
mybatis的快取機制(一級快取二級快取和重新整理快取)和mybatis整合ehcache
1 查詢快取
1.1 什麼是查詢快取
mybatis提供查詢快取,用於減輕資料壓力,提高資料庫效能。
mybaits提供一級快取,和二級快取。
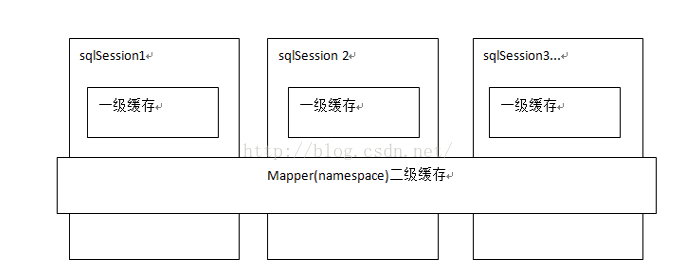
一級快取是SqlSession級別的快取。在操作資料庫時需要構造 sqlSession物件,在物件中有一個(記憶體區域)資料結構(HashMap)用於儲存快取資料。不同的sqlSession之間的快取資料區域(HashMap)是互相不影響的。
一級快取的作用域是同一個SqlSession,在同一個sqlSession中兩次執行相同的sql語句,第一次執行完畢會將資料庫中查詢的資料寫到快取(記憶體),第二次會從快取中獲取資料將不再從資料庫查詢,從而提高查詢效率。
二級快取是mapper級別的快取,多個SqlSession去操作同一個Mapper的sql語句,多個SqlSession去操作資料庫得到資料會存在二級快取區域,多個SqlSession可以共用二級快取,二級快取是跨SqlSession的。
二級快取是多個SqlSession共享的,其作用域是mapper的同一個namespace,不同的sqlSession兩次執行相同namespace下的sql語句且向sql中傳遞引數也相同即最終執行相同的sql語句,第一次執行完畢會將資料庫中查詢的資料寫到快取(記憶體),第二次會從快取中獲取資料將不再從資料庫查詢,從而提高查詢效率。
如果快取中有資料就不用從資料庫中獲取,大大提高系統性能。
1.2 一級快取
1.2.1 一級快取工作原理
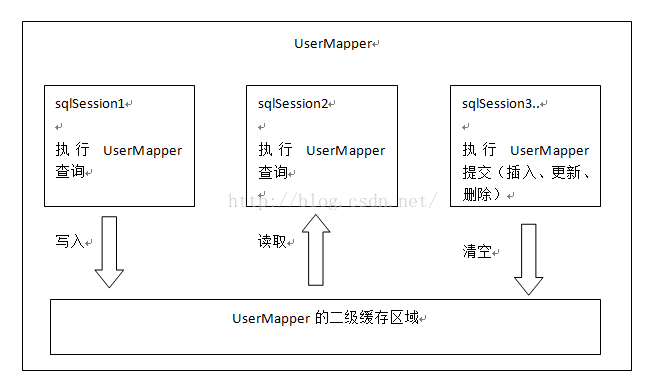
下圖是根據id查詢使用者的一級快取圖解

第一次發起查詢使用者id為1的使用者資訊,先去找快取中是否有id為1的使用者資訊,如果沒有,從資料庫查詢使用者資訊。
得到使用者資訊,將使用者資訊儲存到一級快取中。
如果sqlSession去執行commit操作(執行插入、更新、刪除),清空SqlSession中的一級緩存,這樣做的目的為了讓快取中儲存的是最新的資訊,避免髒讀。
第二次發起查詢使用者id為1的使用者資訊,先去找快取中是否有id為1的使用者資訊,快取中有,直接從快取中獲取使用者資訊。
1.2.2 一級快取測試
mybatis預設支援一級快取,不需要在配置檔案去配置。
按照上邊一級快取原理步驟去測試。
@Test
public void testCache1() throws Exception{
SqlSessionsqlSession = sqlSessionFactory.openSession();//建立代理物件
UserMapperuserMapper = sqlSession.getMapper(UserMapper.class);
//下邊查詢使用一個SqlSession
//第一次發起請求,查詢id為1的使用者
Useruser1 = userMapper.findUserById(1);
System.out.println(user1);
// 如果sqlSession去執行commit操作(執行插入、更新、刪除),清空SqlSession中的一級快取,這樣做的目的為了讓快取中儲存的是最新的資訊,避免髒讀。
//更新user1的資訊
user1.setUsername("測試使用者22");
userMapper.updateUser(user1);
//執行commit操作去清空快取
sqlSession.commit();
//第二次發起請求,查詢id為1的使用者
Useruser2 = userMapper.findUserById(1);
System.out.println(user2);
sqlSession.close();
}
1.2.3 一級快取應用
正式開發,是將mybatis和spring進行整合開發,事務控制在service中。
一個service方法中包括很多mapper方法呼叫。
service{
//開始執行時,開啟事務,建立SqlSession物件
//第一次呼叫mapper的方法findUserById(1)
//第二次呼叫mapper的方法findUserById(1),從一級快取中取資料
//aop控制 只要方法結束,sqlSession關閉 sqlsession關閉後就銷燬資料結構,清空快取
Service結束sqlsession關閉
}
如果是執行兩次service呼叫查詢相同的使用者資訊,不走一級快取,因為Service方法結束,sqlSession就關閉,一級快取就清空。
1.3 二級快取
1.3.1 原理
首先開啟mybatis的二級快取。
sqlSession1去查詢使用者id為1的使用者資訊,查詢到使用者資訊會將查詢資料儲存到二級快取中。
如果SqlSession3去執行相同 mapper下sql,執行commit提交,清空該 mapper下的二級快取區域的資料。
sqlSession2去查詢使用者id為1的使用者資訊,去快取中找是否存在資料,如果存在直接從快取中取出資料。
二級快取與一級快取區別,二級快取的範圍更大,多個sqlSession可以共享一個UserMapper的二級快取區域。資料型別仍然為HashMap
UserMapper有一個二級快取區域(按namespace分,如果namespace相同則使用同一個相同的二級快取區),其它mapper也有自己的二級快取區域(按namespace分)。
每一個namespace的mapper都有一個二快取區域,兩個mapper的namespace如果相同,這兩個mapper執行sql查詢到資料將存在相同的二級快取區域中。
1.3.2 開啟二級快取
mybaits的二級快取是mapper範圍級別,除了在SqlMapConfig.xml設定二級快取的總開關,還要在具體的mapper.xml中開啟二級快取。
在核心配置檔案SqlMapConfig.xml中加入
<setting name="cacheEnabled"value="true"/>
<!-- 全域性配置引數,需要時再設定 -->
<settings>
<!-- 開啟二級快取預設值為true -->
<setting name="cacheEnabled" value="true"/>
</settings>
|
描述 |
允許值 |
預設值 |
|
|
cacheEnabled |
對在此配置檔案下的所有cache 進行全域性性開/關設定。 |
true false |
true |
在UserMapper.xml中開啟二快取,UserMapper.xml下的sql執行完成會儲存到它的快取區域(HashMap)。
<mapper namespace="cn.hpu.mybatis.mapper.UserMapper">
<!-- 開啟本mapper namespace下的二級快取 -->
<cache></cache>
1.3.3 呼叫pojo類實現序列化介面
public class Userimplements Serializable {
//Serializable實現序列化,為了將來反序列化
二級快取需要查詢結果對映的pojo物件實現java.io.Serializable介面實現序列化和反序列化操作,注意如果存在父類、成員pojo都需要實現序列化介面。
pojo類實現序列化介面是為了將快取資料取出執行反序列化操作,因為二級快取資料儲存介質多種多樣,不一定在記憶體有可能是硬碟或者遠端伺服器。
1.3.4 測試方法
// 二級快取測試
@Test
public void testCache2() throws Exception {
SqlSessionsqlSession1 = sqlSessionFactory.openSession();
SqlSessionsqlSession2 = sqlSessionFactory.openSession();
SqlSessionsqlSession3 = sqlSessionFactory.openSession();
// 建立代理物件
UserMapperuserMapper1 = sqlSession1.getMapper(UserMapper.class);
// 第一次發起請求,查詢id為1的使用者
Useruser1 = userMapper1.findUserById(1);
System.out.println(user1);
//這裡執行關閉操作,將sqlsession中的資料寫到二級快取區域
sqlSession1.close();
//使用sqlSession3執行commit()操作
UserMapperuserMapper3 = sqlSession3.getMapper(UserMapper.class);
Useruser = userMapper3.findUserById(1);
user.setUsername("張明明");
userMapper3.updateUser(user);
//執行提交,清空UserMapper下邊的二級快取
sqlSession3.commit();
sqlSession3.close();
UserMapperuserMapper2 = sqlSession2.getMapper(UserMapper.class);
// 第二次發起請求,查詢id為1的使用者
Useruser2 = userMapper2.findUserById(1);
System.out.println(user2);
sqlSession2.close();
}
1.3.5 useCache配置禁用二級快取
在statement中設定useCache=false可以禁用當前select語句的二級快取,即每次查詢都會發出sql去查詢,預設情況是true,即該sql使用二級快取。
<selectid="findOrderListResultMap" resultMap="ordersUserMap" useCache="false">
總結:針對每次查詢都需要最新的資料sql,要設定成useCache=false,禁用二級快取。
1.3.6 mybatis重新整理快取(就是清空快取)
在mapper的同一個namespace中,如果有其它insert、update、delete操作資料後需要重新整理快取,如果不執行重新整理快取會出現髒讀。
設定statement配置中的flushCache="true" 屬性,預設情況下為true即重新整理快取,如果改成false則不會重新整理。使用快取時如果手動修改資料庫表中的查詢資料會出現髒讀。
如下:
<insertid="insertUser" parameterType="cn.itcast.mybatis.po.User" flushCache="true">
總結:一般下執行完commit操作都需要重新整理快取,flushCache=true表示重新整理快取預設情況下為true,我們不用去設定它,這樣可以避免資料庫髒讀。
1.3.7 Mybatis Cache引數
flushInterval(重新整理間隔)可以被設定為任意的正整數,而且它們代表一個合理的毫秒形式的時間段。預設情況是不設定,也就是沒有重新整理間隔,快取僅僅呼叫語句時重新整理。
size(引用數目)可以被設定為任意正整數,要記住你快取的物件數目和你執行環境的可用記憶體資源數目。預設值是1024。
readOnly(只讀)屬性可以被設定為true或false。只讀的快取會給所有呼叫者返回快取物件的相同例項。因此這些物件不能被修改。這提供了很重要的效能優勢。可讀寫的快取會返回快取物件的拷貝(通過序列化)。這會慢一些,但是安全,因此預設是false。
如下例子:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
這個更高階的配置建立了一個 FIFO 快取,並每隔 60 秒重新整理,存數結果物件或列表的 512 個引用,而且返回的物件被認為是隻讀的,因此在不同執行緒中的呼叫者之間修改它們會導致衝突。可用的收回策略有, 預設的是 LRU:
1. LRU – 最近最少使用的:移除最長時間不被使用的物件。
2. FIFO – 先進先出:按物件進入快取的順序來移除它們。
3. SOFT – 軟引用:移除基於垃圾回收器狀態和軟引用規則的物件。
4. WEAK – 弱引用:更積極地移除基於垃圾收集器狀態和弱引用規則的物件。
1.4 mybatis整合ehcache
ehcache是一個分散式快取框架。
EhCache 是一個純Java的程序內快取框架,是一種廣泛使用的開源Java分散式快取,具有快速、精幹等特點,是Hibernate中預設的CacheProvider。
1.4.1 分佈快取
我們系統為了提高系統併發,效能、一般對系統進行分散式部署(叢集部署方式)
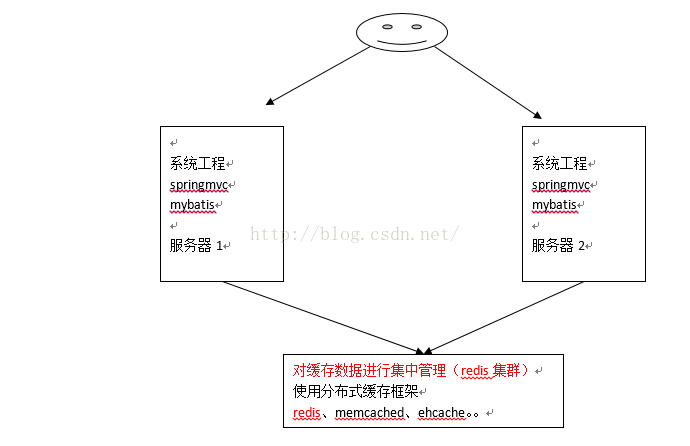
不使用分佈快取,快取的資料在各各服務單獨儲存,不方便系統開發。所以要使用分散式快取對快取資料進行集中管理。
mybatis無法實現分散式快取,需要和其它分散式快取框架進行整合。
1.4.2 整合方法(掌握無論整合誰,首先想到改type介面)
mybatis提供了一個cache介面,如果要實現自己的快取邏輯,實現cache介面開發即可。
mybatis和ehcache整合,mybatis和ehcache整合包中提供了一個cache介面的實現類。
1.4.3 第一步加入ehcache包

1.4.4 整合ehcache
配置mapper中cache中的type為ehcache對cache介面的實現型別。
<mapper namespace="cn.hpu.mybatis.mapper.UserMapper">
<!-- 開啟本mapper namespace下的二級快取
type:指定cache介面實現類,mybatis預設使用PerpetualCache
要和eache整合,需要配置type為ehcahe實現cache介面的型別
-->
<cache type="org.mybatis.caches.ehcache.EhcacheCache">
</cache>
可以根據需求調整快取引數:
<cache type="org.mybatis.caches.ehcache.EhcacheCache">
<property name="timeToIdleSeconds" value="3600"/>
<property name="timeToLiveSeconds" value="3600"/>
<!-- 同ehcache引數maxElementsInMemory-->
<property name="maxEntriesLocalHeap"value="1000"/>
<!-- 同ehcache引數maxElementsOnDisk -->
<property name="maxEntriesLocalDisk" value="10000000"/>
<property name="memoryStoreEvictionPolicy" value="LRU"/>
</cache>
1.4.5 加入ehcache的配置檔案
在classpath下配置ehcache.xml
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="../config/ehcache.xsd">
<diskStore path="F:\develop\ehcache"/>
<defaultCache
maxElementsInMemory="1000"
maxElementsOnDisk="10000000"
eternal="false"
overflowToDisk="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU">
</defaultCache>
</ehcache>
屬性說明:
diskStore:指定資料在磁碟中的儲存位置。
defaultCache:當藉助CacheManager.add("demoCache")建立Cache時,EhCache便會採用<defalutCache/>指定的的管理策略
以下屬性是必須的:
maxElementsInMemory - 在記憶體中快取的element的最大數目
maxElementsOnDisk - 在磁碟上快取的element的最大數目,若是0表示無窮大
eternal - 設定快取的elements是否永遠不過期。如果為true,則快取的資料始終有效,如果為false那麼還要根據timeToIdleSeconds,timeToLiveSeconds判斷
overflowToDisk- 設定當記憶體快取溢位的時候是否將過期的element快取到磁碟上
以下屬性是可選的:
timeToIdleSeconds - 當快取在EhCache中的資料前後兩次訪問的時間超過timeToIdleSeconds的屬性取值時,這些資料便會刪除,預設值是0,也就是可閒置時間無窮大
timeToLiveSeconds - 快取element的有效生命期,預設是0.,也就是element存活時間無窮大
diskSpoolBufferSizeMB 這個引數設定DiskStore(磁碟快取)的快取區大小.預設是30MB.每個Cache都應該有自己的一個緩衝區.
diskPersistent在VM重啟的時候是否啟用磁碟儲存EhCache中的資料,預設是false。
diskExpiryThreadIntervalSeconds - 磁碟快取的清理執行緒執行間隔,預設是120秒。每個120s,相應的執行緒會進行一次EhCache中資料的清理工作
memoryStoreEvictionPolicy - 當記憶體快取達到最大,有新的element加入的時候,移除快取中element的策略。預設是LRU(最近最少使用),可選的有LFU(最不常使用)和FIFO(先進先出)
1.5 二級應用場景
對於訪問多的查詢請求且使用者對查詢結果實時性要求不高,此時可採用mybatis二級快取技術降低資料庫訪問量,提高訪問速度,業務場景比如:耗時較高的統計分析sql、電話賬單查詢sql等。
實現方法如下:通過設定重新整理間隔時間,由mybatis每隔一段時間自動清空快取,根據資料變化頻率設定快取重新整理間隔flushInterval,比如設定為30分鐘、60分鐘、24小時等,根據需求而定。
1.6 二級快取侷限性
mybatis二級快取對細粒度的資料級別的快取實現不好,對同時快取較多條資料的快取,比如如下需求:對商品資訊進行快取,由於商品資訊查詢訪問量大,但是要求使用者每次都能查詢最新的商品資訊,此時如果使用mybatis的二級快取就無法實現當一個商品變化時只重新整理該商品的快取資訊而不重新整理其它商品的資訊,因為mybaits的二級快取區域以mapper為單位劃分,當一個商品資訊變化會將所有商品資訊的快取資料全部清空。解決此類問題需要在業務層根據需求對資料有針對性快取。需要使用三級快取
摘自傳智部落格燕青老師的視訊
相關推薦
mybatis的快取機制(一級快取二級快取和重新整理快取)和mybatis整合ehcache
1 查詢快取 1.1 什麼是查詢快取 mybatis提供查詢快取,用於減輕資料壓力,提高資料庫效能。 mybaits提供一級快取,和二級快取。 一級快取是SqlSession級別的快取。在操作資料庫時需要構造 sqlSession物件,在物件中有一個(記憶
MyBatis快取機制(一級快取,二級快取)
一,MyBatis一級快取(本地快取) My Batis 一級快取存在於 SqlSession 的生命週期中,是SqlSession級別的快取。在操作資料庫時需要構造SqlSession物件,在物件中有一個數據結構用來儲存快取資料。不同的SqlSession之間的資料快取是不能共享的。 在同一個Sql
Leetcode 146:LRU快取機制(超詳細的解法!!!)
運用你所掌握的資料結構,設計和實現一個 LRU (最近最少使用) 快取機制。它應該支援以下操作: 獲取資料 get 和 寫入資料 put 。 獲取資料 get(key) - 如果金鑰 (key) 存在於快取中,則獲取金鑰的值(總是正數),否則返回 -1。 寫入資料 put(key,
效能優化(一)Hibernate 利用快取(一級、二級、查詢)提高系統性能
在hibernate中我們最常用的有三類快取,分別為一級快取、二級快取和查詢快取,下面我們對這三個快取在專案中的使用以及優缺點分析一下。 快取它的作用在於提高效能系統性能,介於應用系統與資料庫之間而存在於記憶體或磁碟上的資料。 我們程式設
Mybatis的快取機制(二)
0.寫在前面 MyBatis是一個簡單,小巧但功能非常強大的ORM開源框架,它的功能強大也體現在它的快取機制上。MyBatis提供了一級快取、二級快取 這兩個快取機制,能夠很好地處理和維護快取,以提高系統的效能。本文的目的則是向讀者詳細介紹MyBatis的一
LeetCode 146. LRU快取機制(java實現)
參考解答 總結:這道題主要要知道選取何種資料結構並且在 O(1) 時間複雜度內完成這兩種操作? O(1) 的get方法肯定要用到HashMap() LinkedList(雙向連結串列)可以以O(1)時間複雜度,很方便地實現資料的插入和刪除 所以,將兩個資料結構聯合使用,Ha
Mybait快取機制(四)
MyBatis同大多數ORM框架一樣,提供了一級快取和二級快取的支援。 一級快取:其作用域為session範圍內,當session執行flush或close方法後,一級快取會被清空。 二級快取:二級快取和一級快取機制相同,但是可以自定義其作用範圍,如Ehcache。 一級快取 在預設情況下mybati
.Net——快取機制(一):利用Dictionary模擬快取
在計算機的硬體設計中,有一個被反覆使用的思想——快取。同樣,在軟體設計中,這個思想也可以用來解決資料讀取非常耗時帶來的效能問題(當然,在時間和空間上,我們要尋找一個平衡點)。
說說自己對hibernate一級、二級、查詢、快取的理解。
今天面試碰到答不上來。。馬上回家查了下,現在寫下對hibernate快取的理解以加深印象。 1、一級快取 可以簡單的理解為session快取,即同一個session中使用get、load、迭代,會優先重快取中取,如果沒有則查詢資料庫並存入快取,session關閉後快取清空
laravel自定義快取memcache(自帶memcached,windows不支援)
1、首先弄清楚memcache和memcached的區別(自行搜尋) 2、安裝memcache服務端(參照https://www.cnblogs.com/winstonsias/p/10190745.html)及php擴充套件(參照https://www.cnblogs.com/winstonsias/p/
歷年全國GIS應用水平考試真題(一級、二級)
GIS水平考試輔導資料 全國資訊化工程師——GIS應用水平考試2018年度下半年全國統一考試將於11月24日舉行,為幫助廣大考生順利通過考試,特整理GIS水平考試輔導資料。本次培訓的兩位主講人對M
Redis系列--內存淘汰機制(含單機版內存優化建議)
del dbn amp 一段 最簡 nal imp 同學 博客 https://blog.csdn.net/Jack__Frost/article/details/72478400?locationNum=13&fps=1 每臺redis的服務器的內存都是有限的,而
mybatis 初步使用(IDEA的Maven項目, 超詳細)
font arc conn sys water 2.3 包名 cor pri 創建 Maven 項目 1. 菜單上選擇新建項目 File | New | Project 2. 選擇左側的Maven 由於我們只是創建一個普通的項目, 此處點擊 Next即可。 3. 輸入
許可權管理-一級選單-二級選單-三級選單-路徑導航和許可權粒度控制到按鈕級別
許可權管理 RBAC 許可權管理 1. 為什麼要有許可權? 2. 開發一套許可權的元件。為什麼要開發元件? 3. 許可權是什麼? web 開發中 URL 約等於 許可權 4. 表結構
Redis 哨兵節點之間相互自動發現機制(自動重寫哨兵節點的配置檔案)
Redis的哨兵機制中,如果是多哨兵模式,哨兵節點之間也是可以相互感知的,各種搜尋之後出來的是千篇一律的一個基礎配置檔案,在配置當前哨兵節點的配置檔案中,並沒有配置其他哨兵節點的任何資訊。 如下是一個哨兵節點的配置資訊,可以看到,哨兵與哨兵之間沒有任何配置,死活想不明白,哨兵之間是如何自動識別的。 #se
mybatis中 排序(將指定的排在後/前面)
public List<SuitEvidenceVo> selectWithFileByCaseId(Long caseId, List<Long> userIdList, Page evidencePge) { SuitEvi
java 使用圖片代理程式,解決網站圖片防盜鏈機制(測試百度,QQ空間有效)
業務場景 1、頁面引用其他站點圖片的時候,由於某些站點存在圖片的防盜鏈機制,所以在引用圖片的時候,返回的一張預設的圖片,而不是原圖片。 2、使用java完成一個代理程式,代理所有的存在防盜鏈機制的圖片請求,繞過防盜鏈機制,返回原圖片 解決思路 1、代
nodejs之事件處理機制(丟擲事件、監聽事件)
程式執行到一定階段的時候會發出一個訊息,對這個訊息進行監聽,作出響應;==========================================***************建立伺服器var http = require('http'); var fs = requ
java事件監聽機制(觀察者設計模式的實際運用)
package cn.yang.test.controller; /**java的事件監聽機制和觀察者設計模式 * Created by Dev_yang on 2016/3/1. */ publ
C++實現 反射 機制( 即根據 類名 建立 類例項)Create C++ Object Dynamically
Create C++ Object Dynamically Introduction C++不像C#和Java那樣具有反射的能力,通常不能根據任意一個class name來建立該class的instance。但我們知道在MFC中,任何繼承了CObject的類都可以根據其名字來建立例項,它是使用了一些巨集。而