned not null auto_increment,
userid int unsigned not null default 0,
username varchar(20) not null default ‘’,
detail varchar(255) not null default ‘’,
primary key(aid),
unique key(uid) USING BTREE,
key (username(12)) USING BTREE — 此處 uname 列只建立了最左12個字元長度的部分索引
)engine=InnoDB;
一個經典的B+樹索引資料結構見下圖: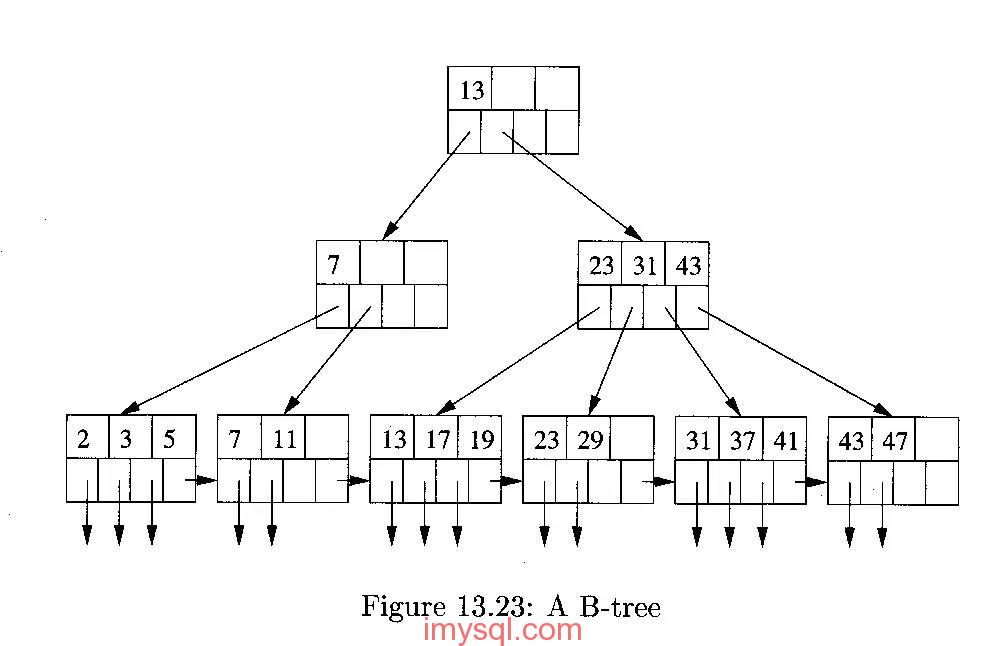
(圖片源自網路)
B+樹是一個平衡的多叉樹,從根節點到每個葉子節點的高度差值不超過1,而且同層級的節點間有指標相互連結。
在B+樹上的常規檢索,從根節點到葉子節點的搜尋效率基本相當,不會出現大幅波動,而且基於索引的順序掃描時,也可以利用雙向指標快速左右移動,效率非常高。
因此,B+樹索引被廣泛應用於資料庫、檔案系統等場景。順便說一下,xfs檔案系統比ext3/ext4效率高很多的原因之一就是,它的檔案及目錄索引結構全部採用B+樹索引,而ext3/ext4的檔案目錄結構則採用Linked list, hashed B-tree、Extents/Bitmap等索引資料結構,因此在高I/O壓力下,其IOPS能力不如xfs。
詳細可參見:
https://en.wikipedia.org/wiki/Ext4
https://en.wikipedia.org/wiki/XFS
而雜湊索引的示意圖則是這樣的: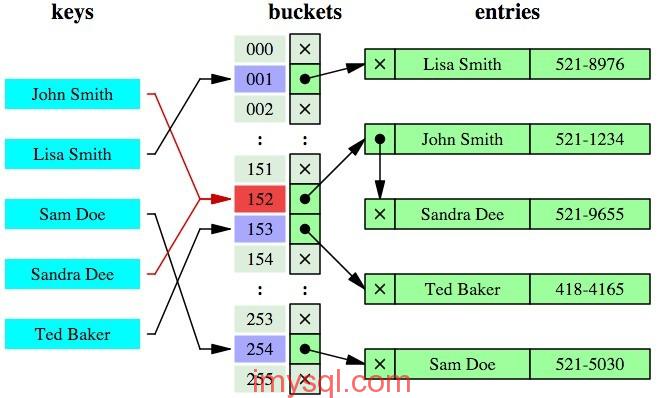
(圖片源自網路)
簡單地說,雜湊索引就是採用一定的雜湊演算法,把鍵值換算成新的雜湊值,檢索時不需要類似B+樹那樣從根節點到葉子節點逐級查詢,只需一次雜湊演算法即可立刻定位到相應的位置,速度非常快。
從上面的圖來看,B+樹索引和雜湊索引的明顯區別是:
-
如果是等值查詢,那麼雜湊索引明顯有絕對優勢,因為只需要經過一次演算法即可找到相應的鍵值;當然了,這個前提是,鍵值都是唯一的。如果鍵值不是唯一的,就需要先找到該鍵所在位置,然後再根據連結串列往後掃描,直到找到相應的資料;
-
從示意圖中也能看到,如果是範圍查詢檢索,這時候雜湊索引就毫無用武之地了,因為原先是有序的鍵值,經過雜湊演算法後,有可能變成不連續的了,就沒辦法再利用索引完成範圍查詢檢索;
-
同理,雜湊索引也沒辦法利用索引完成排序,以及like ‘xxx%’ 這樣的部分模糊查詢(這種部分模糊查詢,其實本質上也是範圍查詢);
-
雜湊索引也不支援多列聯合索引的最左匹配規則;
-
B+樹索引的關鍵字檢索效率比較平均,不像B樹那樣波動幅度大,在有大量重複鍵值情況下,雜湊索引的效率也是極低的,因為存在所謂的雜湊碰撞問題。
後記
在MySQL中,只有HEAP/MEMORY引擎表才能顯式支援雜湊索引(NDB也支援,但這個不常用),InnoDB引擎的自適應雜湊索引(adaptive hash index)不在此列,因為這不是建立索引時可指定的。
還需要注意到:HEAP/MEMORY引擎表在mysql例項重啟後,資料會丟失。
通常,B+樹索引結構適用於絕大多數場景,像下面這種場景用雜湊索引才更有優勢:
在HEAP表中,如果儲存的資料重複度很低(也就是說基數很大),對該列資料以等值查詢為主,沒有範圍查詢、沒有排序的時候,特別適合採用雜湊索引
例如這種SQL:
SELECT … FROM t WHERE C1 = ?; — 僅等值查詢
在大多數場景下,都會有範圍查詢、排序、分組等查詢特徵,用B+樹索引就可以了。
相關推薦
Mysql InnoDB B+樹索引和雜湊索引的區別? MongoDB 為什麼使用B-樹?
B-樹和B+樹最重要的一個區別就是B+樹只有葉節點存放資料,其餘節點用來索引,而B-樹是每個索引節點都會有Data域。 B+樹 B+樹是為磁碟及其他儲存輔助裝置而設計一種平衡查詢樹(不是二叉樹)。B+樹中,所有記錄的節點按大小順序存放在同一層的葉節點中,各葉
MySQL B+樹索引和雜湊索引的區別
導讀 在MySQL裡常用的索引資料結構有B+樹索引和雜湊索引兩種,我們來看下這兩種索引資料結構的區別及其不同的應用建議。 二者區別 備註:先說下,在MySQL文件裡,實際上是把B+樹索引寫成了BTREE,例如像下面這樣的寫法: CREATE TABLE t( a
MySQL索引 B+樹索引和雜湊索引的區別
備註:先說下,在MySQL文件裡,實際上是把B+樹索引寫成了BTREE,例如像下面這樣的寫法: CREATE TABLE t( aid int unsigned not null auto_increment, userid int unsigned no
Mysql B-tree索引和雜湊索引
hash 索引結構的特殊性,其檢索效率非常高,索引的檢索可以一次定位,不像B-Tree 索引需要從根節點到枝節點,最後才能訪問到頁節點這樣多次的IO訪問,所以 Hash 索引的查詢效率要遠高於 B-Tree 索引。 可 能很多人又有疑問了,既然 Hash 索引的效率要比
B樹索引、點陣圖索引、雜湊索引
create table btree_test(id number,code varchar2(10));create index idx_btree_test_id on btree_test(id,code);select object_id from user_objects where object_
雜湊索引和B+樹索引的區別
邏輯區別 hash演算法立刻定位 對應的hash筒的關鍵字 b+數可能會做3次IO 最大4次IO 最小的話直接記憶體取出結果 hash: 1.只能等值查詢不能排序 2.hash碰撞 3.不支援範圍排序 4.hash筒大了維護成本更大 大資料的情況下b+索引比hash索
MySQL B+樹索引和哈希索引的區別(轉 JD二面)
不同的應用 not null 效率比較 xxx apt link int data- 創建 導讀 在MySQL裏常用的索引數據結構有B+樹索引和哈希索引兩種,我們來看下這兩種索引數據結構的區別及其不同的應用建議。 二者區別 備註:先說下,在MySQL文檔裏,實際上是把B
MySQL B+樹索引和哈希索引的區別
掃描 pad 不同的 tab ble 這不 只需要 網絡 adapt 導讀 在MySQL裏常用的索引數據結構有B+樹索引和哈希索引兩種,我們來看下這兩種索引數據結構的區別及其不同的應用建議。 二者區別 備註:先說下,在MySQL文檔裏,實際上是把B+樹索引寫成了BTRE
MySQL索引演算法——雜湊演算法
雜湊索引 雜湊索引(hash index)基於雜湊表實現,只有精確匹配索引所有列的查詢才有效。對於每一行資料,儲存引擎都會對所有的索引列計算一個雜湊碼(hash code), 雜湊碼是一個較小的值,並且不同鍵值的行計算出來的雜湊碼也不一樣。雜湊索引將所
雜湊儲存、B樹儲存和LSM樹儲存引擎
1、雜湊儲存引擎 是雜湊表的持久化實現,支援增、刪、改以及隨機讀取操作,但不支援順序掃描,對應的儲存系統為key-value儲存系統。對於key-value的插入以及查詢,雜湊表的複雜度都是O(1),明顯比樹的操作O(n)快,如果不需要有序的遍歷資料,雜湊表就是your M
【資料結構之二叉樹】(一)B樹、B-樹、B+樹、B*樹介紹,和B+樹更適合做檔案索引的原因
今天看資料庫,書中提到:由於索引是採用 B 樹結構儲存的,所以對應的索引項並不會被刪除,經過一段時間的增刪改操作後,資料庫中就會出現大量的儲存碎片,這和磁碟碎片、記憶體碎片產生原理是類似的,這些儲存碎片不僅佔用了儲存空間,而且降低了資料庫執行的速度。如果發現索引
MySql B+樹索引
資料庫索引的資料結構: 採用的是B+Tree 檔案系統採用的是B-Tree 為什麼採用B+Tree 一般來說,索引本身也很大,不可能全部儲存在記憶體中,因此索引往往以索引檔案的形式儲存在磁碟上。這樣的話,索引查詢過程中就要產生磁碟I/O的消耗,所以評價一個索引的優
B+樹以及非聚簇索引和聚簇索引
1 B樹以及B+樹 1.1 B樹 是一種多路搜尋樹,假設為M叉樹 1. 每個節點中的關鍵字,比指向兒子的指標少一,即每個節點最多有M-1個關鍵字和M個指標 2. 關鍵字集合分佈在整棵樹中,任何一個關鍵字出現且只出現在一
mySql 雜湊索引的建立
① 索引適合創建於出現重複資料少的列名上,列的值衝突越多,代價越大。 ② SELECT ID FROM 表名 WHERE URL ="http://www.mysql.com"; 如果要新增索引的列值很長,可以在表中新增列,並用SRC32做雜湊,將很長的字串轉化成數字。 例
Oracle B樹索引和點陣圖索引、索引的說明和目的、索引碎片問題
B樹索引和點陣圖索引 索引是資料庫為了提高查詢效率提供的一種冗餘結構,保守計算資料庫50%以上的調優可以通過調整索引來進行優化; 引用國內一位資深的ORACLE專家的話:"我其實只懂點(挨踢)知識,IT裡面其實只懂點甲骨文,甲骨文裡面其實只懂點資料庫,資料庫裡面其實只懂點SQL,SQL裡面其實
MySQL 雜湊索引
雜湊索引基於雜湊表實現,只有精確匹配索引所有列的查詢才有效。對於每一行資料,儲存引擎都會對所有的索引列計算一個雜湊碼,雜湊碼是一個較小的值,並且不同鍵值計算出來的雜湊碼也不同。雜湊索引將所有雜湊碼存放在索引中,同時在雜湊表存放指向資料行的指標。 在雜湊索引中,採用桶(bu
oracle點知識8——索引聚簇和雜湊聚簇
原文整理自網路: Oracle支援兩種型別的聚簇: 索引聚簇和雜湊聚簇 1. 什麼是聚簇 聚簇是根據碼值找到資料的物理儲存位置,從而達到快速檢索資料的目的。聚簇索引的順序就是資料的物理儲存順序,葉節點就是資料節點。非聚簇索引的順序與資料物理排列順序無關,葉節點仍然是
好文 | MySQL 索引B+樹原理,以及建索引的幾大原則
MySQL事實上使用不同的儲存引擎也是有很大區別的,下面猿友們可以瞭解一下。 一、儲存引擎的比較 注:上面提到的B樹索引並
MySQL中的雜湊索引
Memory中的雜湊索引 雜湊索引是基於雜湊表實現的,只有精確匹配索引所有列的查詢才有效。對於每一行資料,儲存引擎都會對所有的索
在什麽情況下使用B-tree索引和哈希索引
聯合 not gpo 情況 b-tree索引 精確 限制 匹配 date 在什麽情況下可以使用B-tree索引 1、全值匹配的查詢 order_sn=‘987654321000‘; 2、匹配最左前綴的查詢 order_sn order_date 聯合索引,第一列可以利用索引