
hadoop SequenceFile
SequenceFile是專為mapreduce設計的,是可分割的二進位制格式,以key/value對的形式儲存。在儲存日誌檔案時,每一行文字代表一條日誌記錄。純文字不合適記錄二進位制型別的資料。SequenceFile可以作為小檔案的容器。
write
先看下 在hadoop中如何寫SequenceFile。
private static final String[] DATA = {
"One, two, buckle my shoe",
"Three, four, shut the door",
"Five, six, pick up sticks" 上面的程式碼基於hadoop 2.6.4,指定了 file option 就不能指定 stream option,否則會丟擲異常。原因如下:
// check consistency of options
if ((fileOption == null) == (streamOption == null)) {
throw new IllegalArgumentException("file or stream must be specified");
}read
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://hadoop:9000");
FileSystem fs = FileSystem.get(configuration);
Path path = new Path("hdfs://hadoop:9000/hadoop/seq/numbers.seq");
SequenceFile.Reader.Option file = SequenceFile.Reader.file(path);
SequenceFile.Reader reader = new SequenceFile.Reader(configuration,file);
Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(),configuration);
Writable value = (Writable)ReflectionUtils.newInstance(reader.getValueClass(),configuration);
long position = reader.getPosition();
while (reader.next(key,value)){
String syncSeen = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
IOUtils.closeStream(reader);輸出內容如下:
[128] 100 One, two, buckle my shoe
[173] 99 Three, four, shut the door
[220] 98 Five, six, pick up sticks
[264] 97 Seven, eight, lay them straight
[314] 96 Nine, ten, a big fat hen
[359] 95 One, two, buckle my shoe
[404] 94 Three, four, shut the door
[451] 93 Five, six, pick up sticks
[495] 92 Seven, eight, lay them straight
[545] 91 Nine, ten, a big fat hen
[590] 90 One, two, buckle my shoe
[635] 89 Three, four, shut the door
[682] 88 Five, six, pick up sticks
[726] 87 Seven, eight, lay them straight
[776] 86 Nine, ten, a big fat hen
[821] 85 One, two, buckle my shoe
[866] 84 Three, four, shut the door
[913] 83 Five, six, pick up sticks
[957] 82 Seven, eight, lay them straight
[1007] 81 Nine, ten, a big fat hen
The SequenceFile format
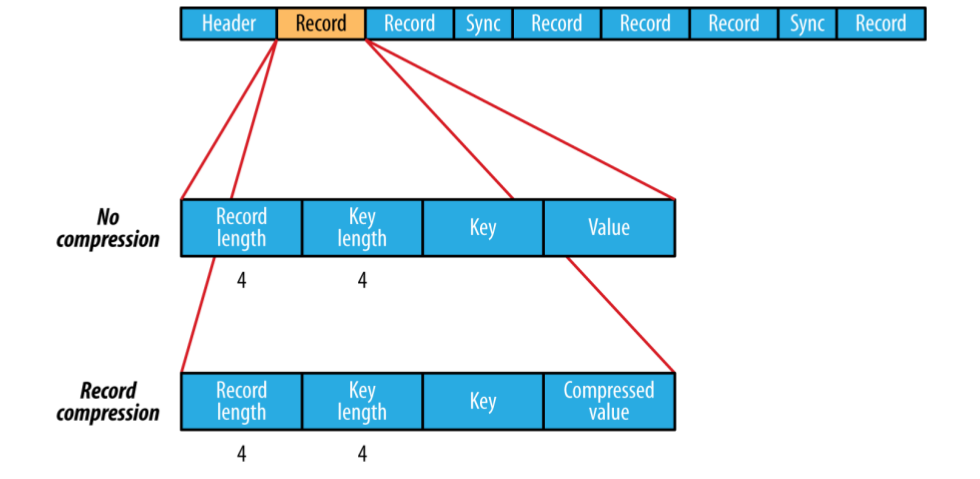
一個SequenceFile是由一個head和 一條或者多條record組成。
SequenceFile頭三個位元組是SEQ ,用數字表示;其後是version number,如下圖,Header也包括其他欄位,key/value class,compress等資訊。Sync 標誌是否允許使用者從檔案的任何position同步的讀取記錄。

SequenceFile 的record的格式化依賴於 是否開啟壓縮,如果壓縮,是record compression還是block compression。使用record compression的key不會被壓縮。
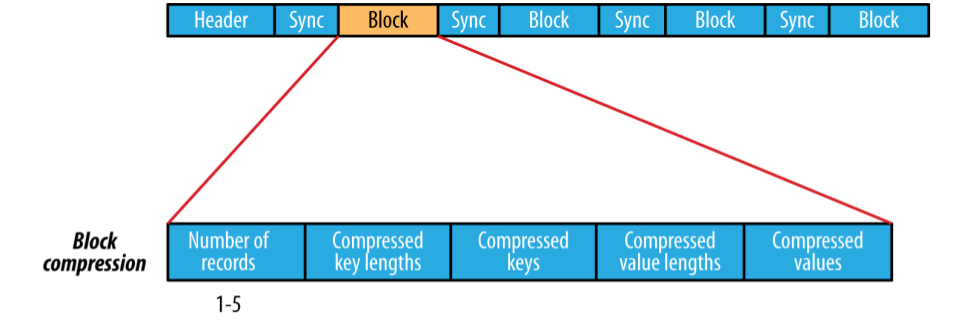
block 壓縮的有點是高效,整個塊被壓縮,而不是在記錄層進行壓縮。資料直到達到塊的大小時才被壓縮,在某一點上整個塊被壓縮,從而形成整體壓縮。預設情況下block的大小與HDFS的block的大小相同,可以使用 io.seqfile.compress.blocksize 設定。
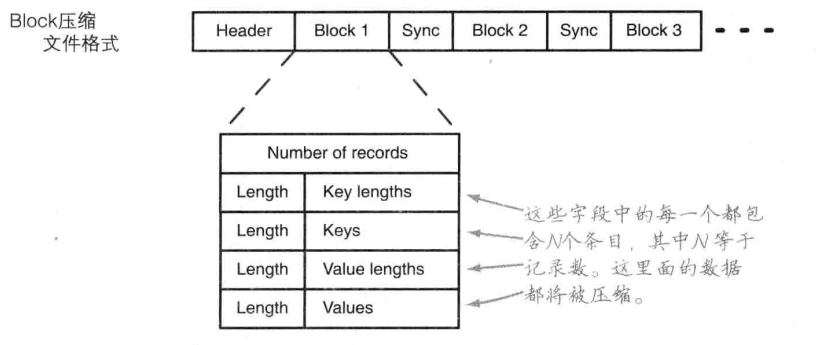
使用壓縮,只要在write中新增 一行程式碼就可以,read 程式碼可以不變
SequenceFile.Writer.Option compression = SequenceFile.Writer.compression(SequenceFile.CompressionType.BLOCK,new DefaultCodec());相關推薦
hadoop SequenceFile——大資料 儲存
SequenceFile是一個由二進位制序列化過的key/value的位元組流組成的文字儲存檔案。 基於壓縮型別CompressType,共有三種SequenceFile Writer: public static enum CompressionType { /
hadoop SequenceFile 簡介/優缺點
1. 什麼是SequenceFile 1.1.sequenceFile檔案是Hadoop用來儲存二進位制形式的[Key,Value]對而設計的一種平面檔案(Flat File)。 1.2.可以把SequenceFile當做是一個容器,把所有的檔案打包到SequenceFile類中可以
基於Hadoop Sequencefile的小檔案解決方案
基於Hadoop Sequencefile的小檔案解決方案 一、概述 小檔案是指檔案size小於HDFS上block大小的檔案。這樣的檔案會給hadoop的擴充套件性和效能帶來嚴重問題。首先,在HDFS中,任何block,檔案或者目錄在記憶體中均以物件的形式儲存,每個物件約佔150byte,如果有10
Hadoop—SequenceFile檔案的資料格式(1)
一: 概述 1 SequenceFile是Hadoop為例儲存二進位制的<k,v>而設計的一種平面檔案。 2 SequenceFile的key和value是writable或者writable子類。 3 SequenceFile的儲存不按照key排序,內部類Writer提供了
hadoop SequenceFile介紹 大資料 儲存
SequenceFile是一個由二進位制序列化過的key/value的位元組流組成的文字儲存檔案。 基於壓縮型別CompressType,共有三種SequenceFileWriter: 1 2 3 4 5 6 7 8 public static enum Co
hadoop sequenceFile詳解
hadoop不僅可以處理文字資訊,還可以處理二進位制格式資料,sequenceFile就是這樣的檔案。有以下特點:可分割支援壓縮每一行都是一個key value對可以設定同步點SequenceFile的格式是由一個header 跟隨一個或多個記錄組成。前三個位元組是一個Byt
hadoop SequenceFile
SequenceFile是專為mapreduce設計的,是可分割的二進位制格式,以key/value對的形式儲存。在儲存日誌檔案時,每一行文字代表一條日誌記錄。純文字不合適記錄二進位制型別的資料。SequenceFile可以作為小檔案的容器。 write 先
hadoop SequenceFile介紹
SequenceFile是一個由二進位制序列化過的key/value的位元組流組成的文字儲存檔案。 基於壓縮型別CompressType,共有三種SequenceFileWriter: 1 2 3 4
Hadoop IO操作之SequenceFile 和 MapFile
直接 修改 head ati rec key 情況 接口 用戶 一、SquenceFile 文件中每條記錄是可序列化,可持久化的鍵值對,提供相應的讀寫器和排序器,寫操作根據壓縮的類型分為3種。 ---Write 無壓縮寫數據 ---RecordCompressWr
Hadoop定義的SequenceFile和MapFile的程式設計實現
Hadoop定義了SequenceFile 和MapFile兩種型別的資料結構以適應Mapreduce程式設計框架的需要,Map輸出的中間結果就是由他們表示的。其中MapFile是經過排序並帶有索引的SequenceFile. SequenceFile記錄的是key/value對的列表,是序列化
Hadoop中的SequenceFile系統之一
SequenceFile是一個由二進位制序列化過的key/value的位元組流組成的文字儲存檔案。在Hadoop上利用來解決小檔案序列化的問題。 最近的專案之中,需要將伺服器內的日誌檔案壓縮成一個二進位制的序列化檔案,考慮到可以Hadoop中的HDFS
Hadoop中sequencefile和mapfile的區別
原文網址:http://blog.csdn.net/javaman_chen/article/details/7241087 Hadoop的HDFS和MapReduce子框架主要是針對大資料檔案來設計的,在小檔案的處理上不但效率低下,而且十分消耗記憶體資源(每一個小檔
Hadoop中基於檔案的資料格式(1)SequenceFile
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import o
Hadoop 中SequenceFile的簡介
MapFile 一個key-value 對應的查詢資料結構,由資料檔案/data 和索引檔案 /index 組成,資料檔案中包含所有需要儲存的key-value對,按key的順序排列。索引檔案包含一部分key值,用以指向資料檔案的關鍵位置SetFile – 基於 MapFile 實現的,他只有key,va
hadoop 使用map合並小文件到SequenceFile
耗時 art 合並 next entity 繼承 name for each nes 上一例是直接用SequenceFile的createWriter來實現,本例采用mapreduce的方式。 1、把小文件整體讀入需要自定義InputFormat格式,自定義InputFor
Hadoop HDFS SequenceFile
SequenceFile 是一個由二進位制序列化過的 key/value 的位元組流組成的文字儲存檔案,它可以在map/reduce過程中的input/output 的format時被使用。在map/reduce過程中,map處理檔案的臨時輸出就是使用SequenceFile處理過的。 所以一般的Sequen
hadoop安裝
簡介 系統 官方文檔 lock tsl star tfs replica 控制 曾經的學習筆記 1.Hadoop簡介: a) 分布式存儲系統HDFS 分布式存儲系統 提供了高可靠性、高擴展性和高吞吐率的數據存儲服務 b) 分布式計算框架MapReduce 分布式計
全文索引-lucene,solr,nutch,hadoop之nutch與hadoop
aof java get 查詢 自己 結構 目的 strong 之間 全文索引-lucene。solr。nutch,hadoop之lucene 全文索引-lucene。solr,nutch,hadoop之solr 我在去年的時候,就想把lucene,sol
Hadoop化繁為簡-從安裝Linux到搭建集群環境
開始 協調 利用 html isa 同學 防火墻 右鍵 $path 簡介與環境準備 hadoop的核心是分布式文件系統HDFS以及批處理計算MapReduce。近年,隨著大數據、雲計算、物聯網的興起,也極大的吸引了我的興趣,看了網上很多文章,感覺還是雲裏霧裏,很多不必
Ubuntu14下Hadoop開發<1> 基礎環境安裝
oot jar包 臺式機 解壓 span ice href 安裝samba lan 準備了一臺淘汰的筆記本。單核CPU。3G內存。160G硬盤;準備一個2G的U盤在官網下載了64位的14.04版本號(麒麟)的ISO。下載UNetbootin(Ubuntu專用U盤安裝工