
DFA演算法實現敏感詞過濾
阿新 • • 發佈:2019-02-01
DFA,即Deterministic Finite Automaton,也就是確定有窮自動機。
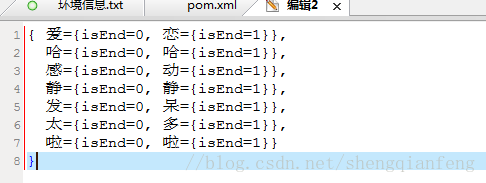
比如我們有愛戀、哈哈、感動、靜靜、發呆、太多、啦啦這幾個敏感詞,以上其實是通過HashMap組織成的樹形結構,比如我們通過“太”就可以知道這個字是否是“太多”這個詞的最後一個字,並且可以通過“太”獲取到“多”這個字且知道其是否為最後一個字。通過這些資訊我們就可以過濾掉敏感詞彙。
java例子:
package com.admin.util; import java.util.HashMap; import java.util.HashSet; import java.util.Iterator; import java.util.Map; import java.util.Set; /** * 敏感詞處理 - DFA演算法實現 * * @author jeff * @since 2018/3/15 */ public class SensitiveWordUtil { /** * 敏感詞匹配規則 */ public static final int MinMatchTYpe = 1; //最小匹配規則,如:敏感詞庫["中國","中國人"],語句:"我是中國人",匹配結果:我是[中國]人 public static final int MaxMatchType = 2; //最大匹配規則,如:敏感詞庫["中國","中國人"],語句:"我是中國人",匹配結果:我是[中國人] /** * 敏感詞集合 */ public static HashMap sensitiveWordMap; /** * 初始化敏感詞庫,構建DFA演算法模型 * * @param sensitiveWordSet 敏感詞庫 */ public static synchronized void init(Set<String> sensitiveWordSet) { initSensitiveWordMap(sensitiveWordSet); } /** * 初始化敏感詞庫,構建DFA演算法模型 * * @param sensitiveWordSet 敏感詞庫 */ private static void initSensitiveWordMap(Set<String> sensitiveWordSet) { //初始化敏感詞容器,減少擴容操作 sensitiveWordMap = new HashMap(sensitiveWordSet.size()); String key; Map nowMap; Map<String, String> newWorMap; //迭代sensitiveWordSet Iterator<String> iterator = sensitiveWordSet.iterator(); while (iterator.hasNext()) { //關鍵字 key = iterator.next(); nowMap = sensitiveWordMap; for (int i = 0; i < key.length(); i++) { //轉換成char型 char keyChar = key.charAt(i); //庫中獲取關鍵字 Object wordMap = nowMap.get(keyChar); //如果存在該key,直接賦值,用於下一個迴圈獲取 if (wordMap != null) { nowMap = (Map) wordMap; } else { //不存在則,則構建一個map,同時將isEnd設定為0,因為他不是最後一個 newWorMap = new HashMap<>(); //不是最後一個 newWorMap.put("isEnd", "0"); nowMap.put(keyChar, newWorMap); nowMap = newWorMap; } if (i == key.length() - 1) { //最後一個 nowMap.put("isEnd", "1"); } } } } /** * 判斷文字是否包含敏感字元 * * @param txt 文字 * @param matchType 匹配規則 1:最小匹配規則,2:最大匹配規則 * @return 若包含返回true,否則返回false */ public static boolean contains(String txt, int matchType) { boolean flag = false; for (int i = 0; i < txt.length(); i++) { int matchFlag = checkSensitiveWord(txt, i, matchType); //判斷是否包含敏感字元 if (matchFlag > 0) { //大於0存在,返回true flag = true; } } return flag; } /** * 判斷文字是否包含敏感字元 * * @param txt 文字 * @return 若包含返回true,否則返回false */ public static boolean contains(String txt) { return contains(txt, MaxMatchType); } /** * 獲取文字中的敏感詞 * * @param txt 文字 * @param matchType 匹配規則 1:最小匹配規則,2:最大匹配規則 * @return */ public static Set<String> getSensitiveWord(String txt, int matchType) { Set<String> sensitiveWordList = new HashSet<>(); for (int i = 0; i < txt.length(); i++) { //判斷是否包含敏感字元 int length = checkSensitiveWord(txt, i, matchType); if (length > 0) {//存在,加入list中 sensitiveWordList.add(txt.substring(i, i + length)); i = i + length - 1;//減1的原因,是因為for會自增 } } return sensitiveWordList; } /** * 獲取文字中的敏感詞 * * @param txt 文字 * @return */ public static Set<String> getSensitiveWord(String txt) { return getSensitiveWord(txt, MaxMatchType); } /** * 替換敏感字字元 * * @param txt 文字 * @param replaceChar 替換的字元,匹配的敏感詞以字元逐個替換,如 語句:我愛中國人 敏感詞:中國人,替換字元:*, 替換結果:我愛*** * @param matchType 敏感詞匹配規則 * @return */ public static String replaceSensitiveWord(String txt, char replaceChar, int matchType) { String resultTxt = txt; //獲取所有的敏感詞 Set<String> set = getSensitiveWord(txt, matchType); Iterator<String> iterator = set.iterator(); String word; String replaceString; while (iterator.hasNext()) { word = iterator.next(); replaceString = getReplaceChars(replaceChar, word.length()); resultTxt = resultTxt.replaceAll(word, replaceString); } return resultTxt; } /** * 替換敏感字字元 * * @param txt 文字 * @param replaceChar 替換的字元,匹配的敏感詞以字元逐個替換,如 語句:我愛中國人 敏感詞:中國人,替換字元:*, 替換結果:我愛*** * @return */ public static String replaceSensitiveWord(String txt, char replaceChar) { return replaceSensitiveWord(txt, replaceChar, MaxMatchType); } /** * 替換敏感字字元 * * @param txt 文字 * @param replaceStr 替換的字串,匹配的敏感詞以字元逐個替換,如 語句:我愛中國人 敏感詞:中國人,替換字串:[遮蔽],替換結果:我愛[遮蔽] * @param matchType 敏感詞匹配規則 * @return */ public static String replaceSensitiveWord(String txt, String replaceStr, int matchType) { String resultTxt = txt; //獲取所有的敏感詞 Set<String> set = getSensitiveWord(txt, matchType); Iterator<String> iterator = set.iterator(); String word; while (iterator.hasNext()) { word = iterator.next(); resultTxt = resultTxt.replaceAll(word, replaceStr); } return resultTxt; } /** * 替換敏感字字元 * * @param txt 文字 * @param replaceStr 替換的字串,匹配的敏感詞以字元逐個替換,如 語句:我愛中國人 敏感詞:中國人,替換字串:[遮蔽],替換結果:我愛[遮蔽] * @return */ public static String replaceSensitiveWord(String txt, String replaceStr) { return replaceSensitiveWord(txt, replaceStr, MaxMatchType); } /** * 獲取替換字串 * * @param replaceChar * @param length * @return */ private static String getReplaceChars(char replaceChar, int length) { String resultReplace = String.valueOf(replaceChar); for (int i = 1; i < length; i++) { resultReplace += replaceChar; } return resultReplace; } /** * 檢查文字中是否包含敏感字元,檢查規則如下:<br> * * @param txt * @param beginIndex * @param matchType * @return 如果存在,則返回敏感詞字元的長度,不存在返回0 */ private static int checkSensitiveWord(String txt, int beginIndex, int matchType) { //敏感詞結束標識位:用於敏感詞只有1位的情況 boolean flag = false; //匹配標識數預設為0 int matchFlag = 0; char word; Map nowMap = sensitiveWordMap; for (int i = beginIndex; i < txt.length(); i++) { word = txt.charAt(i); //獲取指定key nowMap = (Map) nowMap.get(word); if (nowMap != null) {//存在,則判斷是否為最後一個 //找到相應key,匹配標識+1 matchFlag++; //如果為最後一個匹配規則,結束迴圈,返回匹配標識數 if ("1".equals(nowMap.get("isEnd"))) { //結束標誌位為true flag = true; //最小規則,直接返回,最大規則還需繼續查詢 if (MaxMatchType == matchType) { break; } } } else {//不存在,直接返回 break; } } if (matchFlag < 2 || !flag) {//長度必須大於等於1,為詞 matchFlag = 0; } return matchFlag; } public static void main(String[] args) { Set<String> sensitiveWordSet = new HashSet<>(); sensitiveWordSet.add("共和國"); sensitiveWordSet.add("共產"); sensitiveWordSet.add("政府"); sensitiveWordSet.add("萬萬歲"); sensitiveWordSet.add("萬歲"); //初始化敏感詞庫 SensitiveWordUtil.init(sensitiveWordSet); System.out.println("敏感詞的數量:" + SensitiveWordUtil.sensitiveWordMap.size()); String string = "中華人民共和國萬歲,偉大的共產黨萬歲,中央人民政府萬歲。萬歲萬歲萬萬歲。"; System.out.println("待檢測語句字數:" + string.length()); //是否含有關鍵字 boolean result = SensitiveWordUtil.contains(string); System.out.println(result); result = SensitiveWordUtil.contains(string, SensitiveWordUtil.MaxMatchType); System.out.println(result); //獲取語句中的敏感詞 Set<String> set = SensitiveWordUtil.getSensitiveWord(string); System.out.println("語句中包含敏感詞的個數為:" + set.size() + "。包含:" + set); set = SensitiveWordUtil.getSensitiveWord(string, SensitiveWordUtil.MaxMatchType); System.out.println("語句中包含敏感詞的個數為:" + set.size() + "。包含:" + set); //替換語句中的敏感詞 String filterStr = SensitiveWordUtil.replaceSensitiveWord(string, '*'); System.out.println(filterStr); filterStr = SensitiveWordUtil.replaceSensitiveWord(string, '*', SensitiveWordUtil.MaxMatchType); System.out.println(filterStr); String filterStr2 = SensitiveWordUtil.replaceSensitiveWord(string, "[*敏感詞*]"); System.out.println(filterStr2); filterStr2 = SensitiveWordUtil.replaceSensitiveWord(string, "[*敏感詞*]", SensitiveWordUtil.MaxMatchType); System.out.println(filterStr2); } }
列印結果:
敏感詞的數量:3 待檢測語句字數:36 true true 語句中包含敏感詞的個數為:5。包含:[萬歲, 萬萬歲, 共和國, 政府, 共產] 語句中包含敏感詞的個數為:5。包含:[萬歲, 萬萬歲, 共和國, 政府, 共產] 中華人民*****,偉大的**黨**,中央人民****。****萬**。 中華人民*****,偉大的**黨**,中央人民****。****萬**。 中華人民[*敏感詞*][*敏感詞*],偉大的[*敏感詞*]黨[*敏感詞*],中央人民[*敏感詞*][*敏感詞*]。[*敏感詞*][*敏感詞*]萬[*敏感詞*]。 中華人民[*敏感詞*][*敏感詞*],偉大的[*敏感詞*]黨[*敏感詞*],中央人民[*敏感詞*][*敏感詞*]。[*敏感詞*][*敏感詞*]萬[*敏感詞*]。
最大匹配原則驗證:
{你={isEnd=0, 好={啊={faqId=key_main_kcb_faq_004,isEnd=1}, faqId=key_main_kcb_faq_001, isEnd=1}},
說={吧={faqId=key_main_kcb_faq_003, isEnd=1}, isEnd=0},
您={說={faqId=key_main_kcb_faq_003, isEnd=1}, isEnd=0},
改={天={吧={faqId=key_main_kcb_faq_004, isEnd=1}, isEnd=0}, isEnd=0},
不={需={要={faqId=key_main_kcb_faq_002, isEnd=1}, isEnd=0}, isEnd=0}}
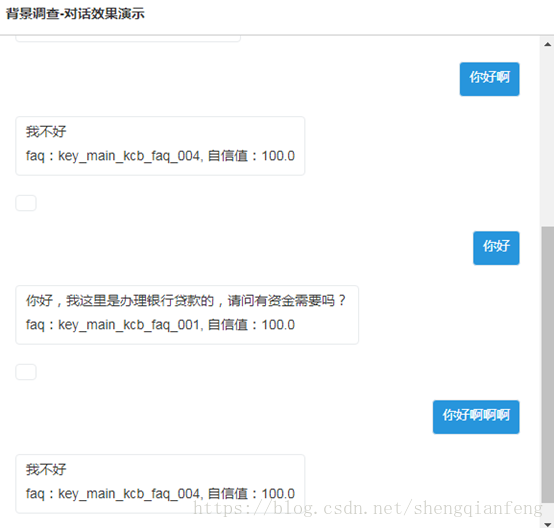
解釋:
問題:你好啊
匹配結果:綠色字型部分,完整都匹配上,faqId:key_main_kcb_faq_004
問題:你好
匹配結果:黃色字型部分,完整匹配上,faqId:key_main_kcb_faq_001
舉例:客戶說了一長段“你好啊啊啊啊”,就會匹配上綠色部分,因為dfa演算法最大匹配原則可以匹配到“你好啊”。