
MySQL 雜湊索引
雜湊索引基於雜湊表實現,只有精確匹配索引所有列的查詢才有效。對於每一行資料,儲存引擎都會對所有的索引列計算一個雜湊碼,雜湊碼是一個較小的值,並且不同鍵值計算出來的雜湊碼也不同。雜湊索引將所有雜湊碼存放在索引中,同時在雜湊表存放指向資料行的指標。
在雜湊索引中,採用桶(bucket)來表示一條或多條記錄的儲存單元。令K表示搜尋碼的集合,B表示所有桶地址的集合。雜湊函式h是一個從K中的找出B中的一個桶地址。
插入一條搜尋碼為的資料行,計算,得出一個雜湊碼,該雜湊碼能夠索引到能夠存放該資料行的桶的地址,如果桶不滿。
搜尋一條搜尋碼為的資料行,計算,得出一個雜湊碼,該雜湊碼能夠索引該資料行所存放桶的地址。如果有兩個搜尋碼和,它們計算的雜湊碼一致,如果該雜湊碼索引的桶能夠存放這兩個資料行,則在索引到的桶中查詢和 。
在MySQL中,只有Memory引擎顯示支援雜湊索引,這也是Memory引擎搜尋表的預設索引型別。
有如下表:
+-----+-------+-------+CREATE DATABASE Student; CREATE TABLE Student ( id int NOT NULL , name char(10) NOT NULL , score float(1) NULL , KEY USING HASH(id) )ENGINE=MEMORY; INSERT INTO Student ( id,name,score ) VALUES ( 78, 'Crick',97.6 ), ( 125,'Katz', 85.3 ), ( 634,'Gold', 66.6 );
| id | name | score |
+-----+-------+-------+
| 78 | Crick | 97.6 |
| 125 | Katz | 85.3 |
| 634 | Gold | 66.6 |
+-----+-------+-------+
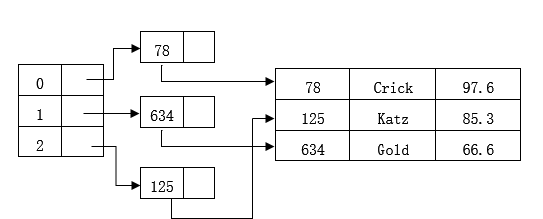
主鍵id採用雜湊索引的方式,因此假設進行對id計算後得到的hash code如下:
h(78)= 0;
h(125) = 2;
h(634) = 1;
採用雜湊表的方式進行儲存
如果此時插入一行且該主鍵的計算出的雜湊碼的值與前面的某行計算出的雜湊
碼一致,會產生雜湊衝突。例如:
h(35) = 2
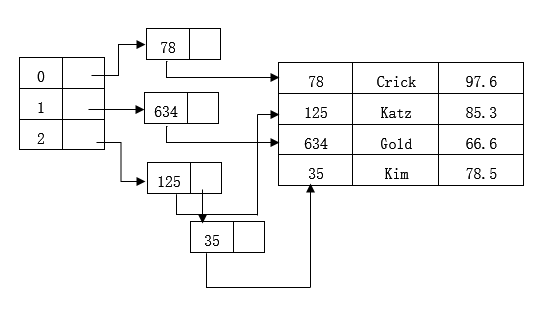
查詢id=35的資料行,計算35的雜湊碼,根據雜湊碼索引出該資料行的指標,但是該雜湊碼對應的兩個按照鏈式儲存的資料行指標,還需要在該鏈上進行查詢。
也可以採用桶進行儲存,假設每個桶能儲存三個資料行的指標,如果每個資料行的主鍵計算所得雜湊碼相同,存放在一個桶中。如果發生桶溢位,則會在該桶後面以鏈式進行連結一個溢位桶。溢位桶大小與剛才的桶一致。
雜湊索引並不是按照索引值索引值順序儲存,所以也就無法用於排序。
雜湊索引也不支援部分索引列匹配查詢,因為雜湊索引始終使用索引列的全部內容來計算雜湊值的。
雜湊索引只支援等值比較查詢,包括=,IN,<=>,也不支援範圍查詢。
當出現雜湊衝突時,儲存引擎必須遍歷連結串列所有資料行指標,逐行比較,直到找出符合條件的資料行。
如果雜湊衝突很多,一些索引維護操作代價也很高。
相關推薦
mySql 雜湊索引的建立
① 索引適合創建於出現重複資料少的列名上,列的值衝突越多,代價越大。 ② SELECT ID FROM 表名 WHERE URL ="http://www.mysql.com"; 如果要新增索引的列值很長,可以在表中新增列,並用SRC32做雜湊,將很長的字串轉化成數字。 例
MySQL 雜湊索引
雜湊索引基於雜湊表實現,只有精確匹配索引所有列的查詢才有效。對於每一行資料,儲存引擎都會對所有的索引列計算一個雜湊碼,雜湊碼是一個較小的值,並且不同鍵值計算出來的雜湊碼也不同。雜湊索引將所有雜湊碼存放在索引中,同時在雜湊表存放指向資料行的指標。 在雜湊索引中,採用桶(bu
Mysql InnoDB B+樹索引和雜湊索引的區別? MongoDB 為什麼使用B-樹?
B-樹和B+樹最重要的一個區別就是B+樹只有葉節點存放資料,其餘節點用來索引,而B-樹是每個索引節點都會有Data域。 B+樹 B+樹是為磁碟及其他儲存輔助裝置而設計一種平衡查詢樹(不是二叉樹)。B+樹中,所有記錄的節點按大小順序存放在同一層的葉節點中,各葉
MySQL B+樹索引和雜湊索引的區別
導讀 在MySQL裡常用的索引資料結構有B+樹索引和雜湊索引兩種,我們來看下這兩種索引資料結構的區別及其不同的應用建議。 二者區別 備註:先說下,在MySQL文件裡,實際上是把B+樹索引寫成了BTREE,例如像下面這樣的寫法: CREATE TABLE t( a
MySQL索引 B+樹索引和雜湊索引的區別
備註:先說下,在MySQL文件裡,實際上是把B+樹索引寫成了BTREE,例如像下面這樣的寫法: CREATE TABLE t( aid int unsigned not null auto_increment, userid int unsigned no
Mysql B-tree索引和雜湊索引
hash 索引結構的特殊性,其檢索效率非常高,索引的檢索可以一次定位,不像B-Tree 索引需要從根節點到枝節點,最後才能訪問到頁節點這樣多次的IO訪問,所以 Hash 索引的查詢效率要遠高於 B-Tree 索引。 可 能很多人又有疑問了,既然 Hash 索引的效率要比
MySQL中的雜湊索引
Memory中的雜湊索引 雜湊索引是基於雜湊表實現的,只有精確匹配索引所有列的查詢才有效。對於每一行資料,儲存引擎都會對所有的索
雜湊索引和B+樹索引的區別
邏輯區別 hash演算法立刻定位 對應的hash筒的關鍵字 b+數可能會做3次IO 最大4次IO 最小的話直接記憶體取出結果 hash: 1.只能等值查詢不能排序 2.hash碰撞 3.不支援範圍排序 4.hash筒大了維護成本更大 大資料的情況下b+索引比hash索
關於Hash 函式 雜湊索引表 解決位置衝突的問題
最近要用到關於hash表和hash函式,建立索引的方法 主要用於資料的查詢和資料的儲存 ,現在主要不太理解的地方在於如何解決位置衝突的問題。先把收集的資料貼在這裡 處理問題和解決問題的能力有待加強,主要是還不夠淡定,一遇到沒有解決過的問題就會很慌!
InnoDB儲存引擎——自適應雜湊索引
雜湊(hash)是一種非常快的查詢方法,在一般情況下這種查詢的時間複雜度為O(1),即一般僅需要一次查詢就能定位資料。 而B+樹的查詢次數,取決於B+樹的高度,在生產環境中,B+樹的高度一般為3~4層,所以需要3~4次的查詢。 InnoDB儲存引擎會監控對錶
B樹索引、點陣圖索引、雜湊索引
create table btree_test(id number,code varchar2(10));create index idx_btree_test_id on btree_test(id,code);select object_id from user_objects where object_
MySQL索引演算法——雜湊演算法
雜湊索引 雜湊索引(hash index)基於雜湊表實現,只有精確匹配索引所有列的查詢才有效。對於每一行資料,儲存引擎都會對所有的索引列計算一個雜湊碼(hash code), 雜湊碼是一個較小的值,並且不同鍵值的行計算出來的雜湊碼也不一樣。雜湊索引將所
順序 鏈式 索引 雜湊儲存
儲存結構分四類:順序儲存、鏈式儲存、索引儲存和雜湊儲存。 順序結構和連結結構適用在記憶體結構中。 索引結構和雜湊結構適用在外存與記憶體互動結構。 順序儲存:在計算機中用一組地址連續的儲存單元依次儲存線性表的各個資料元素,稱作線性表的順序儲存結構。 特點: 1、隨機存取表中元素
資料庫索引(B樹,B+樹,雜湊)
資料庫索引是儲存引擎用於快速找到記錄的一種資料結構。 《高效能MySQL》 一. 什麼是索引?
四種資料儲存結構---順序儲存 連結儲存 索引儲存 雜湊儲存
儲存結構分四類:順序儲存、連結儲存、索引儲存 和 雜湊儲存。 順序結構和連結結構適用在記憶體結構中。 索引結構和雜湊結構適用在外存與記憶體互動結構。 順序儲存:在計算機中用一組地址連續的儲存單元依次儲存線性表的各個資料元素,稱作線性表的順序儲存結構。 特
資料結構 索引結構與雜湊
知識要點: 線性索引結構、倒排表、靜態搜尋樹的結構和特點; B樹的結構;(B-樹,B+樹) 雜湊的實現原理和各種操作的實現演算法。(Hash表,平均查詢長度(成功、失敗)) 1.雜湊函式和雜湊地址:記錄存取位置P和關鍵字Key之間的對應關係,有P=Function(K
C#:索引器用法、集合(動態陣列,堆疊,佇列,雜湊表)用法、指標(fixed關鍵字)用法
1.索引器用法 http://www.runoob.com/csharp/csharp-indexer.html 2.集合用法 http://www.runoob.com/csharp/csharp-collection.html 3.指標用法
mysql主從複製、讀寫分離到資料庫水平拆分及庫表雜湊
web專案最原始的情況是一臺伺服器只能連線一個mysql伺服器(c3p0只能配置一個mysql),但隨著專案的增大,這種方案明顯已經不能滿足需求了。Mysql主從複製,讀寫分離:上面的方案使用mysql-Proxy代理,分發讀寫請求,寫操作轉發到Mysql主伺服器,讀操作轉發
Mysql千萬資料級分表設計及實現方案(2)附一致性雜湊原理解析
首先,接著上篇博文:Mysql千萬資料級分表設計及實現方案已經分析了自增id作分表key和全域性服務id(16位)作分表key進行分表的兩種設計方案。自增id優勢在於簡單,直接雜湊取模即可分表完成。根據
查詢演算法,簡單查詢,二叉排序樹,索引查詢,雜湊表
利用了元素間的次序關係,採用分治策略,可在最壞的情況下用O(log n)完成搜尋任務。它的基本思想是,將n個元素分成個數大致相同的兩半,取a[n/2]與欲查詢的x作比較,如果x=a[n/2]則找到x,演算法終止。如 果x<a[n/2],則我們只要在陣列a的左半部繼續搜尋x(這裡假設陣列元素呈升序排列)