
基於最小生成樹的實時立體匹配演算法簡介
圖割,置信傳播等全域性優化立體匹配演算法,由於運算過程中需要迭代求精,運算時間長,無法達到實時計算立體匹配的需求,然而實時性需求卻廣泛存在立體匹配的應用場景中。很多基於區域性匹配的演算法雖然運算時間短,但由於僅考慮匹配窗內的代價聚合,效果很差,視差圖只有很多稀疏的視差點,還要經過插值計算,顯然無法用於汽車導航,目標拾取等需要精確結果且對運算速度有一定要求的場景。
1區域性代價聚合
基於窗結構區域性立體匹配演算法,按照匹配約束來搜尋最佳的匹配點,在搜尋求取左右兩幅影象在視差d下一點的匹配代價時,實際是求得以該點為中心的匹配窗內所有點的代價的平均值(或者其他的度量方式)。如圖(4-1):
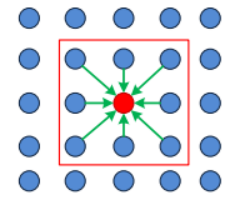
圖 4-1 區域性匹配演算法的代價傳遞
Figure 4-1 Cost delivery of local aggregation
我們把這一過程叫做代價聚類(Cost aggregation),這種基於區域的匹配方法利用區域性視窗之間的相似性度量來匹配對應基元的空間座標,對於連續性細節明顯的區域效果較好。顯然,此類方法對於匹配窗以外的點卻無法影響該點的代價值,使得代價聚類的值不具有全域性特性,也就喪失了匹配基元的全域性結構特性,因此在紋理特徵較低的區域非常容易產生誤匹配。
如何在代價聚類中獲取匹配基元的全域性特徵,進而使得區域性代價聚合方法克服上述缺點,本章相對於基於區域的區域性窗立體匹配方法,採用圖論中的最小生成樹方法,利用樹結構進行全域性代價聚合。
2 雙邊濾波與代價聚合
雙邊濾波(Bilateral filter)是一種可以保邊去噪的濾波器。簡單的說就是一種同時考慮了畫素空間差異與強度差異的濾波器,因此具有保持影象邊緣的特性。該濾波器可以由兩個濾波引數進行控制。一個控制幾何空間距離。另一個控制畫素差。
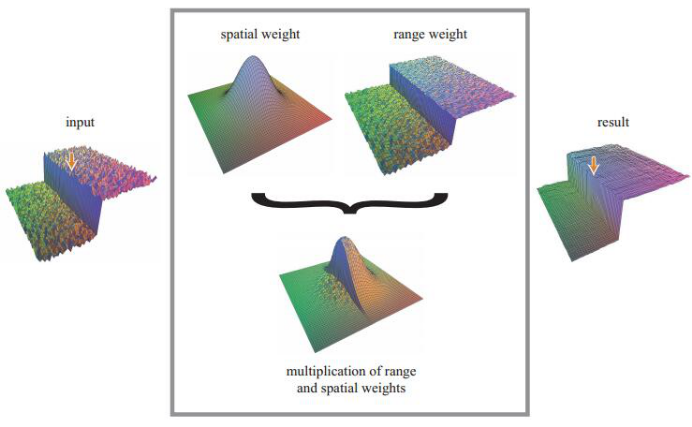
圖 4-2 雙邊濾波對空間和顏色權重的同時作用
Figure 4-2 bilateral filter weights of the central pixel
在傳統高斯濾波器中,權重只和畫素之間的空間距離有關係,無論影象的內容是什麼,都有相同的濾波效果。雙邊濾波器,在高斯濾波器的基礎上增加了畫素差值的權重資訊,公式(4-1)如下所示:
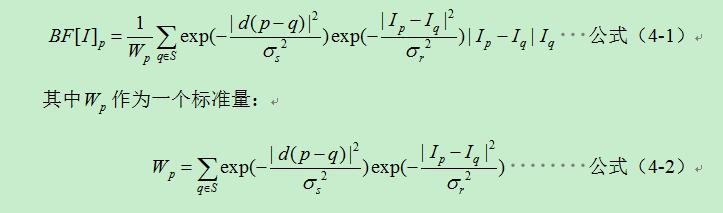
公式(4-1)是一個歸一加權平均,和分別衡量影象I的濾除量,前者控制距離資訊的權重,後者控制顏色資訊的權重。因此總體而言,在畫素強度變換不大的區域,雙邊濾波有類似於高斯濾波的效果,而在影象邊緣等強度梯度較大的地方,可以保持梯度。該特性在立體匹配問題中可以取代影象分割方法,或者作為影象分割方法的預處理手段,降低核心匹配演算法的計算量。
設為畫素p在視差層級d的匹配代價,為聚集代價。則雙邊濾波可以按照公式(4-1)與求取聚集代價進行融合中。
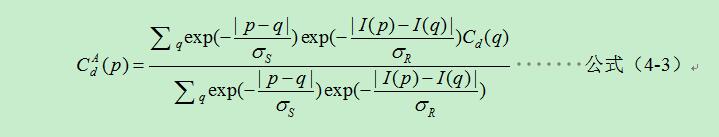
其中q作為支撐窗中的一個畫素。和與公式(4-1)的引數類似分別為調整空間相似性,和顏色(灰度)相似性的兩個引數。通常雙邊濾波函式計算中可以省去標準化的步驟,則公式(4-3)可以簡化為:
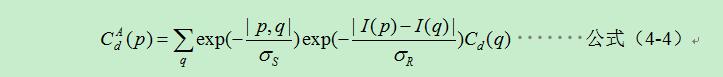
3 最小生成樹
最小生成樹也叫最小權重生成樹。在給定的無向圖中,(u,v)代表連線頂點u與頂點v的邊,w(u,v)代表此邊的權重,若存在T為E的子集且不存在環,使得w(T)最小,則T為G的最小生成樹。
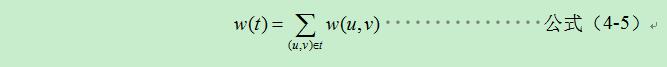
根據最小生成樹結構,當把影象看做是一個四聯通區域的圖時,影象兩點所形成邊的權值定義為這兩點灰度值的差值(或者顏色資訊等其他度量準則),這種定義下生成的最小生成樹結構正好符合為匹配窗新增全域性特性的期望。
4 基於最小生成樹的代價聚合
求兩幅待匹配影象在視差d下一點的代價值時,基於區域的匹配窗代價聚合方法對與匹配窗以外的點無法影響該點的代價值,著眼於代價聚類,為了使代價值具有全域性屬性,使影象內所有點都對該點傳遞一個支撐量,距離該點較遠的顏色差別很大的畫素點傳遞較小的支撐量,距離相近顏色差別不大的傳遞較大的支撐量。
根據最小生成樹結構我們知道,當把影象看做是一個四聯通區域的圖時,影象兩點所形成邊的權值我們可以定義為這兩點灰度值的差值,這種定義下生成的MST結構正好符合我們的期望,相當於在區域性演算法上加了全域性性質,並且沒有增加過多的運算量。
基於最小生成樹的代價聚類過程十分簡單,針對待匹配影象生成一顆最小生成樹後,其代價聚合方式主要有兩種:
1.自底向上聚合,即從葉子節點到頂點的遍歷。
2.自頂向下聚合,即從頂點到葉子節點的遍歷。
對於每一個節點的聚合代價,只需要對生成樹遍歷兩次就可以得到結果(如圖4- )。
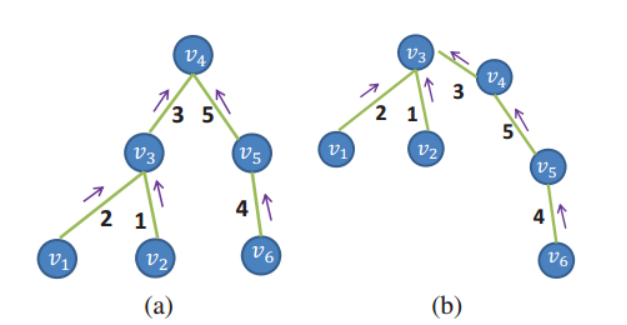
圖 4-3 兩種代價聚合方案
Firgure 4-3 Two cost aggregation schemes
設S(p,q)定義為兩點的相似度,D(p,q)定義為兩點的距離(MST兩點間的最小路徑),為聚類值。則有:
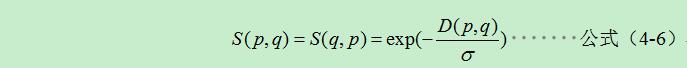
其中作為控制兩點之間相似度的引數。融合公式(4-4)雙邊濾波的結果後:
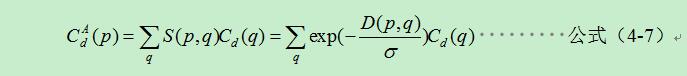
注意到公式(4-4)中存在兩個濾波控制引數,由於最小生成樹結構本身帶有距離度量,並且在樹中距離相近的畫素也越相似,所以公式(4-7)只使用一個引數控制相似度。
下面根據兩種聚合方式分別介紹如何計算聚合代價。
4.1 自底向上聚合(Leaf to Root)
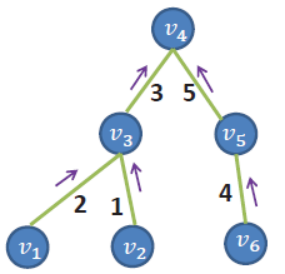
圖4-4 自底向上聚合
Figure 4-4 Leaf to Root aggregation
自底向上聚合即為Leaf to Root,是從葉子節點到根節點的代價聚合,以圖4-4為例,假設圖4-4是一個最小生成樹,邊上的數值代表權重,此時計算節點V4的代價聚合,那麼可以直接計運算元節點(V3, V4)的代價聚合值與各自邊緣的乘積集合,因為V4是根節點,不需要考慮父節點的影響。箭頭向上代表從葉子到當前節點的代價聚合值。則V4的聚合代價可以表示為公式(4-8):
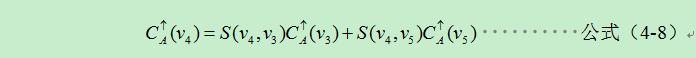
根據公式(4-8)可以推匯出計算自底向上聚合代價的方法,按照根節點的聚合代價為子節點聚合代價乘積的和來進行計算:
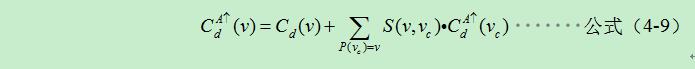
如果節點v是葉子節點,則
由於在計算過程中利用了最小生成樹的特性,自底向上的代價聚合過程中每一層的計算只需要計算其子節點的乘積,而子節點的代價聚合值已經包含了孫子節點及其子孫節點的影響。所以運算過程中極大的降低了運算量。
4.2 自頂向下聚合(Root to leaf)
對於圖4-4中的情況,V4沒有父親節點,屬於特殊情況,如果我們要計算V3的代價聚合值呢?顯然只考慮V1和V2是不夠的,還得考慮V4的影響。也就是從上到下的影響。如圖4-5所示:
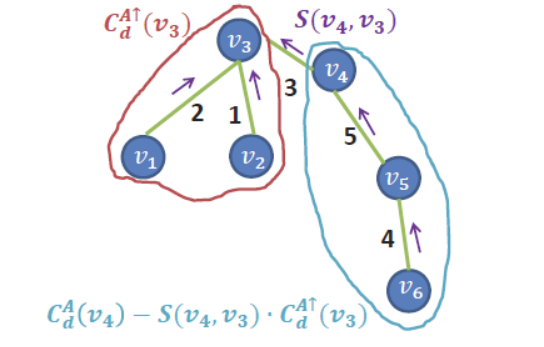
圖 4-5 自頂向下聚合
Figure 4-5 Root to leaf aggregation
此時我們完全可以假設V3為根節點,它的父節點向下轉換變為他的子節點,則可以利用同樣的辦法,將V4的代價聚合值乘以它的權重一起再加進來。但是因為V4的代價聚合值已經考慮到了V3的影響,所以必須事先將V4的代價聚合值減去V3的代價聚合值才可以。則V3的聚合代價值可以表示為:
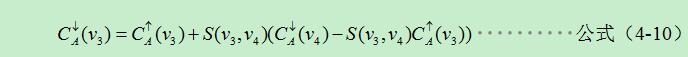
其中,自頂向下的代價聚合值就是最終的代價聚合值,要從上到下一層一層的計算代價,這樣同樣可以減少計算量。對於更為一般的情況,即當從根節點向葉子節點代價聚集時候,根據公式(4-10)可以推匯出其一般形式:
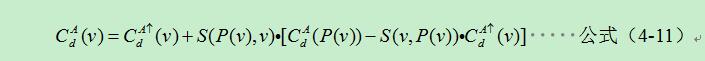
化簡得:
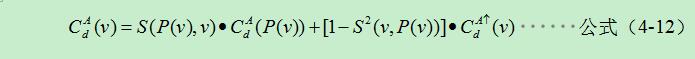
5 立體匹配的通用並行化處理
並行程式開發的程式設計模型主要分為兩類:1.訊息傳遞模型,2.共享儲存模型。本文主要採用共享儲存模型在彩色影象的各個通道上採取粗粒度的並行劃分,在彩色影象上進行並行化處理,各個通道內部針對濾波演算法,最小生成樹的建立等演算法,進行基於處理器指令向量化的SIMD擴充套件。
其主要流程如下流程圖所示:
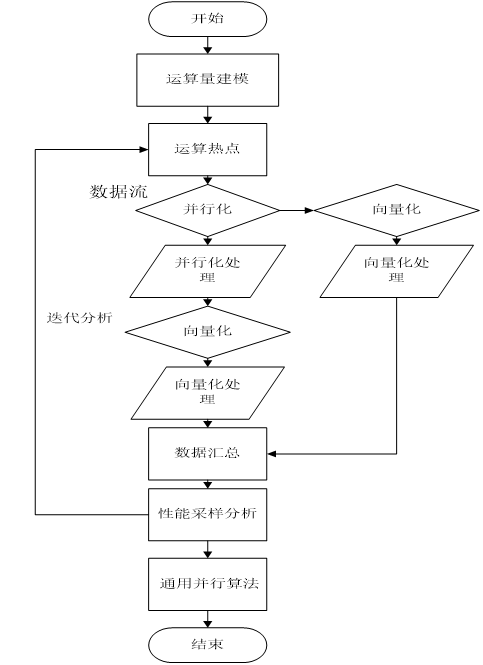
圖4- 並行化立體匹配流程
Figure 4-
首先針對基於最小生成樹的全域性立體匹配演算法,的整個演算法流程進行計算量分析建模,分析並提取其中的密集計算任務,參照[32]進行雙邊濾波的優化
5.1 OpenMP 執行緒並行化
OpenMP實際上是對共享記憶體並行系統,提供了一套指導性的編譯註釋方案。現在的常用的品牌基於x86架構的Intel AMD桌面處理器,基於ARM架構的處理器對OpenMP都有很好的支援。作為主流的共享記憶體模型,得到了幾乎所有商業編譯器的支援,具有很好的可移植性。
主要是,加上openmp程式碼編譯選項後,程式碼可移植了。
5.2 通用處理器指令優化(SIMD向量化計算)
幾乎所有的處理器廠商都為自己的處理器產品製作了多媒體擴充套件部件。圖形處理器的平行計算需要額外的硬體投入,而且與記憶體交換資料需要耗費時間。多媒體擴充套件部件一般在處理器中以向量部件的形式出現,相應的指令集以(Single Instruction Multi Data)單指令多資料流作為出現.
SIMD在效能上的優勢:編輯以加法指令為例,單指令單資料(SISD)的CPU對加法指令譯碼後,執行部件先訪問記憶體,取得第一個運算元;之後再一次訪問記憶體,取得第二個運算元;隨後才能進行求和運算。而在SIMD型的CPU中,指令譯碼後幾個執行部件同時訪問記憶體,一次性獲得所有運算元進行運算。這個特點使SIMD特別適合於多媒體應用等資料密集型運算。
SIMD適量指令能夠加速如C和Java語言的處理。向量指令對過個數據元素進行並行操作,從而使主機能夠快速處理大量資料。這對於社交媒體和大資料工作負載來說是個福音,但對面臨普通負載的系統程式設計師來說似乎沒有太大的幫助。
SIMD指令通過多種方式增加吞吐量。大多數機器指令會的結果會覆蓋輸入運算元其中之一不同,大部分SIMD指令集會使用兩個輸入暫存器,並將結果儲存在第三個暫存器。這意味著程式設計師可以節省與暫存器糾結的時間。
向量暫存器為128位元組長度。前16個暫存器實際上與64位浮點暫存器(FPRs)共存。改變一個FPR同樣會破壞對應向量暫存器的所有位元組。存在一些關於通過程式呼叫保護向量暫存器的特殊規則,IBM的Assembler Services Guide有詳細說明。
SIMD向量指令包括所有數學函式和浮點模式。同樣也有字串操作以及用於獲取和儲存資料的方法。
參考文獻
[11]Yang Q. A non-local cost aggregation method for stereo matching[C]// Proceedings / CVPR, IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE Computer Society Conference on Computer Vision and Pattern Recognition. 2012:1402-1409.
[12]Yang Q, Ji P, Li D, et al. Fast stereo matching using adaptive guided filtering[J]. Image and Vision Computing, 2014, 32(3): 202-211.
[13]Yang Q. Hardware-efficient bilateral filtering for stereo matching[J]. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2014, 36(5): 1026-1032.
[14]Yang Q. Stereo Matching Using Tree Filtering[J]. Pattern Analysis & Machine Intelligence IEEE Transactions on, 2015, 37(4):834-846.
論文資源合集
相關推薦
基於最小生成樹的實時立體匹配演算法簡介
圖割,置信傳播等全域性優化立體匹配演算法,由於運算過程中需要迭代求精,運算時間長,無法達到實時計算立體匹配的需求,然而實時性需求卻廣泛存在立體匹配的應用場景中。很多基於區域性匹配的演算法雖然運算時間短,但由於僅考慮匹配窗內的代價聚合,效果很差,視差圖只有很多
最小生成樹-----普里姆演算法---java版
最小生成樹(自己理解的,不當之處希望有人可以指出) 簡單的說一下最小生成樹: 假設一個圖,它有n個頂點,則只需n-1條邊,就可以將其組成一個連通圖,在各種組合中,所有n-1條邊的權重之和最小的連通圖,就是所謂的最小生成樹. 演算法思想(自己揣摩的,不當之處希
圖->連通性->最小生成樹(普里姆演算法)
文字描述 用連通網來表示n個城市及n個城市間可能設定的通訊線路,其中網的頂點表示城市,邊表示兩城市之間的線路,賦於邊的權值表示相應的代價。對於n個定點的連通網可以建立許多不同的生成樹,每一棵生成樹都可以是一個通訊網。現在,我們要選擇這樣一個生成樹,使總的耗費最少。這個問題就是構造連通網的最小代價生成樹(
圖->連通性->最小生成樹(克魯斯卡爾演算法) 最小生成樹(普里姆演算法)
文字描述 上一篇部落格介紹了最小生成樹(普里姆演算法),知道了普里姆演算法求最小生成樹的時間複雜度為n^2, 就是說複雜度與頂點數無關,而與弧的數量沒有關係; 而用克魯斯卡爾(Kruskal)演算法求最小生成樹則恰恰相反。它的時間複雜度為eloge (e為網中邊的數目),因此它相對於普里姆演算法而
最小生成樹(Dijkstra)演算法和最短路(Prim)演算法的異同
Prim演算法用於構建最小生成樹——即樹中所有路徑之和最小,但不能保證任意兩點之間是最短路徑。例如,構建電路板,使所有邊的和花費最少。只能用於無向圖。Dijkstra演算法用於構建(MST)——即樹中指
【硬核遊戲攻略】1. 最小生成樹的兩種演算法及《我的世界》中迷宮的一鍵生成函式
這個系列的第一篇,雖然起名叫硬核攻略… 但我想開篇還是寫點簡單的,諸如Prim,Kruskal之類的MST生成演算法已經爛大街了,這裡重新實現一遍Prim,然後基於生成的迷宮自動建立一系列對應的mcfunction,用於在遊戲中一鍵呼叫.這個系列不出意外的
最小生成樹的3個演算法
最小生成樹——Prim、Kruskal、Sollin(Boruvka) 本文內容框架: 1.Prim演算法及其基於優先佇列實現 2.Kruskal演算法 3.Sollin演算法 對於最小生成樹,有兩種演算法可以解決。一種是Prim演算法
[Sicily 1090 Highways] 求最小生成樹的兩種演算法(普里姆演算法/克魯斯卡爾演算法)
(1)問題描述: 政府建公路把所有城市聯絡起來,使得公路最長的邊最短,輸出這個最長的邊。 (2)基本思路: 使得公路最長的邊最短其實就是要求最小生成樹。 (3)程式碼實現: 普里姆演算法: #
資料結構圖之二(最小生成樹--普里姆演算法)
1 #include <iostream> 2 #include "SeqList.h" 3 #include <iomanip> 4 using namespace std; 5 6 #define INFINITY 65535 7 8 t
最小生成樹,普里姆演算法(Python實現)
December 16, 2015 12:01 PM 1.相關概念 1)生成樹 一個連通圖的生成樹是它的極小連通子圖,在n個頂點的情形下,有n-1條邊。生成樹是對連通圖而言的,是連同圖的極小連通子圖,包含圖中的所有頂點,有且僅有n-1條邊。非連通圖的生成
最小生成樹的兩種演算法:Prim和Kruskal演算法
越來越明白了一個道理:你寫不出程式碼的原因只有一個,那就是你沒有徹底理解這個演算法的思想!! 以前寫過最小生成樹,但是,水了幾道題後,過了一段時間,就會忘卻,一點也寫不出來了。也許原因只有一個,那就是我沒有徹底理解這兩種演算法。 主題: 其實,求最小生成樹有兩個要點,一個是
最小生成樹Prim和Kruskal演算法
採用鄰接矩陣的儲存結構構建無向網,然後用Prim和Kruskal演算法求出最小生成樹。 總程式碼: #include <stdio.h> #include <stdlib.h> #define VRType int//在這裡是權值型別 #define
最小生成樹的兩個演算法之二:kruskal演算法
基本概念 樹(Tree):如果一個無向連通圖中不存在迴路,則這種圖稱為樹。生成樹 (Spanning Tree):無向連通圖G的一個子圖如果是一顆包含G的所有頂點的樹,則該子圖稱為G的生成樹。 生成樹是連通圖的極小連通子圖。這裡所謂極小是指:若在樹中任意增加一條邊,則將
最小生成樹---普里姆演算法(Prim演算法)和克魯斯卡爾演算法(Kruskal演算法)
**最小生成樹的性質:MST性質(假設N=(V,{E})是一個連通網,U是頂點集V的一個非空子集,如果(u,v)是一條具有最小權值的邊,其中u屬於U,v屬於V-U,則必定存在一顆包含邊(u,v)的最小生成樹)** # 普里姆演算法(Pri
基於矩陣實現的最小生成樹演算法
1.最小生成樹 在Wikipedia中最小生成樹(Minimum Spanning Tree)的定義如下:A minimum spanning tree is a spanning tree of a connected, undirected graph. It conn
基於並查集+Kruskal演算法的matlab程式及最小生成樹繪圖
學了一天最小生成樹,稍稍總結一下,這是第一篇 kruskal演算法 關於kruskal演算法已有大量的資料,不再贅述,演算法流程為: 得到鄰接矩陣和權值; 初始化,連線距離最小的兩點; 連線距離次小的兩點,如果形成迴路則取消連線;重複上述連線步驟,直到所
Ex 5_22 在此我們基於以下性質給出一個新的最小生成樹算法..._第九次作業
遍歷算法 刪除 其中 ima 運行時間 判斷 技術分享 不包含 證明 (a)設環的頂點集為V, e(u,v)為權最重的邊,若把V分成兩部分V1,V2。其中V1包含u,V2包含v,因為V是一個環,因此,至少存在兩條把u和v連接起來的邊。因此,除了e之外,至少還存在另一條邊
POJ 2485 - Highways(求最小生成樹的最大權值-Kruskal演算法)
題目 Language:Default Highways Time Limit: 1000MS
問題 1705: 演算法7-9:最小生成樹
http://www.dotcpp.com/oj/problem1705.html 題目描述 最小生成樹問題是實際生產生活中十分重要的一類問題。假設需要在n個城市之間建立通訊聯絡網,則連通n個城市只需要n-1條線路。這時,自然需要考慮這樣一個問題,即如何在最節省經費的前提下建立這個通訊網
luogu P3366 【模板】最小生成樹(克魯斯卡爾演算法)
題目描述 如題,給出一個無向圖,求出最小生成樹,如果該圖不連通,則輸出orz 輸入輸出格式 輸入格式: 第一行包含兩個整數N、M,表示該圖共有N個結點和M條無向邊。(N<=5000,M<=200000) 接下來M行每行包含三個整數Xi、Yi、Zi,表示有一條長度為Zi的無向邊連線結點Xi