
從零快速搭建自己的爬蟲系統
近期由於工作原因,需要一些資料來輔助業務決策,又無法通過外部合作獲取,所以使用到了爬蟲抓取相關的資料後,進行分析統計。在這個過程中,也看到很多同學爬蟲相關的文章,對基礎知識和所用到的技術分析得很到位,只是缺乏快速的實戰系統搭建指導。
本文將簡單歸納網頁爬蟲所需要的基礎知識,著重於實現一套完整可用的小型網頁爬取、分析系統,方便大家在有需要時,能夠快速搭建系統,以用到實踐中去。
關於網頁爬蟲的定義和用途,想必做技術的都有所瞭解,這裡就不再贅述。目前, 大家使用爬蟲的目的除搜尋引擎屬於無差別爬取外,其他多用於垂直領域或特定網站內容的爬取,本文以特定網站內容爬取作為切入點,當然,也可以應用於垂直領域。
一套合格的網頁爬取、分析系統,大致分為:網頁抓取、網頁分析與連結發現、任務去重與排程、資料預處理與儲存、防反爬蟲策略、進度展示等幾個重要方面。下邊逐一做簡單歸納介紹。
一、基礎知識
(1)網頁爬取
網頁讀取,即讀取給定網頁的完整內容,包含非同步載入的內容,也就是完整地呈現到瀏覽器視窗的內容。
隨著智慧手機的普及,網頁普遍分為 PC 端 和 移動裝置端,由於不同端的網速、流量、裝置速度、螢幕大小等原因,移動裝置端多采用非同步載入的方式來優化使用者體驗,timeline 型別的無縫翻頁就是最佳的例子。這導致常用的 python requests, python urlib, wget, curl 等獲取到的網頁內容不完整,只有網頁的骨架而無內容,內容需要等待 JS 非同步載入。
這種問題的解決,我們一般使用帶 JS 執行引擎的瀏覽器驅動來執行網頁內的非同步載入 JS,解決非同步載入問題。常見的解決方案是 selenium 自動化瀏覽器測試元件配合 chromedriver 或 firfoxdriver 這些有介面瀏覽器來使用,如果是 linux 伺服器命令列下,則可配合 phantomjs 這款無介面瀏覽器。
python selenium 安裝:pip install selenium
這裡附上簡單的應用示例程式碼:
from selenium import webdriver
browser = webdriver.Chrome() # 使用 ChromeDriver,需要安裝
browser.get("http://www.baidu.com")
browser.find\_element\_by\_id("kw").send\_keys("selenium")
browser.find\_element\_by\_id("su").click()
dir( browser ) # 檢視所有屬性和方法
print browser. (2)網頁分析與連結發現
網頁分析,即將爬取到的網頁內容進行分析,提取需要的內容。**連結發現**,即提取該網頁中需要進一步爬取的 URI 地址,或者利用網頁內資訊構建 URI 地址。
網頁分析所針對的內容,大致分為:結構化內容(如 HTML 和 JSON)、半結構化內容(如一條含 JSON 的 JS 語句),非結構化內容(如純 txt)。(嚴格意義上說,結構化內容為固定的類似資料庫二維表一樣的內容,這裡僅針對網頁內容做適當的分類調整)
針對 HTML ,推薦使用 **pyquery** 進行分析。pyquery 的使用非常簡單,用於爬蟲時也無需用到高階特性,常用方法如下例所示:
from pyquery import PyQuery as pq
web = pq( "http://www.qq.com" )
print web("title").text() # 列印標題
print web("span#guess").text() # 列印 <span id="guess"> WWWQQCOM </span> 標籤區域的文字
print web("span.undis").text() # 列印 <span class="undis"> 騰訊網 </span> 標籤區域的文字
print web('a.qqlogo').attr('href') # 列印 <a href="www.qq.com" class="qqlogo"> 騰訊網 </a> 的連線內容 針對 JSON,可使用 python 原生的 **json** 模組進行分析。
針對半結構化的內容,則需要特定的分析,一般格式固定,如新增定長的字首和字尾,但此處無法通用,針對性強,比如含有 JSON 內容,只能固定暴力地將其提取出來再分析。
(3)任務去重與排程
主要是防止網頁的重複抓取,比如 A 中包含了 B 的地址,B 中又包含了返回 A 的地址,如果不做去重,則容易造成爬蟲在 A 和 B 間死迴圈的問題。但同時也要注意去重的時間視窗,無限期的去重將導致網頁內容無法重新爬取被更新。排程是從系統特性的角度出發,網頁爬取的主要耗時是在 網路互動,等待一個網址進行 DNS 解析、請求、返回資料、非同步載入完成等,需要幾秒甚至更長的時間。小批量任務情況下,簡單地使用多執行緒(thread)、多程序(subprocess)都可以解決問題,python 2.7,也可以使用 twitter 開源的 tornado 框架內的 coroutine 模組做協程,python 3.4 本身也提供了非同步 async 關鍵字。
(4)資料儲存與預處理、防反爬蟲策略、進度展示
資料預處理,即篩掉無用的內容,並格式化有用資料,降低儲存的壓力和資料大小,也方便後期分析處理。一般網頁抓取時,需要的是展現在使用者面前的文字和圖片資訊,而網頁內的 css 樣式表、js 程式碼等則不那麼關心,這時,同樣推薦使用 pyquery 進行資料提取,簡直方便好用(不過 pyquery 存在一些小 bug,標籤解析在特定情況下易被 '>' 打斷)。防反爬蟲則可以搜尋下"防爬蟲""反爬蟲"等關鍵字,看下實現原理,如果目標網站有,進行鍼對性破解即可,一般採用隨機 User-Agent 和 降頻等策略都可以繞過,掛代理換 IP 就會麻煩一些,不過大多數瀏覽器驅動也都支援。
(5)資料展示
這是額外的說明,爬取到資料後,進行資料統計分析之後,是要用來輔助決策的,要展示給老闆或產品看的,如何直觀地將成果展示出來呢?這時推薦使用 JS 的 Highcharts 元件進行資料展示。github 上有 Highcharts 的 python 封裝,但使用起來比較麻煩,學習還需要耗費不少時間,這裡封裝了幾個常用圖表形式的簡易 python 介面,如果需要其他型別的圖,按照 highcharts 的文件進行和已有程式碼稍加擴充套件即可擴充,簡單易用。(程式碼整理上傳後貼連結)
二、常見爬蟲實現
基礎知識介紹完後,我們來搭建實際的系統。不管是自己動手,還是使用做好的框架或者產品,都需要知道自己的目的是什麼,要達到什麼樣的目的,如果想加深知識學習,那無疑自己動手做一套是最合適的,如果是需要快速完成工作,最好是使用現成的框架或產品。
(1)自己動手
如果想自己開發一個的話,作者也是支援的,簡單開發將基礎元件聯動起來,也可以完成任務,雖然坑比較多,尤其是異常環節處理以及編碼問題的解決。但話說回來,經驗不就是從踩過的坑中學習的嗎?如果想在這方面有所作為,自己寫或仿寫都是必不可少的學習途徑。
由於自己開發的起點層次有很多,最底層的可以從自己建 TCP 連結解析 http 協議開始,也可以從利用已有 http 開發庫開始(求別說最底層應該從寫作業系統或協議棧開始。。。)。
常見的使用 python 開發爬蟲的**套路**:
**subrpocess/thread 做多程序任務分發 requests/selenium 網頁抓取 pyquery 網頁分析加連結生成 db 或 shelve 做結果儲存 自定義資料統計分析 matlab/highcharts 做報表圖。**
其中,網頁獲取可以用 urllib 來替代,pyquery 也可以用 beautifulsoup 或正則來替代,但這兩者都不推薦,用起來比 requests pyquery 麻煩。
db 常用的就是 sqlite,shelve 可以用來儲存 python 物件,如果你的資料分析也是 python 指令碼實現,shelve 無疑可以降低不少解析時間。
matlab 做報表圖是畫報表後生成圖片格式。這裡也建議使用 highcharts 來做報表,只是 highcharts 生成的結果是展示成網頁形式,動態渲染。
在常見的**報表知會**場景中大致分為兩種:1、發定期郵件看走勢;2、網頁展示。如果需要定期郵件,公司內部有提供從 server 傳送郵件/rtx 的工具,可以找運維要一下。但是該工具限制無法直接傳送圖片,通過將郵件做成 html 格式,將圖片轉為 base64 內嵌進 html 即可。
那麼如何將 **highcharts 生成的報表匯出圖片**呢?新版本的 highcharts 有提供介面,但並不是很好用,因為你的報表也不僅僅是一個圖,多個圖還要手工拼裝,根據郵件客戶端的不同,有可能展示的樣式也會有變化。 這裡我們仍然可以使用 phantomjs 來完成,原理就是使用瀏覽器對渲染後的頁面進行整頁截圖。實現的原理也比較簡單,使用 js 程式碼,控制瀏覽器直接以圖片形式渲染網頁,之後儲存。由於該需求反響強烈,phantomjs 官網也提供瞭解決方案:http://phantomjs.org/screen-capture.html,即下載 rasterize.js,按照下面命令來執行截圖。
這個命令的含義是使用 phantomjs 執行 rasterize.js 渲染 my_html.html 並將結果儲存到 tmp.png 中。
$ phantomjs rasterize.js ./my\_html.html ./tmp.png
生成截圖的過程中有**可能遇到的坑**,在這裡也提一下,希望後來的同學不會再因為這個問題浪費時間:首先,控制 phantomjs 進行截圖的時候,有可能截圖不完整,這是因為網頁有一個動畫繪製的過程(如 highcharts 圖表頁),可以修改 rasterize.js 內設定的預設 200ms 的超時渲染時間到 5000ms 甚至更長,保證網頁載入完後再截圖。另外,在公司環境下,爬蟲多部署在 server 端的 linux 系統下,伺服器系統很少安裝字型檔案,如果截圖出的內容中文字缺失或跟本地預覽樣式不符,一般就是這個問題了。
(2) scrapy
如果到百度或者谷歌上搜 python 爬蟲關鍵字的話,你肯定會看到有不少人推薦使用 scrapy。scrapy 是不錯的爬蟲庫,或者說是爬蟲框架,著重實現了上述的 網頁爬取、任務去重排程功能,也提供網頁內容分析,不過是 xpath 的形式。其他方面,如 結果儲存 和 進度展示 需要開發者自己完成,也沒有提供簡便的頻控防反爬蟲策略的功能。
(3) pyspider
pyspider,是近幾年國人開發的一款爬蟲產品,之所以提升到產品級別,是因為該框架提供了相當完善的爬蟲全流程的功能。從網頁爬取,到內容分析,再到頻控,定時重新整理,資料儲存,分散式部署等,做得可圈可點,且相當易用,也是本文重點推薦的系統。
pyspider 簡單的二次開發介面,同時自帶了一個頁面開發偵錯程式。在實際的應用中,配合 phantomjs 進行頁面渲染獲取動態載入資料非常方便。
這裡的我們先看使用方法,體驗一下 pyspider 的強大和易用,再來介紹該框架的架構和實現方法。
安裝:
pip install pyspider
執行:
pyspider
如果已安裝 phantomjs,則可使用 $ pyspider all 來配合使用。
訪問、開發:
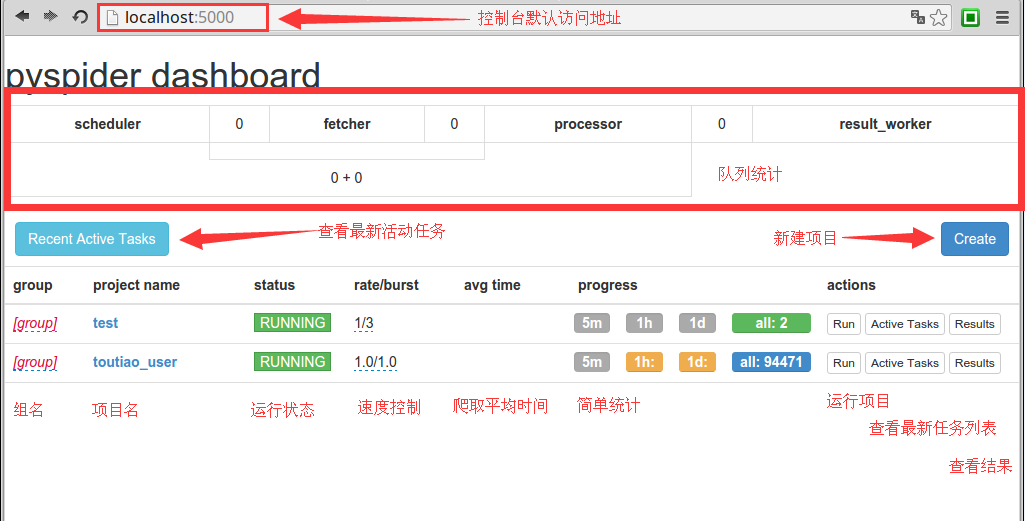
Create project 後,直接點選 project ,即可進入**頁面式的開發除錯環境**,非常方便。
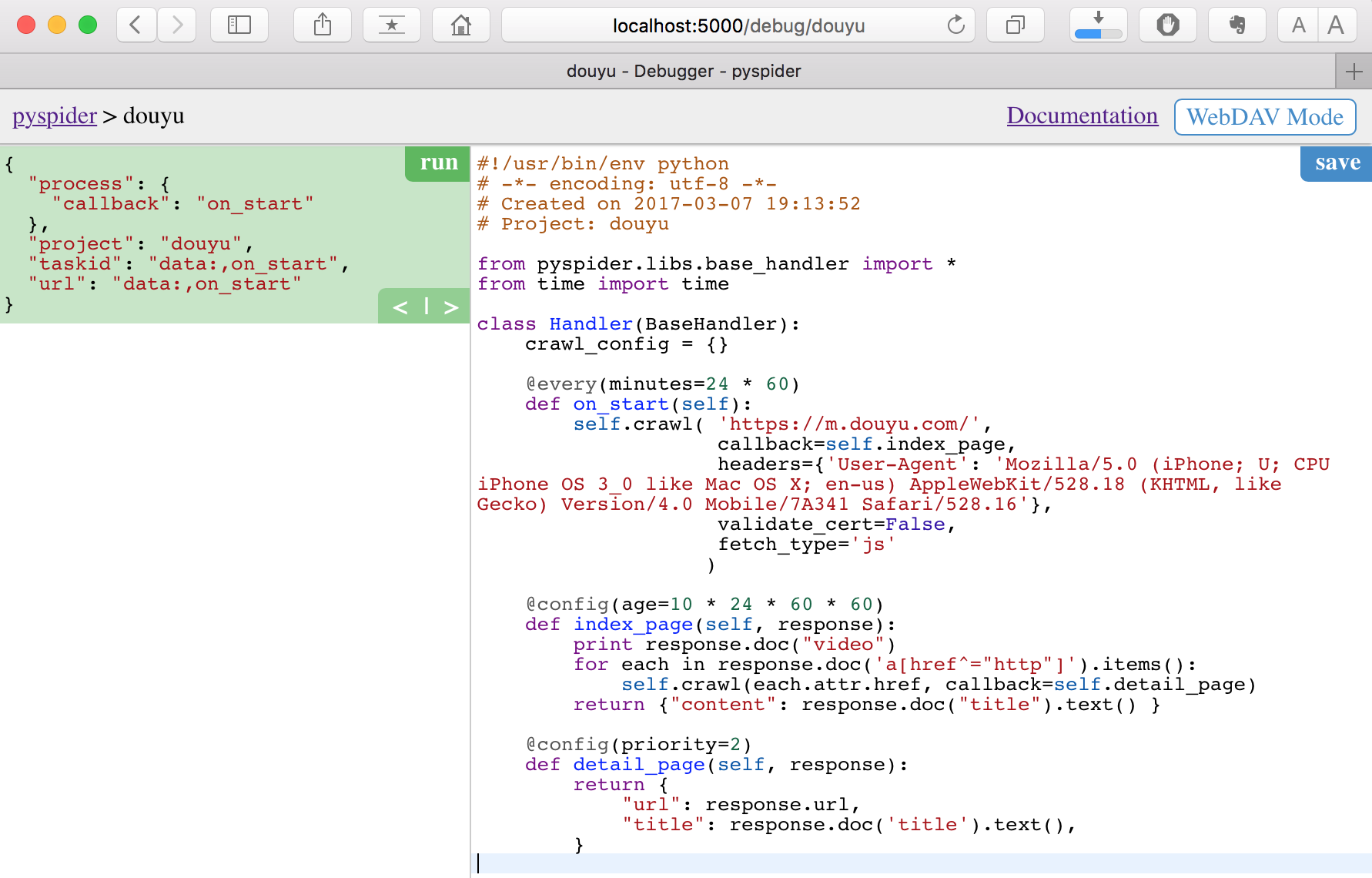
我們以 douyu 的一個簡單例子來介紹下**二次開發程式碼的含義**

之後點選右上角 save 後,返回首頁,修改 project status 和 rate/burst 後, 點選 run 即可執行:

關於 rate/burst,這裡是**採用令牌桶做的頻控**,這裡設定 0.1/5 的含義是:rate = 0.1 每秒發起 0.1 個請求,即 10s 一個請求,耗費一個令牌;burst = 5,最多併發發起 5 個請求,即耗費 5 個令牌,那麼也意味著併發後,第 6 個請求,要等待 50s。
另外,pyspider 安裝完即可用,預設採用 sqlite 作為資料庫,單機部署,使用本機的 phantomjs 和 xmlrpc。單機效能不足以支撐時,也可以支援各模組的分散式部署。如果需要分散式部署,就需要了解下 pyspider 的架構情況,和基本的實現原理。
下面來簡要地看一下pyspider 的架構:
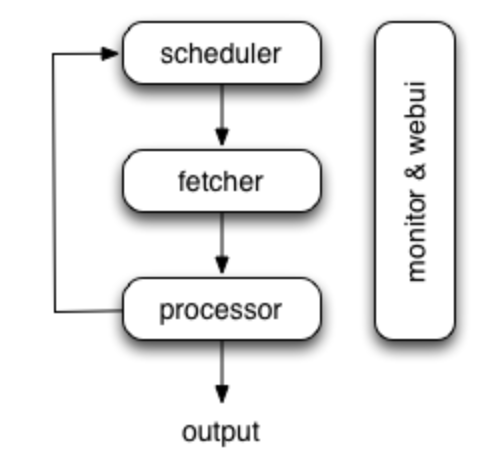
從圖中可以看出,pyspider 主要的構成模組為 排程器 scheduler,網頁爬取 fetcher,資料預處理與連結發現 processor,output 到資料庫,還有 web 頁面的進度監控、運營。
結合上述談到的爬蟲幾大塊,淺顯地看一下 pyspider 的實現:
webui部分,使用 flask 模組實現。
fetcher部分使用 tornado 的 gen 模組內的 coroutine 做協程,當 fetch_type = 'js' 的時候則連結 phantomjs 進行資料的爬取,否則直接非同步爬取。
processor處理階段,提供了 pyquery 解析物件 repsonse.doc,也可以直接訪問頁面原始碼進行解析,連結發現需要使用者自己完成,pyquery 也提供了方便的介面 reponse.doc('a') 即可篩選出所有的 <a > 標籤物件。
任務排程,pyspider 採用資料庫來儲存需要的任務,taskid = md5sum( URL ) 為 primary key 儲存每個任務連結上次執行的時間以及更新時間,以此方式去重和篩選出可執行的任務,放入內部執行佇列中,由 fetcher 提取執行。表結構如下:
CREATE TABLE `taskdb\_douyu\_pro` (
taskid PRIMARY KEY,
project,
url, status,
schedule, fetch, process, track,
lastcrawltime, updatetime
);
CREATE INDEX `status\_taskdb\_douyu\_pro\_index` ON `taskdb\_douyu\_pro` (status);**資料儲存**,也是可配置的,但幾十萬連結的小量,還是可以用 sqlite 來儲存。表結構如下:
CREATE TABLE `resultdb\_douyu\_pro` (
taskid PRIMARY KEY,
url,
result,
updatetime
);三、一些遺留的問題及小技巧
1、pyspider 使用 phantomjs 抓取頁面時發現,當請求量較大,會存在 phantomjs 有大量連結未關閉,從而停止響應。沒有深入定位具體原因,採用暴力定時重啟 phantomjs 的方式來解決了,有遇到的同學可以深入定位一下。
2、另外,selenium phantomjs 是可以通過執行 js 程式碼來操作瀏覽器動作的,所以遇到翻頁自動載入的情況,可以尋找頁內的 more 元素傳送 click() 事件。
3、如果目標網站量較少,不妨試一下手機端的站點,一般手機端站點為了優化使用者體驗,都提供了非同步載入功能,提供非同步載入,則很大可能是使用 ajax 進行 json 明文形式的查詢和結果返回,可以通過 chrome 的 F12 或 safari 的響應式設計模式,記錄請求 timeline,直接定位到網站自身提供的 restAPI 查詢介面,要比解析網頁事半功倍了。
相關推薦
從零快速搭建自己的爬蟲系統
近期由於工作原因,需要一些資料來輔助業務決策,又無法通過外部合作獲取,所以使用到了爬蟲抓取相關的資料後,進行分析統計。在這個過程中,也看到很多同學爬蟲相關的文章,對基礎知識和所用到的技術分析得很到位,只是缺乏快速的實戰系統搭建指導。本文將簡單歸納網頁爬蟲所需要的基礎知識,著重
從零開始搭建自己的VueJS2.0+ElementUI單頁面網站(一、環境搭建)
如圖所示 增刪改 type default sdn orm rain exp 名稱 原網址:https://blog.csdn.net/u012907049/article/details/72764151 前言 VueJS可以說是近些年來最火的前端框架之一,越來越多的
【從零開始搭建自己的.NET Core Api框架】(二)搭建項目的整體架構
config 七層 數據 TP 暫時 整體架構 比較 架構 其他 本來打算將搭建項目架構和集成SqlSugar放在一起講的,但是感覺東西有點多,還是分成兩章吧~ 這一章講搭建項目的整體架構,這裏先把搭建完成後的最終效果放出來,然後再逐個解釋每層的作用。 可以看到這裏一
【從零開始搭建自己的.NET Core Api框架】(三)集成輕量級ORM——SqlSugar:3.3 自動生成實體類
i++ 點運算 自己的 yui content project style ref 數據庫表 系列目錄 一. 創建項目並集成swagger 1.1 創建 1.2 完善 二. 搭建項目整體架構 三. 集成輕量級ORM框架——SqlSugar 3.1 搭建環境
【從零開始搭建自己的.NET Core Api框架】(六)泛型倉儲的作用
tar write ges 分享圖片 () dex 抽象 .sql cut 系列目錄 一. 創建項目並集成swagger 1.1 創建 1.2 完善 二. 搭建項目整體架構 三. 集成輕量級ORM框架——SqlSugar 3.1 搭建環境 3.2 實戰篇:
LFS 8.3 從零開始做自己的系統(二)~!~
cif dump ras x86-64 users setup ace trace 找到你 六、構建LFS系統 1.準備虛擬內核文件系統 1)創建將掛載文件系統的目錄:mkdir -pv $LFS/{dev,proc,sys,run}2)創建設備節點:mknod -m 60
LFS 8.3 從零開始做自己的系統(一)~!~
網站 acc multi sda ica 光盤 erl 主機系統 再次 此文是寫給新手的教程~!~我會盡量寫的詳細一些。虛擬機軟件:我選的是VirtualBox,版本:4.3.12 r93733。如果用vmware的話,設置方面基本差不多。縮主機系統:我用的是debian
vue從入門到女裝??:從零開始搭建後臺管理系統(一)安裝框架
安裝及執行都是基於node的,不會node的可以自行百度,網上教程很多,也不難 專案效果預覽: demo1 demo2 原始碼下載 開始安裝框架: vue element-ui 注意如果報錯安裝失敗就重新安裝,不然雖然本地有element的依賴包但是可能會出一些奇怪的錯誤 另外element-ui
從零開始搭建完整分散式系統
1. 執行平臺:CentOS 6.3 x86_64,基本等同於RHEL 6.32. 安裝方法:安裝MySQL主要有兩種方法:一種是通過原始碼自行編譯安裝,這種適合高階使用者定製mysql的特性,這裡不做說明;另一種是通過編譯過的二進位制檔案進行安裝。二進位制檔案安裝的方法又分為兩種:一
如何從零開始搭建自己的部落格(通俗易懂)
序 作為一名合(zhuang)格(bi)的程式猿,經常寫點東西,肯定少不了各種網站、部落格,通俗的CSDN,文藝的簡書,強大的GitHub,以及微信、掘金、知乎等等風格迥異的平臺。不過,再多的地方,也容不下一顆想捯飭的心,不管什麼網站,都有自己固定的模板,統一的風格,這怎麼
從零開始搭建自己的網站二:Springboot專案框架搭建
上一篇文章中,講的第一、二步購買伺服器和繫結域名,我就不細細講了。本文中會講解如何構建一個基本的Springboot+freemarker+mybatis專案框架 1、先建立Gradle專案,用Gradle來管理我們的專案。 2、建立目錄結構 3、具體程式碼 1)bui
什麼是devops,基於Gitlab從零開始搭建自己的持續整合流水線(Pipeline)
一、gitlab 實現的 auto devops 1. DevOps中的一些概念與原則 (1) 什麼是持續整合 持續整合(Continuous integration,簡稱CI)指的是,頻繁地(一天多次)將程式碼整合到主幹。 它的好處主要有兩個。
Vue+ElementUI從零開始搭建自己的網站(三、元件間的通訊)
前面討論了環境的搭建和導航頁面以及路由的配置,今天我們討論下如何開發一個擁有表單和表格功能的頁面。先上開發完的效果圖: 可以看出頁面非常的簡單,其中上半部分是表單搜尋和查詢,下半部分是用於展示資料的表格。如果按照傳統的開發思路,其實非常簡單,只要用兩個div,第一個d
基於ionic+cordova+angularJs從零開始搭建自己的移動端H5 APP
這裡詳細介紹下如何用ionic+cordova+angularjs搭建自己的移動端app,包括環境搭建,框架使用等,具體專案已放置在github上,可下載下來自行啟動。 下載地址:https://github.com/foreverjiangting/myApp/
一、從零開始搭建自己的靜態部落格 -- 基礎篇
目錄 1. 準備環境 2. 新建專案 3. 第一篇博文 4. 修改配置檔案 5. 本地構建和訪問 6. markdown解析異常 6.1. Markdown包的
二、從零開始搭建自己的靜態部落格 -- 主題篇
目錄 1. 下載主題 2. 使用主題 2.1. 基本配置 2.2. 高階配置 2.2.1. 配置網站圖示 2.2.2. 更新Font Awesome的版本 2.
微信公共號(企業號)開發框架-gochat的從零開始教程(二): 5分鐘快速搭建自己的公共號
上一章裡我們把前期準備和環境配置已經完成啦,本章講一下怎麼通過5分鐘快速搭建自己的公共號~ 首先,前往github頁面下載gochat框架的原始碼 ,原始碼中已經包含了一個最基礎的公共號開發模版。(這裡非常非常希望大家在下載的
從零開始搭建ELK+GPE監控預警系統
elasticsearch logstash kibana redis grafana prometheus exporter consul前言本文可能不會詳細記錄每一步實現的過程,但一定程度上可以引領小夥伴走向更開闊的視野,串聯每個環節,呈現予你不一樣的效果。業務規模8個平臺100+臺服務器10+個集群分
從零開始搭建系統3.4——緩存組件開發
搭建 html OS get gpo target 開發 href 系統 從零開始搭建系統3.4——緩存組件開發從零開始搭建系統3.4——緩存組件開發
從零開始搭建系統2.7——Quartz安裝及配置
get AR blank 安裝 pos html uart body cnblogs 從零開始搭建系統2.7——Quartz安裝及配置從零開始搭建系統2.7——Quartz安裝及配置