
DFA演算法實現Java敏感詞過濾
敏感詞、文字過濾是一個網站必不可少的功能,如何設計一個好的、高效的過濾演算法是非常有必要的。前段時間我一個朋友(馬上畢業,接觸程式設計不久)要我幫他看一個文字過濾的東西,它說檢索效率非常慢。我把它程式拿過來一看,整個過程如下:讀取敏感詞庫、如果HashSet集合中,獲取頁面上傳文字,然後進行匹配。我就想這個過程肯定是非常慢的。對於他這個沒有接觸的人來說我想也只能想到這個,更高階點就是正則表示式。但是非常遺憾,這兩種方法都是不可行的。當然,在我意識裡沒有我也沒有認知到那個演算法可以解決問題,但是Google知道!
DFA簡介
在實現文字過濾的演算法中,DFA是唯一比較好的實現演算法。DFA即Deterministic Finite Automaton,也就是確定有窮自動機,它是是通過event和當前的state得到下一個state,即event+state=nextstate。下圖展示了其狀態的轉換
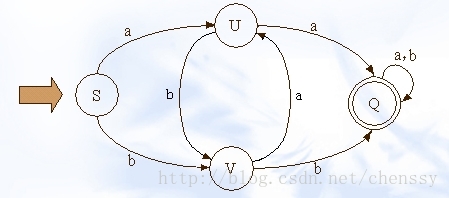
在這幅圖中大寫字母(S、U、V、Q)都是狀態,小寫字母a、b為動作。通過上圖我們可以看到如下關係
a b b
S —–> U S —–> V U —–> V
在實現敏感詞過濾的演算法中,我們必須要減少運算,而DFA在DFA演算法中幾乎沒有什麼計算,有的只是狀態的轉換。
Java實現DFA演算法實現敏感詞過濾
在Java中實現敏感詞過濾的關鍵就是DFA演算法的實現。首先我們對上圖進行剖析。在這過程中我們認為下面這種結構會更加清晰明瞭。
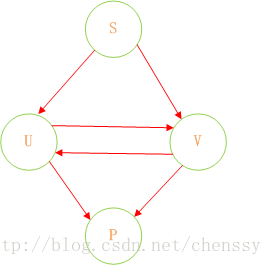
同時這裡沒有狀態轉換,沒有動作,有的只是Query(查詢)。我們可以認為,通過S query U、V,通過U query V、P,通過V query U P。通過這樣的轉變我們可以將狀態的轉換轉變為使用Java集合的查詢。
誠然,加入在我們的敏感詞庫中存在如下幾個敏感詞:日本人、日本鬼子、毛.澤.東。那麼我需要構建成一個什麼樣的結構呢?
首先:query 日 —> {本}、query 本 —>{人、鬼子}、query 人 —>{null}、query 鬼 —> {子}。形如下結構:
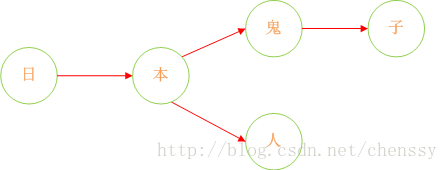
下面我們在對這圖進行擴充套件:
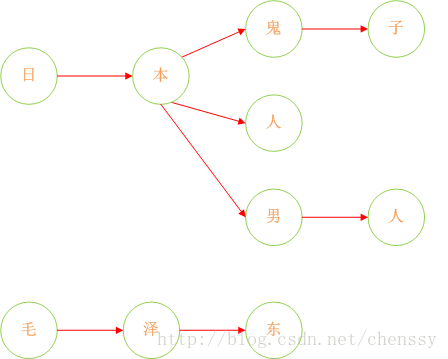
這樣我們就將我們的敏感詞庫構建成了一個類似與一顆一顆的樹,這樣我們判斷一個詞是否為敏感詞時就大大減少了檢索的匹配範圍。比如我們要判斷日本人,根據第一個字我們就可以確認需要檢索的是那棵樹,然後再在這棵樹中進行檢索。
但是如何來判斷一個敏感詞已經結束了呢?利用標識位來判斷。
所以對於這個關鍵是如何來構建一棵棵這樣的敏感詞樹。下面我已Java中的HashMap為例來實現DFA演算法。具體過程如下:
日本人,日本鬼子為例
1、在hashMap中查詢“日”看其是否在hashMap中存在,如果不存在,則證明已“日”開頭的敏感詞還不存在,則我們直接構建這樣的一棵樹。跳至3。
2、如果在hashMap中查詢到了,表明存在以“日”開頭的敏感詞,設定hashMap = hashMap.get(“日”),跳至1,依次匹配“本”、“人”。
3、判斷該字是否為該詞中的最後一個字。若是表示敏感詞結束,設定標誌位isEnd = 1,否則設定標誌位isEnd = 0;
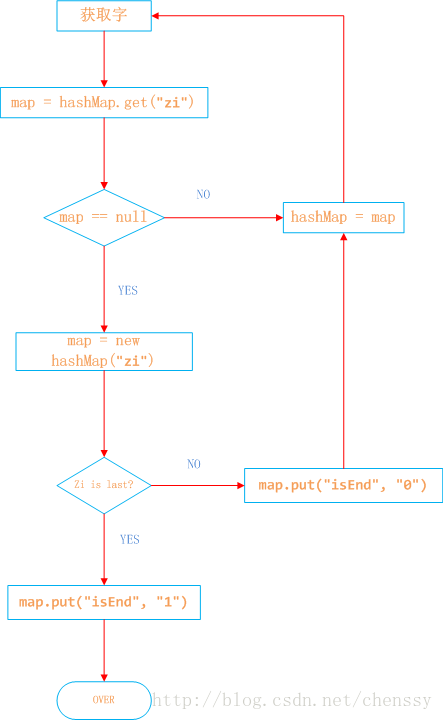
程式實現如下:
[java] view plain copy print?- /**
- * 讀取敏感詞庫,將敏感詞放入HashSet中,構建一個DFA演算法模型:<br>
- * 中 = {
- * isEnd = 0
- * 國 = {<br>
- * isEnd = 1
- * 人 = {isEnd = 0
- * 民 = {isEnd = 1}
- * }
- * 男 = {
- * isEnd = 0
- * 人 = {
- * isEnd = 1
- * }
- * }
- * }
- * }
- * 五 = {
- * isEnd = 0
- * 星 = {
- * isEnd = 0
- * 紅 = {
- * isEnd = 0
- * 旗 = {
- * isEnd = 1
- * }
- * }
- * }
- * }
- * @author chenming
- * @date 2014年4月20日 下午3:04:20
- * @param keyWordSet 敏感詞庫
- * @version 1.0
- */
- @SuppressWarnings({ “rawtypes”, “unchecked” })
- privatevoid addSensitiveWordToHashMap(Set<String> keyWordSet) {
- sensitiveWordMap = new HashMap(keyWordSet.size()); //初始化敏感詞容器,減少擴容操作
- String key = null;
- Map nowMap = null;
- Map<String, String> newWorMap = null;
- //迭代keyWordSet
- Iterator<String> iterator = keyWordSet.iterator();
- while(iterator.hasNext()){
- key = iterator.next(); //關鍵字
- nowMap = sensitiveWordMap;
- for(int i = 0 ; i < key.length() ; i++){
- char keyChar = key.charAt(i); //轉換成char型
- Object wordMap = nowMap.get(keyChar); //獲取
- if(wordMap != null){ //如果存在該key,直接賦值
- nowMap = (Map) wordMap;
- }
- else{ //不存在則,則構建一個map,同時將isEnd設定為0,因為他不是最後一個
- newWorMap = new HashMap<String,String>();
- newWorMap.put(”isEnd”, “0”); //不是最後一個
- nowMap.put(keyChar, newWorMap);
- nowMap = newWorMap;
- }
- if(i == key.length() - 1){
- nowMap.put(”isEnd”, “1”); //最後一個
- }
- }
- }
- }
/**
* 讀取敏感詞庫,將敏感詞放入HashSet中,構建一個DFA演算法模型:<br>
* 中 = {
* isEnd = 0
* 國 = {<br>
* isEnd = 1
* 人 = {isEnd = 0
* 民 = {isEnd = 1}
* }
* 男 = {
* isEnd = 0
* 人 = {
* isEnd = 1
* }
* }
* }
* }
* 五 = {
* isEnd = 0
* 星 = {
* isEnd = 0
* 紅 = {
* isEnd = 0
* 旗 = {
* isEnd = 1
* }
* }
* }
* }
* @author chenming
* @date 2014年4月20日 下午3:04:20
* @param keyWordSet 敏感詞庫
* @version 1.0
*/
@SuppressWarnings({ "rawtypes", "unchecked" })
private void addSensitiveWordToHashMap(Set<String> keyWordSet) {
sensitiveWordMap = new HashMap(keyWordSet.size()); //初始化敏感詞容器,減少擴容操作
String key = null;
Map nowMap = null;
Map<String, String> newWorMap = null;
//迭代keyWordSet
Iterator<String> iterator = keyWordSet.iterator();
while(iterator.hasNext()){
key = iterator.next(); //關鍵字
nowMap = sensitiveWordMap;
for(int i = 0 ; i < key.length() ; i++){
char keyChar = key.charAt(i); //轉換成char型
Object wordMap = nowMap.get(keyChar); //獲取
if(wordMap != null){ //如果存在該key,直接賦值
nowMap = (Map) wordMap;
}
else{ //不存在則,則構建一個map,同時將isEnd設定為0,因為他不是最後一個
newWorMap = new HashMap<String,String>();
newWorMap.put("isEnd", "0"); //不是最後一個
nowMap.put(keyChar, newWorMap);
nowMap = newWorMap;
}
if(i == key.length() - 1){
nowMap.put("isEnd", "1"); //最後一個
}
}
}
}執行得到的hashMap結構如下:
{五={星={紅={isEnd=0, 旗={isEnd=1}}, isEnd=0}, isEnd=0}, 中={isEnd=0, 國={isEnd=0, 人={isEnd=1}, 男={isEnd=0, 人={isEnd=1}}}}}敏感詞庫我們一個簡單的方法給實現了,那麼如何實現檢索呢?檢索過程無非就是hashMap的get實現,找到就證明該詞為敏感詞,否則不為敏感詞。過程如下:假如我們匹配“中國人民萬歲”。
1、第一個字“中”,我們在hashMap中可以找到。得到一個新的map = hashMap.get(“”)。
2、如果map == null,則不是敏感詞。否則跳至3
3、獲取map中的isEnd,通過isEnd是否等於1來判斷該詞是否為最後一個。如果isEnd == 1表示該詞為敏感詞,否則跳至1。
通過這個步驟我們可以判斷“中國人民”為敏感詞,但是如果我們輸入“中國女人”則不是敏感詞了。
[java] view plain copy print?- /**
- * 檢查文字中是否包含敏感字元,檢查規則如下:<br>
- * @author chenming
- * @date 2014年4月20日 下午4:31:03
- * @param txt
- * @param beginIndex
- * @param matchType
- * @return,如果存在,則返回敏感詞字元的長度,不存在返回0
- * @version 1.0
- */
- @SuppressWarnings({ “rawtypes”})
- publicint CheckSensitiveWord(String txt,int beginIndex,int matchType){
- boolean flag = false; //敏感詞結束標識位:用於敏感詞只有1位的情況
- int matchFlag = 0; //匹配標識數預設為0
- char word = 0;
- Map nowMap = sensitiveWordMap;
- for(int i = beginIndex; i < txt.length() ; i++){
- word = txt.charAt(i);
- nowMap = (Map) nowMap.get(word); //獲取指定key
- if(nowMap != null){ //存在,則判斷是否為最後一個
- matchFlag++; //找到相應key,匹配標識+1
- if(“1”.equals(nowMap.get(“isEnd”))){ //如果為最後一個匹配規則,結束迴圈,返回匹配標識數
- flag = true; //結束標誌位為true
- if(SensitivewordFilter.minMatchTYpe == matchType){ //最小規則,直接返回,最大規則還需繼續查詢
- break;
- }
- }
- }
- else{ //不存在,直接返回
- break;
- }
- }
- if(matchFlag < 2 && !flag){
- matchFlag = 0;
- }
- return matchFlag;
- }
/**
* 檢查文字中是否包含敏感字元,檢查規則如下:<br>
* @author chenming
* @date 2014年4月20日 下午4:31:03
* @param txt
* @param beginIndex
* @param matchType
* @return,如果存在,則返回敏感詞字元的長度,不存在返回0
* @version 1.0
*/
@SuppressWarnings({ "rawtypes"})
public int CheckSensitiveWord(String txt,int beginIndex,int matchType){
boolean flag = false; //敏感詞結束標識位:用於敏感詞只有1位的情況
int matchFlag = 0; //匹配標識數預設為0
char word = 0;
Map nowMap = sensitiveWordMap;
for(int i = beginIndex; i < txt.length() ; i++){
word = txt.charAt(i);
nowMap = (Map) nowMap.get(word); //獲取指定key
if(nowMap != null){ //存在,則判斷是否為最後一個
matchFlag++; //找到相應key,匹配標識+1
if("1".equals(nowMap.get("isEnd"))){ //如果為最後一個匹配規則,結束迴圈,返回匹配標識數
flag = true; //結束標誌位為true
if(SensitivewordFilter.minMatchTYpe == matchType){ //最小規則,直接返回,最大規則還需繼續查詢
break;
}
}
}
else{ //不存在,直接返回
break;
}
}
if(matchFlag < 2 && !flag){
matchFlag = 0;
}
return matchFlag;
}在文章末尾我提供了利用Java實現敏感詞過濾的檔案下載。下面是一個測試類來證明這個演算法的效率和可靠性。
[java] view plain copy print?- publicstaticvoid main(String[] args) {
- SensitivewordFilter filter = new SensitivewordFilter();
- System.out.println(”敏感詞的數量:” + filter.sensitiveWordMap.size());
- String string = ”太多的傷感情懷也許只侷限於飼養基地 熒幕中的情節,主人公嘗試著去用某種方式漸漸的很瀟灑地釋自殺指南懷那些自己經歷的傷感。”
- + ”然後法.輪.功 我們的扮演的角色就是跟隨著主人公的喜紅客聯盟 怒哀樂而過於牽強的把自己的情感也附加於銀幕情節中,然後感動就流淚,”
- + ”難過就躺在某一個人的懷裡盡情的闡述心扉或者手機卡複製器一個人一杯紅酒一部電影在夜三.級.片 深人靜的晚上,關上電話靜靜的發呆著。”;
- System.out.println(”待檢測語句字數:” + string.length());
- long beginTime = System.currentTimeMillis();
- Set<String> set = filter.getSensitiveWord(string, 1);
- long endTime = System.currentTimeMillis();
- System.out.println(”語句中包含敏感詞的個數為:” + set.size() + “。包含:” + set);
- System.out.println(”總共消耗時間為:” + (endTime - beginTime));
- }
public static void main(String[] args) {
SensitivewordFilter filter = new SensitivewordFilter();
System.out.println("敏感詞的數量:" + filter.sensitiveWordMap.size());
String string = "太多的傷感情懷也許只侷限於飼養基地 熒幕中的情節,主人公嘗試著去用某種方式漸漸的很瀟灑地釋自殺指南懷那些自己經歷的傷感。"
+ "然後法.輪.功 我們的扮演的角色就是跟隨著主人公的喜紅客聯盟 怒哀樂而過於牽強的把自己的情感也附加於銀幕情節中,然後感動就流淚,"
+ "難過就躺在某一個人的懷裡盡情的闡述心扉或者手機卡複製器一個人一杯紅酒一部電影在夜三.級.片 深人靜的晚上,關上電話靜靜的發呆著。";
System.out.println("待檢測語句字數:" + string.length());
long beginTime = System.currentTimeMillis();
Set<String> set = filter.getSensitiveWord(string, 1);
long endTime = System.currentTimeMillis();
System.out.println("語句中包含敏感詞的個數為:" + set.size() + "。包含:" + set);
System.out.println("總共消耗時間為:" + (endTime - beginTime));
}執行結果:

從上面的結果可以看出,敏感詞庫有771個,檢測語句長度為184個字元,查出6個敏感詞。總共耗時1毫秒。可見速度還是非常可觀的。
下面提供兩個文件下載:
Desktop.rar(http://pan.baidu.com/s/1o66teGU)裡面包含兩個Java檔案,一個是讀取敏感詞庫(SensitiveWordInit),一個是敏感詞工具類(SensitivewordFilter),裡面包含了判斷是否存在敏感詞(isContaintSensitiveWord(String txt,int matchType))、獲取敏感詞(getSensitiveWord(String txt , int matchType))、敏感詞替代(replaceSensitiveWord(String txt,int matchType,String replaceChar))三個方法。
——————————————————————————————————————————————————–
– –
– –
——————————————————————————————————————————————————–
相關推薦
DFA演算法實現Java敏感詞過濾
敏感詞、文字過濾是一個網站必不可少的功能,如何設計一個好的、高效的過濾演算法是非常有必要的。前段時間我一個朋友(馬上畢業,接觸程式設計不久)要我幫他看一個文字過濾的東西,它說檢索效率非常慢。我把它程式拿過來一看,整個過程如下:讀取敏感詞庫、如果Ha
java敏感詞過濾(詞庫+演算法)高效率驗證
需求:使用者輸入一段文字,驗證是否包含敏感詞,以及具體的是哪些敏感詞,替換為*等....1.需要一個詞庫,我這裡就是一個從github下載的一個txt檔案。已轉存到百度網盤,點選下載詞庫,提取碼:tk3g2.DFA演算法,效能卓越,請放心使用,直接上java程式碼:packa
Java 敏感詞過濾,Java 敏感詞替換,Java 敏感詞工具類
blog rds log code ima 方法 www enter iteye Java 敏感詞過濾,Java 敏感詞替換,Java 敏感詞工具類 =========================== ?Copyright 蕃薯耀 2017年9月25日 http:
JAVA 敏感詞過濾
package me.mymilkbottles; import org.apache.commons.lang.CharUtils; import java.io.File; import java.util.HashMap; import java.ut
Java利用DFA演算法實現敏感詞過濾
前言: 敏感詞文字過濾是一個網站必不可少的功能,如何設計一個好的、高效的過濾演算法是非常有必要的。作為一般開發人員來說首先考慮的肯定是簡單的匹配,這樣是可以實現功能,但效率比較慢,在高階一點的就是正則表示式,比前一個好一點,但終究還是一丘之貉,非常遺憾,兩種方法都不可取。當
DFA演算法實現敏感詞過濾
DFA,即Deterministic Finite Automaton,也就是確定有窮自動機。比如我們有愛戀、哈哈、感動、靜靜、發呆、太多、啦啦這幾個敏感詞,以上其實是通過HashMap組織成的樹形結構,比如我們通過“太”就可以知道這個字是否是“太多”這個詞的最後一個字,並且
61 dfa 實現敏感詞過濾
引用 nbsp bsp 概念 pre clas logs code println 基本的概念 Class class=null 【只是在棧內存中有了指向,堆內存並沒有分配內存】 Class class=new Class()【棧內存中有了指向(引用),堆內存也分配了內存
java HashMap實現中文分詞器 應用:敏感詞過濾實現
今天下午部門內部技術分享是分詞器演算法。這次的主講是大名鼎鼎的Ansj分詞器的作者-孫健。 作者簡介: Ansj分詞器作者 elasticsearch-sql(elasticsearch的sql外掛)作者,支援sql查詢 nlp-lang自然語言工具包發起人 NLPCN(自然語言處理
C#敏感詞過濾演算法實現
1.DFA演算法簡介DFA全稱為:Deterministic Finite Automaton,即確定有窮自動機。其特徵為:有一個有限狀態集合和一些從一個狀態通向另一個狀態的邊,每條邊上標記有一個符號,其中一個狀態是初態,某些狀態是終態。但不同於不確定的有限自動機,DFA中不
DFA敏感詞過濾演算法
運用DFA演算法加密。首先我先對敏感詞庫初始化,若我的敏感詞庫為冰毒白粉大麻大壞蛋初始化之後得到的是下面這樣。:{冰={毒={isEnd=1}, isEnd=0}, 白={粉={isEnd=1}, isEnd=0}, 大={麻={isEnd=1}, isEnd=0, 壞={蛋
Java Web敏感詞過濾演算法
1.DFA演算法DFA演算法的原理可以參考 這裡 ,簡單來說就是通過Map構造出一顆敏感詞樹,樹的每一條由根節點到葉子節點的路徑構成一個敏感詞,例如下圖:程式碼簡單實現如下:public class TextFilterUtil { //日誌 private stat
【Java】聊天過濾 DFA演算法的Java實現
開心就好 Trie樹的原理不講了,直接上程式碼 ChatFilter.java 是核心的過濾器,他從NoneWantToSee.list檔案中讀敏感詞,這個檔案中一個敏感詞放一行,這個檔案放在src目錄下就行。 過濾器實現資料載入和提供過濾服務,過濾服務是把敏感詞替換成**
Java 敏感詞替換-dfa演算法,效率高
實現的步驟:1.用一個方法來讀取敏感詞放入一個List集合 2.寫一個敏感詞庫方法讀取集合中的敏感詞,然後生成樹形結構, 3.寫一個查詢傳入字串查詢其中的敏感詞的方法,找到字串中的敏感詞
敏感詞過濾的演算法原理之DFA演算法
轉載自:https://blog.csdn.net/chenssy/article/details/26961957敏感詞、文字過濾是一個網站必不可少的功能,如何設計一個好的、高效的過濾演算法是非常有必要的。前段時間我一個朋友(馬上畢業,接觸程式設計不久)要我幫他看一個文字過
java DFA 敏感詞過濾
@SuppressWarnings("unchecked") public class SensitiveWordUtils { /** * 只要匹配到一個就返回 */ public static final int
PHP實現敏感詞過濾系統
trie樹 sel 重復 .html ole lang 最大 foreach header PHP實現敏感詞過濾系統 安裝說明 安裝PHP擴展 trie_filter,安裝教程 http://blog.41ms.com/post/39.html 安
敏感詞過濾演算法:字首樹演算法
背景 平時我們在逛貼吧、牛客網的時候,我們經常可以看到一些形如 “***”的符號,通過上下文,我們也可以很容易猜到這些詞原來是罵人的話,只是被系統和諧了。那麼這是如何實現的呢?作為普通人,我們最先想到的一種辦法就是把所有敏感串存入一個列表中,然後使用者每發一條內容後臺就把該內容與敏感串列表
php 實現敏感詞過濾 - PHP擴充套件trie_filter
實現方法1 使用PHP擴充套件trie_filter 安裝:libiconv wget http://ftp.gnu.org/pub/gnu/libiconv/libiconv-1.14.tar.gz tar zxvf libiconv-1.14.tar.gz cd libicon
【python 走進NLP】英文敏感詞過濾演算法改進版本
中文DFA演算法過濾敏感詞改進版本 # 中文DFA演算法過濾敏感詞改進版本 class Chinese_DFAFilter(): def __init__(self): self.keyword_chains = {} s
高效能的敏感詞過濾演算法 可以忽略大小寫、全半形、簡繁體、特殊符號干擾 (二)
/// <summary> /// 敏感詞過濾 已忽略大小寫 全半形 簡繁體差異 特殊符號 html標籤 干擾 /// </summary> public static class FilterKeyWords { priv