
python資料分析之pandas學習一
連結(官網文件):點選這裡
Pandas是python第三方庫,提供高效能易用資料型別和分析工具。import pandas as pd
pandas基於Numpy實現,常與Numpy和Matplotlib一同使用。
| Numpy | pandas(Series+dataframe) |
| 基礎資料型別 | 擴充套件資料型別 |
| 關注資料的結構表達 | 關注資料的應用表達 |
| 維度:資料間關係 | 資料與索引間關係 |
一 Series型別
Series型別由一組資料及與之相關的資料索引組成。
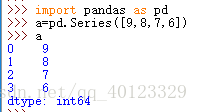
0-3是自動索引,int64為Numpy中資料型別。

Series型別可以由如下型別建立
Python列表 /標量值/Python字典/ndarray/其它函式
1 列表已說
2 標量值(可以自定義索引)

3 字典

4 ndarray

Series型別的基本操作
1 Series型別包括index和values兩部分 .index獲得索引,.values獲得資料

2 Series型別的操作類似於ndarray型別。自動索引和自定義索引可以同時存在,兩套索引並存,但不能混用。
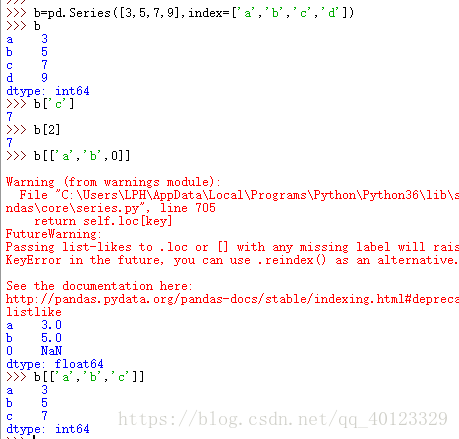
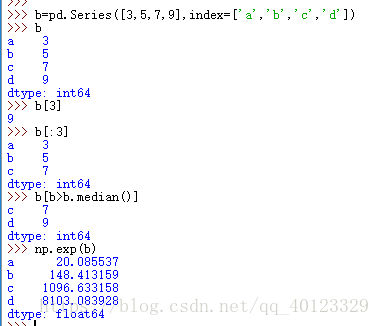
3 Series型別的操作類似Python字典型別(通過自定義索引訪問,保留字in操作,使用.get()方法)

Series的name屬性
Series物件和索引都可以有一個名字,儲存在屬性.name中。

Series物件可以隨時修改並即刻生效。
二 DataFrame型別
DataFrame型別由共用相同索引的一組列組成。由索引(行索引:index和列索引: column)和多列資料組成。
行axis=0,列axis=1
DataFrame是一個表格型的資料型別,每列值型別可以不同。常用於表達二維資料,也可以表達多維資料。
DataFrame型別可以由以下型別建立
1)二維ndarray物件
2)由一維ndarray,列表,字典,元組或Series構成的字典
3)Series型別
4)其他的DataFrame型別
由二維ndarray物件建立

由一維ndarray物件字典建立(資料根據行列索引自動補齊)

從列表型別的字典建立

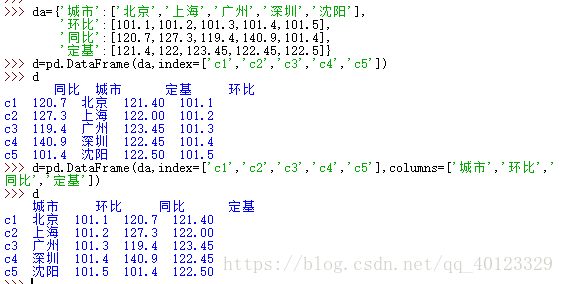

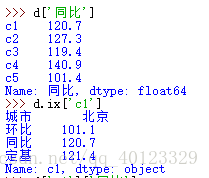
DataFrame是帶標籤的陣列,其基本操作類似於Series,依據行列索引
三 資料型別的操作
改變Series和DataFrame物件(增加或重排:重新索引
刪除:drop)
重新索引.reindex()能夠改變或重排Series和DataFrame索引

.reindex(index=None,columns=None,...)的引數
| 引數 | 說明 |
| index,columns | 新的行列自定義索引 |
| fill_value | 重新索引中,用於填充缺失位置的值 |
| method | 填充方法,ffill為當前值向前填充,bfill向後填充 |
| limit | 最大填充量 |
| copy | 預設為True,生成新的物件,False時,新舊相等不復制。 |


Series和DataFrame的索引都是Index型別,是不可修改的。
索引型別的常用方法
| 方法 | 說明 |
| .append(idx) | 連線另一個Index物件,產生一個新的Index物件 |
| .diff(idx) | 計算差集,產生新的Index物件 |
| .intersection(index) | 計算交集 |
| .union(index) | 計算並集 |
| .delete(loc) | 刪除loc位置處的元素 |
| .insert(loc,e) | 在loc位置增加一個元素e |
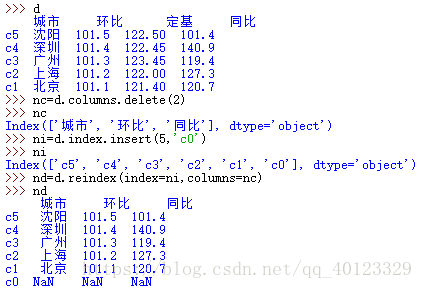
刪除指定索引物件
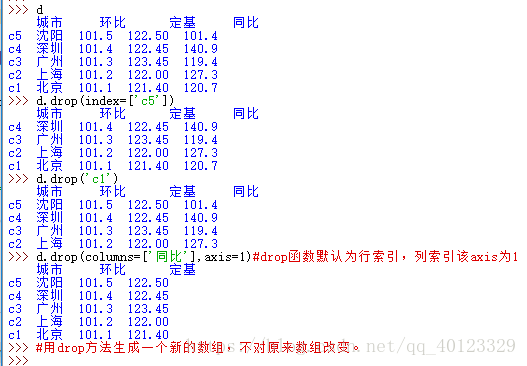
.drop()能夠刪除Series和DataFrame指定行或列索引

四 資料運算
算數運演算法則
算數運演算法則根據行列索引,補齊後運算,運算預設產生浮點數。補齊時缺項值填充NAN(空置)
二維和一維,一維和零維間為廣播運算。採用+-*/符號進行的二元運算產生新的物件。
廣播運算:不同維度之間的運算,低維的元素會作用到高維的每一個元素。
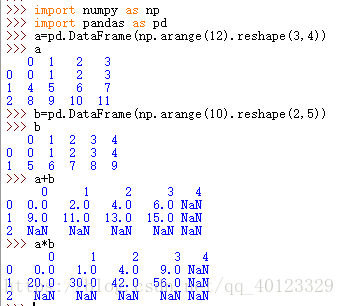
也可以使用方法形式的運算(可以增加引數)
| 方法 | 說明 |
| .add(d,**argws) | 型別間加法運算,可選引數 |
| .sub(d,**argws) | 型別間減法運算,可選引數 |
| .mul(d,**argws) | 型別間乘法運算,可選引數 |
| .div(d.**argws) | 型別間除法運算,可選引數 |

不同維度之間為廣播運算,一維Series預設在軸1進行運算。

使用運算方法可以令一維Series參與軸0運算
。
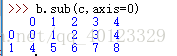
比較運演算法則(只能進行同維度運算,尺寸一致)
比較運算只能比較相同索引的元素,不進行補齊。廣播運算。採用><>=<===!=等符號進行的二元運算產生布爾物件。
五:資料的特徵,統計分析
一組資料表達一個或多個含義。從一組資料提取出摘要(有損地提取資料特徵的過程)。
1 基本統計(含排序)
2 分佈/累計統計
3 資料特徵(相關性,週期性等)
4資料探勘(形成知識)
Pandas庫的資料排序
.sort_index()方法在指定軸上根據索引進行排序,預設升序。
.sort_index(axis=0,ascending=True)


.sort_values()方法在指定軸上根據數值進行排序,預設升序(NaN值同一排放在末尾)
Series.sort_values(axis=0,ascending=True)
DataFrame.sort_valies(by,axis=0,ascending=True)
by:axis軸上的某個索引或索引列表

基本統計分析函式(適用於Series和DataFrame型別)
| 方法 | 說明 |
| .sum() | 計算資料總和,按照0軸 |
| .count() | 非NaN值的數量 |
| .mean() .median() | 計算資料的算數平均值,算數中位數 |
| .var() .std() | 方差,標準差 |
| .min() .max() |
最小/最大值 |
| .argmin() .argmax() | 計算資料最大值和最小值所在位置的索引位置(自動索引) |
| .idxmin() .idxmax() | 計算資料最大值,最小值所在位置的索引(自定義索引) |
| .describe() | 針對0軸(各列)的統計彙總 |

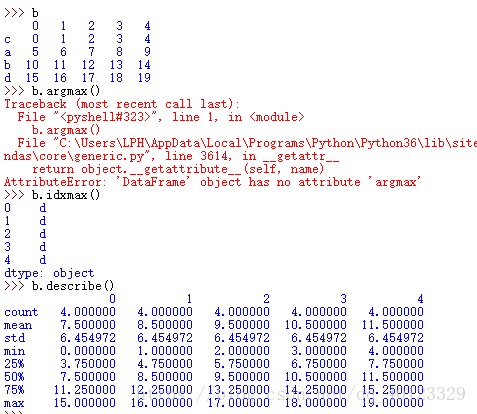
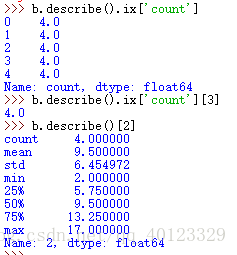
累計統計分析函式(適用於Series和DataFrame型別)
| 方法 | 說明 |
| .cumsum() | 依次給出前1,2,...n個數之和 |
| .cumprod() | 依次給出前1,2,...n個數之積 |
| .cummax() | 依次給出前1,2...n個數的最大值 |
| .cummin() | 最小值 |
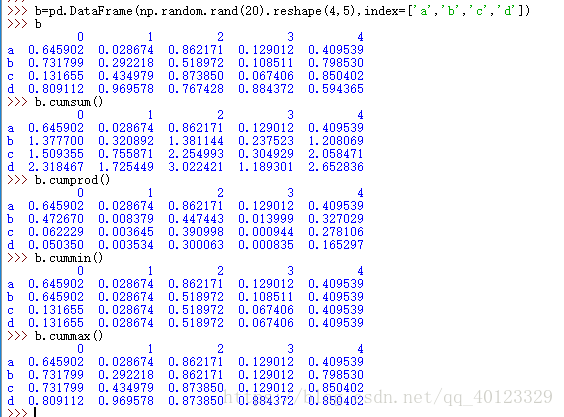
累計統計分析函式(適用於Series和DataFrame型別,滾動計算(視窗計算))
| 方法 | 說明 |
| .rolling(w).sum() |
依次計算相鄰w個元素的和 |
| .rolling(w).mean() | |
| .rolling(w).var() | |
| .rolling(w).std() | |
|
.rolling(w).min() .rolling(w).max() |

相關分析(正相關,負相關,不相關)
Pearson相關係數r
r取值範圍為[-1,1]
0.8-1.0 極強相關
0.6-0.8強相關
0.4-0.6中等相關程度
0.2-0.4弱相關
0-0.2極弱相關或無相關
相關分析函式(適用於Series和DataFrame型別)
| 方法 | 說明 |
| .cov() | 計算協方差矩陣 |
| .corr() | 計算相關係數矩陣(常用) |
