
Spark1.6.1 MLlib 特徵抽取和變換
1 TF-IDF
TF-IDF是一種特徵向量化方法,這種方法多用於文字挖掘,通過演算法可以反應出詞在語料庫中某個文件中的重要性。文件中詞記為t,文件記為d , 語料庫記為D . 詞頻TF(t,d) 是詞t 在文件d 中出現的次數。文件頻次DF(t,D) 是語料庫中包括詞t的文件數。如果使用詞在文件中出現的頻次表示詞的重要程度,那麼很容易取出反例,即有些詞出現頻率高反而沒多少資訊量, 如,”a” , “the” , “of” 。如果一個詞在語料庫中出現頻率高,說明它在特定文件集中資訊量很低。逆文件頻次(inverse document frequency)是詞所能提供的資訊量的一種度量:
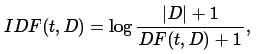
此處|D| 是語料庫中總的文件數,注意到,公式中使用log函式,當詞出現在所有文件中時,它的IDF值變為0. 給IDF加一個防止在此情況下分母為0. TF-IDF 度量值表示如下:
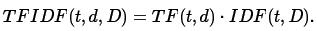
對於TF 和 IDF 定義有多種,spark.mllib 中,分開定義TF 和IDF 。
Spark.mllib 中實現詞頻率統計使用特徵hash的方式,原始的特徵通過hash函式,對映到一個索引值。後面只需要統計這些索引值的頻率,就可以知道對應詞的頻率。這種方式避免設計一個全域性1對1的詞到索引的對映,這個對映在對映大量語料庫時需要花費更長的時間。但需要注意,通過hash的方式可能會對映到同一個值的情況,即不同的原始特徵通過Hash對映後是同一個值。為了降低這種情況出現的概率,我們只能對特徵向量升維。i.e., hash表的桶數,預設特徵維度是 2^20 = 1,048,576.
注意:spark.mllib 不支援文字分段,詳見 Stanford nlp group http://nlp.stanford.edu/和 scalanlp/chalk : https://github.com/scalanlp/chalk
TF實際是統計詞hash之後索引值的頻次,可使用HashingTF 方法並傳入RDD[Iterable[_]] , IDF 需要使用IDF方法。需要注意,每條記錄是可iterable的字串或其它型別。
import org.apache.spark.rdd.RDD import org.apache.spark.<span class="wp_keywordlink_affiliate"><a href="http://www.iteblog.com/archives/tag/spark" title="" target="_blank" data-original-title="View all posts in Spark">Spark</a></span>Context import org.apache.spark.mllib.feature.HashingTF import org.apache.spark.mllib.linalg.Vector val sc: <span class="wp_keywordlink_affiliate"><a href="http://www.iteblog.com/archives/tag/spark" title="" target="_blank" data-original-title="View all posts in Spark">Spark</a></span>Context = ... // Load documents (one per line). val documents: RDD[Seq[String]] = sc.textFile("...").map(_.split(" ").toSeq) val hashingTF = new HashingTF() val tf: RDD[Vector] = hashingTF.transform(documents)
HashingTF 方法只需要一次資料互動,而IDF需要兩次資料互動:第一次計算IDF向量,第二次需要和詞頻次相乘
import org.apache.spark.mllib.feature.IDF
// ... continue from the previous example
tf.cache()
val idf = new IDF().fit(tf)
val tfidf: RDD[Vector] = idf.transform(tf)import org.apache.spark.mllib.feature.IDF
// ... continue from the previous example
tf.cache()
val idf = new IDF(minDocFreq = 2).fit(tf)
val tfidf: RDD[Vector] = idf.transform(tf)
2 Word2Vect (詞到向量)
Word2Vec 計算詞表徵向量的分佈,這樣可以利用相似相近的詞表徵分佈在鄰近的向量空間,好處就是易於產生新型模型,且模型預測的誤差也容易解釋。向量分佈在自然語言處理中是很有用的,特定像命名實體識別,歧義消除,句法分析,詞性標記和機器翻譯。2.1 模型
Word2vec 的實現中,我們使用skip-gram模型。Skip-gram的訓練目標是學習詞表徵向量分佈,這個分佈可以用來預測句子所在的語鏡。數學上,給定一組訓練詞w_1, … w_T ,skip-gram模型的目標是最大化平均log-似然。
此處 k 是訓練樣本視窗。
在skip-gram模型中,每個單詞w 關聯兩個向量u_w 和v_w ,其中u_w是單詞w的向量表示,v_w是單詞對應的語境。對於給定的單詞w_j ,計算預測結果的正確概率由以下softmax 模型。
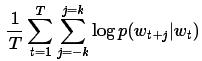


2.2 例子
下例子列舉如何載入文字檔案,將文字內容存放到RDD[Seq[String]],從RDD構造一個Word2Vec例項,將輸入資料送入此例項訓練得到Word2VecModel模型。最終,我們展示特定詞的前40個同義詞。為了執行這個例子,首先下載text8(http://mattmahoney.net/dc/text8.zip) 資料,解壓到特定的目錄下。此處我們假設解壓出來的檔案還叫text8 ,並且在當前目錄。import org.apache.spark._
import org.apache.spark.rdd._
import org.apache.spark.SparkContext._
import org.apache.spark.mllib.feature.{Word2Vec, Word2VecModel}
val input = sc.textFile("text8").map(line => line.split(" ").toSeq)
val word2vec = new Word2Vec()
val model = word2vec.fit(input)
val synonyms = model.findSynonyms("china", 40)
for((synonym, cosineSimilarity) <- synonyms) {
println(s"$synonym $cosineSimilarity")
}
// Save and load model
model.save(sc, "myModelPath")
val sameModel = Word2VecModel.load(sc, "myModelPath")3 standardscaler標準化
標準化是通過變化將原始資料放縮到單位方差,通過平移資料得到均值為0(如果原資料均值不為0,需要對取樣資料求出樣本均值,將原始資料減雲樣本均值,即得到均值為0的新資料)。例如,支援向量機的RBF 核,或L1和L2空間的正則線性模型,這兩個例子很能說明問題,經過標準化所有特徵的計算能得到更好的結果。
標準化後的資料,在最優化過程中會更快的收斂,同時也會在模型訓練時防止方差大的資料對整體資料的影響。
3.1 模型擬合
標準化需要配置以下引數:1 withMean 預設是假(false)。在標準化之前將原始資料以均值為中心,這樣會使標準化後的資料分佈相對緊密些,這種方法不適合於稀鬆的資料集,否則會觸發異常。
2 withStd 預設是真(true) , 意味將資料標準化到單位方差。
在StandardScaler 中提供一個擬合方法將RDD[Vector]作為輸入,學習輸入的統計資訊,將輸入集合變換成單位標準差,變換結果可能(也可能不是)均值為0 ,通過配置StandardScaler 來實現。
模型支援VectorTransformer ,可以將標準向量變換成新的向量,或者將RDD[Vector] 變換到新的RDD[Vector]。
如果特徵向量某個維度的方差為0,則特徵向量這個維度的變換結果仍然是0.0
3.2 例子
下例展示如何載入libsvm格式資料,將資料標準化後得到新的向量,此新向量的標準差是1,均值可能(也可能不是) 0 。import org.apache.spark.SparkContext._
import org.apache.spark.mllib.feature.StandardScaler
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.util.MLUtils
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
val scaler1 = new StandardScaler().fit(data.map(x => x.features))
val scaler2 = new StandardScaler(withMean = true, withStd = true).fit(data.map(x => x.features))
// scaler3 is an identical model to scaler2, and will produce identical transformations
val scaler3 = new StandardScalerModel(scaler2.std, scaler2.mean)
// data1 will be unit variance.
val data1 = data.map(x => (x.label, scaler1.transform(x.features)))
// Without converting the features into dense vectors, transformation with zero mean will raise
// exception on sparse vector.
// data2 will be unit variance and zero mean.
val data2 = data.map(x => (x.label, scaler2.transform(Vectors.dense(x.features.toArray))))
4.1 例子

import org.apache.spark.SparkContext._
import org.apache.spark.mllib.feature.Normalizer
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.util.MLUtils
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
val normalizer1 = new Normalizer()
val normalizer2 = new Normalizer(p = Double.PositiveInfinity)
// Each sample in data1 will be normalized using $L^2$ norm.
val data1 = data.map(x => (x.label, normalizer1.transform(x.features)))
// Each sample in data2 will be normalized using $L^\infty$ norm.
val data2 = data.map(x => (x.label, normalizer2.transform(x.features)))5 ChiSqSelector(ChiSq選擇器)
在模型構造階段,特徵選擇從特徵向量中剔除相關的維度,即對特徵空間進行降維,這樣可以加速迭代過程,並提升學習效率。ChiSqSelector 實現基於chi-squared 的特徵選擇器,它處理歸類特徵的類標籤,ChiSqSelector 基於Chi-Squared 檢驗對特徵進行排序,而不直接考慮特徵向量的類別,選取排序靠前的特徵向量,因為這些特徵向量能很好的決定類別標籤。這就好比選取對分類有決定意義的特徵向量。
在實際中,選取檢驗集可以優化特徵的數量。
5.1 模型擬合
ChiSqSelector 演算法配置 numTopFeatures 引數來確定選取排名前多少個特徵向量。擬合方法的輸入是歸類特徵的RDD[LabeledPoint],通過學習統計資訊,返回ChiSqSelectorModel模型,這個模型可以用於對特徵空間進行降維。這個模型可以處理輸入Vector,得到降維後的Vector , 或者對RDD[Vector]進行降維。
當然,也可以構造一個特徵索引(索引按升序排列), 對這個索引的陣列訓練ChiSqSelectorModel模型。
5.2例子
下例展現ChiSqSelector的基礎應用,輸入矩陣的每個元素的範圍 0 ~ 255 。import org.apache.spark.SparkContext._
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.mllib.feature.ChiSqSelector
// Load some data in libsvm format
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// Discretize data in 16 equal bins since ChiSqSelector requires categorical features
// Even though features are doubles, the ChiSqSelector treats each unique value as a category
val discretizedData = data.map { lp =>
LabeledPoint(lp.label, Vectors.dense(lp.features.toArray.map { x => (x / 16).floor } ) )
}
// Create ChiSqSelector that will select top 50 of 692 features
val selector = new ChiSqSelector(50)
// Create ChiSqSelector model (selecting features)
val transformer = selector.fit(discretizedData)
// Filter the top 50 features from each feature vector
val filteredData = discretizedData.map { lp =>
LabeledPoint(lp.label, transformer.transform(lp.features))
}6 Hadamard乘積(ElementwiseProduct)
ElementwiseProduct對輸入向量的每個元素乘以一個權重向量的每個元素,對輸入向量每個元素逐個進行放縮。這個稱為對輸入向量v 和變換向量scalingVec 使用Hadamard product(阿達瑪積)進行變換,最終產生一個新的向量。用向量 w 表示 scalingVec ,則Hadamard product可以表示為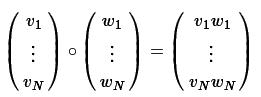
Hamard 乘積需要配置一個權向量 scalingVec
1) scalingVec 變換向量
ElementwiseProduct實現 VectorTransformer 方法,就可以對向量乘以權向量,得到新的向量,或者對RDD[Vector] 乘以權向量得到RDD[Vector]
6.1 例子
下例展示如何對向量進行ElementwiseProduct變換import org.apache.spark.SparkContext._
import org.apache.spark.mllib.feature.ElementwiseProduct
import org.apache.spark.mllib.linalg.Vectors
// Create some vector data; also works for sparse vectors
val data = sc.parallelize(Array(Vectors.dense(1.0, 2.0, 3.0), Vectors.dense(4.0, 5.0, 6.0)))
val transformingVector = Vectors.dense(0.0, 1.0, 2.0)
val transformer = new ElementwiseProduct(transformingVector)
// Batch transform and per-row transform give the same results:
val transformedData = transformer.transform(data)
val transformedData2 = data.map(x => transformer.transform(x))7 PCA
PCA可以將特徵向量投影到低維空間,實現對特徵向量的降維。7.1 例子
下例展示如何計算特徵向量空間的主成分,使用主成分對向量投影到低維空間,同時保留向量的類標籤。import org.apache.spark.mllib.regression.LinearRegressionWithSGD
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.feature.PCA
val data = sc.textFile("data/mllib/ridge-data/lpsa.data").map { line =>
val parts = line.split(',')
LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.toDouble)))
}.cache()
val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0).cache()
val test = splits(1)
val pca = new PCA(training.first().features.size/2).fit(data.map(_.features))
val training_pca = training.map(p => p.copy(features = pca.transform(p.features)))
val test_pca = test.map(p => p.copy(features = pca.transform(p.features)))
val numIterations = 100
val model = LinearRegressionWithSGD.train(training, numIterations)
val model_pca = LinearRegressionWithSGD.train(training_pca, numIterations)
val valuesAndPreds = test.map { point =>
val score = model.predict(point.features)
(score, point.label)
}
val valuesAndPreds_pca = test_pca.map { point =>
val score = model_pca.predict(point.features)
(score, point.label)
}
val MSE = valuesAndPreds.map{case(v, p) => math.pow((v - p), 2)}.mean()
val MSE_pca = valuesAndPreds_pca.map{case(v, p) => math.pow((v - p), 2)}.mean()
println("Mean Squared Error = " + MSE)
println("PCA Mean Squared Error = " + MSE_pca)相關推薦
Spark1.6.1 MLlib 特徵抽取和變換
1 TF-IDF TF-IDF是一種特徵向量化方法,這種方法多用於文字挖掘,通過演算法可以反應出詞在語料庫中某個文件中的重要性。文件中詞記為t,文件記為d , 語料庫記為D . 詞頻TF(t,d) 是詞t 在文件d 中出現的次數。文件頻次DF(t,D) 是語料庫中包括詞
spark1.6.1讀取csv檔案,轉為為DataFrame和使用SQL
一、讀取csv spark2.0才開始原始碼支援CSV,所以1.6版本需要藉助第三方包來實現讀取CSV檔案,有好幾種方法, 1.如果有maven的,到https://spark-packages.org/package/databricks/spark-csv下載對應scala版本的第三方j
Spark MLlib 特徵抽取、轉化和選擇 -- 特徵抽取3 CountVectorizer
這一部分主要介紹和特徵處理相關的演算法,大體分為以下三類: 1)特徵抽取:從原始資料中抽取特徵 2)特徵轉換:特徵的維度、特徵的轉化、特徵的修改 3)特徵選取:從大規模特徵集中選取一個子集 特徵提取: CountVectorizer CountVectorizer旨
Spark MLlib 特徵抽取、轉化和選擇 -- 特徵選取:卡方選擇器
這一部分主要介紹和特徵處理相關的演算法,大體分為以下三類: 1)特徵抽取:從原始資料中抽取特徵 2)特徵轉換:特徵的維度、特徵的轉化、特徵的修改 3)特徵選取:從大規模特徵集中選取一個子集 特徵選擇(feature Selection)指的是在特徵向量中選擇出那些優秀的
5.6.1 快速傅立葉變換(FFT+RFFT)
1.影象頻域處理的意義 在影象處理和分析中,經常會將影象從影象空間轉換到其他空間中,並利用這些空間的特點進行對轉換後圖像進行分析處理,然後再將處理後的影象轉換到影象空間中,這稱之為影象變換。 在一些影象處理和分析中通過空間變換往往會取得更有效
NLP原理,本質,資訊理論,文字特徵抽取和預處理
自然語言處理基本概念 語言的數學本質 語言的出現是為了通訊,通訊的本質是為了傳遞資訊。字母,文字,數字都是資訊編碼的不同單元。任何一種語言都是一種編解碼演算法。 我們通過語言把要表達的意思傳遞出來,實際上就是用語言將大腦中的資訊進行了一次編碼,形成了一串文字。
《Spark1.6.1官方文件》Spark1.6.1操作指南
原文連結 譯者:小村長 本專案是 Apache Spark1.6.1方文件的中文翻譯版,之前翻譯過spark1.5,由於網站有組織翻譯Spark1.6.1所以我又重新翻譯了一下,我翻譯的這一章和spark1.5一樣。本次翻譯主要針對對Spark感興趣和致力於從事大資料方法開發的人員提供有價
6.1 物件的構造和析構(Object Costruction and Destruction)
一般而言,constructor和destructor的安插如你所預期那樣: //C++ pseudo { Point point; //point.Point::Point(); 一般會被安插在這裡 ... //point.Point::~Point(); 一般會被安插在這裡 }
最新版scala2.11.8與spark1.6.1一步到位安裝
一,scala安裝: 先到官網下載一個scala的壓縮包,它沒有過多的要求,然後在Linux下按照如下步驟操作: 1,解壓包: [email protected]:/mysoftwaretar−zxvfscala−2.11
編譯spark1.6.1原始碼
正常的情況下從spark官方網站下載的發行包已經可以滿足正常使用(預設支援了hive),但如果要編譯相應cdh版本的hadoop或者把ganglia打包進來等,那就要重新指定編譯引數來重新編譯原始碼了。建議最好在linux環境下進行編譯。 原始碼下載
AIX 6.1 引數配置分析和建議-關閉影響效能的系統程式
考慮到AIX系統中,可能某些系統程式是不需要的,我們可以考慮關閉掉。直接修改配置檔案,註釋掉即可。 在/etc/inittab中關閉xdaily項 -:xmdaily:2:once:/usr/bin/topasrec-L -s 300 -R 1 -r 7 -o /etc/p
《深入理解Spark》之Spark常用運算元詳解(java版+spark1.6.1)
最近公司要用Java開發Spark專案,以前用的是Scala語言,今天就把Spark常用的運算元使用java語言實現了一遍 XML Code 1 2 3 4 5 6 7 8 9 10 11 12
spark1.6+hadoop2.6+kafka2.10-0.8.2.1+zookeeper3.3.6安裝及sparkStreaming程式碼編寫和除錯
安裝環境 安裝之前確保裝置至少有4GB記憶體,推薦8GB centos7.2 docker(這個安裝請參考我的另一篇部落格https://blog.csdn.net/qq_16563637/article/details/81699251) 目標安裝軟體
中M2018春C入門和進階練習集 函數題 6-1 使用函數求素數和(20 分)
|| bre 題目 span lse for mes view html 函數題 6-1 使用函數求素數和(20 分) 本題要求實現一個判斷素數的簡單函數、以及利用該函數計算給定區間內素數和的函數。 素數就是只能被1和自身整除的正整數。註意:1不是素數,2是素數。 函
PTA 6-1 使用函數求素數和
calc pro 浙江 col tdi require i++ 以及 大學 本題要求實現一個判斷素數的簡單函數、以及利用該函數計算給定區間內素數和的函數。 素數就是只能被1和自身整除的正整數。註意:1不是素數,2是素數。 函數接口定義: int prime( int p
6.1.2.9 文本和字體
行高 size its 技術 erl ont 字體 info 分享 字號: font-size: 20px; 默認是16px px: 像素 rem em % 移動端使用的單位 字形: font-weight: bold; normal bol
使用Apache commons-maths3-3.6.1.jar包實現快速傅立葉變換(java)
快速傅立葉變換 (fast Fourier transform), 即利用計算機計算離散傅立葉變換(DFT)的高效、快速計算方法的統稱,簡稱FFT。 1 package com; 2 3 import org.apache.commons.math3
windows安裝Jupyter Notebook Windows下的Python 3.6.1的下載與安裝(適合32bits和64bits)(圖文詳解)
這是我自定義的Python 的安裝目錄 (D:\SoftWare\Python\Python36\Scripts) 1、Jupyter Notebook 和 pip 為了更加方便地寫 Python 程式碼,還需要安裝 Jupyter notebook。 利用 pip 安裝
第六章樹和二叉樹作業1—二叉樹--計算機17級 6-1 求二叉樹高度 (20 分)
6-1 求二叉樹高度 (20 分) 本題要求給定二叉樹的高度。 函式介面定義: int GetHeight( BinTree BT ); 其中BinTree結構定義如下: typedef struct TNode *Position; typedef P
Elam的caffe筆記之配置篇(三):Centos 6.5下裝CUDA8.0 和cudnnv5.1
Elam的caffe筆記之配置篇(三):Centos 6.5下裝CUDA8.0 和cudnnv5.1 配置要求: 系統:centos6.5 目標:基於CUDA8.0+Opencv3.1+Cudnnv5.1+python3.6介面的caffe框架 寫在前面,本文是在C