
[DeeplearningAI筆記]序列模型3.9-3.10語音辨識/CTC損失函式/觸發字檢測
5.3序列模型與注意力機制
覺得有用的話,歡迎一起討論相互學習~Follow Me
3.9語音辨識 Speech recognition
- 問題描述 對於音訊片段(audio clip)x ,y生成文字(transcript),人聽見的或者麥克風捕捉的都是空氣中細微的氣壓變化,語音識別系統能夠根據這種微弱的氣壓變化將音訊轉化為文字字元。
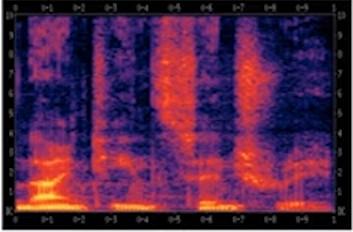
- 將空氣中微弱的氣壓變化顯示成頻率圖的形式,並輸出音訊的文字內容如下圖所示:

- 考慮到人的耳朵並不會處理聲音的原始波形,而是通過一種特殊的物理結構來測量不同的頻率和強度的聲波,音訊的常見預處理方式就是生成這樣的 聲譜圖 ,同樣的 橫軸是時間,縱軸是聲音的頻率,而圖中不同的顏色顯示了聲波的能量,也就是在不同的時間和頻率上這些聲音有多大
- 音位 過去的語音識別系統是依據 音位 來進行分辨的,即通過人為制定的音位符號來表示一個特定的語言,使用音位的符號標記就能使用機器合成出指定的語言。
- 進展 但是在 深度學習 這種端到端的學習系統中使用 音位 來表示聲音符號已經不再有必要,而是可以構建一個系統,通過向系統中輸入音訊,然後直接輸出音訊的文字。而不需要用這種人工設計的表示方法。所以語音識別使用的資料集特別巨大,往往可以長達300多個小時甚至3000個小時的文字音訊資料集。大型的商業系統中也訓練了1W或者10W個小時。
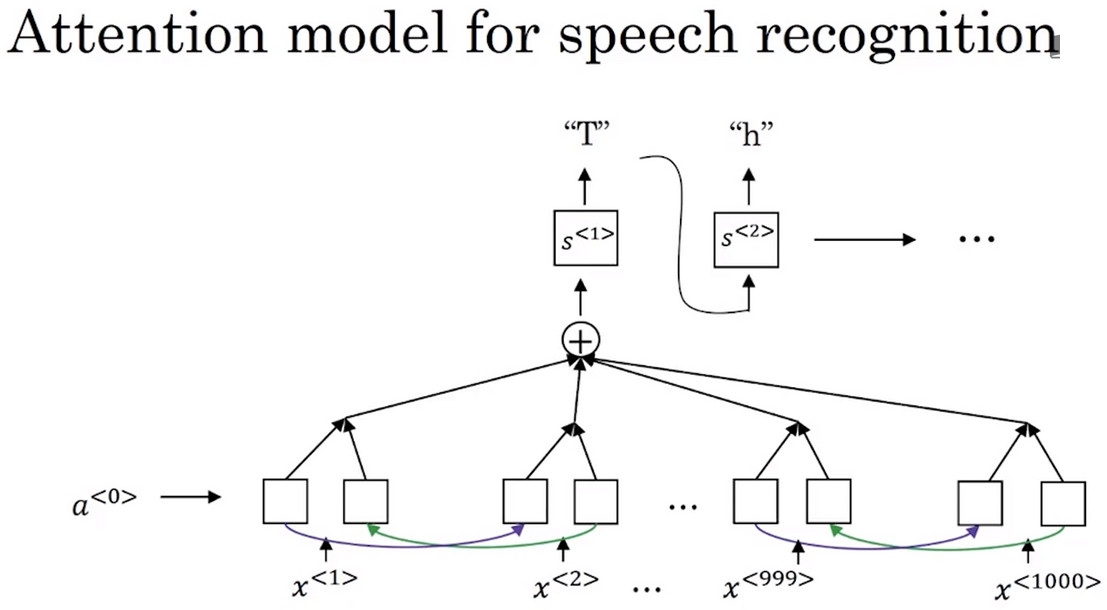
注意力模型在語音識別中的應用
- 輸入語音文字資料集的不同時間幀上的資料,並使用一個注意力模型輸出文字描述。
CTC損失函式語音識別(Connectionist temporal classification)
Graves A, Gomez F. Connectionist temporal classification:labelling unsegmented sequence data with recurrent neural networks[C]// International Conference on Machine Learning. ACM, 2006:369-376.
示例 假設輸入音訊為 the quick brown fox ,這時使用一個新的網路,在這個例子中 輸入 和 輸出 的數量相等,在這裡使用一個簡單的 單向迴圈神經網路 作為例子,而 實際應用使用的往往是一個很大很深的雙向LSTM或GIU結構的迴圈神經網路
通常輸入的數量往往比輸出的數量要多很多 比如你有一段10秒的音訊,並且特徵是100HZ的,即每秒有100個樣本,於是這段10s的音訊片段,就會有1000個輸入。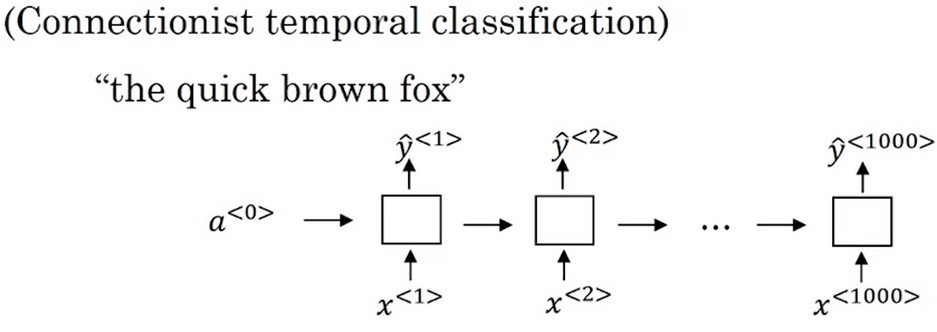
但是音訊文字識別的輸出肯定沒有1W個,所以可以用 空白字元 和 重複字元 來對其進行填充,其中 重複字元 可以用來重疊,而 空白字元 可以用來佔位。
- 例如 ttt_h_eee___\space____qqq__ \space 表示空格符,表示此處為單詞的結尾,用來分割單詞,而 “_ ” 表示用於佔位的佔位符,其中佔位符中間的 重複字元 可以摺疊。 ttt_h_eee___\space____qqq__ 可以被處理為 the q 三個t,e,q都可以被摺疊為一個字母,而佔位符可以被忽略。
3.10觸發字檢測 Trigger word detection
- 隨著語音識別的發展,越來越多的裝置可以被你的聲音 喚醒 ,這被稱為 觸發字檢測系統

- 有關於 觸發字檢測 的文獻還處於發展階段,對於 觸發字檢測 的最好演算法目前還沒有一個廣泛的定論。
- 首先將音訊檔案輸入到RNN中,然後定義目標標籤y
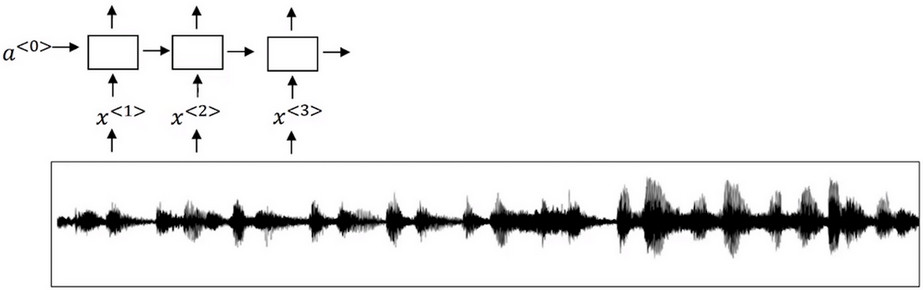
- 假如音訊片段的一點處剛說完一個觸發字,那麼你就可以在訓練集中把目標標籤都設為0,然後此點目標籤設為1.然後此點之後恢復成0,持續這個過程,只要觸發了關鍵詞,就將目標標籤設定為1.
- 缺點 該演算法構建了一個很不平衡的訓練集,即0的出現次數比1的出現次數多出了很多。 為了解決這個問題可以在 關鍵詞被觸發 後輸出多個1,以消除這種不平衡性。
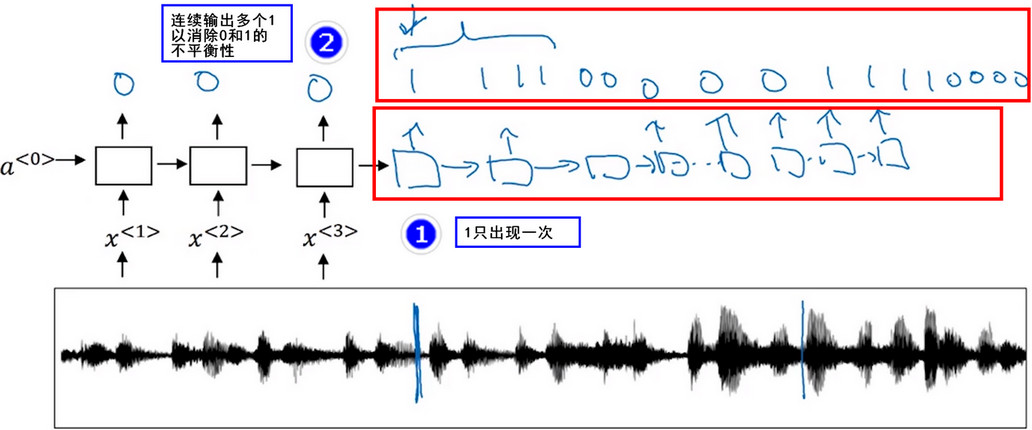
- 首先將音訊檔案輸入到RNN中,然後定義目標標籤y
相關推薦
[DeeplearningAI筆記]序列模型3.9-3.10語音辨識/CTC損失函式/觸發字檢測
5.3序列模型與注意力機制 覺得有用的話,歡迎一起討論相互學習~Follow Me 3.9語音辨識 Speech recognition 問題描述 對於音訊片段(audio clip)x
[DeeplearningAI筆記]序列模型3.6Bleu得分/機器翻譯得分指標
5.3序列模型與注意力機制 覺得有用的話,歡迎一起討論相互學習~Follow Me 3.6Bleu得分 在機器翻譯中往往對應有多種翻譯,而且同樣好,此時怎樣評估一個機器翻譯系統是一個難題
[DeeplearningAI筆記]序列模型2.7負采樣Negative sampling
叠代 的區別 text rep 新的 -h 表示 form 監督學習 5.1循環序列模型 覺得有用的話,歡迎一起討論相互學習~Follow Me 2.7 負采樣 Negative sampling Mikolov T, Sutskever I, Chen K, et al
[DeeplearningAI筆記]序列模型2.7負取樣Negative sampling
5.2自然語言處理 覺得有用的話,歡迎一起討論相互學習~Follow Me 2.7 負取樣 Negative sampling Mikolov T, Sutskever I, Chen
[DeeplearningAI筆記]序列模型1.1-1.2序列模型及其數學符號定義
5.1迴圈序列模型 覺得有用的話,歡迎一起討論相互學習~Follow Me 1.1什麼是序列模型 在進行語音識別時,給定了一個輸入音訊片段X,並要求輸出片段對應的文字記錄Y,這個例子中的
3.9 8.10-8.13聽課筆記
tee 特殊符號 sort uniq Shell特殊符_cut命令 特殊符號: * 任意個字符?任意一個字符# 註釋字符(在配置文件的命令前加#則命令不生效;shell腳本某一行加#則這一行不被執行,通常是註釋)[root@localhost ~]# #ls -a[root@localhost
第3章 Pandas資料處理(3.9-3.10)_Python資料科學手冊學習筆記
3.9 累計與分組 3.9.1 行星資料 import seaborn as sns planets = sns.load_dataset('planets') planets.shape (1035, 6) planets.head()
吳恩達Coursera深度學習課程 deeplearning.ai (5-3) 序列模型和注意力機制--程式設計作業(二):觸發字檢測
Part 2: 觸發字檢測 關鍵詞語音喚醒 觸發字檢測 歡迎來到這個專業課程的最終程式設計任務! 在本週的視訊中,你瞭解瞭如何將深度學習應用於語音識別。在本作業中,您將構建一個語音資料集並實現觸發字檢測演算法(有時也稱為關鍵字檢測或喚醒檢測)。觸發字
[DeeplearningAI筆記]卷積神經網路3.1-3.5目標定位/特徵點檢測/目標檢測/滑動視窗的卷積神經網路實現/YOLO演算法
4.3目標檢測 覺得有用的話,歡迎一起討論相互學習~Follow Me 3.1目標定位 物件定位localization和目標檢測detection 判斷影象中的物件是不是汽車–I
CleanMyMac 3.9.3中文版註冊機破解版
用戶友好 下載 密鑰 pan 拖放 tle 忽略 可靠 軟件 CleanMyMac 3.9.3是一個用戶友好的Mac應用程序,它有助於找到垃圾文件,甚至用戶和登錄項目。如果有任何可執行文件,它將立即將其全部刪除。此應用程序有助於查找長時間未使用的舊文件。CleanMyMa
《深入理解計算機系統》 練習題3.9-3.11 移位操作
移位操作 移位操作是二元操作。第一個運算元是移位量,第二個運算元是被移位的數。 移位量只能是立即數,或者放在單位元組暫存器%cl中。 被移位的數可以是一個暫存器,或者一個記憶體位置。 如果移位操作對w位長的資料,那麼移位量就是%cl中的低m位的無符號數值(它們的關係是
上週熱點回顧(3.9-3.15)
熱點隨筆: · 200行程式碼,7個物件——讓你瞭解ASP.NET Core框架的本質[3.x版] (Artech)· C#桌面開發的未來WebWindow (zeje)· 分享一個基於Net
斯坦福大學機器學習筆記——聚類(k-均值聚類演算法、損失函式、初始化、聚類數目的選擇)
上面的部落格的演算法都是有監督學習的演算法,即對於每個資料我們都有該資料對應的標籤,資料集的形式如下: 而今天我們學習的演算法是一種無監督學習的演算法——聚類,該演算法中的每個資料沒有標籤,資料集的形式如下: K-均值聚類 k-均值聚類是一種最常見
【論文閱讀筆記3】序列模型入門之LSTM和GRU
本文只是吳恩達視訊課程關於序列模型一節的筆記。 參考資料: 吳恩達深度學習工程師微專業之序列模型 博文——理解LSTM 吳恩達本來就是根據這篇博文的內容來講的,所以 個人認為 認真學習過吳恩達講的那個課程後可以不用再看那篇博文了,能獲得的新的知識不多,另外網上的博文基本也都是根據那篇
DeepLearning.ai筆記:(5-3) -- 序列模型和注意力機制
title: ‘DeepLearning.ai筆記:(5-3) – 序列模型和注意力機制’ id: dl-ai-5-3 tags: dl.ai categories: AI Deep Learning date: 2018-10-18 18:39:10
給定一個正整數k(3≤k≤15),把所有k的方冪及所有有限個互不相等的k的方冪之和構成一個遞增的序列,例如,當k=3時,這個序列是: 1,3,4,9,10,12,13,… (該序列實際上就是:3^0,3^1,3^0+3^1,3^2,3^0+3^2,3^1+3^2,3^0+3^1+3^2,…) 請你求
只有1行,為2個正整數,用一個空格隔開: k N (k、N的含義與上述的問題描述一致,且3≤k≤15,10≤N≤1000)。 計算結果,是一個正整數(在所有的測試資料中,結果均不超過2.1*10^9)。(整數前不要有空格和其他符號)。 #include<stdio.h> int
Coursera吳恩達《序列模型》課程筆記(3)-- Sequence models & Attention mechanism
《Recurrent Neural Networks》是Andrw Ng深度學習專項課程中的第五門課,也是最後一門課。這門課主要介紹迴圈神經網路(RNN)的基本概念、模型和具體應用。該門課共有3周課時,所以我將分成3次筆記來總結,這是第三節筆記。 1. B
吳恩達Coursera深度學習課程 deeplearning.ai (5-3) 序列模型和注意力機制--課程筆記
3.1 基礎模型 sequence to sequence sequence to sequence:兩個序列模型組成,前半部分叫做編碼,後半部分叫做解碼。用於機器翻譯。 image to sequence sequence to sequenc
吳恩達Coursera深度學習課程 DeepLearning.ai 提煉筆記(5-3)-- 序列模型和注意力機制
完結撒花!以下為吳恩達老師 DeepLearning.ai 課程專案中,第五部分《序列模型》第三週課程“序列模型和注意力機制”關鍵點的筆記。 同時我在知乎上開設了關於機器學習深度學習的專欄收錄下面的筆記,以方便大家在移動端的學習。歡迎關注我的知
9.Solr4.10.3數據導入(post.jar方式和curl方式)
order multicore aps start publish 所有 padding enca 頭信息 轉載請出自出處:http://www.cnblogs.com/hd3013779515/1.使用post.jar方式 java -Durl=http://192.16