
Python資料分析之pandas統計分析
pandas模組為我們提供了非常多的描述性統計分析的指標函式,如總和、均值、最小值、最大值等,我們來具體看看這些函式:
1、隨機生成三組資料
import numpy as np
import pandas as pd
np.random.seed(1234)
d1 = pd.Series(2*np.random.normal(size = 100)+3)
d2 = np.random.f(2,4,size = 100)
d3 = np.random.randint(1,100,size = 100)2、統計分析用到的函式
d1.count() #非空元素計算
d1.min - 必須注意的是,descirbe方法只能針對序列或資料框,一維陣列是沒有這個方法的
自定義一個函式,將這些統計指標彙總在一起:
def status(x) :
return pd.Series([x.count(),x.min(),x.idxmin(),x.quantile(.25),x.median(),
x.quantile(.75 執行該函式,檢視一下d1資料集的這些統計函式值:
df = pd.DataFrame(status(d1))
df結果:
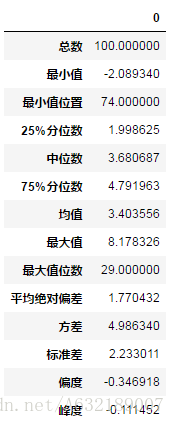
在實際的工作中,我們可能需要處理的是一系列的數值型資料框,如何將這個函式應用到資料框中的每一列呢?可以使用apply函式,這個非常類似於R中的apply的應用方法。
將之前建立的d1,d2,d3資料構建資料框:
df = pd.DataFrame(np.array([d1,d2,d3]).T, columns=['x1','x2','x3'])
df.head()
df.apply(status)結果:
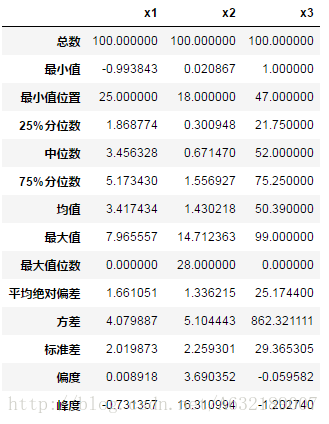
3、載入CSV資料
import numpy as np
import pandas as pd
bank = pd.read_csv("D://bank/bank-additional-train.csv")
bank.head() #檢視前5行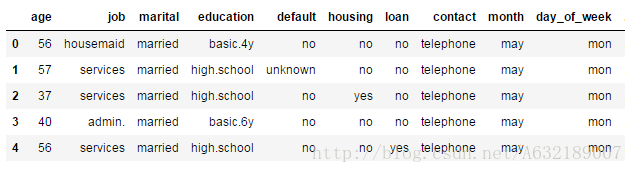
描述性統計1:describe()
result = bank['age'].describe()
pd.DataFrame(result ) #格式化成DataFrame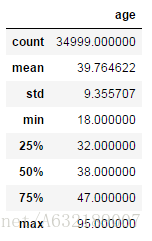
描述性統計2:describe(include=[‘number’])
include中填寫的是資料型別,若想檢視所有資料的統計資料,則可填寫object,即include=['object'];若想檢視float型別的資料,則為include=['float']。
result = bank.describe(include=['object'])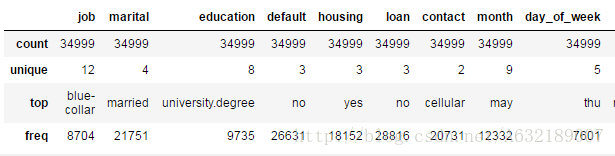
含義:
- count:指定欄位的非空總數。
- unique:該欄位中儲存的值型別數量,比如性別列儲存了男、女兩種值,則unique值則為2。
- top:數量最多的值。
- freq:數量最多的值的總數。
bank.describe(include=['number'])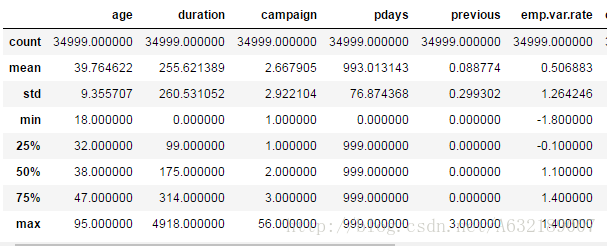
連續變數的相關係數(corr)
bank.corr()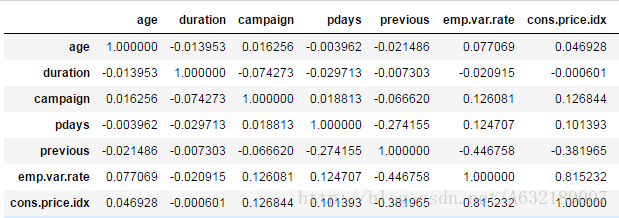
協方差矩陣(cov)
bank.cov()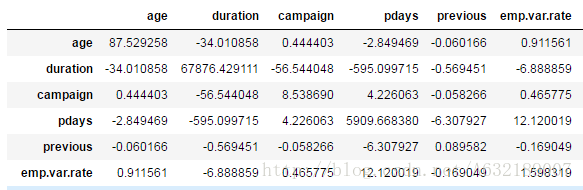
刪除列
bank.drop('job', axis=1) #刪除年齡列,axis=1必不可少排序
bank.sort_values(by=['job','age']) #根據工作、年齡升序排序
bank.sort_values(by=['job','age'], ascending=False) #根據工作、年齡降序排序多表連線
準備資料:
import numpy as np
import pandas as pd
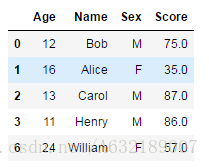
student = {'Name':['Bob','Alice','Carol','Henry','Judy','Robert','William'],
'Age':[12,16,13,11,14,15,24],
'Sex':['M','F','M','M','F','M','F']}
score = {'Name':['Bob','Alice','Carol','Henry','William'],
'Score':[75,35,87,86,57]}
df_student = pd.DataFrame(student)
df_student
df_score = pd.DataFrame(score)
df_scorestudent:
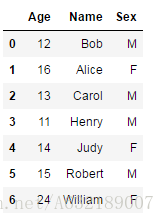
score:
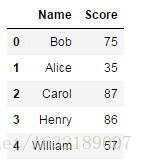
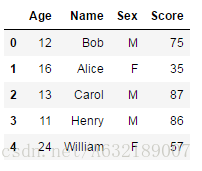
內連線
stu_score1 = pd.merge(df_student, df_score, on='Name')
stu_score1- 注意,預設情況下,merge函式實現的是兩個表之間的內連線,即返回兩張表中共同部分的資料。可以通過how引數設定連線的方式,left為左連線;right為右連線;outer為外連線。
左連線
stu_score2 = pd.merge(df_student, df_score, on='Name',how='left')
stu_score2- 左連線中,沒有Score的學生Score為NaN
缺失值處理
現實生活中的資料是非常雜亂的,其中缺失值也是非常常見的,對於缺失值的存在可能會影響到後期的資料分析或挖掘工作,那麼我們該如何處理這些缺失值呢?常用的有三大類方法,即刪除法、填補法和插值法。
刪除法
當資料中的某個變數大部分值都是缺失值,可以考慮刪除改變數;當缺失值是隨機分佈的,且缺失的數量並不是很多是,也可以刪除這些缺失的觀測。
替補法
對於連續型變數,如果變數的分佈近似或就是正態分佈的話,可以用均值替代那些缺失值;如果變數是有偏的,可以使用中位數來代替那些缺失值;對於離散型變數,我們一般用眾數去替換那些存在缺失的觀測。
插補法
插補法是基於蒙特卡洛模擬法,結合線性模型、廣義線性模型、決策樹等方法計算出來的預測值替換缺失值。
- 此處測試使用上面學生成績資料進行處理
查詢某一欄位資料為空的數量
sum(pd.isnull(stu_score2['Score']))
結果:2直接刪除缺失值
stu_score2.dropna()刪除前:
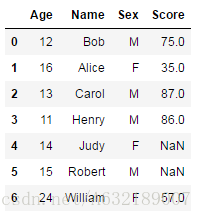
刪除後:
- 預設情況下,dropna會刪除任何含有缺失值的行
刪除所有行為缺失值的資料
import numpy as np
import pandas as pd
df = pd.DataFrame([[1,2,3],[3,4,np.nan],
[12,23,43],[55,np.nan,10],
[np.nan,np.nan,np.nan],[np.nan,1,2]],
columns=['a1','a2','a3'])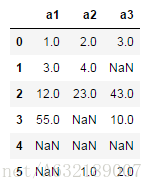
df.dropna() #該操作會刪除所有有缺失值的行資料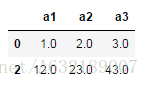
df.dropna(how='all') #該操作僅會刪除所有列均為缺失值的行資料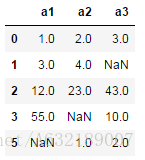
填充資料
使用一個常量來填補缺失值,可以使用fillna函式實現簡單的填補工作:
1、用0填補所有缺失值
df.fillna(0)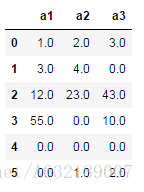
2、採用前項填充或後向填充
df.fillna(method='ffill') #用前一個值填充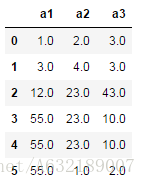
df.fillna(method='bfill') #用後一個值填充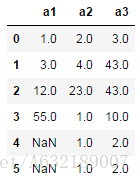
3、使用常量填充不同的列
df.fillna({'a1':100,'a2':200,'a3':300})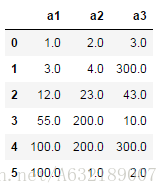
4、用均值或中位數填充各自的列
a1_median = df['a1'].median() #計算a1列的中位數
a1_median=7.5
a2_mean = df['a2'].mean() #計算a2列的均值
a2_mean = 7.5
a3_mean = df['a3'].mean() #計算a3列的均值
a3_mean = 14.5
df.fillna({'a1':a1_median,'a2':a2_mean,'a3':a3_mean}) #填充值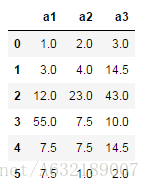
- 很顯然,在使用填充法時,相對於常數填充或前項、後項填充,使用各列的眾數、均值或中位數填充要更加合理一點,這也是工作中常用的一個快捷手段。
資料打亂(shuffle)
實際工作中,經常會碰到多個DataFrame合併後希望將資料進行打亂。在pandas中有sample函式可以實現這個操作。
df = df.sample(frac=1)- 這樣對可以對df進行shuffle。其中引數frac是要返回的比例,比如df中有10行資料,我只想返回其中的30%,那麼frac=0.3。
有時候,我們可能需要打混後資料集的index(索引)還是按照正常的排序。我們只需要這樣操作
df = df.sample(frac=1).reset_index(drop=True) 相關推薦
Python資料分析之pandas統計分析
pandas模組為我們提供了非常多的描述性統計分析的指標函式,如總和、均值、最小值、最大值等,我們來具體看看這些函式: 1、隨機生成三組資料 import numpy as np import pandas as pd np.random.seed
Python資料分析之pandas資料視覺化 python
Python資料視覺化常用的是matplotlib庫,matplotlib是底層庫,今天學了pandas的資料視覺化,相對於matplotlib庫來說,簡單許多。 折線圖 %matplotlib inline import numpy as np import
Python-資料分析-Pandas統計分析基礎2
前些日子一直在忙實驗,結束後又去忙其他事情,看完了Pandas一直沒有時間寫筆記,今天忙裡偷閒再寫一篇Pandas DataFrame是最常用的Pandas物件,類似於Microsoft Office Excel表格,完成資料讀取後,DataFrame資
Python資料分析之pandas入門
一、pandas庫簡介 pandas是一個專門用於資料分析的開源Python庫,目前很多使用Python分析資料的專業人員都將pandas作為基礎工具來使用。pandas是以Numpy作為基礎來設計開發的,Numpy是大量Python資料科學計算庫的基礎,pandas以此為基礎,在計算方面具有很高的效能
Python資料分析之pandas學習(二)
有關pandas模組的學習與應用主要介紹以下8個部分: 1、資料結構簡介:DataFrame和Series 2、資料索引index 3、利用pandas查詢資料 4、利用pandas的DataFrames進行統計分析 5、利用pandas實現SQL操作 6、利用panda
(轉載)Python資料分析之pandas學習
轉載地址:http://www.cnblogs.com/nxld/p/6058591.html Python中的pandas模組進行資料分析。 接下來pandas介紹中將學習到如下8塊內容: 1、資料結構簡介:DataFrame和Series 2、資料索引index 3
Python資料分析之pandas學習
Python中的pandas模組進行資料分析。 接下來pandas介紹中將學習到如下8塊內容: 1、資料結構簡介:DataFrame和Series 2、資料索引index 3、利用pandas查詢資料 4、利用pandas的DataFrames進行統計分析 5、利用pa
python資料分析之pandas學習一
連結(官網文件):點選這裡 Pandas是python第三方庫,提供高效能易用資料型別和分析工具。import pandas as pd pandas基於Numpy實現,常與Numpy和Matplotlib一同使用。 Numpy pandas(Series+dat
Python資料分析之pandas基本資料結構:Series、DataFrame
1引言 本文總結Pandas中兩種常用的資料型別: (1)Series是一種一維的帶標籤陣列物件。 (2)DataFrame,二維,Series容器 2 Series陣列 2.1 Series陣列構成 Series陣列物件由兩部分構成: 值(value):一維陣列的各元素值,是一個ndarr
資料分析之pandas知識梳理
Series及DataFrame部分知識梳理 一、Series索引與切片 首先匯入pandas和Series import pandas as pd from pandas import Series 顯式索引: 使用index中的元素作為索
資料分析之pandas入門
概念 Python Data Analysis Library 或 pandas 是基於NumPy 的一種工具,該工具是為了解決資料分析任務而建立的。Pandas 納入了大量庫和一些標準的資料模型,提供了高效地操作大型資料集所需的工具。pandas提供了大量能使我們快速便捷地處理資料的
資料分析之pandas計算A股節日效應持續更新【內向即完敗--王奕君】
'''計算7年大盤節日效應的前兩天後兩天與當天開市的單期收益率的累加和個股節日單期收益率累加的比較,選出能跑贏大盤的 節日效應以國定假日為主:元旦|春節|清明節|勞動節|端午節|中秋節|國慶節,其中端午節,中秋節,清明節只計算前一天和當天的單期收益率,''' 其中以國慶節+
資料分析之Pandas——資料結構
資料結構介紹 Pandas的資料物件中都包含最基本的屬性,如資料型別,索引,標籤等。 要使用Pandas的資料結構首先需要引入pandas和numpy: In [1]: import numpy as np In [2]: import pandas
資料分析介紹之七——單變數資料觀察之彙總統計和箱線圖
模組提供了高效、便捷的numpy Python大數值陣列的處理。它的前身是無論是早前的數字和替代Numarray模組。(見附錄A中更多的科學計算與Python。史)的NumPy模組使用的許多其他的庫和專案,在這個意義上是一個“基地”技術。 讓我們在鑽研深入技術
資料分析介紹之六——單變數資料觀察之彙總統計和箱線圖
你可能已經注意到,到目前為止我還沒有在所有關於平均數和中位數、標準差等簡單的主題發言,和百分位數。那是很有意的。這些彙總統計僅適用於某些假設,如果這些假設未實現,則是誤導性的,如果不是完全錯誤的話。我知道這些量是容易理解和容易計算的,但是如果有一條資訊我想讓你從
數據分析之pandas教程-----概念篇
對齊 0.12 概念 sta 等等 valid nbsp get 小數 目錄 1 pandas基本概念1.1 pandas數據結構剖析1.1.1 Series1.1.2 DataFrame1.1.3 索引1.1.4 pandas基本操作1.1.4.1 重索引1
統計分析之單因素分析、多因素分析(多指標聯合分析)與ROC曲線的繪製——附SPSS操作指南
Q1.什麼是單因素分析和多因素分析? 單因素分析(monofactor analysis)是指在一個時間點上對某一變數的分析。目的在於描述事實。 多因素分析亦稱“多因素指數體系
Python資料處理之(一)為什麼要學習 Numpy & Pandas?
今天我們介紹兩個科學運算當中最為重要的兩個模組,一個是numpy,一個是 pandas。任何關於資料分析的模組都少不了它們兩個。 一、主要用途: 資料分析 機器學習 深度學習 二、為什麼使用 numpy & pandas
Python資料處理之(十 一)Pandas 選擇資料
首先先建立一個6X4的矩陣 >>> import pandas as pd >>> import numpy as np >>> dates=pd.date_range('20181121',periods=6) >>
Python資料處理之(十)Pandas 基本介紹
一、Numpy 和 Pandas 有什麼不同 如果用 python 的列表和字典來作比較, 那麼可以說 Numpy 是列表形式的,沒有數值標籤,而 Pandas 就是字典形式。Pandas是基於Numpy構建的,讓Numpy為中心的應用變得更加簡單。 要使用pandas,首先需要