
PAC學習理論:機器學習那些事
參考翻譯,有大量刪除和修改,如有異議,請拜訪原文。一定要看英文原文!!!。
機器學習是有別於專家系統(基於知識/規則)的一種模式識別方法,與專家系統的構建方法不同,但目的相同。本文分析了一眾機器學習方法,並給出了一些機器學習概念的通俗解釋。
通俗論述的理論解釋在第二段,由公式詳細說明。
一、機器學習那點事
學習=表示 + 評價+ 優化
假設有一個應用,你認為機器學習有可能在其中發揮作用。那麼,你面臨的第一個問題是各種機器學習演算法令人眼花繚亂。應挑選使用哪一個?現在有成千上萬的機器學習演算法,每年還有成百上千的新演算法發表出來。免迷失在這麼多演算法中的關鍵是,要認識到這些演算法都是由三個部分組成的,分別是:
表示(Representation)
一個分類器必須用計算機可以處理的某種形式語言來表示。反過來講,為學習器選擇一種表示,就意味選擇一個特定的分類器集合。學習器可能學出的分類器只能在這個集合中。這個集合被稱為學習器的假設空間(hypothesis space)。如果某個分類器不在該空間中,它就不可能被該學習器學到。與此相關的一個問題是如何表示輸入,即使用哪些特徵,本文稍後介紹。
評價(Evaluation)
我們需要一個評價函式(亦稱為目標函式或打分函式)來判斷分類器的優劣。機器學習演算法內部使用的評價函式和我們希望分類器進行優化的外部評價函式有所不同。這是為了便於優化,接下來會討論。
優化(Optimization)
一些學習機制的優化方法
使用什麼樣的模型表示什麼樣的假設,使用怎樣的評價方法,使用什麼樣的優化方法篩選最優假設。
下面的圖有問題,有誤導性,應該上原圖!!!!:

..................

..................
當然,並不是表 1 中從各列選出元素的相互組合都同樣有意義。例如,離散表示很自然地與組合優化相結合;而連續表示則與連續優化相結合。然而,很多學習器同時包含離散和連續的部分。實際上,所有可能的組合也都快被實現過了。
過擬合(Overfitting)有多張面孔
如果我們擁有的知識和資料並不足以學習出正確的分類器,將會怎樣呢?我們就得冒風險構建一個分類器(或者其中一部分),這個分類器並非建立在現實基礎上,而是將資料隨機表現加以解讀。這個問題稱為過擬合,它是機器學習中的棘手問題。當你的學習器輸出的分類器在訓練資料上準確率為 100%,而在測試資料上僅有 50% 的時候(而本來可以學到一個分類器能夠在兩個資料上均達到 75% 的準確率),說明這個分類器發生過擬合了。
機器學習領域的每個人都瞭解過擬合,但過擬合會以多種並不明顯的形式出現。一種理解過擬合的方式是將泛化誤差(generalization error)分解為偏置(bias)和方差( variance)【9】。偏置度量了學習器傾向於一直學習相同錯誤的程度。方差則度量了學習器傾向於忽略真實訊號、學習隨機事物的程度。圖 1用朝板子扔飛鏢作為類比進行了直觀說明。

一個線性學習器有較高的偏置,因為當兩個類別的交界不是超平面的時候,這個學習器就無法進行歸納(摘注:原文 A linear learner has high bias, because when the frontier between two classes is not a hyper-plane the learner is unable
to induce it)。決策樹就不會有這個問題,因為它可以表示任意的布林函式,但在另一方面,決策樹會面臨高方差的問題:在同一現象所產生的不同訓練資料上學習的決策樹往往差異巨大,而實際上它們應當是相同的。類似道理也適用於優化方法的選擇上:與貪心搜尋相比,柱搜尋的偏置較低,但方差較高,原因是柱搜尋會嘗試搜尋更多的假設。因此,與直覺相反,一個學習能力更強的學習器並不見得比學習能力弱的效果更好。
圖 2 示例說明了這一點(注:訓練樣例含有 64 個布林型別特徵和 1 個根據一個集合的“如果…那麼…”的規則集合計算得到的布林型別的類別。圖中的曲線是對 100 次執行結果的平均,每次對應不同的隨機產生的規則集合。誤差條(error bar)代表兩個標準方差。具體細節請參考論文【10】)。即使真正的分類器是一個規則集合,但根據 1000個樣例學習的樸素貝葉斯學習器(摘注:原文 Naive Bayes)仍比一個規則學習器的準確率更高。甚至當樸素貝葉斯錯誤地假設分類面是線性的,也依然如此。這種情形在機器學習領域很常見:一個強錯誤假設比那些弱正確假設更好,這是因為後者需要更多的資料才能避免過擬合。

交叉驗證可以幫助避免過擬合,例如通過交叉驗證來選擇決策樹的最佳大小。但這不能徹底解決問題,因為假如我們利用交叉驗證做太多的引數選擇,它本身就會開始過擬合【17】。
..................................更多的資料勝過更聰明的演算法
假設你已經盡你所能構建了最好的特徵集合,但分類器的效果仍不夠好,這時候應該怎麼辦呢?有兩個主要選擇:設計更好的學習演算法,或者收集更多資料(包括更多的樣例和不致造成維度災難的更多可能的原始特徵)。機器學習研究者更關注前者,但從實用角度來看,最快捷的方法是收集更多資料。作為一條經驗,有大量資料的笨演算法要勝過資料量較少的聰明演算法。(畢竟,機器學習就是研究如何讓資料發揮作用的。)
然而這帶來了另外一個問題:可擴充套件性(scalability)。在絕大多數電腦科學問題中,兩個主要資源是有限的——時間和記憶體。而在機器學習中,還有第三個:訓練資料(摘注:原文training data )。其中哪一個資源會成為瓶頸是隨著時間變化而不斷變化的。在20世紀80年代,瓶頸是資料。現在的瓶頸則是時間。我們有海量資料,但沒有足夠的時間處理它們,只能棄之不用。這就造成一個悖論:即使理論上說,更多資料意味著我們可以學習更復雜的分類器,但在實踐中由於複雜分類器需要更多的學習時間,我們只能選用更簡單的分類器。一個解決方案是對複雜分類器提出快速學習演算法,在這個方向上已經有了一些引人注目的進展(例如赫爾滕(Hulten)和多明戈斯(Domingos)的工作【11】)。
採用更聰明的演算法得到的回報比預期要少,一部分原因是,機器學習的工作機制基本上是相同的。這個論斷也許讓你吃驚,特別是當你想到諸如規則集與神經網路之間差異巨大的表示方法的時候。但實際上,命題規則的確可以輕易地表示成神經網路,其他表示之間也有類似的關係。本質上所有的學習器都是將臨近的樣例歸類到同一個類別中;關鍵的不同之處在於“臨近”的意義。對於非均勻分佈的資料,不同的學習器可以產生迥乎不同的分類邊界,同時仍能在關心的領域(即那些有大量訓練樣例、測試樣例也會有很大概率出現的領域)保證得到相的預測結果。這也有助於解釋為什麼能力強的學習器雖然不穩定卻仍然很精確。圖 3在二維空間展示了這一點,在高維空間這個效應會更強。

作為一條規則,首先嚐試最簡單的學習器總是有好處的(例如應該在邏輯斯蒂迴歸之前先嚐試樸素貝葉斯,在支援向量機之前先嚐試近鄰 [ 摘注:原文, naïve Bayes before logistic regression, k-nearest neighbor beforesupport vector machines)])。更復雜的分類器固然誘人,但它們通常比較難駕馭,原因包括我們需要調節更多的引數才能得到好的結果,以及它們的內部機制更不透明。
學習器可以分為兩大類:一類的表示是大小不變的,比如線性分類器(摘注:原文 linear classifiers);另一類的表示會隨著資料而增長,比如決策樹(摘注:原文 decisiontrees)。(後者有時候會被稱為非引數化學習器(nonparametric learners),但不幸的是,它們通常需要比引數化學習器學習更多的引數。)資料超過一定數量後,大小不變的學習器就不能再從中獲益。(注意圖 2 中樸素貝葉斯的準確率是如何逼近大約 70%的。)而如果有足夠的資料,大小可變的學習器理論上可以學習任何函式,但實際上卻無法做到。這主要是受到演算法(例如貪心搜尋會陷入區域性最優)和計算複雜度的限制。而且,由於維度災難,再多的資料也不會夠。正是由於這些原因,只要你努力,聰明的演算法——那些充分利用已有資料和計算資源的演算法——最後總能取得成功。在設計學習器和學習分類器之間並沒有明顯的界限;因為任何知識要麼可以被編碼進學習器,要麼可以從資料中學到。所以,機器學習專案通常會有學習器設計這一重要部分,機器學習實踐者應當在這方面積累一些專門知識【12】。
........................................................簡單並不意味著準確
著名的奧坎姆剃刀(occam’s razor)原理稱:若無必要,勿增實體(entities should not be multi-plied beyond necessity)。在機器學習中,這經常被用來表示成:對於有相同訓練誤差的兩個分類器,比較簡單的那個更可能有較低的測試誤差。關於這個斷言的證明經常出現在文獻中,但實際上對此有很多反例,而且“沒有免費的午餐”定理也暗示了這個斷言並不正確。
我們前面已經看到了一個反例:模型整合。整合模型的泛化誤差會一直隨著增加新的分類器而改進,甚至可以優於訓練誤差。另一個反例是支援向量機,它實際上可以有無限個引數而不至於過擬合。而與之相反,函式可以將軸上任意數量、任意分類的資料點劃分開,即使它只有1個引數【23】。因此,與直覺相反,在模型引數的數量和過擬合之間並無直接聯絡。
一個更成熟的認識是將複雜度等同於假設空間的大小。這是基於以下事實:更小的假設空間允許用更短的程式碼表示假設。那麼“理論保證”一節中的邊界就暗示了,更短的假設可以泛化得更好。這還可以進一步改善為,為有先驗偏好的空間中的假設分配更短的程式碼。但如果將此看作是準確(accuracy)和簡單(simplicity)之間權衡的“證明”,那就變成迴圈論證了—— 我們將所偏好的假設設計得更加簡單,而如果結果是準確的是因為我們的偏好是準確的,而不是因為這些假設在我們選擇的表示方法中是“簡單的”............................................................
簡單意味著較小的泛化誤差,但有可能造成學習器本身的偏差很大。
..............................................................
相關並不意味著因果
相關不意味著因果,這一點經常被提起,好像在這兒已經不值得再加贅述了。但是,即使我們討論的這些學習器只能學習到相關性,它們的結果也經常被作為因果關係來對待。這樣做錯了麼?如果是錯的,為什麼人們還這樣做呢?
更多時候,人們學習預測模型的目標是作為行動指南。如果我們發現超市裡的啤酒和尿布經常被一起購買,那將啤酒放在尿布旁邊將會提高銷售量。(這是資料探勘領域的著名例子。)但除非真的做實驗,不然很難發現這一點。機器學習通常應用於觀測(observational)資料,在觀測資料中預測變數並不在學習器的控制之下,這與實驗(experimental)資料相反,後者的預測變數在控制範圍內。一些學習演算法其實有潛力做到從觀測資料發現因果資訊,但它們的可用性比較差 【19】。而另一方面,相關性是因果關係的標誌,我們可以將其作為進一步考察的指南(例如試圖理解因果鏈可能是什麼樣)。
二、PAC學習理論
學習=PAC可學習=ε可學習
1.我們不要求學習器輸出零錯誤率的假設,只要求錯誤率被限制在某常數ε範圍內,ε可為任意小。
2.不要求學習器對所有任意抽取的資料都能成功預測,只要求其失敗的概率被限定在某個常數μ的範圍內,μ可取任意小。
3.簡而言之,我們只要求學習器可能學習到一個近似正確的假設,故得到了“可能近似正確學習”或PAC學習。
PAC可學習的主要公式
下列公式是機器學習的泛化誤差和一些學習器引數的關係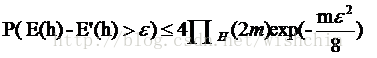
簡單並不意味著準確
著名的奧坎姆剃刀(occam’s razor)原理稱:若無必要,勿增實體(entities should not be multi-plied beyond necessity)。
在機器學習中,簡單的演算法意味著增長函式
較小,帶入公式12,意味著相對較小的泛化誤差。
但是簡單的演算法導致E’(h)較大,產生較大的訓練誤差,導致學習器變得沒有實際意義。
更多的資料有更好的準確率
相關並不意味著因果
相關推薦
PAC學習理論:機器學習那些事
參考翻譯,有大量刪除和修改,如有異議,請拜訪原文。一定要看英文原文!!!。 機器學習是有別於專家系統(基於知識/規則)的一種模式識別方法,與專家系統的構建方法不同,但目的相同。本文分析了一眾機器學習方法,並給出了一些機器學習概念的通俗解釋。
六天搞懂“深度學習”之一:機器學習
一般來說,人工智慧、機器學習和深度學習是相互關聯的:“深度學習是一種機器學習,而機器學習是一種人工智慧。” 機器學習指的是人工智慧的特定領域,即,機器學習表示人工智慧的特定技術組成。機器學習是一種從“資料”中找出“模型”的技術。 深度學習是機器學習的一種技術。 深度學習近年來備受
深度譯文:機器學習那些事 關於自己的理解
【譯題】機器學習的那些事 【譯者】劉知遠 【說明】譯文載於《中國計算機學會通訊》 第 8 卷 第 11 期 2012 年 11 月 ,本文譯自Communications of the ACM 2012年第10期的“A Few Useful Things to
Ng第十一課:機器學習系統的設計(Machine Learning System Design)
未能 計算公式 pos 構建 我們 行動 mic 哪些 指標 11.1 首先要做什麽 11.2 誤差分析 11.3 類偏斜的誤差度量 11.4 查全率和查準率之間的權衡 11.5 機器學習的數據 11.1 首先要做什麽 在接下來的視頻將談到機器
專家坐堂:機器學習中對核函數的理解
wechat size 學習 blank weixin itl cti title redirect 專家坐堂:機器學習中對核函數的理解 專家坐堂:機器學習中對核函數的理解
機器學習入門之四:機器學習的方法-神經網絡(轉載)
轉載 bsp 圖像 src nbsp 加速 數值 str 我們 轉自 飛鳥各投林 神經網絡 神經網絡(也稱之為人工神經網絡,ANN)算法是80年代機器學習界非常流行的算法,不過在90年代中途衰落。現在,攜著“深度學習”之勢,神
搜索系統10:機器學習算法淺析
eric 功能 ood 簡單的 ons 線性回歸 不知道 效果 大堆 很多網站都有猜你喜歡,我對淘寶的推薦還是比較滿意的。很多算法都可以實現推薦功能,下面來看一看機器學習的算法: 1.回歸算法。 回歸的意思大概是,估計這堆數據這個規律,然後找出這個規律,這個過程就是回歸。s
邪惡的三位一體:機器學習、黑暗網絡和網絡犯罪
機器學習 網絡安全 網絡犯罪 作者:Martin Banks我們應該期待與網絡犯罪分子進行持續的鬥爭,因為惡意軟件會變得聰明,而我們的安全防護技能也會不斷提高。大多數人都知道物聯網,它需要監視和控制成千上萬的單個傳感器和設備,以構成一個完整的網絡。大多數人也會聽說勒索軟件,無論是作為企業中的個人或
終極演算法:機器學習和人工智慧如何重塑世界筆記(轉)
終極演算法:機器學習和人工智慧如何重塑世界筆記 2017年08月17日 11:00:38 Notzuonotdied 閱讀數:4492 版權宣告:本文為博主原創文章,未經博主允許不得轉載。 https://blog.csdn.net/Notzuonotdied/artic
sklearn 學習筆記-3 機器學習理論基礎
本章主要知識點: 過擬合和欠擬合的概念 模型的成本及成本函式的含義 評價一個模型的好壞的標準 學習曲線,以及用學習曲線來對模型進行診斷 通用模型優化方法 其他模型評價標準 ##3.1過擬合和欠擬合 過擬合就是模型能很好的擬合訓練樣
TensorFlow系列專題(二):機器學習基礎
歡迎大家關注我們的網站和系列教程:http://www.tensorflownews.com/,學習更多的機器學習、深度學習的知識! 目錄: 資料預處理 歸一化 標準化 離散化 二值化 啞編碼
TensorFlow系列專題(一):機器學習基礎
歡迎大家關注我們的網站和系列教程:http://www.tensorflownews.com/,學習更多的機器學習、深度學習的知識! 一.人工智慧發展 1956年的8月,美國達特茅斯學院(Dartmouth College)舉行了一次研討會,這次會議由約翰[圖片上傳失敗...(ima
人工智慧入門(三):機器學習問題的基本型別
1:concept learning:version space,decision tree等; 2:rule learning:If-then rules, association rules, genetic programming等; 3. instance-based learning(
機器學習筆記 第1課:機器學習中的資料
資料在機器學習中起著重要的作用。 在談論資料時,理解和使用正確的術語非常重要。 你如何看待資料?想想電子表格吧,有列、行和單元格。 從統計視角而言,機器學習的任務是在假設函式( f )的上下文中構建資料。這些假設函式由機器學習演算法通過學習建立。給定一些輸入變數( Input ),該函式回答
流體標註:機器學習助力探索性介面研發,大幅提升影象標註速度
文 / 機器感知研究員 Jasper Uijlings 和 Vittorio Ferrari 對於基於深度學習的現代計算機視覺模型(例如由 TensorFlow Object Detection API 實現的模型)而言,其效能取決於能否使用日益擴大的標註訓
MIT與谷歌專家合著論文:機器學習和神經科學的相互啟發與融合
摘 要 神經科學專注的點包括計算的細節實現,還有對神經編碼、力學以及迴路的研究。然而,在機器學習領域,人工神經網路則傾向於避免出現這些,而是往往使用簡單和相對統一的初始結構,以支援成本函式(cost funcion)的蠻力最優化。近期出現了兩項機器學習方面的進展,或許會將這兩種看似不同的
免費報名 | 微軟亞洲研究院副院長劉鐵巖:機器學習技術前沿與未來展望
人工智慧備受關注、取得革命性進步背後的最大推手是“機器學習”。機器學習從業者在當下需要掌握哪些前沿技術?展望未來,又會有哪些技術趨勢值得期待? AI科技大本營聯合華章科技特別邀請到了微軟亞洲研究院副院長劉鐵巖博士進行線上公開課分享,他將帶來微軟研究院最新的研究成果,以及對機器學習領域未
未明學院:機器學習vs深度學習,如何規劃學習與就業路徑
自2016年以來,業界掀起一股人工智慧的熱潮。 2017年初,AlphaGo化身網路棋手Master擊敗聶衛平、柯潔、樸廷桓、井山裕太在內的數十位中日韓圍棋高手,在30秒一手的快棋對決中,無一落敗,拿下全勝,在棋界和科技界引發劇震。這使人們認識到AI(Artifical Intelligence
今晚直播 | 微軟亞洲研究院副院長劉鐵巖:機器學習技術前沿與未來展望
人工智慧正受到越來越多的關注,而這波人工智慧浪潮背後的最大推手就是“機器學習”。機器學習從業者在當下需要掌握哪些前沿技術?展望未來,又會有哪些技術趨勢值得期待? AI科技大本營聯合華章科技特別邀請到了微軟亞洲研究院副院長劉鐵巖博士進行線上公開課分享,他將帶來微軟研究院最新的研究成果,以及對機
直播即將開始 | 微軟亞洲研究院副院長劉鐵巖:機器學習技術前沿與未來展望...
人工智慧正受到越來越多的關注,而這波人工智慧浪潮背後的最大推手就是“機器學習”。機器學習從業者在當下需要掌握哪些前沿技術?展望未來,又會有哪些技術趨勢值得期待? AI科技大本營聯合華章科技特別邀請到了微軟亞洲研究院副院長劉鐵巖博士進行線上公開課分享,他將帶來微軟研究院最