
Oracle-記憶體管理解讀
概述
關於記憶體的配置,是最影響 Oracle效能的配置。記憶體還直接影響到其他兩個重要資源的消耗: CPU 和 IO.
那Oracle 記憶體儲存的主要內容是什麼呢?
- 程式程式碼( PLSQL、 Java);
- 關於已經連線的會話的資訊,包括當前所有活動和非活動會話;
- 程式執行時必須的相關資訊,例如查詢計劃;
- Oracle 程序之間共享的資訊和相互交流的資訊,例如鎖;
- 那些被永久儲存在外圍儲存介質上,被 cache 在記憶體中的資料( 如 redo log 條目,資料塊)。
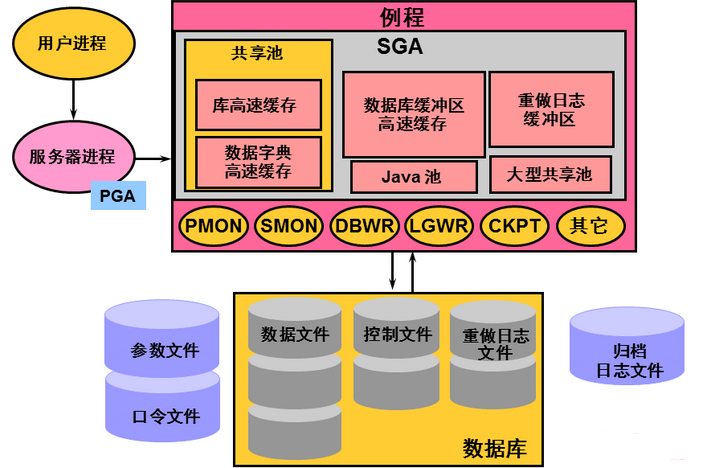
每個 Oracle 資料庫都是由 Oracle Instance(例項)與資料庫(資料檔案,控制檔案、重做日誌檔案)組成,其中所謂例項就是使用者同資料庫互動的媒介,使用者通過於一個例項相連來操作資料庫。
而例項又是由統一的記憶體結構( SGA,PGA, UGA)和一批記憶體駐留程序組成。
例項在作業系統中用 ORACLE_SID 來標識,在 Oracle 中用引數 INSTANCE_NAME 來標識, 它們兩個的值是相同的。
資料庫啟動時,系統首先在伺服器記憶體中分配系統全域性區( SGA), 構成了 Oracle的記憶體結構,然後啟動若干個常駐記憶體的作業系統程序,即組成了 Oracle 的 程序結構,記憶體區域和後臺程序合稱為一個 Oracle 例項。
SGA (System Gloable Area)
架構圖
SGA概述
SGA 是一組為系統分配的共享的記憶體結構,可以包含一個數據庫例項的資料或控制資訊。
如果多個使用者連線到同一個資料庫例項,在例項的 SGA 中,資料可以被多個使用者共享。
當資料庫例項啟動時, SGA 的記憶體被自動分配;當資料庫例項關閉時, SGA 記憶體被回收。
SGA 是佔用記憶體最大的一個區域,同時也是影響資料庫效能的重要因素。
SGA 區是可讀寫的。所有登入到例項的使用者都能讀取 SGA 中的資訊,而在oracle 做執行操作時,服務程序會將修改的資訊寫入 SGA 區。
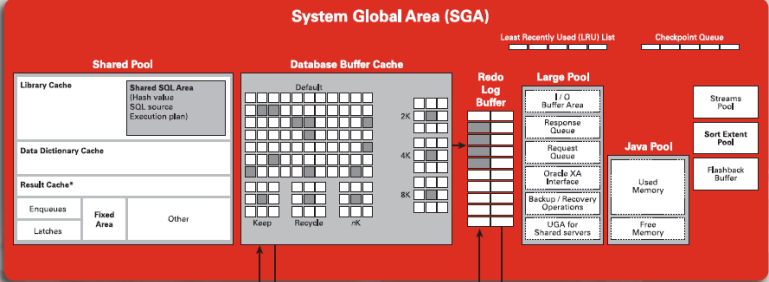
SGA 主要包括了以下的資料結構:
- 資料緩衝( Buffer Cache)
- 重做日誌緩衝( Redo Log Buffer)
- 共享池( Shared Pool)
- Java 池( Java Pool)
- 大池( Large Pool)
- 流池( Streams Pool — 10g 以後才有)
- 資料字典快取( Data Dictionary Cache)
- 其他資訊(如資料庫和例項的狀態資訊)
SGA 中的資料字典快取 和其他資訊 會被例項的後臺程序所訪問,它們在例項啟動後就固定在 SGA 中了,而且不會改變,所以這部分又稱為固定 SGA( Fixed SGA)。這部分割槽域的大小一般小於 100K。
Shared Pool、 Java Pool、 Large Pool 和 Streams Pool 這幾塊記憶體區的大小是相應系統引數設定而改變的,所以有通稱為可變 SGA( Variable SGA)。
SGA資訊及含義
使用有DBA許可權的使用者
SQL> show parameter sga
NAME TYPE VALUE
------------------- ----------- --------------------------
lock_sga boolean FALSE
pre_page_sga boolean FALSE
sga_max_size big integer 6256M
sga_target big integer 0或者查詢v$parameter
select a.name ,a.VALUE ,a.ISMODIFIED ,a.DESCRIPTION from v$parameter a where a.NAME like '%sga%';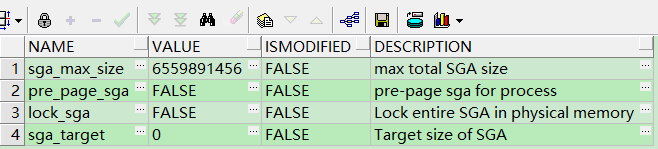
如果 ISSYS_MODIFIABLE 返回的是 false,說明該引數無法用 alter system語句動態修改,需要重啟資料庫。
所以 sga_max_size 是不可以動態調整的。但是我們可以對sga_target 進行動態的調整。
SGA_MAX_SIZE
如果發現 SGA 各個記憶體總和大於 SGA_MAX_SIZE,它會將SGA_MAX_SIZE 的值修改為 SGA 各個記憶體區總和的值。
SGA 所分配的是虛擬記憶體,但是,在我們配置 SGA 時,一定要使整個 SGA 區都在實體記憶體中,否則,會導致 SGA 頻繁的頁入/頁出,會極大影響系統性能。
對於 OLTP 系統, 一般的建議是將 SGA_MAX_SIZE 設為實體記憶體的 60%,PGA 設為 20%.
下面給出一些參考值:

PRE_PAGE_SGA
這個引數的預設值為FALSE,即不將全部SGA置入實體記憶體中。當設定為TRUE時,例項啟動會將全部SGA置入實體記憶體中。
它可以使例項啟動達到它的最大效能狀態,但是,啟動時間也會更長(因為為了使所有SGA都置入實體記憶體中,oracle程序需要touch所有的SGA頁)。
SQL> alter system set pre_page_sga=true scope=spfile;LOCK_SGA
為了保證SGA都被鎖定在實體記憶體中,而不必頁入/頁出,可以通過引數LOCK_SGA來控制。
這個引數預設值為FALSE,當指定為TRUE時,可以將全部SGA都鎖定在實體記憶體中。
當然,有些系統不支援記憶體鎖定,這個引數也就無效了。
SGA_TARGET
Oracle10g中引入的一個非常重要的引數。
在10g之前,SGA的各個記憶體區的大小都需要通過各自的引數指定,並且都無法超過引數指定大小的值,儘管他們之和可能並沒有達到SGA的最大限制。此外,一旦分配後,各個區的記憶體只能給本區使用,相互之間是不能共享的。拿SGA中兩個最重要的記憶體區Buffer Cache和Shared Pool來說,它們兩個對例項的效能影響最大,但是就有這樣的矛盾存在:在記憶體資源有限的情況下,某些時候資料被cache的需求非常大,為了提高buffer hit,就需要增加Buffer Cache,但由於SGA有限,只能從其他區“搶”過來——如縮小Shared Pool,增加Buffer Cache;而有時又有大塊的PLSQL程式碼被解析駐入記憶體中,導致Shared Pool不足,甚至出現4031錯誤,又需要擴大Shared Pool,這時可能又需要人為干預,從Buffer Cache中將記憶體奪回來。
10g 以後有了新特性:自動共享記憶體管理(Automatic Shared Memory Management ASMM)。
而控制這一特性的,也就僅僅是這一個引數SGA_TARGE。
設定這個引數後,就不需要為每個記憶體區來指定大小了。SGA_TARGET指定了SGA可以使用的最大記憶體大小,而SGA中各個記憶體的大小由Oracle自行控制,不需要人為指定。Oracle可以隨時調節各個區域的大小,使之達到系統性能最佳狀態的個最合理大小,並且控制他們之和在SGA_TARGET指定的值之內。
一旦給SGA_TARGET指定值後(預設為0,即沒有啟動ASMM),就自動啟動了ASMM特性。如果不設定SGA_TARGET,則自動共享記憶體管理功能被禁止。
設定了SGA_TARGET後,以下的SGA記憶體區就可以由ASMM來自動調整:
- 共享池(Shared Pool)
- Java池(Java Pool)
- 大池(Large Pool)
- 資料快取區(Buffer Cache)
- 流池(Streams Pool)
對於SGA_TARGET的限制,它的大小是不能超過SGA_MAX_SIZE的大小的。
要注意的是:當指定SGA_TARGET小於SGA_MAX_SIZE,例項重啟後,SGA_MAX_SIZE就自動變為和SGA_TARGET一樣的值了。
在10g中,修改SGA_MAX_SIZE的值還是需要重啟的.
SGA_TARGET帶來一個重要的好處就是,能使SGA的利用率達到最佳,從而節省記憶體成本。因為ASMM啟動後,Oracle會自動根據需要調整各個區域的大小,大大減少了某些區域記憶體緊張,而某些區域又有記憶體空閒的矛盾情況出現。這也同時大大降低了出現4031錯誤的機率。
SGA組成
Database Buffer Cache
Buffer Cache是SGA區中專門用於存放從資料檔案中讀取的的資料塊拷貝的區域。Oracle程序如果發現需要訪問的資料塊已經在buffer cache中,就直接讀寫記憶體中的相應區域,而無需讀取資料檔案,從而大大提高效能.
Buffer cache對於所有oracle程序都是共享的,即能被所有oracle程序訪問。
和Shared Pool一樣,buffer cache被分為多個集合,這樣能夠大大降低多CPU系統中的爭用問題。
Buffer cache的管理
Oracle對於buffer cache的管理,是通過兩個重要的連結串列實現的:寫連結串列和最近最少使用連結串列(the Least Recently Used LRU).
寫連結串列所指向的是所有髒資料塊快取(即被程序修改過,但還沒有被回寫到資料檔案中去的資料塊,此時緩衝中的資料和資料檔案中的資料不一致)。
LRU連結串列指向的是所有空閒的快取、pin住的快取以及還沒有來的及移入寫連結串列的髒快取。空閒快取中沒有任何有用的資料,隨時可以使用。而pin住的快取是當前正在被訪問的快取。LRU連結串列的兩端就分別叫做最近使用端(the Most Recently Used MRU)和最近最少使用端(LRU)。
Buffer cache的資料塊訪問
當一個 Oracle 程序訪問一個快取時,這個程序會將這塊快取移到 LRU 連結串列中的 MRU。而當越來越多的緩衝塊被移到 MRU 端,那些已經過時的髒緩衝(即資料改動已經被寫入資料檔案中,此時緩衝中的資料和資料檔案中的資料已經一致)則被移到 LRU 連結串列中 LRU 端。
當一個 Oracle 使用者程序第一次訪問一個數據塊時,它會先查詢 buffer cache中是否存在這個資料塊的拷貝。如果發現這個資料塊已經存在於 buffer cache(即命中 cache hit),它就直接讀從記憶體中取該資料塊。如果在 buffer cache 中沒有發現該資料塊(即未命中 cache miss),它就需要先從資料檔案中讀取該資料塊到buffer cache 中,然後才訪問該資料塊。
命中次數與程序讀取次數之比就是我們一個衡量資料庫效能的重要指標:buffer hit ratio(buffer命中率),可以通過以下語句獲得自例項啟動至今的buffer命中率.
SQL> select (1-(sum(decode(name, 'physical reads',value,0))/(sum(decode(name, 'db block gets',value,0))
2 +sum(decode(name,'consistent gets',value,0))))) * 100 "Hit Ratio" from v$sysstat;
Hit Ratio
----------
99.6854209一個良好效能的系統,命中率一般保持在95%左右。
Share Pool
SGA中的共享池由庫快取(Library Cache)、字典快取(Dictionary Cache)、用於並行執行訊息的緩衝以及控制結構組成。
Shared Pool的大小由引數SHARED_POOL_SIZE決定。10g 以後可以通過SGA_TARGET 引數來自動調整。
對於Shared Pool的記憶體管理,是通過修正過的LRU演算法表來實現的。
庫快取(Library Cache)
Library Cache中包括共享SQL區(Shared SQL Areas)、PL/SQL儲存過程以及控制結構(如鎖、庫快取控制代碼)。
任何使用者都可以訪問共享SQL區(可以通過v$sqlarea訪問)。因此庫快取存在於SGA的共享池中。
共享SQL區和私有SQL區
Oracle會為每一條SQL語句執行(每執行一條語句Oracle都會開啟一個遊標)提供一個共享SQL區(Shared SQL Areas)和私有SQL區(Private SQL Areas屬於PGA)。當發現兩個(或多個)使用者都在運行同一SQL語句時,Oracle會重新組織SQL區,使這些使用者能重用共享SQL區。但他們還會在私有SQL區中儲存一份這條SQL語句的拷貝。
一個共享SQL區中儲存了一條語句的解析樹和查詢計劃
從解析語句到分配共享SQL區是一個比較消耗CPU的工程。這就是為什麼我們提倡使用繫結變數的原因了。在沒有使用繫結變數時,語句中的變數的數值不同,oracle就視為一條新的語句(9i後可以通過cursor_sharing來控制),重複上面的解析、記憶體分配的動作,將大大消耗系統資源,降低系統性能。
PL/SQL程式單元
Oracle對於PL/SQL程式單元(儲存過程、函式、包、匿名PL/SQL塊和觸發器)的處理過程與SQL的處理方式類似。它會分配一個共享區來儲存被解析、編譯過的程式單元。
字典快取(Dictionary Cache)
資料字典是有關於資料庫的參考資訊、資料庫的結構資訊和資料庫中的使用者資訊的一組表和檢視的集合,如我們常用到的V$檢視、DBA_檢視都屬於資料字典。
共享池的記憶體管理
當一條SQL語句被提交給Oracle執行,Oracle會自動執行以下的記憶體分配步驟:
1.Oracle檢查共享池,看是否已經存在關於這條語句的共享SQL區。如果存在,這個共享SQL區就被用於執行這條語句。而如果不存在,Oracle就從共享池中分配一塊新的共享SQL區給這條語句。同時,無論共享SQL區存在與否,Oracle都會為使用者分配一塊私有SQL區以儲存這條語句相關資訊(如變數值)。
2. Oracle為會話分配一個私有SQL區。私有SQL區的所在與會話的連線方式相關。
在以下情況下,Oracle也會將共享SQL區從共享池中釋放出來:
當使用ANALYZE語句更新或刪除表、簇或索引的統計資訊時,所有與被分析物件相關的共享SQL區都被從共享池中釋放掉。當下一次被釋放掉的語句被執行時,又重新在一個新的共享SQL區中根據被更新過的統計資訊重新解析。
當物件結構被修改過後,與該物件相關的所有共SQL區都被標識為無效(invalid)。在下一次執行語句時再重新解析語句。
如果資料庫的全域性資料庫名(Global Database Name)被修改了,共享池中的所有資訊都會被清空掉。
DBA通過手工方式清空共享池:ALTER SYSTEM FLUSH SHARED_POOL;
保留共享池
通過檢視V$SHARED_POOL_RESERVED可以查到保留池的統計資訊。其中欄位REQUEST_MISSES記錄了沒有立即從空閒列表中得到可用的大記憶體段請求次數。這個值要為0。
因為保留區必須要有足夠個空閒記憶體來適應那些短期的記憶體請求,而無需將那些需要長期cache住的沒被pin住的可重建的段清除。否則就需要考慮增大SHARED_POOL_RESERVED_SIZE了。
Shared Pool的重要引數
$sgastatSHARED_POOL_SIZE
SHARED_POOL_RESERVED_SIZE:指定了共享池中快取大記憶體物件的保留區的大小
_SHARED_POOL_RESERVED_MIN_ALLOC:設定了進入保留區的物件大小的閥值。
Redo Log Buffer重做日誌快取
Redo Log Buffer是SGA中一段儲存資料庫修改資訊的快取。
.重做條目中包含了由於INSERT、UPDATE、DELETE、CREATE、ALTER或DROP所做的修改操作而需要對資料庫重新組織或重做的必須資訊。在必要時,重做條目還可以用於資料庫恢復。
引數LOG_BUFFER決定了Redo Log Buffer的大小。它的預設值是512K(一般這個大小都是足夠的),最大可以到4G。10g中可通過引數自動設定。當系統中存在很多的大事務或者事務數量非常多時,可能會導致日誌檔案IO增加,降低效能。這時就可以考慮增加LOG_BUFFER。
但是,Redo Log Buffer的實際大小並不是LOB_BUFFER的設定大小。為了保護Redo Log Buffer,oracle為它增加了保護頁(一般為11K)
SQL> show parameter log_buffer
NAME TYPE VALUE
------------------------------------ ----------- ------------
log_buffer integer 18317312
SQL> select * from v$sgastat where name = 'log_buffer';
POOL NAME BYTES
------------ -------------------------- ----------
log_buffer 18993152大池(large pool)
大池是屬於SGA的可變區(Variable Area)的,它不屬於共享池。
大池中只有兩種記憶體段:空閒(free)和可空閒(freeable)記憶體段
large pool是沒有LRU連結串列的。
Java池(Java Pool)
Java池也是SGA中的一塊可選記憶體區,它也屬於SGA中的可變區。
Java池的記憶體是用於儲存所有會話中特定Java程式碼和JVM中資料。Java池的使用方式依賴與Oracle服務的執行模式。
Java池的大小由引數JAVA_POOL_SIZE設定。Java Pool最大可到1G。
在Oracle 10g以後,提供了一個新的建議器——Java池建議器——來輔助DBA調整Java池大小。建議器的統計資料可以通過檢視V$JAVA_POOL_ADVICE來查詢
流池(Streams Pool)
流池是Oracle 10g中新增加的。是為了增加對流的支援。
流池也是可選記憶體區,屬於SGA中的可變區。它的大小可以通過引數STREAMS_POOL_SIZE來指定。
如果沒有被指定,oracle會在第一次使用流時自動建立。如果設定了SGA_TARGET引數,Oracle會從SGA中分配記憶體給流池;
如果沒有指定SGA_TARGET,則從buffer cache中轉換一部分記憶體過來給流池。轉換的大小是共享池大小的10%。
Oracle同樣為流池提供了一個建議器——流池建議器。建議器的統計資料可以通過檢視V$STREAMS_POOL_ADVICE查詢。
PGA(Program Global Area)
PGA由兩組區域組成:固定PGA和可變PGA
它的記憶體段可以通過檢視X$KSMPP(另外一個檢視X$KSMSP可以查到可變SGA的記憶體段資訊,他們的結構相同)查到。
PGA堆包含用於存放X$表的的記憶體(依賴與引數設定,包括DB_FILES、CONTROL_FILES)。
總的來說,PGA的可變區中主要分為以下三部分內容:
- 1)私有SQL區;
- 2)遊標和SQL區
- 3)會話記憶體
UGA ( The User Global Area)
UGA(User Global Area使用者全域性區)由使用者會話資料、遊標狀態和索引區組成。
PGA是服務於程序的,它包含的是程序的資訊;而UGA是服務於會話的,它包含的是會話的資訊
CGA ( The Call Global Area)
與其他的全域性區不同,CGA(Call Global Area呼叫全域性區)的存在是瞬間的。它只存在於一個呼叫過程中。對於例項的一些低層次的呼叫需要CGA,包括:
1)解析一條SQL語句;
2)執行一條SQL語句;
3)取一條SELECT語句的輸出值。
Java呼叫記憶體也分配在CGA中。它被分為三部分空間:堆空間、新空間和老空間。
軟體程式碼區(Software Code Area)
軟體程式碼區是一部分用於存放那些正在執行和可以被執行的程式碼(Oracle自身的程式碼)的記憶體區。Oracle程式碼一般儲存在一個不同於使用者程式儲存區的軟體程式碼區,而使用者程式儲存區是排他的、受保護的區域。
相關推薦
Oracle-記憶體管理解讀
概述 關於記憶體的配置,是最影響 Oracle效能的配置。記憶體還直接影響到其他兩個重要資源的消耗: CPU 和 IO. 那Oracle 記憶體儲存的主要內容是什麼呢? 程式程式碼( PLSQL、 Java); 關於已經連線的會話的資訊,包括當前所有
Oracle記憶體管理方式由amm切換為asmm
(一)ASMM和AMM 在Oracle 10g時,Orale推出ASMM(Automatic Shared Memory Managed),實現了SGA和PGA各自內部的自調節。在Oracle 11g,又推出了AMM(Automatic Memory managed),實現了SGA和PGA的統籌管理。在
Oracle 自動共享記憶體管理(ASMM)與自動記憶體管理(AMM)
相關引數: MEMORY_MAX_TARGET:不可動態調整,代表記憶體(SGA+PGA)的最大值。 SQL>ALTER SYSTEM SET MEMORY_MAX_TARGET = 1000M SCOPE=SPFILE MEMORY_TARGET可被動
Oracle 11G啟動自動記憶體管理AMM
前言:下面主要介紹了11G的AMM特性,實現了對SGA,PGA,以及SGA下面的記憶體如share_pool的自動管理,因為10G的ASMM特性需要手動對SGA,PGA管理,所以11G引出來了AMM管理。 在一個oracle server可以分為兩部分,一部分是data
Oracle 記憶體一 手動記憶體管理,自動記憶體管理
oracle的記憶體分為兩個部分。一個是SGA(system global area),一個是PGA(program global area)。所謂的記憶體管理,就是對這兩部分割槽域進行管理。oracle的記憶體管理經理了如下發展: oracle 9i PGA自動管理,
oracle 自動記憶體管理
oracle記憶體結構一般指的是SGA和PGA(當然還有UGA)。自動記憶體管理是指自動管理SGA和PGA 一、自動PGA記憶體管理 使用自動PGA記憶體管理,這種方法就不需要設定PGA內部其他記憶體大小,比如 SOR_AREA_SIZE ,B
Linux 核心解讀之記憶體管理----memory.c
轉載請註明原文出處http://blog.csdn.net/lizhiliang06/article/details/8655115 80x86體系結構中,Linux核心的記憶體管理程式使用分頁管理方式。利用頁目錄和頁表結構處理核心中其他部分程式碼對記憶體申請和釋放操作。M
vxWorks核心解讀五--記憶體管理
本篇博文,我們該談到Wind核心的記憶體管理模組了,嵌入式作業系統中, 記憶體的管理及分配佔據著極為重要的位置, 因為在嵌入式系統中, 儲存容量極為有限, 而且還受到體積、成本的限制, 更重要的是其對系統的效能、可靠性的要求極高, 所以深入剖析嵌入式作業系統的記憶體管理, 對其進行優化及有效管理, 具有十分
oracle 10g:自動共享記憶體管理
是不是很難準確地分配不同的池所需的記憶體數?自動共享記憶體管理特性使得自動將記憶體分配到最需要的地方去成為可能。 無論您是一個剛入門的 DBA 還是一個經驗豐富的 DBA,您肯定至少看到過一次類似以下的錯誤: ORA-04031:unable to allocate 2216 bytes of
dataguard oracle 歸檔管理腳本
dataguard 歸檔管理管理部分如果沒有啟用database force logging,則備庫對/*+ append */操作,nologging操作,會報壞塊;建議表空間force logging或者database force logging;--force logging /nologging 測
oracle asm管理
oracle asm oracle asm管理1、asm優點概念:auto storage managedb+instance<=====> raw裸設備性能比較:raw > asm > filesystem管理方便性 filesystem
Oracle配置管理
Oracle配置管理Oracle客戶端與服務器端的通信機制Oracle產品安裝完成後,服務器和客戶端都需要進行網絡配置才能實現網絡連接,服務器端配置監聽器,客戶端配置網絡服務名。 oracle net協議Oracle通過oracle net協議實現客戶端與服務器端的連接及數據傳遞。Oracle net是同時駐
Oracle 11g 管理控制文件
存儲 mark 數據字典 重新 恢復 日誌 覆蓋 發生 復制 oracle數據庫控制文件是非常重要的文件,它是數據庫創建的時候自動生成的二進制文件,其中記錄了數據庫的狀態信息,主要包括以下內容 ? 數據庫的名稱,一個控制文件只能屬於一個數據庫 ? 數據庫創建時間 ?
Oracle 11g 管理重做日誌文件
自動 新的 以及 產生 防止 當前 數據文件 ESS 數據 重做日誌也稱聯機重做日誌。引入重做日誌的目的是數據恢復。在數據庫運行過程中,用戶更改的數據會暫時存放在數據庫的高速緩沖區中。為了提高寫數據的速度,並不是一旦有數據變化,就把變化的數據寫到數據文件中。頻繁的讀寫磁盤文
第四節:FreeRTOS 記憶體管理
目錄 記憶體管理的介紹 記憶體碎片 Heap_1-5記憶體分配的區別 Heap_1:適用於一旦建立好記憶體,就不刪除的任務。 (本質是分配的大陣列做記憶體堆.) Heap_2:適用於重複分配和刪除具有相同堆疊空間任務。(本質是分配的大
Objective-C高階程式設計:iOS與OS X多執行緒和記憶體管理
這篇文章主要給大家講解一下GCD的平時不太常用的API,以及文末會貼出GCD定時器的一個小例子。 需要學習的朋友可以通過網盤免費下載pdf版 (先點選普通下載-----再選擇普通使用者就能免費下載了)http://putpan.com/fs/cy1i1beebn7s0h4u9/ 1.G
找工作筆試面試那些事兒(3)---記憶體管理那些事
作者:寒小陽 時間:2013年8月。 出處:http://blog.csdn.net/han_xiaoyang/article/details/10676931。 宣告:版權所有,轉載請註明出處,謝謝。 七、記憶體管理
記憶體管理+記憶體佈局
記憶體管理 8.1 作用域 C語言變數的作用域分為: l 程式碼塊作用域(程式碼塊是{}之間的一段程式碼) l 函式作用域 l 檔案作用域 8.1.1 區域性變數 區域性變數也叫auto自動變數(auto可寫可不寫),一般情況下程式碼塊{}內部定義的變數都是自
Linux記憶體管理(最透徹的一篇)
摘要:本章首先以應用程式開發者的角度審視Linux的程序記憶體管理,在此基礎上逐步深入到核心中討論系統實體記憶體管理和核心記憶體的使用方法。力求從外到內、水到渠成地引導網友分析Linux的記憶體管理與使用。在本章最後,我們給出一個記憶體對映的例項,幫助網友們理解核心記憶體管理與使用者記憶體管理之
[讀書筆記]iOS與OS X多執行緒和記憶體管理 [GCD部分]
3.2 GCD的API 蘋果對GCD的說明:開發者要做的只是定義想執行的任務並追加到適當的Dispatch Queue中。 “Dispatch Queue”是執行處理的等待佇列。通過dispatch_async函式等API,在Block