
自然語言處理(NLP)入門
本文簡要介紹Python自然語言處理(NLP),使用Python的NLTK庫。NLTK是Python的自然語言處理工具包,在NLP領域中,最常使用的一個Python庫。
什麼是NLP?
簡單來說,自然語言處理(NLP)就是開發能夠理解人類語言的應用程式或服務。
這裡討論一些自然語言處理(NLP)的實際應用例子,如語音識別、語音翻譯、理解完整的句子、理解匹配詞的同義詞,以及生成語法正確完整句子和段落。
這並不是NLP能做的所有事情。
NLP實現
搜尋引擎: 比如谷歌,Yahoo等。谷歌搜尋引擎知道你是一個技術人員,所以它顯示與技術相關的結果;
社交網站推送:比如Facebook News Feed。如果News Feed演算法知道你的興趣是自然語言處理,就會顯示相關的廣告和帖子。
語音引擎:比如Apple的Siri。
垃圾郵件過濾:如谷歌垃圾郵件過濾器。和普通垃圾郵件過濾不同,它通過了解郵件內容裡面的的深層意義,來判斷是不是垃圾郵件。
NLP庫
下面是一些開源的自然語言處理庫(NLP):
Natural language toolkit (NLTK);
Apache OpenNLP;
Stanford NLP suite;
Gate NLP library
其中自然語言工具包(NLTK)是最受歡迎的自然語言處理庫(NLP),它是用Python編寫的,而且背後有非常強大的社群支援。
NLTK也很容易上手,實際上,它是最簡單的自然語言處理(NLP)庫。
在這個NLP教程中,我們將使用Python NLTK庫。
安裝 NLTK
如果您使用的是Windows/Linux/Mac,您可以使用pip安裝NLTK:
pip install nltk開啟python終端匯入NLTK檢查NLTK是否正確安裝:
import nltk如果一切順利,這意味著您已經成功地安裝了NLTK庫。首次安裝了NLTK,需要通過執行以下程式碼來安裝NLTK擴充套件包:
import nltk
nltk.download()這將彈出NLTK 下載視窗來選擇需要安裝哪些包:
您可以安裝所有的包,因為它們的大小都很小,所以沒有什麼問題。
使用Python Tokenize文字
首先,我們將抓取一個web頁面內容,然後分析文字瞭解頁面的內容。
我們將使用urllib模組來抓取web頁面:
import urllib.request
response = urllib.request.urlopen('http://php.net/')
html = response.read()
print (html)從列印結果中可以看到,結果包含許多需要清理的HTML標籤。
然後BeautifulSoup模組來清洗這樣的文字:
from bs4 import BeautifulSoup
import urllib.request
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")這需要安裝html5lib模組
text = soup.get_text(strip=True)
print (text)現在我們從抓取的網頁中得到了一個乾淨的文字。
下一步,將文字轉換為tokens,像這樣:
from bs4 import BeautifulSoup
import urllib.request
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = text.split()
print (tokens)統計詞頻
text已經處理完畢了,現在使用Python NLTK統計token的頻率分佈。
可以通過呼叫NLTK中的FreqDist()方法實現:
from bs4 import BeautifulSoup
import urllib.request
import nltk
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = text.split()
freq = nltk.FreqDist(tokens)
for key,val in freq.items():
print (str(key) + ':' + str(val))
如果搜尋輸出結果,可以發現最常見的token是PHP。
您可以呼叫plot函式做出頻率分佈圖:
freq.plot(20, cumulative=False)
# 需要安裝matplotlib庫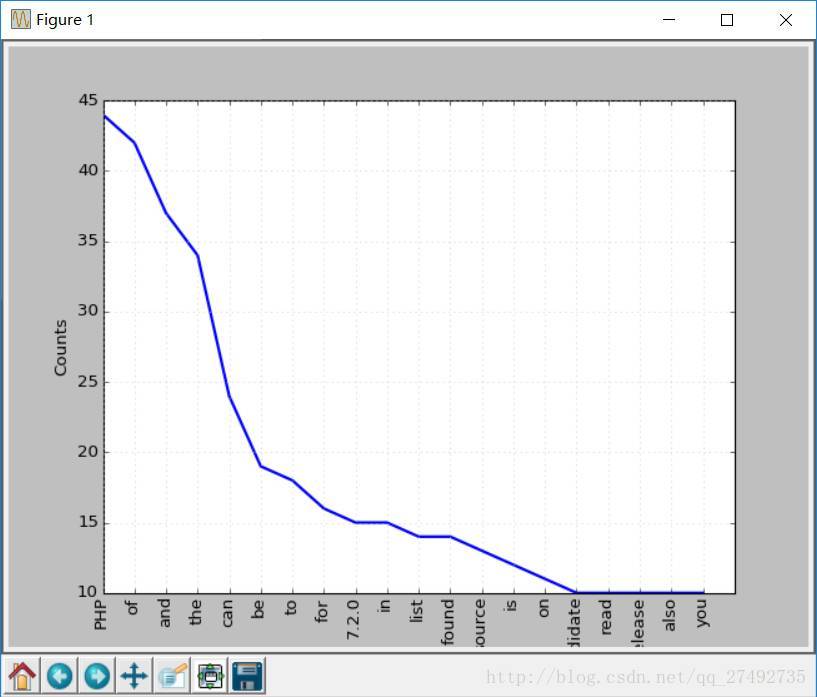
這上面這些單詞。比如of,a,an等等,這些詞都屬於停用詞。
一般來說,停用詞應該刪除,防止它們影響分析結果。
處理停用詞
NLTK自帶了許多種語言的停用詞列表,如果你獲取英文停用詞:
from nltk.corpus import stopwords
stopwords.words('english')現在,修改下程式碼,在繪圖之前清除一些無效的token:
clean_tokens = list()
sr = stopwords.words('english')
for token in tokens:
if token not in sr:
clean_tokens.append(token)最終的程式碼應該是這樣的:
from bs4 import BeautifulSoup
import urllib.request
import nltk
from nltk.corpus import stopwords
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = text.split()
clean_tokens = list()
sr = stopwords.words('english')
for token in tokens:
if not token in sr:
clean_tokens.append(token)
freq = nltk.FreqDist(clean_tokens)
for key,val in freq.items():
print (str(key) + ':' + str(val))現在再做一次詞頻統計圖,效果會比之前好些,因為剔除了停用詞:
freq.plot(20,cumulative=False)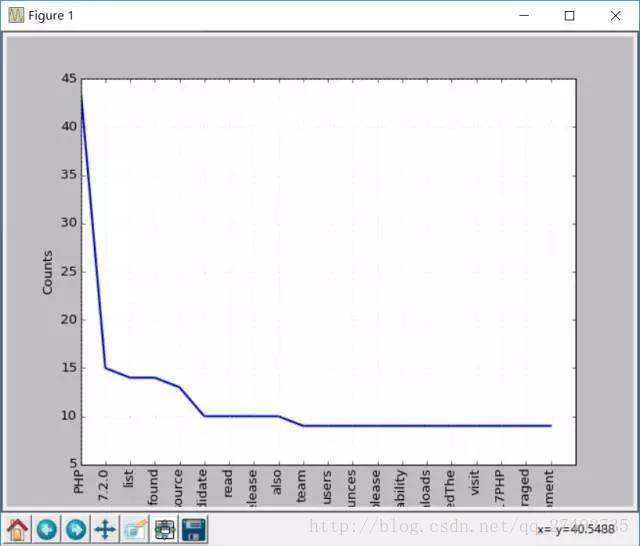
使用NLTK Tokenize文字
在之前我們用split方法將文字分割成tokens,現在我們使用NLTK來Tokenize文字。
文字沒有Tokenize之前是無法處理的,所以對文字進行Tokenize非常重要的。token化過程意味著將大的部件分割為小部件。
你可以將段落tokenize成句子,將句子tokenize成單個詞,NLTK分別提供了句子tokenizer和單詞tokenizer。
假如有這樣這段文字:
Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude使用句子tokenizer將文字tokenize成句子:
from nltk.tokenize import sent_tokenize
mytext = "Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(sent_tokenize(mytext))輸出如下:
['Hello Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']這是你可能會想,這也太簡單了,不需要使用NLTK的tokenizer都可以,直接使用正則表示式來拆分句子就行,因為每個句子都有標點和空格。
那麼再來看下面的文字:
Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude.這樣如果使用標點符號拆分,Hello Mr將會被認為是一個句子,如果使用NLTK:
from nltk.tokenize import sent_tokenize
mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(sent_tokenize(mytext))輸出如下:
['Hello Mr. Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']這才是正確的拆分。
接下來試試單詞tokenizer:
from nltk.tokenize import word_tokenize
mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(word_tokenize(mytext))輸出如下:
['Hello', 'Mr.', 'Adam', ',', 'how', 'are', 'you', '?', 'I', 'hope', 'everything', 'is', 'going', 'well', '.', 'Today', 'is', 'a', 'good', 'day', ',', 'see', 'you', 'dude', '.']Mr.這個詞也沒有被分開。NLTK使用的是punkt模組的PunktSentenceTokenizer,它是NLTK.tokenize的一部分。而且這個tokenizer經過訓練,可以適用於多種語言。
非英文Tokenize
Tokenize時可以指定語言:
from nltk.tokenize import sent_tokenize
mytext = "Bonjour M. Adam, comment allez-vous? J'espère que tout va bien. Aujourd'hui est un bon jour."
print(sent_tokenize(mytext,"french"))輸出結果如下:
['Bonjour M. Adam, comment allez-vous?', "J'espère que tout va bien.", "Aujourd'hui est un bon jour."]同義詞處理
使用nltk.download()安裝介面,其中一個包是WordNet。
WordNet是一個為自然語言處理而建立的資料庫。它包括一些同義詞組和一些簡短的定義。
您可以這樣獲取某個給定單詞的定義和示例:
from nltk.corpus import wordnet
syn = wordnet.synsets("pain")
print(syn[0].definition())
print(syn[0].examples())輸出結果是:
a symptom of some physical hurt or disorder
['the patient developed severe pain and distension']WordNet包含了很多定義:
from nltk.corpus import wordnet
syn = wordnet.synsets("NLP")
print(syn[0].definition())
syn = wordnet.synsets("Python")
print(syn[0].definition())結果如下:
the branch of information science that deals with natural language information
large Old World boas
可以像這樣使用WordNet來獲取同義詞:
from nltk.corpus import wordnet
synonyms = []
for syn in wordnet.synsets('Computer'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)輸出:
['computer', 'computing_machine', 'computing_device', 'data_processor', 'electronic_computer', 'information_processing_system', 'calculator', 'reckoner', 'figurer', 'estimator', 'computer']反義詞處理
也可以用同樣的方法得到反義詞:
from nltk.corpus import wordnet
antonyms = []
for syn in wordnet.synsets("small"):
for l in syn.lemmas():
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
print(antonyms)
輸出:
['large', 'big', 'big']詞幹提取
語言形態學和資訊檢索裡,詞幹提取是去除詞綴得到詞根的過程,例如working的詞幹為work。
搜尋引擎在索引頁面時就會使用這種技術,所以很多人為相同的單詞寫出不同的版本。
有很多種演算法可以避免這種情況,最常見的是波特詞幹演算法。NLTK有一個名為PorterStemmer的類,就是這個演算法的實現:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem('working'))
print(stemmer.stem('worked'))輸出結果是:
work
work還有其他的一些詞幹提取演算法,比如 Lancaster詞幹演算法。
非英文詞幹提取
除了英文之外,SnowballStemmer還支援13種語言。
支援的語言:
from nltk.stem import SnowballStemmer
print(SnowballStemmer.languages)
'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish'你可以使用SnowballStemmer類的stem函式來提取像這樣的非英文單詞:
from nltk.stem import SnowballStemmer
french_stemmer = SnowballStemmer('french')
print(french_stemmer.stem("French word"))單詞變體還原
單詞變體還原類似於詞幹,但不同的是,變體還原的結果是一個真實的單詞。不同於詞幹,當你試圖提取某些詞時,它會產生類似的詞:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem('increases'))結果:
increas現在,如果用NLTK的WordNet來對同一個單詞進行變體還原,才是正確的結果:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('increases'))結果:
increase結果可能會是一個同義詞或同一個意思的不同單詞。
有時候將一個單詞做變體還原時,總是得到相同的詞。
這是因為語言的預設部分是名詞。要得到動詞,可以這樣指定:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))結果:
play實際上,這也是一種很好的文字壓縮方式,最終得到文字只有原先的50%到60%。
結果還可以是動詞(v)、名詞(n)、形容詞(a)或副詞(r):
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
print(lemmatizer.lemmatize('playing', pos="n"))
print(lemmatizer.lemmatize('playing', pos="a"))
print(lemmatizer.lemmatize('playing', pos="r"))
輸出:
play
playing
playing
playing
詞幹和變體的區別
通過下面例子來觀察:
from nltk.stem import WordNetLemmatizer
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
print(stemmer.stem('stones'))
print(stemmer.stem('speaking'))
print(stemmer.stem('bedroom'))
print(stemmer.stem('jokes'))
print(stemmer.stem('lisa'))
print(stemmer.stem('purple'))
print('----------------------')
print(lemmatizer.lemmatize('stones'))
print(lemmatizer.lemmatize('speaking'))
print(lemmatizer.lemmatize('bedroom'))
print(lemmatizer.lemmatize('jokes'))
print(lemmatizer.lemmatize('lisa'))
print(lemmatizer.lemmatize('purple'))
輸出:
stone
speak
bedroom
joke
lisapurpl
stone
speaking
bedroom
joke
lisa
purple詞幹提取不會考慮語境,這也是為什麼詞幹提取比變體還原快且準確度低的原因。
個人認為,變體還原比詞幹提取更好。單詞變體還原返回一個真實的單詞,即使它不是同一個單詞,也是同義詞,但至少它是一個真實存在的單詞。
如果你只關心速度,不在意準確度,這時你可以選用詞幹提取。
在此NLP教程中討論的所有步驟都只是文字預處理。在以後的文章中,將會使用Python NLTK來實現文字分析。
我已經儘量使文章通俗易懂。希望能對你有所幫助。
相關推薦
自然語言處理(NLP)入門學習資源清單
致謝 鍾崇光博士參與了資料派THU於6月5日、THU資料派於6月8日釋出的《循序漸進提升Kaggle競賽模型精確度,以美國好事達保險公司理賠為例》一文的校對工作,並且給出了許多有建設性的意見,在此資料派翻譯組對鍾博士表達誠摯的感謝! 作者:Melanie Tosik
自然語言處理(NLP)入門
本文簡要介紹Python自然語言處理(NLP),使用Python的NLTK庫。NLTK是Python的自然語言處理工具包,在NLP領域中,最常使用的一個Python庫。 什麼是NLP? 簡單來說,自然語言處理(NLP)就是開發能夠理解人類語言的應用程式或服務
自然語言處理(NLP)入門指南資料
作者:Melanie Tosik 翻譯:閔黎 校對:丁楠雅 Melanie Tosik目前就職於旅遊搜尋公司WayBlazer,她的工作內容是通過自然語言請求來生產個性化旅遊推薦路線。回顧她的學習歷程,她為期望入門自然語言處理的初學者列出了一份學習資源清單。
自然語言處理NLP快速入門
真的 mat unit rod visit ctrl may let 深入 自然語言處理NLP快速入門 https://mp.weixin.qq.com/s/J-vndnycZgwVrSlDCefHZA 【導讀】自然語言處理已經成為人工智能領域一個重要的分支,它
自然語言處理如何入門
意義 更新 枯燥 最大的 處理 計算 關聯分析 教育 詞典 ps:筆者會持續更新~ 領域分支概括 俗話說得好: 做research或者學習某個技能最重要的是要對自己的research要非常熟悉(3mins讓別人聽懂你做的這玩意兒是個啥,contribution在哪裏,讓別
自然語言處理NLP(一)
rac 控制臺 分析 arm ont 正則表達 stop python none NLP 自然語言:指一種隨著社會發展而自然演化的語言,即人們日常交流所使用的語言; 自然語言處理:通過技術手段,使用計算機對自然語言進行各種操作的一個學科; NLP研究的內容
自然語言處理NLP(二)
哪些 一個 圖片 ali cor res https 的區別 進行 詞性標註 標註語料庫; 各詞性標註及其含義 自動標註器; 默認標註器; 正則表達式標註器; 查詢標註器; N-gram標註器; 一元標註器; 分離訓練和測試數據; 一般的N-gram的標註
自然語言處理(nlp)比計算機視覺(cv)發展緩慢,而且更難!
https://mp.weixin.qq.com/s/kWw0xce4kdCx62AflY6AzQ 1. 搶跑的nlp nlp發展的歷史非常早,因為人從計算機發明開始,就有對語言處理的需求。各種字串演算法都貫穿於計算機的發展歷史中。偉大的喬姆斯基提出了
自然語言處理NLP技術里程碑、知識結構、研究方向和機構導師(公號回覆“NLP總結”下載彩標PDF典藏版資料)
自然語言處理NLP技術里程碑、知識結構、研究方向和機構導師(公號回覆“NLP總結”下載彩標PDF典藏版資料) 原創: 秦隴紀 資料簡化DataSimp 今天 資料簡化DataSimp導讀:自然語言處理髮展史上的十大里程碑、NLP知識結構,以及NLP國內研究方向、機構、導師。祝大家學習
斯坦福CS224N_自然語言處理NLP深度學習DL課程筆記(一)
Lecture 1: Introduction pdf 本節課是對自然語言處理的定義介紹和應用介紹,還順帶說了NLP的難點; 本節課使用深度學習作為NLP的主要處理工具。 傳統的機器學習技術,需要人為地去做特徵工程,將這些的特徵餵給機器學期演算法;然後機器學習演
自然語言處理NLP(三)
樣本點中的關鍵度量指標:距離 定義: 常用距離: 歐氏距離,euclidean–通常意義下的距離; 馬氏距離,manhattan–考慮到變數間的相關性,且與變數單位無關; 餘弦距離,cosi
自然語言處理NLP(四)
實體識別 實體識別–分塊型別: 名詞短語分塊; 標記模式分塊; 正則表示式分塊; 分塊的表示方法:標記和樹狀圖; 分塊器評估; 命名實體識別; 命名實體定義:指特定型別的個體,是一些確切的名詞短語
最新自然語言處理(NLP)四步流程:Embed->Encode->Attend->Predict
過去半年以來,自然語言處理領域進化出了一件神器。此神器乃是深度神經網路的一種新模式,該模式分為:embed、encode、attend、predict四部分。本文將對這四個部分娓娓道來,並且剖析它在兩個例項中的用法。 人們在談論機器學習帶來的提升時,往往只想到了機器在效率和
自然語言處理(NLP) 一: 分詞、分句、詞幹提取
需要安裝nltk自然語言處理包,anaconda預設已經安裝了 還需要安裝nltk語料庫:http://www.nltk.org/data.html 自然語言基礎知識: 1、分詞 魚香肉絲裡面多放點辣椒 對稱加密需要DES處理引擎 天兒冷了多穿點
ML:自然語言處理NLP面試題
自然語言處理的三個里程碑: 兩個事實分別為: 一、短語結構語法不能有效地描寫自然語言。 二、短語結構規則的覆蓋有限。Chomsky 曾提出過這樣的假設,認為對一種自然語言來說,其語法規則的數目是有限的,而據此生成的句子數目是無限的。 文中提到的三個里程碑式的進展為:
對自然語言處理nlp的一點感想
自然語言處理(nlp)作為計算機的一個研究方向存在已久,但是最近人工智慧這一波熱潮又讓nlp重新得到巨大關注。由於處理物件是語言這一種人類特有的溝通工具以及其豐富巨大的資訊量,給人一種錯覺--似乎這是人工智慧領域真正的皇冠,達到最終真正人工智慧(強人工智慧)的最近之路。但是事
自然語言處理(NLP) 三:詞袋模型 + 文字分類
1.詞袋模型 (BOW,bag of words) 用詞頻矩陣作為每個樣本的特徵 Are you curious about tokenization ? Let’s see how it works! we need to analyze a coupl
自然語言處理(nlp)的流程圖
1. 讀取原始資料 html = urlopen(url).read() 2. 資料清洗 raw = nltk.clean_html(html) 3. 資料切片 raw = raw[111:2222222] 4. 資料分詞 tokens = nltk.wordpunc
一文讀懂自然語言處理NLP
前言 自然語言處理是文字挖掘的研究領域之一,是人工智慧和語言學領域的分支學科。在此領域中探討如何處理及運用自然語言。 對於自然語言處理的發展歷程,可以從哲學中的經驗主義和理性主義說起。基於統計的自然語言處理是哲學中的經驗主義,基於規
自然語言處理(NLP) 四:性別識別
import random import numpy as np import nltk.corpus as nc import nltk.classify as cf male_names = nc.names.words('male.txt') fe