
決策樹模型入門學習
一:基本介紹
決策樹模型就是為了求出一系列規則,按照規則劃分資料,得到預測結果。可以把決策樹看做有決策塊和終止塊組成,如下圖:
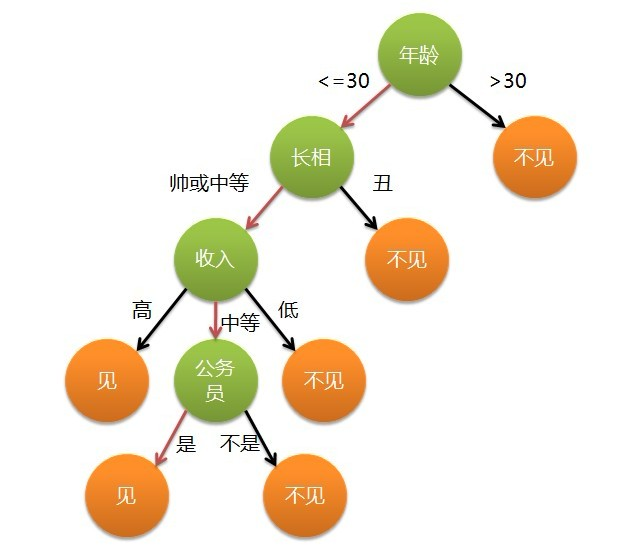
上圖圖是女孩對是否與男生見面的決策過程,典型的分類樹決策。相當於通過年齡、長相、收入和是否公務員對將男人分為兩個類別:見和不見。假設這個女孩對男人的要求是:30歲以下、長相中等以上並且是高收入者或中等以上收入的公務員,那麼這個可以用下圖表示女孩的決策邏輯。
二:為什麼需要決策樹
那麼在處理資料問題中我們為什麼會選用決策樹模型?
下面介紹決策樹的優點:
1、決策樹易於理解和解釋.人們在通過解釋後都有能力去理解決策樹所表達的意義。
2、 對於決策樹,資料的準備往往是簡單或者是不必要的.其他的技術往往要求先把資料一般化,比如去掉多餘的或者空白的屬性。
3、 能夠同時處理資料型和常規型屬性。其他的技術往往要求資料屬性的單一。
4、 決策樹是一個白盒模型。如果給定一個觀察的模型,那麼根據所產生的決策樹很容易推出相應的邏輯表示式。
5、 易於通過靜態測試來對模型進行評測。表示有可能測量該模型的可信度。
6、 在相對短的時間內能夠對大型資料來源做出可行且效果良好的結果。
7、 可以對有許多屬性的資料集構造決策樹。
8、決策樹可很好地擴充套件到大型資料庫中,同時它的大小獨立於資料庫的大小。
三、決策樹建模過程及常用模型
決策樹的工作過程一般可以分為三步:
1、特徵選擇
2、決策樹生成
3、剪枝
下面結合具體的幾個決策樹模型來鞏固掌握的知識:
1、ID3:
根據資訊增益進行特徵選擇,這就涉及到資訊熵的概念,資訊熵描述的是資料的混亂程度,資訊增益描述的加入特徵後資料混亂程度的減小程度,所以資訊增益的值等於資訊熵減去條件熵的值。

每一步選擇資訊增益最大的特徵作為決策塊,最終生成決策樹。
ID3模型沒有剪枝部分。
2、C4.5
C4.5是對ID3的改進,ID3只可以處理標稱型資料,沒有剪枝過程容易過擬合。C4.5的特徵選擇依據資訊增益率進行,

每次選擇資訊增益率最高的特徵作為決策塊。
C4.5的剪枝可以根據最小化損失函式策略進行。
3、cart樹
cart(classification and regression tree)分類迴歸樹,同樣有特徵選擇、樹的生成和剪枝。當cart為迴歸樹時,特徵選擇按照最小化誤差平方和進行,選擇使誤差平方和最小的特徵作為切分點,以此規則不斷生成樹。當cart為分類樹時,按照基尼指數進行特徵選擇,公式如下:

在樹的生成過程中,在所有可能的特徵A以及它們所有可能的切分點a中選擇基尼係數最小的特徵及其對應的切分點作為最優特徵與最優切分點。
對於cart樹的剪枝,cart剪枝演算法從“完全生長”的決策樹的底端減去一些子樹,使決策樹變小,從而能夠對未知資料有更準確的預測。cart剪枝演算法由兩步組成:首先從生成演算法產生的決策樹底端開始不斷剪枝,直到根節點,形成一個子樹序列;然後通過交叉驗證法在獨立的驗證資料集上對子樹序列進行驗證,從中選擇最優子樹。
四、決策樹的不足
決策樹的缺點:
1、 對於那些各類別樣本數量不一致的資料,在決策樹當中,資訊增益的結果偏向於那些具有更多數值的特徵。
2、決策樹處理缺失資料時的困難。
3、過度擬合問題的出現。
4、忽略資料集中屬性之間的相關性。
相關推薦
決策樹模型入門學習
一:基本介紹 決策樹模型就是為了求出一系列規則,按照規則劃分資料,得到預測結果。可以把決策樹看做有決策塊和終止塊組成,如下圖: 上圖圖是女孩對是否與男生見面的決策過程,典型的分類樹決策。相當於通過年齡、長相、收入和是否公務員對將男人分為兩個類別:見和不
決策樹模型與學習《一》
ini 相親 tor ext 測試的 select port RR rand html { } :root { } html { font-size: 14px; background-color: var(--bg-color); color: var(--tex
《深度實踐Spark機器學習 》第11章 pyspark決策樹模型
由於此書不配程式碼,以下程式碼都是本寶寶在ipynb測試過的,執行環境為hdp2.6.2和Anaconda2。完整ipynb和py程式碼地址:https://gitee.com/iscas/deep_spark_ml/tree/master11.3 資料載入刪除標題sed 1
Python資料分析與機器學習-使用sklearn構造決策樹模型
# datasets包括內建的資料集 california_housing房價的資料集 from sklearn.datasets.california_housing import fetch_california_housing import pandas as pd
李航《統計學習方法》——第五章 決策樹模型
由於網上資料很多,這裡就不再對演算法原理進行推導,僅給出博主用Python實現的程式碼,供大家參考 適用問題:多類分類 三個步驟:特徵選擇、決策樹的生成和決策樹的剪枝 常見的決策樹演算法有: ID3:特徵劃分基於資訊增益 C4.5:特徵劃分基於資訊增益
大資料入門——使用決策樹模型預測泰坦尼克號乘客的生還情況
#資料查驗 import pandas as pd titanic=pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataS
機器學習之使用sklearn構造決策樹模型
一、任務基礎 匯入所需要的庫 import matplotlib.pyplot as plt import pandas as pd %matplotlib inline 載入sklearn內建資料集 ,檢視資料描述 from sklearn.datasets.californ
深入瞭解機器學習決策樹模型——C4.5演算法
本文始發於個人公眾號:**TechFlow**,原創不易,求個關注 今天是機器學習專題的第22篇文章,我們繼續決策樹的話題。 上一篇文章當中介紹了一種最簡單構造決策樹的方法——ID3演算法,也就是每次選擇一個特徵進行拆分資料。這個特徵有多少個取值那麼就劃分出多少個分叉,整個建樹的過程非常簡單。如果錯過了上篇
決策樹模型組合之隨機森林與GBDT(轉)
get 9.png 生成 代碼 margin ast decision 損失函數 固定 版權聲明: 本文由LeftNotEasy發布於http://leftnoteasy.cnblogs.com, 本文可以被全部的轉載或者部分使用,但請註明出處,如果有問題,請
R_針對churn資料用id3、cart、C4.5和C5.0建立決策樹模型進行判斷哪種模型更合適
data(churn)匯入自帶的訓練集churnTrain和測試集churnTest 用id3、cart、C4.5和C5.0建立決策樹模型,並用交叉矩陣評估模型,針對churn資料,哪種模型更合適 決策樹模型 ID3/C4.5/CART演算法比較 傳送門
基於決策樹模型對 IRIS 資料集分類
基於決策樹模型對 IRIS 資料集分類 文章目錄 基於決策樹模型對 IRIS 資料集分類 1 python 實現 載入資料集 視覺化資料集 分類和預測 計算準確率 2 基於MATLA
利用Python sklearn庫裡的決策樹模型生成決策樹圖片以及測試分類的準確度
本案例利用sklearn自帶的資料集,選取房子經緯度作為特徵引數來對標籤進行分類。 也用切分的資料訓練模型來進行特徵引數的選擇得到最好的測試準確度。 Python原始碼: #!/usr/bin/env python # encoding: utf-8 """ @Company:華中科技大
客戶貸款逾期預測[2]-svm和決策樹模型
任務 本次以信用貸款資料作為練習資料,目的是學會使用常用的機器學習模型,用它們預測貸款客戶是否會逾期,給到的資料已經包含了標籤,列名是status,有0和1兩種值,0表示未逾期,1表示逾期,所以這是一個二分類的問題。 資料處理 &n
決策樹模型
1.概述 決策樹是一種簡單的機器學習方法,它是對被觀測資料進行分類的一種相當直觀的方法。 優點:計算複雜度不高,輸出結果易於理解,對中間值的缺失不敏感,可以處理不相關特徵資料。 缺點:可能會產生過度匹配問題。 適用資料型別:數值型和標稱型。 2.決策樹的構造 決策樹
決策樹模型 ID3/C4.5/CART演算法比較
決策樹模型在監督學習中非常常見,可用於分類(二分類、多分類)和迴歸。雖然將多棵弱決策樹的Bagging、Random Forest、Boosting等tree ensembel 模型更為常見,但是“完全生長”決策樹因為其簡單直觀,具有很強的解釋性,也有廣泛的應用,而且決策樹是
決策樹模型(R語言)
R語言中最常用於實現決策樹的有兩個包,分別是rpart包和party包,其區別如下: rpart包的處理方式:首先對所有自變數和所有分割點進行評估,最佳的選擇是使分割後組內的資料更為“一致”(pure)。這裡的“一致”是指組內資料的因變數取值變異較小。rpart包對這種“一
決策樹系列之一決策樹的入門教程
決策樹 (Decisiontree) 一、決策樹的概念 決策樹(decision tree)又稱為分類樹(classification tree),決策樹是最為廣泛的歸納推理演算法之一,處理類別型或連續型變數的分類預測問題,可以用圖形和if-then的規則表示模型,可讀性較
r語言做決策樹模型(少廢話版本)
#第1步:工作目錄和資料集的準備 setwd("C:/Users/IBM/Desktop/170222分類樹建模/2.23建模")#設定當前的工作目錄,重要! audit2<-read.csv("model2.csv",header=T) str(audit2) #轉
決策樹基本理論學習以及Python程式碼實現和詳細註釋
首先是樹的概念我們都比較熟悉了,然後決策樹其實就是一棵樹,通過在每一個幾點通過特徵的不同,走向不同的子樹直到走到葉子節點找到分類的標籤,算是完成了分類的過程。分類的過程不難理解,主要的是資料構造過程。 首先是構造的依據是什麼呢,以什麼依據作為特徵使用的選擇條件
R語言練習-利用決策樹模型分析泰坦尼克生還率(1)
R語言練習-利用決策樹模型分析泰坦尼克生還率 一、資料預處理 列名 含義 pclass 將1/2/3等艙分別儲存在1/2/3 survived 是否生還 name 姓名 sex 性別