
kafka在windows上的安裝、執行
1.簡介
Kafka是一種高吞吐量的分散式釋出訂閱訊息系統。詳細介紹可查閱官網:kafka官網
2.環境搭建
2.1 安裝JDK
下載地址:jre下載
有關jdk的安裝不再贅述。
2.2 安裝Zookeeper
下載後,解壓放在目錄D:\bigdata(本文所用的目錄)下,關於zookeeper以及kafka的目錄,路徑中最好不要出現空格,比如D:\Program Files,儘量別用,執行指令碼時會有問題。
①進入zookeeper的相關設定所在的檔案目錄,例如本文的:D:\bigdata\zookeeper-3.4.10\conf
②將"zoo_sample.cfg"重新命名為"zoo.cfg"
③開啟zoo.cfg(至於使用什麼編輯器,根據自己喜好選即可),找到並編輯:
dataDir=/tmp/zookeeper to D:/bigdata/zookeeper-3.4.10/data或 D:\\bigdata\\zookeeper-3.4.10\\data(路徑僅為示例,具體可根據需要配置)
這裡注意,路徑要麼是"/"分割,要麼是轉義字元"\\",這樣會生成正確的路徑(層級,子目錄)。
④與配置jre類似,在系統環境變數中新增:
a.系統變數中新增ZOOKEEPER_HOME=D:\bigdata\zookeeper-3.4.10
b.編輯系統變數中的path變數,增加%ZOOKEEPER_HOME%\bin
⑤在zoo.cfg檔案中修改預設的Zookeeper埠(預設埠2181)
這是本文最終的zoo.cfg檔案的內容:
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=D:/bigdata/zookeeper-3.4.10/data #dataDir=D:\\bigdata\\zookeeper-3.4.10\\data # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
⑥開啟cmd視窗,輸入zkserver,執行Zookeeper,執行結果如下:
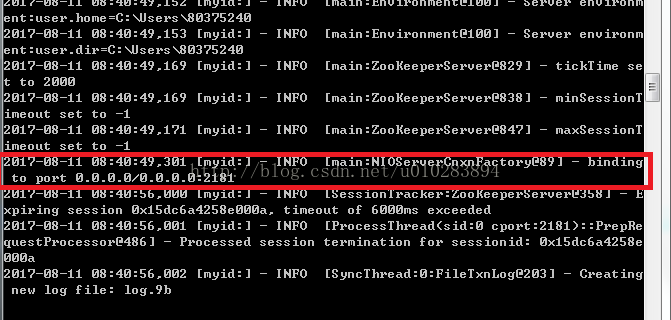
恭喜,Zookeeper已經安裝完成,已在2181埠執行。
2.3 安裝kafka
要下載Binary downloads這個型別,不要下載原始檔,這種方便使用。下載後,解壓放在D:\bigdata目錄下。
①進入kafka配置檔案所在目錄,D:\bigdata\kafka_2.11-0.9.0.1\config
②編輯檔案"server.properties",找到並編輯:
log.dirs=/tmp/kafka-logs to log.dirs=D:/bigdata/kafka_2.11-0.9.0.1/kafka-logs 或者 D:\\bigdata\\kafka_2.11-0.9.0.1\\kafka-logs
同樣注意:路徑要麼是"/"分割,要麼是轉義字元"\\",這樣會生成正確的路徑(層級,子目錄)。錯誤路徑情況可自行嘗試,資料夾名為這種形式:bigdatakafka_2.11-0.9.0.1kafka-logs
③在server.properties檔案中,zookeeper.connect=localhost:2181代表kafka所連線的zookeeper所在的伺服器IP以及埠,可根據需要更改。本文在同一臺機器上使用,故不用修改。
④kafka會按照預設配置,在9092埠上執行,並連線zookeeper的預設埠2181。
2.4 執行kafka
提示:請確保啟動kafka伺服器前,Zookeeper例項已經在執行,因為kafka的執行是需要zookeeper這種分散式應用程式協調服務。
①進入kafka安裝目錄D:\bigdata\kafka_2.11-0.9.0.1
②按下shift+滑鼠右鍵,選擇"在此處開啟命令視窗",開啟命令列。
③在命令列中輸入:.\bin\windows\kafka-server-start.bat .\config\server.properties 回車。
④正確執行的情況為:
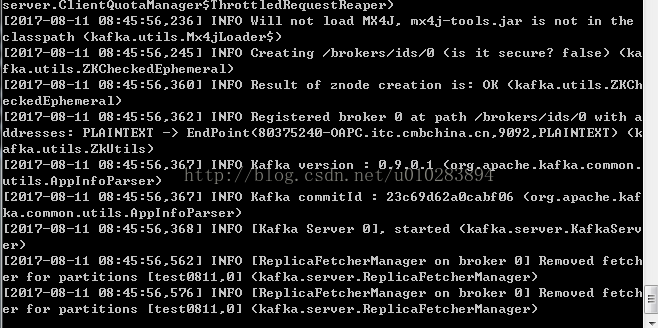
到目前為止,zookeeper以及kafka都已正確執行。保持執行狀態,不要關閉。
重要(操作日誌的處理):
kafka啟動後,如果你去檢視kafka所在的根目錄,或者是kafka本身的目錄,會發現已經預設生成一堆操作日誌(這樣看起來真心很亂):
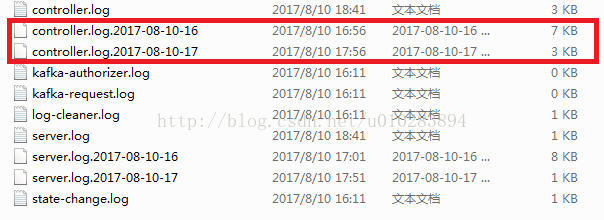
而且會不斷生成不同時間戳的操作日誌。剛開始不知所措,一番研究後,看了啟動的指令碼內容,發現啟動的時候是會預設使用到這個log4j.properties檔案中的配置,而在zoo.cfg是不會看到本身的啟動會呼叫到這個,還以為只有那一個日誌路徑:

在這裡配置一下就可以了,找到config下的log4j.properties:
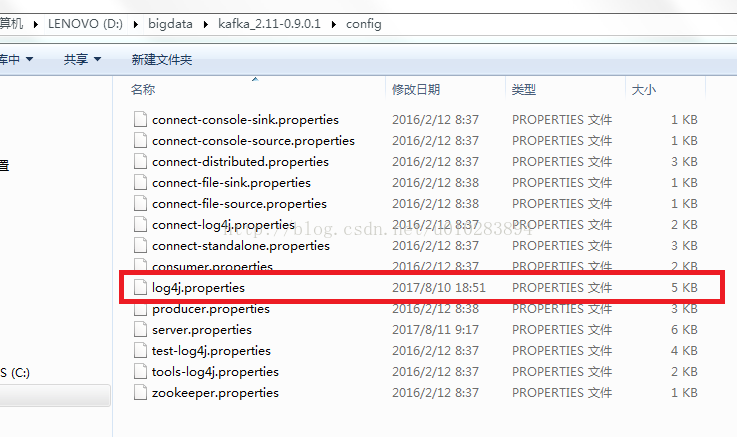
將路徑更改下即可,這樣就可以歸檔在一個資料夾下邊了,路徑根據自己喜好定義:

另外如何消除不斷生成日誌的問題,就是同一天的不同時間會不停生成。
修改這裡,還是在log4j.properties中:
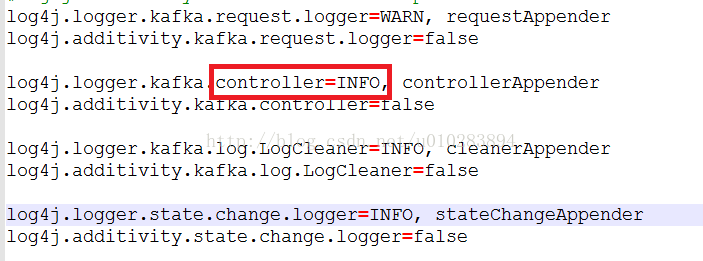
本身都為trace,字面理解為會生成一堆跟蹤日誌,將其改為INFO即可。
2.5 建立主題
①建立主題,命名為"test0811",replicationfactor=1(因為只有一個kafka伺服器在執行)。可根據叢集中kafka伺服器個數來修改replicationfactor的數量,以便提高系統容錯性等。
②在D:\bigdata\kafka_2.11-0.9.0.1\bin\windows目錄下開啟新的命令列
③輸入命令:
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test0811
回車。
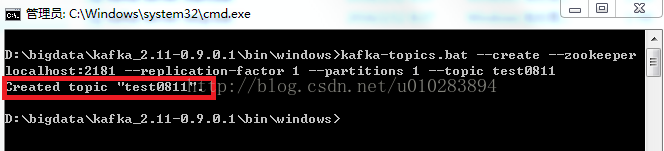
該視窗可以關閉。
2.6 建立生產者(producer)和消費者(consumer)
①在D:\bigdata\kafka_2.11-0.9.0.1\bin\windows目錄下開啟新的命令列。
②輸入命令,啟動producer:
kafka-console-producer.bat --broker-list localhost:9092 --topic test0811
該視窗不要關閉。
③同樣在該目錄下開啟新的命令列。
④輸入命令,啟動consumer:
kafka-console-consumer.bat --zookeeper localhost:2181 --topic test0811
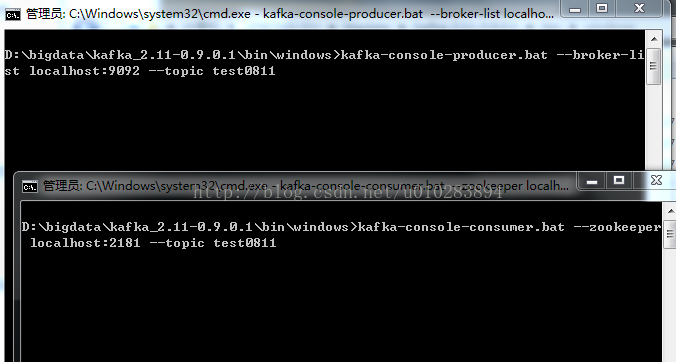
現在生產者、消費者均已建立完成。
⑤在producer命令列視窗中任意輸入內容,回車 在consumer命令列視窗中即可看到相應的內容。
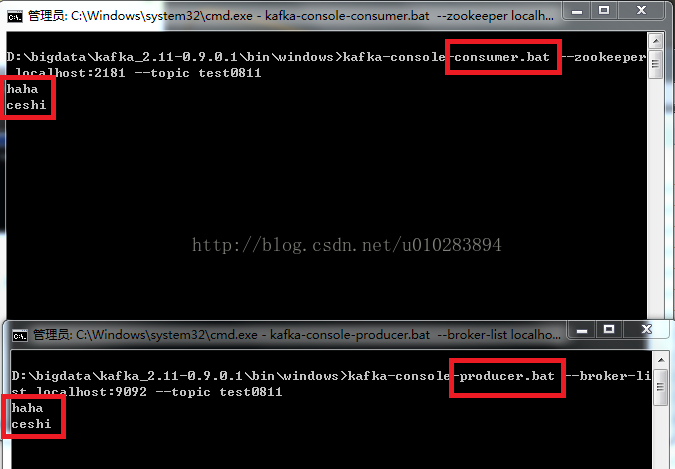
至此,已完成kafka在windows下的安裝和基本的使用。
本人才疏學淺,如有錯誤,還望批評指正。
相關推薦
kafka在windows上的安裝、執行
1.簡介 Kafka是一種高吞吐量的分散式釋出訂閱訊息系統。詳細介紹可查閱官網:kafka官網 2.環境搭建 2.1 安裝JDK 下載地址:jre下載 有關jdk的安裝不再贅述
詳解node + mongoDb(mongoDb安裝、執行,在node中連線、增刪改查)
一、序言 好久沒寫部落格了,這次主要聊聊 node 和 mongoDb 。 先說明一下技術棧 node + express + mongoose + mongoDb。這篇部落格,主要講述 mongoDb 的下載 、安裝 、 配置 、 執行 以及如何在 node
Redis入門(下載、安裝、執行)(兩個系統Linux、window)
Redis入門(下載、安裝)(Linux、window) 一、Redis介紹 Redis是NoSql的一種。 1、什麼是NoSql NoSql,全名:Not Only Sql,是一種非關係型資料庫,它不能替代關係弄資料庫,只是關係型資料庫的一個補充,是可以解決高
關於在contos6.9上安裝並執行kettle7.0錯誤的總結
在將kettle壓縮包上傳到linux後,在路徑下執行sh Kitchen.sh時出現 [[email protected] data-integration]# ./kitchen.sh ###########################################
CEF3在CentOS7.2上編譯、執行
1. 前言 CEF 官方提供了Ubuntu的編譯認證,對於CentOS沒有特別說明。 基於最新的二進位制編譯結果進行編譯整合,測試沒啥問題,特此記錄 1.事先準備 發行版映象YUM源 本次實驗對應的版本: cef_binary_3.3497.1834.g0a
樹莓派上 安裝並 執行opencv
http://www.cnblogs.com/farewell-farewell/p/6125761.html 1.先安裝依賴項 OpenCV 2.2以後版本需要使用Cmake生成makefile檔案,因此需要先安裝cmake。 s
在Ubuntu 16.04上安裝、使用、解除安裝MongoDB
1.匯入包管理系統使用的公鑰 sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 2930ADAE8CAF5059EE73BB4B58712A2291FA4AD5 2.為M
詳解node + mongoDb(mongoDb安裝、執行,在node中連線、增刪改查)
module.exports = { production: { uri: 'mongodb://localhost/db', option: { autoIndex: true, reconnectTries: Number.MAX_VALUE,
Linux安裝、執行MongoDB
一.我的安裝環境:CentOS7+MongoDB4.0.1。 二.下載MongoDB。 我下載的是最新的4.0.1的legacy(舊)版。壓縮包下載完成後上傳到Linux上,然後解壓。解壓命令: tar -zxvf mongodb-linux-x86_64-4.
打造新聖魔大戰簡體中文終極版(H補丁、不能安裝、執行問題)
最近玩通了新聖魔大戰,感覺很好玩,我玩的這個是迅雷搜尋找到的152 MB的新聖魔大戰中文版。新聖魔大戰(Castle Fantisia)全記錄存檔 注意:別人的存檔不能直接用,解決方法看我的文章:新聖魔大戰(Castle Fantisia)修改器/祕籍——究極修改大法 問題是沒有H劇情(呵呵,別不
詳細講解如何在windows下搭建react-native的開發環境(包括在裝置上安裝和執行react-native app )!
我之前在增加完變數後,react-native命令不起作用了,後來重新安裝react-native解決了此問題. 開啟安裝好的android stdio,然後start一個專案,下一步下一步,然後找到這個按鈕,這個是啟動模擬器的鍵,如果沒有安裝模擬器的話,可以選一個手機型號來下載,找到對應你的電腦的
Elasticsearch簡單入門--elasticsearch 在Linux下的安裝、執行、停止
1.首先對Elasticsearch進行簡短的介紹 Elasticsearch是一個高度可伸縮的開源全文搜尋和分析引擎。它允許您快速、實時地儲存、搜尋和分析大量資料。它通常用作底層引擎/技術,為具有複雜搜尋特性和需求的應用程式提供支援。 核心概念:NRT、Cluster、Node、Ind
macOS Docker 上安裝、啟動 MySQL
1 、檢視mysql映象 docker search mysql (檢視所有映象 docker images -a 檢視容器 docker ps) 2、下載映象 docker pull mysql 3、啟動mysql容器 docker run -it mysql
mac上安裝go執行環境liteide
mac上go語言開發環境除了sublime,另外一個熱門是國人開發的liteide.1. 首先確保go已經安裝在本機,並且配置了環境變數, terminal下vim .bash_profile,這是我的配置:GOPATH是我們本機go專案存放的地方,類似於workspace。
在Windows XP上安裝和執行SqlMap的步驟
1、首先下載SqlMap 2、其次下載用於Windows系統的Python ……點選這裡…… 3、然後安裝Python: Python預設安裝的路徑是“C:\Python”(你也可以修改安裝路徑,但要記住路徑),直接預設安裝“下一步”OK … :) 4、解壓SqlM
Live555學習(一)--編譯、安裝、執行
Live555 是一個為流媒體提供解決方案的跨平臺的C++開源專案,它實現了對標準流媒體傳輸協議如RTP/RTCP、RTSP、SIP等的支援。Live555實現了對多種音視訊編碼格式的音視訊資料的流化、接收和處理等支援,包括MPEG、H.263+、DV、JPEG視訊和多種音訊編碼。同時由於良好的設計,Liv
weblogic安裝、執行及中文問題
weblogic安裝 環境說明:作業系統 版本:RedHat Enterprise Advanced Server 3.0WebLogic版本:Weblogic 8.1 sp2 安裝前的準備工作 確定一個安裝目錄,建議該目錄下至少有1個G的空間,可以使用du來察看磁碟空間的
在Ubuntu16.04.1上安裝、配置、使用Nginx
實驗環境 ubuntu16.04.1 怎麼安裝 網上有很多安裝的教程,自己摸索吧 我是通過sudo apt-get install nginx命令安裝的nginx 上述命令執行完,都幹了什麼?如何找到它的檔案在哪呢? 使用locate ngi
64位Linux(ubuntu)安裝、執行32位程式
ubuntu 64位版本,安裝支援32位程式的二進位制庫。 sudo dpkg --add-architecture i386 sudo apt-get update sudo apt-get install zlib1g:i386 libstdc++6:
全真教程:Windows環境Jupyter Notebook安裝、執行和工作資料夾配置
 # 全真教程:Windows環境Jupyter Notebook安裝