
Apache Kafka系列(五) Kafka Connect及FileConnector示例
一. Kafka Connect簡介
Kafka是一個使用越來越廣的訊息系統,尤其是在大資料開發中(實時資料處理和分析)。為何整合其他系統和解耦應用,經常使用Producer來發送訊息到Broker,並使用Consumer來消費Broker中的訊息。Kafka Connect是到0.9版本才提供的並極大的簡化了其他系統與Kafka的整合。Kafka Connect運用使用者快速定義並實現各種Connector(File,Jdbc,Hdfs等),這些功能讓大批量資料匯入/匯出Kafka很方便。
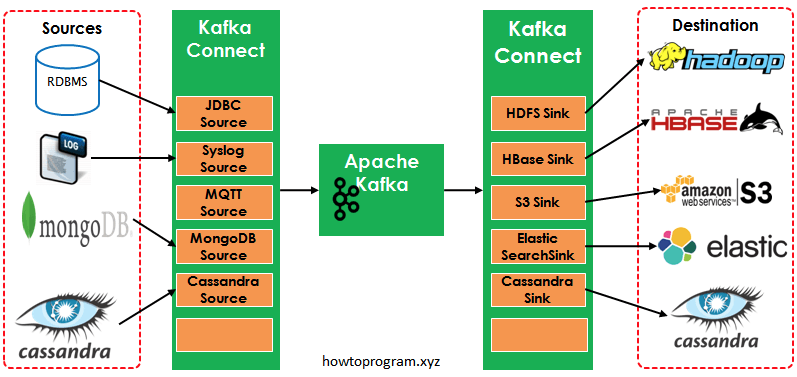
如圖中所示,左側的Sources負責從其他異構系統中讀取資料並匯入到Kafka中;右側的Sinks是把Kafka中的資料寫入到其他的系統中。
二. 各種Kafka Connector
Kafka Connector很多,包括開源和商業版本的。如下列表中是常用的開源Connector
| Connectors | References |
| Jdbc | |
| Elastic Search | Sink1, Sink2, Sink3 |
| Cassandra | |
| HBase | Sink |
| MQTT (Source) | |
| Twitter (Source) | |
| S3 | Sink1, Sink2 |
三. 示例
3.1 FileConnector Demo
本例演示如何使用Kafka Connect把Source(test.txt)轉為流資料再寫入到Destination(test.sink.txt)中。如下圖所示:
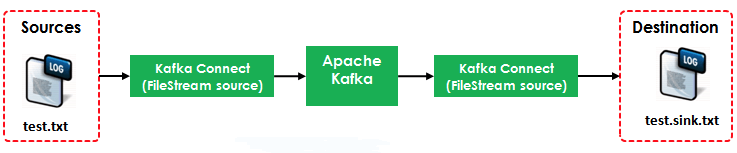
本例使用到了兩個Connector:
- FileStreamSource:從test.txt中讀取併發布到Broker中
- FileStreamSink:從Broker中讀取資料並寫入到test.sink.txt檔案中
其中的Source使用到的配置檔案是${KAFKA_HOME}/config/connect-file-source.properties
name=local-file-source connector.class=FileStreamSource tasks.max=1 file=test.txt topic=connect-test
其中的Sink使用到的配置檔案是${KAFKA_HOME}/config/connect-file-sink.properties
name=local-file-sink connector.class=FileStreamSink tasks.max=1 file=test.sink.txt topics=connect-test
Broker使用到的配置檔案是${KAFKA_HOME}/config/connect-standalone.properties
bootstrap.servers=localhost:9092key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=true value.converter.schemas.enable=trueinternal.key.converter=org.apache.kafka.connect.json.JsonConverter internal.value.converter=org.apache.kafka.connect.json.JsonConverter internal.key.converter.schemas.enable=false internal.value.converter.schemas.enable=false offset.storage.file.filename=/tmp/connect.offsets offset.flush.interval.ms=10000
3.2 執行Demo
3.2.1 啟動Kafka Broker
[[email protected] bin]# cd /opt/kafka_2.11-0.11.0.0/ [[email protected] kafka_2.11-0.11.0.0]# ls bin config libs LICENSE logs NOTICE site-docs [[email protected] kafka_2.11-0.11.0.0]# ./bin/zookeeper-server-start.sh ./config/zookeeper.properties &
[[email protected] kafka_2.11-0.11.0.0]# ./bin/kafka-server-start.sh ./config/server.properties &
3.2.2 啟動Source Connector和Sink Connector
[[email protected] kafka_2.11-0.11.0.0]# ./bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
3.3.3 開啟console-consumer
./kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic connect-test
3.3.4 寫入到test.txt檔案中,並觀察3.3.3中的變化
[[email protected] kafka_2.12-0.11.0.0]# echo 'firest line' >> test.txt [[email protected] kafka_2.12-0.11.0.0]# echo 'second line' >> test.txt 3.3.3中開啟的視窗輸出如下 {"schema":{"type":"string","optional":false},"payload":"firest line"} {"schema":{"type":"string","optional":false},"payload":"second line"}
3.3.5 檢視test.sink.txt
[[email protected] kafka_2.12-0.11.0.0]# cat test.sink.txt firest line second line
四. 結論
本例僅僅演示了Kafka自帶的File Connector,後續文章會完成JndiConnector,HdfsConnector,並且會使用CDC(Changed Data Capture)整合Kafka來完成一個ETL的例子
PS:
相比編譯過Kafka-Manager都知道各種坑,經過了3個小時的努力,我終於把Kafka-Manager編譯通過並打包了,並且新增了Kafka0.11.0版本支援。
附下載地址: 連結: https://pan.baidu.com/s/1miiMsAk 密碼: 866q
相關推薦
Apache Kafka系列(五) Kafka Connect及FileConnector示例
一. Kafka Connect簡介 Kafka是一個使用越來越廣的訊息系統,尤其是在大資料開發中(實時資料處理和分析)。為何整合其他系統和解耦應用,經常使用Producer來發送訊息到Broker,並使用Consumer來消費Broker中的訊息。Kafka Connect是到0.9版本才提供的並極大
kafka系列五、kafka常用java API
引入maven包 <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <
Kafka系列之-Kafka監控工具KafkaOffsetMonitor配置及使用
KafkaOffsetMonitor是一個可以用於監控Kafka的Topic及Consumer消費狀況的工具,其配置和使用特別的方便。源專案Github地址為:https://github.com/quantifind/KafkaOffsetMonitor。
Kafka系列4-基本概念及消費者組(Consumer Group)的理解
幾個基本概念: Kafka是一個分散式流資料系統,使用Zookeeper進行叢集的管理。與其他訊息系統類似,整個系統由生產者、Broker Server和消費者三部分組成,生產者和消費者由開發人員編寫,通過API連線到Broker Server進行資料操作。我
apache kafka系列之kafka.common.ConsumerRebalanceFailedException異常解決辦法
kafka.common.ConsumerRebalanceFailedException :log-push-record-consumer-group_mobile-pushremind02.lf
Kafka系列之-Kafka Protocol例項分析
本文基於A Guide To The Kafka Protocol文件,以及Spark Streaming中實現的org.apache.spark.streaming.kafka.KafkaCluster類。整理出Kafka中有關 Metadata AP
mybatis學習系列五--插件及類型處理器
進行 class 引入 set gis 批量 lte sta sre 2 插件編寫(80-81) 單個插件編寫 2.1實現interceptor接口(ibatis) invocation.proceed()方法執行必須要有,否則不會無法實現攔截作用 2.2 使用@i
springcloud系列21——Zuul簡介及程式碼示例
Zuul簡介 路由是微服務架構的組成部分。 例如,/可以對映到您的Web應用程式,/ api/users對映到使用者服務,/api/shop對映到商店服務。 Zuul是Netflix基於JVM的路由器和伺服器端負載均衡器。 Netflix使用Zuul進行以下操
Apache Lucene 全文檢索詳解及開發示例
講解之前,先來分享一些資料 首先呢,學習任何一門新的亦或是舊的開源技術,百度其中一二是最簡單的辦法,先了解其中的大概,思想等等。這裡就貢獻一個講解很到位的ppt。已經被我轉成了PDF,便於蒐藏。 其次,關於第一次程式設計初探,建議還是檢視官方資料。百度到的資料
kafka系列一、kafka安裝及部署
一、環境準備 作業系統:Cent OS 7 Kafka版本:kafka_2.10 Kafka官網下載:請點選 JDK版本:1.8.0_171 zookeeper-3.4.10 二、kafka安裝配置 1、下載Kafka並解壓 下載:
kafka系列九、kafka事務原理及使用場景
一、事務場景 1.最簡單的需求是producer發的多條訊息組成一個事務這些訊息需要對consumer同時可見或者同時不可見 。 2.producer可能會給多個topic,多個partition發訊息,這些訊息也需要能放在一個事務裡面,這就形成了一個典型的分散式事務。 3.kafka的應用場景經常是應用先
[Kafka] Apache Kafka 簡介、叢集搭建及配置詳解
前言 kafka是一種高吞吐量的分散式釋出訂閱訊息系統,它可以處理消費者規模的網站中的所有動作流資料。這種動作(網頁瀏覽,搜尋和其他使用者的行動)是在現代網路上的許多社會功能的一個關鍵因素。這些資料通常是由於吞吐量的要求而通過處理日誌和日誌聚合來解決。 Kafk
apache kafka系列之效能測試報告(虛擬機器版)
測試方法 在其他虛擬機器上使用 Kafka 自帶 kafka-producer-perf-test.sh 指令碼進行測試 Kafka 寫入效能 嘗試使用 kafka-simple-consumer-p
Apache Kafka系列(二) 命令列工具(CLI)
Apache Kafka命令列工具(Command Line Interface,CLI),下文簡稱CLI。 1. 啟動Kafka 啟動Kafka需要兩步: 1.1. 啟動ZooKeeper [[email protected] kafka_2.12-0.11.0.0]# bin/zo
Apache Kafka系列(三) Java API使用
摘要: Apache Kafka Java Client API 一、基本概念 Kafka集成了Producer/Consumer連線Broker的客戶端工具,但是在訊息處理方面,這兩者主要用於服務端(Broker)的簡單操作,如: 1.建立Topic 2.羅列出已存在的Topic
Apache Kafka系列(一) 起步
摘要: 1.Apache Kafka基本概念 2.Kafka的安裝 3.基本工具建立Topic 本文基於centos7, Apache Kafka 0.11.0 一、基本概念 Apache Kafka是一個釋出/訂閱的訊息系統,於2009年源自Linkedin,並與2011年開源。在架構方
Apache Kafka系列(四) 多執行緒Consumer方案
本文的圖片是通過PPT截圖出的,讀者如果修改意見請聯絡我 一、Consumer為何需要實現多執行緒 假設我們正在開發一個訊息通知模組,該模組允許使用者訂閱其他使用者傳送的通知/訊息。該訊息通知模組採用Apache Kafka,那麼整個架構應該是訊息的釋出者通過Producer呼叫API寫入訊息到Kafk
kafka系列(七)使用Kafka-Connect匯入匯出資料
摘要 本文主要內容是介紹如何使用kafka-connect進行匯入匯出資料,文章內容來自於kafka官方文件,對官方文件中一些內容作了簡要補充。 簡介 向console中寫入資料然後再寫回到console是非常方便的,但是你可能想從其他的資料來源寫入資
Kafka系列 —— 入門及應用場景 & 部署 & 簡單測試
Kafka系列為自己學習與使用Kafka中遇到的問題與總結。本系列將介紹如下內容: Kafka入門及應用場景 & 部署 & 簡單測試 Kafka核心概念 Kafka常用命令 Kafka監控 Kafka消費語義分析 Flume + Kafka
apache kafka系列之原始碼分析走讀-kafka內部模組分析
apache kafka中國社群QQ群:162272557 kafka整體結構分析: kafka原始碼工程目錄結構如下圖: 下面只對core目錄結構作說明,其他都是測試類或java客戶端程式碼 admin --管理員模組,操作和管理topic,parit