
hadoop作業調優引數整理及原理(整個mapreduce執行流程都講的清楚,一步一步優化)
1 Map side tuning引數
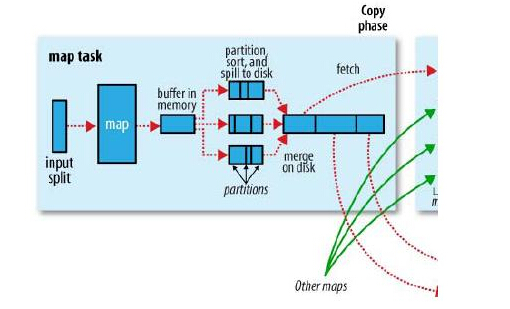
1.1 MapTask執行內部原理
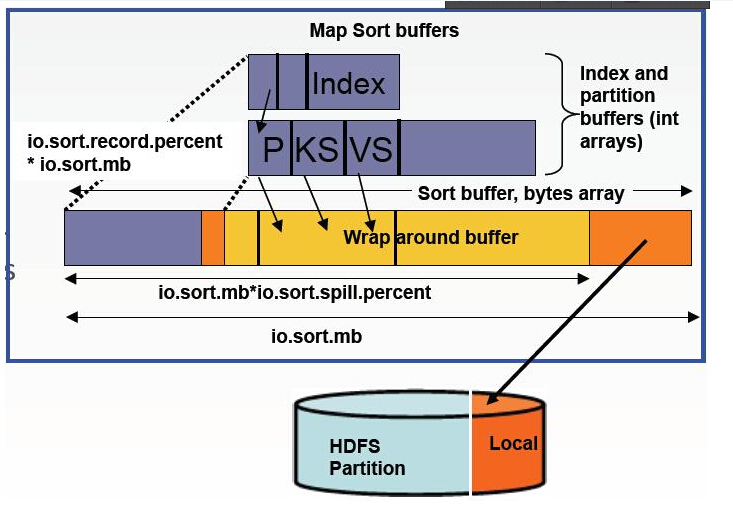
當map task開始運算,併產生中間資料時,其產生的中間結果並非直接就簡單的寫入磁碟。這中間的過程比較複雜,並且利用到了記憶體buffer來進行已經產生的部分結果的快取,並在記憶體buffer中進行一些預排序來優化整個map的效能。如上圖所示,每一個map都會對應存在一個記憶體buffer(MapOutputBuffer,即上圖的buffer in memory),map會將已經產生的部分結果先寫入到該buffer中,這個buffer預設是100MB大小,但是這個大小是可以根據job提交時的引數設定來調整的,該引數即為:io.sort.mb。當map的產生資料非常大時,並且把io.sort.mb調大,那麼map在整個計算過程中spill的次數就勢必會降低,map task對磁碟的操作就會變少,如果map tasks的瓶頸在磁碟上,這樣調整就會大大提高map的計算效能。map做sort和spill的記憶體結構如下如所示:
map在執行過程中,不停的向該buffer中寫入已有的計算結果,但是該buffer並不一定能將全部的map輸出快取下來,當map輸出超出一定閾值(比如100M),那麼map就必須將該buffer中的資料寫入到磁碟中去,這個過程在mapreduce中叫做spill。map並不是要等到將該buffer全部寫滿時才進行spill,因為如果全部寫滿了再去寫spill,勢必會造成map的計算部分等待buffer釋放空間的情況。所以,map其實是當buffer被寫滿到一定程度(比如80%)時,就開始進行spill。這個閾值也是由一個job的配置引數來控制,即io.sort.spill.percent,預設為0.80或80%。這個引數同樣也是影響spill頻繁程度,進而影響map task執行週期對磁碟的讀寫頻率的。但非特殊情況下,通常不需要人為的調整。調整io.sort.mb對使用者來說更加方便。
當map task的計算部分全部完成後,如果map有輸出,就會生成一個或者多個spill檔案,這些檔案就是map的輸出結果。map在正常退出之前,需要將這些spill合併(merge)成一個,所以map在結束之前還有一個merge的過程。merge的過程中,有一個引數可以調整這個過程的行為,該引數為:io.sort.factor。該引數預設為10。它表示當merge spill檔案時,最多能有多少並行的stream向merge檔案中寫入。比如如果map產生的資料非常的大,產生的spill檔案大於10,而io.sort.factor使用的是預設的10,那麼當map計算完成做merge時,就沒有辦法一次將所有的spill檔案merge成一個,而是會分多次,每次最多10個stream。這也就是說,當map的中間結果非常大,調大io.sort.factor,有利於減少merge次數,進而減少map對磁碟的讀寫頻率,有可能達到優化作業的目的。
當job指定了combiner的時候,我們都知道map介紹後會在map端根據combiner定義的函式將map結果進行合併。執行combiner函式的時機有可能會是merge完成之前,或者之後,這個時機可以由一個引數控制,即min.num.spill.for.combine(default 3),當job中設定了combiner,並且spill數最少有3個的時候,那麼combiner函式就會在merge產生結果檔案之前執行。通過這樣的方式,就可以在spill非常多需要merge,並且很多資料需要做conbine的時候,減少寫入到磁碟檔案的資料數量,同樣是為了減少對磁碟的讀寫頻率,有可能達到優化作業的目的。
減少中間結果讀寫進出磁碟的方法不止這些,還有就是壓縮。也就是說map的中間,無論是spill的時候,還是最後merge產生的結果檔案,都是可以壓縮的。壓縮的好處在於,通過壓縮減少寫入讀出磁碟的資料量。對中間結果非常大,磁碟速度成為map執行瓶頸的job,尤其有用。控制map中間結果是否使用壓縮的引數為:mapred.compress.map.output(true/false)。將這個引數設定為true時,那麼map在寫中間結果時,就會將資料壓縮後再寫入磁碟,讀結果時也會採用先解壓後讀取資料。這樣做的後果就是:寫入磁碟的中間結果資料量會變少,但是cpu會消耗一些用來壓縮和解壓。所以這種方式通常適合job中間結果非常大,瓶頸不在cpu,而是在磁碟的讀寫的情況。說的直白一些就是用cpu換IO。根據觀察,通常大部分的作業cpu都不是瓶頸,除非運算邏輯異常複雜。所以對中間結果採用壓縮通常來說是有收益的。以下是一個wordcount中間結果採用壓縮和不採用壓縮產生的map中間結果本地磁碟讀寫的資料量對比:
map中間結果不壓縮:

map中間結果壓縮:

可以看出,同樣的job,同樣的資料,在採用壓縮的情況下,map中間結果能縮小將近10倍,如果map的瓶頸在磁碟,那麼job的效能提升將會非常可觀。
當採用map中間結果壓縮的情況下,使用者還可以選擇壓縮時採用哪種壓縮格式進行壓縮,現在hadoop支援的壓縮格式有:GzipCodec,LzoCodec,BZip2Codec,LzmaCodec等壓縮格式。通常來說,想要達到比較平衡的cpu和磁碟壓縮比,LzoCodec比較適合。但也要取決於job的具體情況。使用者若想要自行選擇中間結果的壓縮演算法,可以設定配置引數:mapred.map.output.compression.codec=org.apache.hadoop.io.compress.DefaultCodec或者其他使用者自行選擇的壓縮方式。
1.2 Map side相關引數調優

2 Reduce side tuning引數
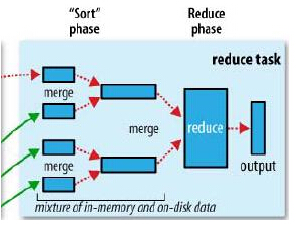
2.1 ReduceTask執行內部原理
reduce的執行是分成三個階段的。分別為copy->sort->reduce。由於job的每一個map都會根據reduce(n)數將資料分成map 輸出結果分成n個partition,所以map的中間結果中是有可能包含每一個reduce需要處理的部分資料的。所以,為了優化reduce的執行時間,hadoop中是等job的第一個map結束後,所有的reduce就開始嘗試從完成的map中下載該reduce對應的partition部分資料。這個過程就是通常所說的shuffle,也就是copy過程。
Reduce task在做shuffle時,實際上就是從不同的已經完成的map上去下載屬於自己這個reduce的部分資料,由於map通常有許多個,所以對一個reduce來說,下載也可以是並行的從多個map下載,這個並行度是可以調整的,調整引數為:mapred.reduce.parallel.copies(default 5)。預設情況下,每個只會有5個並行的下載執行緒在從map下資料,如果一個時間段內job完成的map有100個或者更多,那麼reduce也最多隻能同時下載5個map的資料,所以這個引數比較適合map很多並且完成的比較快的job的情況下調大,有利於reduce更快的獲取屬於自己部分的資料。
reduce的每一個下載執行緒在下載某個map資料的時候,有可能因為那個map中間結果所在機器發生錯誤,或者中間結果的檔案丟失,或者網路瞬斷等等情況,這樣reduce的下載就有可能失敗,所以reduce的下載執行緒並不會無休止的等待下去,當一定時間後下載仍然失敗,那麼下載執行緒就會放棄這次下載,並在隨後嘗試從另外的地方下載(因為這段時間map可能重跑)。所以reduce下載執行緒的這個最大的下載時間段是可以調整的,調整引數為:mapred.reduce.copy.backoff(default 300秒)。如果叢集環境的網路本身是瓶頸,那麼使用者可以通過調大這個引數來避免reduce下載執行緒被誤判為失敗的情況。不過在網路環境比較好的情況下,沒有必要調整。通常來說專業的叢集網路不應該有太大問題,所以這個引數需要調整的情況不多。
Reduce將map結果下載到本地時,同樣也是需要進行merge的,所以io.sort.factor的配置選項同樣會影響reduce進行merge時的行為,該引數的詳細介紹上文已經提到,當發現reduce在shuffle階段iowait非常的高的時候,就有可能通過調大這個引數來加大一次merge時的併發吞吐,優化reduce效率。
Reduce在shuffle階段對下載來的map資料,並不是立刻就寫入磁碟的,而是會先快取在記憶體中,然後當使用記憶體達到一定量的時候才刷入磁碟。這個記憶體大小的控制就不像map一樣可以通過io.sort.mb來設定了,而是通過另外一個引數來設定:mapred.job.shuffle.input.buffer.percent(default 0.7),這個引數其實是一個百分比,意思是說,shuffile在reduce記憶體中的資料最多使用記憶體量為:0.7 × maxHeap of reduce task。也就是說,如果該reduce task的最大heap使用量(通常通過mapred.child.java.opts來設定,比如設定為-Xmx1024m)的一定比例用來快取資料。預設情況下,reduce會使用其heapsize的70%來在記憶體中快取資料。如果reduce的heap由於業務原因調整的比較大,相應的快取大小也會變大,這也是為什麼reduce用來做快取的引數是一個百分比,而不是一個固定的值了。
假設mapred.job.shuffle.input.buffer.percent為0.7,reduce task的max heapsize為1G,那麼用來做下載資料快取的記憶體就為大概700MB左右,這700M的記憶體,跟map端一樣,也不是要等到全部寫滿才會往磁碟刷的,而是當這700M中被使用到了一定的限度(通常是一個百分比),就會開始往磁碟刷。這個限度閾值也是可以通過job引數來設定的,設定引數為:mapred.job.shuffle.merge.percent(default 0.66)。如果下載速度很快,很容易就把記憶體快取撐大,那麼調整一下這個引數有可能會對reduce的效能有所幫助。
當reduce將所有的map上對應自己partition的資料下載完成後,就會開始真正的reduce計算階段(中間有個sort階段通常時間非常短,幾秒鐘就完成了,因為整個下載階段就已經是邊下載邊sort,然後邊merge的)。當reduce task真正進入reduce函式的計算階段的時候,有一個引數也是可以調整reduce的計算行為。也就是:mapred.job.reduce.input.buffer.percent(default 0.0)。由於reduce計算時肯定也是需要消耗記憶體的,而在讀取reduce需要的資料時,同樣是需要記憶體作為buffer,這個引數是控制,需要多少的記憶體百分比來作為reduce讀已經sort好的資料的buffer百分比。預設情況下為0,也就是說,預設情況下,reduce是全部從磁碟開始讀處理資料。如果這個引數大於0,那麼就會有一定量的資料被快取在記憶體並輸送給reduce,當reduce計算邏輯消耗記憶體很小時,可以分一部分記憶體用來快取資料,反正reduce的記憶體閒著也是閒著。
2.2 Reduce side相關引數調優

本文轉載自:http://www.tbdata.org/archives/1470
相關推薦
hadoop作業調優引數整理及原理(整個mapreduce執行流程都講的清楚,一步一步優化)
1 Map side tuning引數 1.1 MapTask執行內部原理 當map task開始運算,併產生中間資料時,其產生的中間結果並非直接就簡單的寫入磁碟。這中間的過程比較複雜,並且利用到了記憶體buffer來進行已經產生的部分結果的快取,並在記憶體bu
Hadoop map調優引數
引數:io.sort.mb(default 100) 當map task開始運算,併產生中間資料時,其產生的中間結果並非直接就簡單的寫入磁碟。 而是會利用到了記憶體buffer來進行已經產生的部分結果的快取, 並在記憶體buffer中進行一些預排序來優化整
JVM效能調優2:JVM效能調優引數整理
關閉新生代收集擔保。 在一次理想化的minor gc中,Eden和First Survivor中的活躍物件會被複制到Second Survivor。然而,Second Survivor不一定能容納下所有從E和F區copy過來的活躍物件。為了確保minor gc能夠順利完成,GC需要在年老代中額外保留一塊
SQL Server調優系列進階篇(查詢語句執行幾個指標值監測)
前言 上一篇我們分析了查詢優化器的工作方式,其中包括:查詢優化器的詳細執行步驟、篩選條件分析、索引項優化等資訊。 本篇我們分析在我們執行的過程中幾個關鍵指標值的檢測。 通過這些指標值來分析語句的執行問題,並且分析其優化方式。 通過本篇我們可以學習到調優中經常利用的幾個利器! 廢話少說,開始本篇的正題
Dubbo效能調優引數及原理
Dubbo呼叫模型 常用效能調優引數 原始碼及原理分析 threads FixedThreadPool.java public Executor getExecutor(URL url) { Stri
Spark Streaming調優引數及最佳實踐深入剖析-Spark商業調優實戰
本套技術專欄是作者(秦凱新)平時工作的總結和昇華,通過從真實商業環境抽取案例進行總結和分享,並給出商業應用的調優建議和叢集環境容量規劃等內容,請持續關注本套部落格。版權宣告:禁止轉載,歡迎學習。QQ郵箱地址:[email protected],如有任何商業交流,可隨時聯絡。
JVM記憶體結構--新生代及新生代裡的兩個Survivor區(下一輪S0與S1交換角色,如此迴圈往復)、常見調優引數
轉自http://www.cnblogs.com/duanxz/p/6076662.html 一、為什麼會有年輕代 我們先來屢屢,為什麼需要把堆分代?不分代不能完成他所做的事情麼?其實不分代完全可以,分代的唯一理由就是優化GC效能。你先想想,如果沒有分代,那我們
JVM效能調優的6大步驟,及關鍵調優引數詳解
JVM效能調優的6大步驟,及關鍵調優引數詳解 JVM效能調優方法和步驟 1.監控GC的狀態 2.生成堆的dump檔案 3.分析dump檔案 4.分析結果,判斷是否需要優化 5.調整GC型別和記憶體分配 6.不斷分析
JVM調優引數簡介、調優目標及調優經驗
一、JVM調優引數簡介1、 JVM引數簡介-XX 引數被稱為不穩定引數,之所以這麼叫是因為此類引數的設定很容易引起JVM 效能上的差異,使JVM 存在極大的不穩定性。如果此類引數設定合理將大大提高JVM 的效能及穩定性。不穩定引數語法規則:1.布林型別引數值 -
hadoop叢集調優及MR調優
一、作業系統調優 1、提高網路連線上限。以增加網路頻寬的利用率,即修改核心net.core.somaxcon引數 2、關閉swap交換分割槽。以免記憶體不足時,資料會溢寫到磁碟,讀取時再從磁碟讀取,增加資料讀取時間 3、調整預讀快取區的大小。將資料預讀,減少磁碟IO時間
數據傾斜是多麽痛?spark作業調優秘籍
提前 相同 發生 開始 機制 對數 .sql 提升 部分 目錄視圖 摘要視圖 訂閱 【觀點】物聯網與大數據將助推工業應用的崛起,你認同麽? CSDN日報20170703——《從高考到程序員——我一直在尋找答案》 【直播】探究Li
MySQL5.7 my.cnf常用參數、調優參數及常用語句
mysql5 collation string 修改 sym tab root密碼 auth lte 首次登陸修改root密碼mysql>use mysql;mysql>ALTER USER ‘root‘@‘localhost‘ IDENTIFIED BY ‘1
Hadoop效能調優全面總結
一、 Hadoop概述 隨著企業要處理的資料量越來越大,MapReduce思想越來越受到重視。Hadoop是MapReduce的一個開源實現,由於其良好的擴充套件性和容錯性,已得到越來越廣泛的應用。 Hadoop實現了一個分散式檔案系統(Hadoop Distributed File Sys
OOM異常分析&&JVM調優-彙總整理帖
1、OOM問題分析參考: 幾種OOM異常分析: https://blog.csdn.net/sunquan291/article/details/79109197 解決OutOfMemoryError: unable to create new native thread問題:ht
機器學習 使用交叉驗證為KNN調優引數
# KNN的距離演算法 使用的是歐氏距離 即算空間中點的距離 (根號下的 差的平方和) # 要注意的是knn演算法是需要做 標準化處理的 # API:(引數:n_neighbors=5)預設使用5個鄰居 鄰居的數量對演算法的結果有影響 數量越大則要判斷的點越多 from sklearn
RocksDB 的常用調優引數
RocksDB 的引數以其資料多和複雜著稱,要全部弄懂也要費一番功夫,這裡也僅僅會說一下我們使用的一些引數,還有很多我們也需要後面慢慢去研究。 Parallelism RocksDB 有兩個後臺執行緒,flush 和 compaction,兩個都可以同時
mysql知識盤點【肆】_調優引數
本文內容整理自《Mysql運維內參》第26章,本書值得一看,即使是開發同學。連結如下: genera_log 建議在資料庫正常服務時,將這個引數設定為關閉狀態,因為它會記
MQ高併發量時的調優引數設定說明
高可用(主從)與負載均衡架構圖 訊息傳送中的接收Topic訂閱結果訊息佇列URL地址、訊息接收佇列URL地址、訊息代理的傳送與接收佇列URL地址以及訊息轉發器傳送的Topic結果訊息佇列URL地址,均需設定為Failover 地址。 由於訊息佇列元件ActiveMQ是
JVM調優引數彙總啊!!!!總結的很不錯。
-XX:PrintHeapAtGC:列印GC前後的詳細堆疊資訊 輸出形式: 34.702: [GC {Heap before gc invocations=7: def new generation total 55296K, used 52568K [0x1ebd0000, 0x227d0000, 0
《Hadoop》之"踽踽獨行"(八)Hadoop叢集的啟動指令碼整理及守護執行緒原始碼
在上一章的偽分散式叢集搭建中,我們使用start-dfs.sh指令碼啟動了叢集環境,並且上傳了一個檔案到HDFS上,還使用了mapreduce程式對HDFS上的這個檔案進行了單詞統計。今天我們就來簡單瞭解一下啟動指令碼的相關內容和HDFS的一些重要的預設配置屬性。 一、啟動指令碼 hadoo