
作業系統的記憶體分配
首先看一下“基本的儲存分配方式”種類:
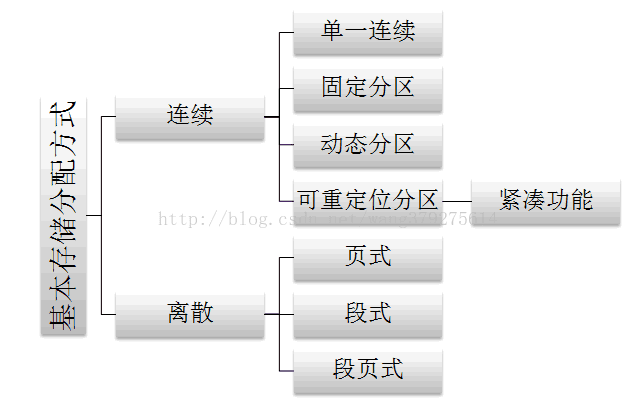
1. 離散分配方式的出現
由於連續分配方式會形成許多記憶體碎片,雖可通過“緊湊”功能將碎片合併,但會付出很大開銷。於是出現離散分配方式:將一個程序直接分散地裝入到許多不相鄰的記憶體分割槽中。
下面主要介紹“離散分配”三種方式的基本原理以及步驟:
2. 基本分頁儲存
2.1. 步驟
³ 邏輯空間等分為頁;並從0開始編號
³ 記憶體空間等分為塊,與頁面大小相同;從0開始編號
分配記憶體時,以塊為單位將程序中的若干個頁分別裝入到多個可以不相鄰接的物理塊中。
2.2. 地址結構
分兩部分:頁號、位移量(業內地址)
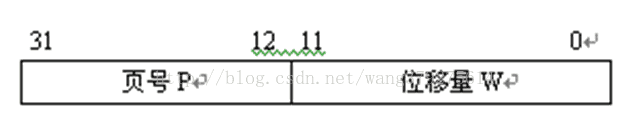
業內地址的位數可以決定頁的大小(如上圖每頁大小為4K)。
邏輯地址=頁號&位移量(&號是連線符號,是將頁號作為邏輯地址的最高位)
2.3. 地址對映(邏輯地址--->實體地址)
如下圖所示:(實體地址=塊號&塊內地址)
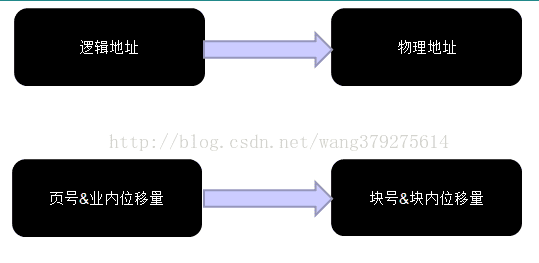
因為塊的大小=頁的大小,所以塊內位移量=頁內位移量,所以只需求出塊號即可:

如何求塊號呢?頁表來幫你
頁表:
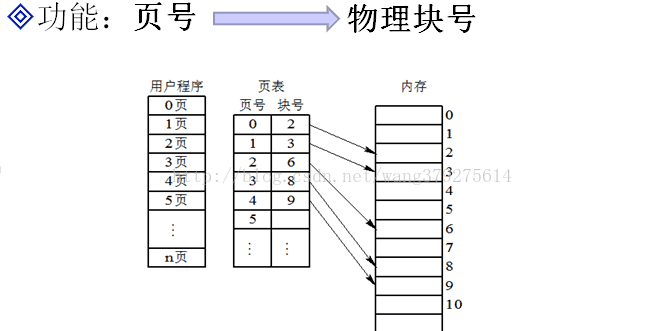
給定一個邏輯地址和頁面大小,如何計算實體地址?
1) 根據頁面大小可計算出頁內地址的位數
2) 頁內地址位數結合邏輯地址計算出頁內地址(即,塊內地址)和頁號
3) 頁號結合頁表,即可得出塊號
4) 塊號&塊內地址即可得出實體地址
2.4. 地址變換原理及步驟
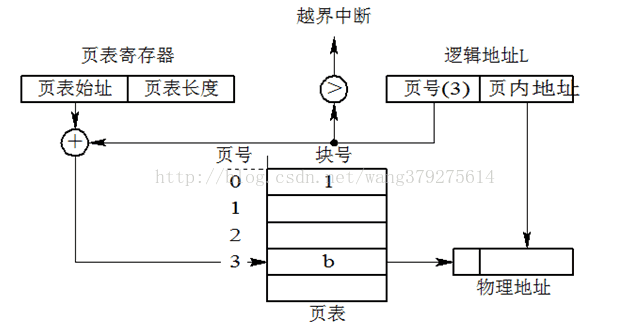
請看上圖,給出邏輯地址的頁號和頁內地址,開始進行地址變換:
1) 在被調程序的PCB中取出頁表始址和頁表大小,裝入頁表暫存器
2) 頁號與頁表暫存器的頁表長度比較,若頁號大於等於頁表長度,發生地址越界中斷,停止呼叫,否則繼續
3) 由頁號結合頁表始址求出塊號
4) 塊號&頁內地址,即得實體地址
以上即為頁式儲存的原理及整個過程……
3. 基本分段儲存
3.1. 步驟
³ 邏輯空間分為若干個段,每個段定義了一組有完整邏輯意義的資訊(如主程式Main()),如:
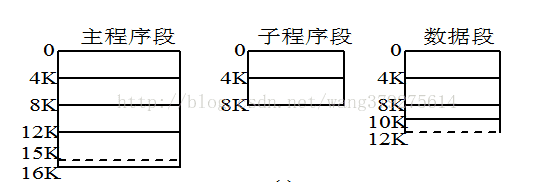
記憶體空間為每個段分配一個連續的分割槽
段的長度由相應的邏輯資訊組的長度決定,因而各段長度不等,引入分段儲存管理方式的目的主要是為了滿足使用者(程式設計師)在程式設計和使用上多方面的要求。
要注重理解,完整的邏輯意義資訊,就是說將程式分頁時,頁的大小是固定的,只根據頁面大小大小死生生的將程式切割開;而分段時比較靈活,只有一段程式有了完整的意義才將這一段切割開。(例如將一個人每隔50釐米切割一段,即為分頁;而將一個人分割為頭部、身體、腿部(有完整邏輯意義)三段,即為分段)
3.2. 地址結構
分兩部分:段號、位移量(段內地址)

³ 段內地址的位數可以決定段的大小
³ 邏輯地址=段號&段內地址(&號是連線符號,是將段號作為邏輯地址的最高位)
3.3. 地址對映(邏輯地址--->實體地址)
如下圖所示:(實體地址=基址+段內地址)(注意為+號,而不是&號)
由上圖可知若想求實體地址,只需求出基址即可:
如何求基址呢?段表來幫你
段表:
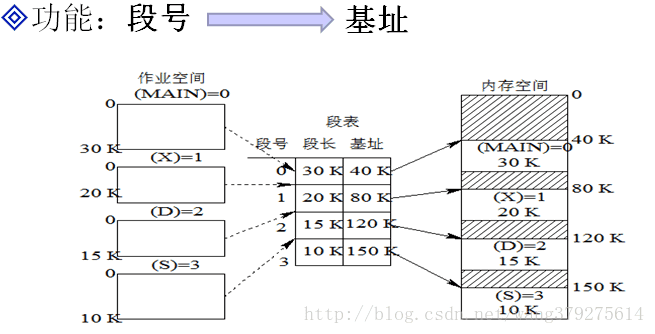
求基址的過程與頁式儲存中求塊號的過程原理相同,這裡需要注意的是,實體地址是基址+段內地址,而不是基址&段內地址,由邏輯地址得到段號、段內地址,再根據段號和段表求出基址,再由基址+段內地址即可得實體地址。
3.4. 地址變換原理及步驟
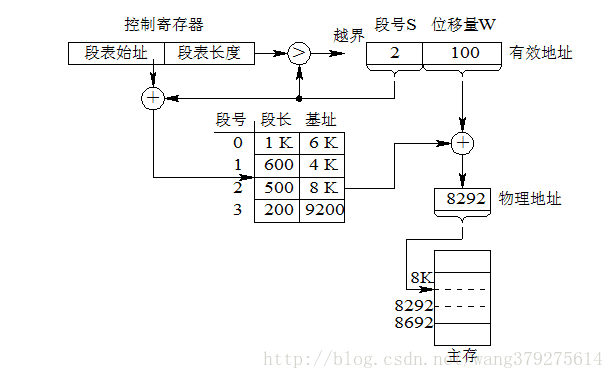
請看上圖,給出邏輯地址的段號和段內地址,開始進行地址變換:
1) 在被調程序的PCB中取出段表始址和段表長度,裝入控制暫存器
2) 段號與控制暫存器的頁表長度比較,若頁號大於等於段表長度,發生地址越界中斷,停止呼叫,否則繼續
3) 由段號結合段表始址求出基址
4) 基址+段內地址,即得實體地址
以上即為段式儲存的原理及整個過程……
分頁和分段的主要區別:

4. 基本段頁式儲存
4.1. 步驟
³ 使用者程式先分段,每個段內部再分頁(內部原理同基本的分頁、分段相同)
4.2. 地址結構
分三部分:段號、段內頁號、頁內地址

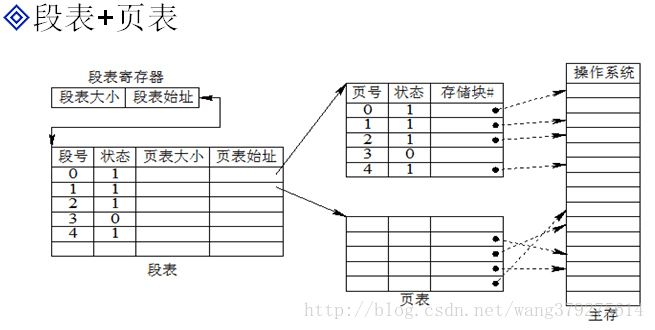
4.3. 地址對映(邏輯地址--->實體地址)
³ 邏輯地址----- >段號、段內頁號、業內地址
³ 段表暫存器--- >段表始址
³ 段號+段表始址---- >頁表始址
³ 頁表始址+段內頁號----->儲存塊號
³ 塊號+頁內地址------>實體地址
4.4. 地址變換原理及步驟
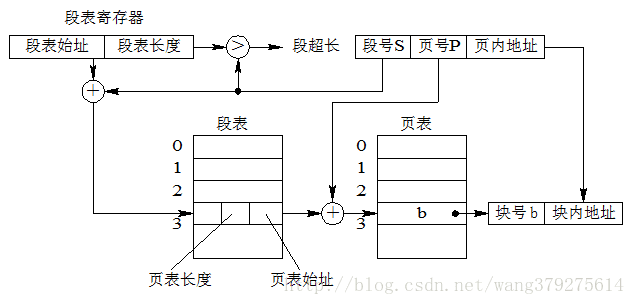
請看上圖,給出邏輯地址的段號、頁號、頁內地址,開始進行地址變換:
1) 在被調程序的PCB中取出段表始址和段表長度,裝入段表暫存器
2) 段號與控制暫存器的頁表長度比較,若頁號大於等於段表長度,發生地址越界中斷,停止呼叫,否則繼續
3) 由段號結合段表始址求出頁表始址和頁表大小
4) 頁號與段表的頁表大小比較,若頁號大於等於頁表大小,發生地址越界中斷,停止呼叫,否則繼續
5) 由頁表始址結合段內頁號求出儲存塊號
6) 儲存塊號&頁內地址,即得實體地址
以上即為段頁式儲存的原理及整個過程……
5. 總結
在頁式、段式儲存管理中,為獲得一條指令或資料,須兩次訪問記憶體;而段頁式則須三次訪問記憶體
相關推薦
C語言——作業系統記憶體分配過程
記憶體分配機制的發展過程: 第一階段——程式直接操作實體記憶體。 某臺計算機總的記憶體大小是128M,現在同時執行兩個程式A和B,A需佔用記憶體10M,B需佔用記憶體100。計算機在給程式分配記憶體時會採取這樣的方法:先將記憶體中的前10M分配給程式A
作業系統記憶體分配分頁與分段的區別
一. 分頁儲存管理 1.基本思想 使用者程式的地址空間被劃分成若干固定大小的區域,稱為“頁”,相應地,記憶體空間分成若干個物理塊,頁和塊的大小相等。可將使用者程式的任一頁放在記憶體的任一塊中,實現了離散分配。 2. 分頁儲存管理的地址機構 15 12 11
作業系統原理:動態記憶體分配
動態記憶體分配背後的機制深刻的體現了電腦科學中的這句名言: All problem in CS can be solved by another level of indirection. — Butler Lampson
作業系統: 最佳適配演算法和鄰近適配演算法的模擬實現(記憶體分配演算法)
實現動態分割槽的分配演算法。 (1) 最佳適配演算法:選擇記憶體空閒塊中最適合程序大小的塊分配。 (2) 鄰近適配演算法:從上一次分配的地址開始查詢符合要求的塊,所查詢到的第一個滿足要求的空閒塊就分配給程序。 模擬新增程序的時候,假定記憶體是一塊完整的空閒區,對於演算法(1
作業系統筆記:(一)實體記憶體分配1:連續記憶體分配
remark: 這是我準備考研期間看學堂線上清華大學的OS MOOC的筆記,由於博主不是科班出身,所寫錯誤可能很大,望大家指正. 本文結構如下: 計算機記憶體管理概述 連續記憶體分配 碎片整理 e.g: 夥伴系統(Buddy System) 計算機
面試知識點-- 作業系統執行可執行程式時,記憶體分配是怎樣的?
一般認為在c中分為這幾個儲存區: 1. 棧 --有編譯器自動分配釋放 2. 堆 -- 一般由程式設計師分配釋放,若程式設計師不釋放,程式結束時可能由OS回收 3. 全域性區(靜態區) -- 全域性變數和靜態變數的儲存是放在一塊的,初始化的全域性變數和靜態變數在一塊區域,未初始化的全
作業系統常見記憶體分配演算法及優缺點
常見記憶體分配演算法及優缺點如下: (1)首次適應演算法。使用該演算法進行記憶體分配時,從空閒分割槽鏈首開始查詢,直至找到一個能滿足其大小需求的空閒分割槽為止。然後再按照作業的大小,從該分割槽中劃出一塊記憶體分配給請求者,餘下的空閒分割槽仍留在空閒分割槽鏈中。 該演算法
作業系統--記憶體管理之連續分配管理方式
連續分配方式,是指為一個使用者程式分配一個連續的記憶體空間。它主要包括單一連續分配、固定分割槽分配和動態分割槽分配。 1單一連續分配 記憶體在此方式下分為系統區和使用者區,系統區僅提供給作業系統使用,通常在低地址部分;使用者區是為使用者提供的、除系統區之外的記憶體空間。這
作業系統的記憶體分配
首先看一下“基本的儲存分配方式”種類: 1. 離散分配方式的出現 由於連續分配方式會形成許多記憶體碎片,雖可通過“緊湊”功能將碎片合併,但會付出很大開銷。於是出現離散分配方式:將一個程序直接分散地裝入到許多不相鄰的記憶體分割槽中。
作業系統中的記憶體分配
連續的記憶體分配 記憶體通常有兩個區域 - 存放作業系統的區域 - 存放使用者程序的區域 將多個程序存放到記憶體中需要考慮如何將輸入佇列中需要調入記憶體的多個程序進行記憶體分配。採用連續記憶體分配時,每個程序位於一個連續的記憶體區域。 記憶體分配
作業系統員動態記憶體分配————分頁式儲存
4.3 知識點3:基本分頁儲存管理方式4.3.1 要點歸納1. 基本分頁儲存管理的原理在分割槽儲存管理中,要求把作業放在一個連續的儲存區中,因而會產生許多碎片,固定分割槽會產生內部碎片,動態分割槽會產生外部碎片。儘管通過拼接技術可以解決碎片問題,但代價較高。分頁儲存管理允許將作業存放到許多不相鄰接的記憶體區域
作業系統的學習(2)——實體記憶體管理:連續記憶體分配
記憶體的最小訪問單位是位元組(8it),一般計算機系統是32位匯流排,一次讀寫可以讀或者寫32位也就是4位元組。 CPU裡會看到快取記憶體,快取記憶體就是在進行讀寫指令或者指令執行的過程中,訪問資料都需要從記憶體中讀資料,如果這時候有大量資料需要讀寫或者重複利
記憶體分配與跟蹤
編寫一個程式,包括兩個執行緒,一個執行緒用於模擬記憶體分配活動,另一個用於跟蹤第一個執行緒的記憶體行為,要求兩個執行緒之間通過訊號量實現同步,模擬記憶體活動的執行緒可以從一個檔案中讀出要進行的記憶體操作。每個記憶體操作包含如下內容: 時間:每個操作等待時間; 塊數:分配記憶體的
學習筆記-C語言6(指標與動態記憶體分配)
1. 指標 指標的引入: 指標是C語言最強大的功能之一,使用指標可以儲存某個變數在記憶體中的地址,並且通過操作指標來對該片記憶體進行靈活的操作,例如改變原變數的值,或者構造複雜的資料結構。指標一般初始化為NULL(0)。& 是取地址運算,* 是間接運算子,通過 * 可以訪問與修改
JVM的垃圾收集機制和記憶體分配策略
首先給大家看一下JVM的資料區模型。 上圖是JVM的資料區模型。但是在Hotspot JVM中,我們知道執行時常量是屬於方法區的,而方法區又屬於堆。對於棧,在hotspot中虛擬機器棧和本地棧是合二為一的。 這裡在順便說一說虛擬機器物件的結構,如下圖所示
java記憶體分配之堆,棧,常量池,方法區
java棧 java棧,在函式的定義中定義的基本型別(int,long,short,byte,float,double,boolean,char)的變數資料和物件的引用變數分配的儲存空間的地方。當在程式碼塊中定義一個變數時,java棧就為這個變數分配適當的記憶體空間,當該變數退出作用域時,jav
記憶體探尋1之——值型別和引用型別的記憶體分配機制
String物件和值型別的記憶體分配機制: 同樣由前延伸,上上篇《由String型別分析,所產生的對引數傳遞之惑的解答》中,最後提及,如果將引用型別的按值傳遞和按引用傳遞,用託管堆表
c++學習之路:2.預設引數&函式過載&堆記憶體分配
預設引數 規則:程式從右向左延伸讀取 例子:如下sortarr函式,在創造函式的時候可以直接賦值,這樣執行的時候就執行預設值。 又如debug函式,不傳參就會列印------------------; 函式過載 理解:幾個同名函式,所設有的引數不一樣,就代表為不同函式。 所以傳參的時候
Java中的陣列和記憶體分配
理解陣列 概念:陣列是儲存同一種資料型別多個元素的集合。也可以看成是一個容器。 陣列既可以儲存基本資料型別,也可以儲存引用資料型別,只要所有的陣列元素具有相同的資料型別即可 定義陣列的方法: ①:type[] arrayName;(推薦使用這種方式) ②:ty
5.3 記憶體分配與垃圾回收
5.3 記憶體分配與垃圾回收 在5.4部分中,我們將展示如何用一個暫存器機器實現一個SCHEME直譯器。 為了簡化討論,我們假定我們的暫存器機器有一個列表結構的記憶體,而且 操作列表結構的基本操作是原生的。當我們聚焦於在一個SCHEME直譯器中的控制機制時, 假定如此的記憶