
Elasticsearch大檔案搜尋
1、大檔案是多大?
ES建立索引完成全文檢索的前提是將待檢索的資訊匯入Elaticsearch。
專案中,有時候需要將一些掃描件、PDF文件、Word、Excel、PPT等文件內容匯入Elasticsearch。
比如:將《深入理解Elasticsearch》這邊書匯入ES,而這邊書的全文內容被識別後的大小可能為3MB——5MB以上的位元組。
存入ES後是一個content欄位,對這個content執行全文檢索&高亮顯示,就存在檢索效率低的問題,會耗時30S以上的時間。
這點,作為習慣了搜尋引擎極速體驗的使用者,是不能忍的。
本文,詳細記錄了大檔案的全文檢索效能問題排查及提升
2、問題描述
從檢索症狀來看:
1)翻頁到1000+頁(每頁10條資料)以上,響應時間會比較長。
2)當遇到某些檔案的時候(事後分析得知是大檔案),響應時間尤其長,超過30S以上返回高亮結果。
3、問題排查與定位
步驟1: 限定返回記錄條數。不提供直接訪問末頁的入口。
baidu,360,搜狗等搜尋引擎都不提供訪問末頁的請求方式。都是基於如下的請求方式:
通過點選上一下、下一頁逐頁訪問。 
這個從使用者的角度也很好理解,搜尋引擎返回的前面都是相關度最高的,也是使用者最關心的資訊。
Elasticsearch的預設支援的資料條數是10000條,可以通過post請求修改。
最終,本步驟將支援ES最大返回值10000條資料,每頁10條,也就是共顯示1000頁資料。
步驟2,from size機制問題 ,大於設定頁就會慢
【from + size機制】:當Elasticsearch響應請求時,它必須確定docs的順序,排列響應結果。如果請求的頁數較少(假設每頁10個docs), Elasticsearch不會有什麼問題,但是如果頁數較大時,比如請求第100頁,Elasticsearch不得不取出第1頁到第100頁的所有docs,再去除第1頁到第99頁的docs,得到第100頁的docs。
【scroll機制】:相對於from和size的分頁來說,使用scroll可以模擬一個傳統資料的遊標,記錄當前讀取的文件資訊位置。這個分頁的用法,不是為了實時查詢資料,而是為了一次性查詢大量的資料(甚至是全部的資料)。
因為這個scroll相當於維護了一份當前索引段的快照資訊,這個快照資訊是你執行這個scroll查詢時的快照。在這個查詢後的任何新索引進來的資料,都不會在這個快照中查詢到。但是它相對於from和size,不是查詢所有資料然後剔除不要的部分,而是記錄一個讀取的位置,保證下一次快速繼續讀取。
from+size方式以及scroll方式優缺點對比:
1)對於from+size方式:當結果足夠大的時候,會大大加大記憶體和CPU的消耗。但,該方式使用非常方便。
2)對於scroll方式: 當結果足夠大的時候, scroll 效能更佳。但是不靈活和 scroll_id 難管理問題存在。
【from網路】個人測試:當 結果足夠大的時候 產生 scroll_id 效能也不低。如果只是一頁頁按照順序,scroll是極好的,但是如果是無規則的翻頁,那也是效能消耗極大的。
經過兩種機制對比,加之步驟1,限定了分頁數,最大1000頁。並且使用者支援主頁翻頁的方式,暫定還是採用from+size方式。
如果後面步驟有問題,再考慮換成scorll機制。
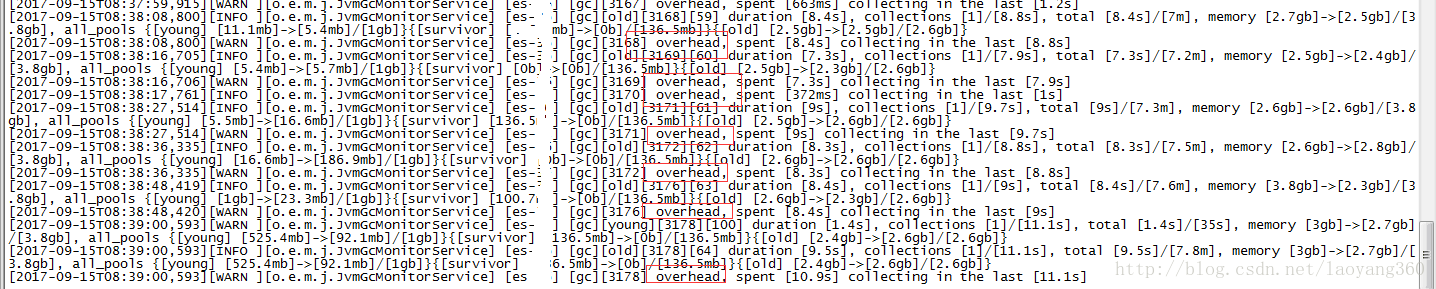
步驟3, 檢視ES列印日誌。
當出現卡頓、卡死等效能低、使用者體驗差問題時,檢視ES的日誌。
分析日誌如下:
原因分析:卡頓、卡死都是堆記憶體設定不足導致。
根據之間總結的高效能配置建議,果斷加堆記憶體,由16GB增加到最大值31GB。
堆記憶體使用比率可以通過:cerebro 工具檢測效能。
步驟4:類似逆向解析dsl,排查查詢慢在哪?
1) 打印出DSL,可以通過介面: searchSourceBuilder.toString()。
2) 新增profile引數,檢視到底哪裡慢了。
profile API的目的是:將ES高層的ES請求拉平展開,直觀的讓你看到請求做了什麼,每個細分點花了多少時間。
給你改善效能提供相關支撐工作。
使用舉例如下:
GET /_search
{
"profile": true,
"query" : {
"match" : { "message" : "message number" }
}
}3) 換了全文介面api ,query_string改成match query滿足要求且速度有提升。
4)刪除某些查詢條件,在基礎資料不變的條件下,檢視查詢速度是否快了(返回時間短了)。
驗證發現,當不返回content欄位(_source控制)時,速度會變快。
當取消高亮欄位處理,速度會更快。0.5秒之內返回結果。
至此,初步斷定和高亮處理有關係。
步驟5:高亮問題排查及優化
通過論壇中網友的建議來看,都推薦對於大檔案高亮使用: fast-vector-highlighter。
查詢官網文件得知:
Elasticsearch高亮分為三種方式:
方式1:傳統plain高亮方式。
官網明確支援,該方式匹配慢,如果出現效能問題,請考慮其他高亮方式。
方式2: postings 高亮方式。
支援postings高亮方式,需要在mapping下新增如下資訊:
"type": "text",
"index_options" : "offsets"新增完畢後,posting高亮方式將取代傳統的高亮方式。
posting高亮方式的特點:
1)速度快,不需要對高亮的文件再分析。文件越大,獲得越高 效能 。
2)比fvh高亮方式需要的磁碟空間少。
3)將text檔案分割成語句並對其高亮處理。對於自然語言發揮作用明顯,但對於html則不然。
4)將文件視為整個語料庫,並 使用BM25演算法 為該語料庫中的文件打分。
使用舉例:
PUT /example
{
"mappings": {
"doc" : {
"properties": {
"comment" : {
"type": "text",
"index_options" : "offsets"
}
}
}
}
}方式3: fast-vector-highlighter 簡稱fvh高亮方式。
如果在mapping中的text型別欄位下添加了如下資訊:
"type": "text",
"term_vector" : "with_positions_offsets"fvh高亮方式將取代傳統的plain高亮方式。
fvh高亮方式的特點如下:
1)當檔案>1MB(大檔案)時候,尤其適合fvh高亮方式。
2)自定義為 boundary_scanner的掃描方式。
3) 設定了 term_vector to with_positions_offsets會增加索引的大小。
4)能聯合多欄位匹配返回一個結果,詳見matched_fields。
5)對於不同的匹配型別分配不同的權重,如:pharse匹配比term匹配高。
舉例:
PUT /example
{
"mappings": {
"doc" : {
"properties": {
"comment" : {
"type": "text",
"term_vector" : "with_positions_offsets"
}
}
}
}
}最終選型:fvh高亮方式。首先:新建了索引,按照fvh的方式對content欄位新設定了mapping;其次通過如下方式進行索引資料同步:
POST /_reindex
{
"source": {
"index": "test_index"
},
"dest": {
"index": "test_index_new"
}
}實踐結果表明,同樣的大檔案,原本檢索>40S,現在2S之內返回結果。
沒有改一行程式碼,只修改了mapping,效率提升了近20倍。
步驟5 小結
解決問題的方法肯定比問題多。
相關推薦
Elasticsearch大檔案搜尋
1、大檔案是多大? ES建立索引完成全文檢索的前提是將待檢索的資訊匯入Elaticsearch。 專案中,有時候需要將一些掃描件、PDF文件、Word、Excel、PPT等文件內容匯入Elasticsearch。 比如:將《深入理解Elasticsearch》這邊書匯入
Elasticsearch大檔案檢索效能提升20倍實踐(乾貨)
少廢話,直接開始。 1、大檔案是多大? ES建立索引完成全文檢索的前提是將待檢索的資訊匯入Elaticsearch。 專案中,有時候需要將一些掃描件、PDF文件、Word、Excel、PPT等文件內容匯入Elasticsearch。 比如:將《深入理
【shell】shell指令碼在大檔案日誌中按照時間段快速搜尋日誌
問題描述: 在大流量線上服務中,日誌系統會產生數量龐大的日誌,動輒就是幾十G。在如此之大的檔案中快速搜尋日誌是運維人員經常遇見的問題。我們經常遇見的問題是查詢一段時間內的某些條日誌。比如,今天有一
linux grep和sed搜尋大檔案中的錯誤日誌
通常我們通過關鍵字找錯誤日誌的時候,日誌並不是每行都匹配,這樣就會顯示出部分日誌,如下面搜尋cat mylog|grep -n XXXAction的結果: 10009875:2015-02-26 14:12:13 com.interfaces.XXXAction:134 [
分散式搜尋elasticsearch配置檔案elasticsearch.yml詳解
配置檔案位於%ES_HOME%/config/elasticsearch.yml檔案中,用Editplus開啟它,你便可以進行配置。 所有的配置都可以使用環境變數,例如:node.rack: ${RACK_ENV_VAR} 表示環境變數中有一個R
python下建立elasticsearch索引實現大資料搜尋——之環境搭建(一)
目錄 1.需求闡述 1)資料儲存在阿里雲內網的Mysql伺服器上,需要通過一臺伺服器SSH隧道穿透取得資料。 2)首先明確,一張設計圖需要多種素材來構成。資料量很大,需要操作的有兩個表,稱為stylepatternshow表,目前資料3w行(
專案常見功能(1) 下載 批量下載 大檔案下載 下載進度條
最通用的就是讀取伺服器上檔案,response 設定響應頭讓瀏覽器知道這是要下載的,然後response相應即可 1、ajax 響應內容只能是字串,不能是流所以 不能傳送請求下載檔案,要使用window.location.href= url 或者 <a href="
python讀取大檔案的方法 python計算檔案的行數和讀取某一行內容的實現方法
python計算檔案的行數和讀取某一行內容的實現方法 :最簡單的辦法是把檔案讀入一個大的列表中,然後統計列表的長度.如果檔案的路徑是以引數的形式filepath傳遞的,那麼只用一行程式碼就可以完成我們的需求了: 1、http://blog.csdn.net/shudaq
磁碟滿了,卻找不到大檔案
某天,突然接到老大電話,說公司網站打不開了,跑去一看,老毛病,磁碟滿了。之前磁碟滿了,都是由於專案的日誌引起的,伺服器上有php和java專案,去刪除日誌就可以了。 我負責php專案,登入php專案一看,我靠,日誌才幾百兆,於是電話java同事,讓他看下,他看了說也只有幾百兆,我倆都清理了,之後
開啟運維之路之第 3 篇——目錄作用介紹、檔案搜尋、其它命令、解壓縮包、使用者管理
1、目錄作用介紹 我們先切換到系統根目錄 / 看看根目錄下有哪些目錄 [[email protected] ~]# cd / [[email protected] /]# ls 說明: 根目錄下的bin和sbin,usr目錄下的bin和sbin,這四
fread讀取大檔案以及返回值問題(轉載)
今天fread檔案讀取遇到問題,本來很小的一個問題,但是一直沒有注意到,導致花了不少時間除錯,所以寫下來備忘一下。 size_t fread ( void * ptr, size_t size, size_t count, FILE * stream ); /
使用uploadify控制元件上傳大檔案錯誤處理記錄
使用uploadify控制元件上傳大檔案時,會出錯:如http 404 錯誤等。 這個錯誤應該是上傳沒有成功,導致讀取上傳後的路徑不存在造成的。 實際的原因還是因為沒有能上傳成功。 上傳失敗的原因有多種,我這裡發現的情況初步判斷是因為檔案超過某個閥值造成的。 第一步: 檢視控制元件本
mysql 5.7匯入較大檔案報錯
Row size too large (> 8126). Changing some columns to TEXT or BLOB may help. In current row format, BLOB prefix of 0 bytes is stored inline. 匯入s
elasticsearch 大資料場景下使用scroll實現分頁查詢
es查詢大批量資料的”可能方案” 當使用es來請求大批量資料時,通常有三種辦法,其一:直接查詢獲取全量資料;其二:使用setFrom以及setSize解決;其三:使用es自帶的scroll分頁支援 方案評估 對於上述方案的評估,此處建議大家可以先看看這篇文章
【轉】Android-使用Socket進行大檔案斷點上傳續傳
在Android中上傳檔案可以採用HTTP方式,也可以採用Socket方式,但是HTTP方式不能上傳大檔案,這裡介紹一種通過Socket方式來進行斷點續傳的方式,服務端會記錄下檔案的上傳進度,當某一次上傳過程意外終止後,下一次可以繼續上傳,這裡用到的其實還是J2SE裡的知識。 這個上傳程式的
arcgis server GP 處理大檔案的方法
問題 伺服器(arcgis server 10.2)釋出GP服務,但瀏覽器解析不了百兆以上的json大檔案,無法完成GP輸入。 解決辦法 允許GP服務的上傳 功能。把大檔案上傳到arcgis server上,用返回的itemid作為輸入值。 步驟 上傳大檔案
Linux基本命令 檔案搜尋命令
1.檔案搜尋命令find ================================================================================== 命令名稱:find 命令所在路徑:/bin/find 執行許可權:所有使用者 語法:find [
004-linux常用命令-檔案搜尋命令
檔案搜尋命令:find命令名稱:find命令所在路徑:/bin/find執行許可權:所有使用者語法:find [搜尋範圍] [匹配條件]功能描述:檔案搜尋 $ find /etc -name init在目錄/etc中查詢檔案init-iname 不區分大小寫$ find / -size +204800在根目
ElasticSearch - 輸入即搜尋 edge n-gram
在此之前,ES所有的查詢都是針對整個詞進行操作,也就是說倒排索引存了hello這個詞,一定得輸入hello才能找到這個詞,輸入 h 或是 he 都找不到倒排索引中的hello 然而在現實情況下,使用者已經漸漸習慣在輸入完查詢內容之前,就能為他們展現搜尋結果,這就是所謂的即
pandas.read_csv——分塊讀取大檔案
訪問本站觀看效果更佳 read_csv中有個引數chunksize,通過指定一個chunksize分塊大小來讀取檔案,返回的是一個可迭代的物件TextFileReader,IO Tools 舉例如下: In [138]: reader = pd.read_table('