
SQL Server 索引和檢視
索引
索引定義
索引就是資料表中資料和相應的儲存位置的列表,利用索引可以提高在表或檢視中的查詢資料的速度。
索引分類
資料庫中索引主要分為兩類:聚集索引和非聚集索引。SQL Server 2005還提供了唯一索引、索引檢視、全文索引、xml索引等等。聚集索引和非聚集索引是資料庫引擎中索引的基本型別,是理解其他型別索引的基礎。
聚集索引
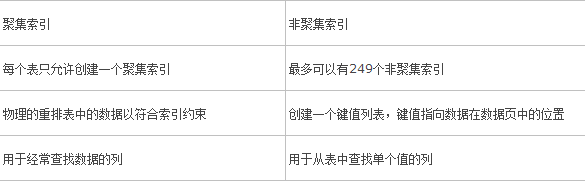
聚集索引是值表中資料行的物理儲存順序和索引的儲存順序完全相同。聚集索引根據索引順序物理地重新排列了使用者插入到表中的資料,因此,每個表只能建立一個聚集索引。聚集索引經常建立在表中經常被搜尋到的列或按順序訪問的列上。在預設情況下,主鍵約束自動建立聚集索引。
非聚集索引
非聚集索引不改變表中資料列的物理儲存位置,資料與索引分開儲存,通過索引指向的地址與表中的資料發生關係。
非聚集索引沒有改變表中物理行的位置,索引可以在以下情況下使用非聚集索引:
如果某個欄位的資料唯一性比較高
如果查詢所得到的資料量比較少
聚集索引和非聚集索引的區別
其他型別索引
除了以上索引,還有以下型別索引:
唯一索引:如果希望索引鍵都不同,可以建立唯一索引。聚集索引和非聚集索引都可以是唯一索引。
包含新列索引:索引列的最大數量是16個,索引列的位元組總數的最高值是900。如果當多個列的位元組總數大於900,切又想在這些劣種都包含索引是,可以使用包含性列索引
檢視索引:提供檢視查詢效率,可以檢視的索引物理化,也就是說將結果集永久儲存在索引中,可以建立檢視索引。
XML索引:是與xml資料關聯的索引形式,是XML二進位制blob的已拆分持久表示形式
全文索引:一種特殊型別的基於標記的功能性功能,用於幫助在字串中搜索賦值的詞
建立索引
語法
create [unique] [clustered | noclustered]
index index_name
on table_name (column_name ...)
[with fillfactor=x]unique唯一索引
clustered聚集索引
noclustered非聚集索引
fillfactor填充因子大小,範圍在0-100直接,表示索引頁填滿的空間所佔的百分比。
例項
if (exists (select * from sys.indexes where name = 'idx_stu_name'))
drop index student.idx_stu_name
go
create index idx_stu_name
on
student(name);
--聯合索引
if (exists (select * from sys.indexes where name = 'idx_uqe_clu_stu_name_age'))
drop index student.idx_uqe_clu_stu_name_age
go
create unique clustered index idx_uqe_clu_stu_name_age
on student(name, age);
if (exists (select * from sys.indexes where name = 'idx_cid'))
drop index student.idx_cid
go
if (exists (select * from sys.indexes where name = 'idx_cid'))
drop index student.idx_cid
go
--非聚集索引
create nonclustered index idx_cid
on
student (cid)
with fillFactor = 30; --填充因子
--聚集索引
if (exists (select * from sys.indexes where name = 'idx_sex'))
drop index student.idx_sex
go
create clustered index idx_sex
on
student(sex);
--聚集索引
if (exists (select * from sys.indexes where name = 'idx_name'))
drop index student.idx_name
go
create unique index idx_name
on
student(name);適合建立索引的列
當資料庫的某一列被頻繁的用於資料庫查詢時,或者該列用於資料庫進行排序時可以建立成索引
不適合建立索引的列
如果列中有幾個不同的值,或者表中僅包含幾行值,則不推薦為其建立索引。因為索引在搜尋資料所花的時間比在表中逐行搜尋話的時間更長。
檢視
檢視的定義
檢視就是一個虛擬的資料表,該資料表中的資料記錄是有一條查詢語句的查詢結果得到的。
建立檢視準則
建立檢視需要考慮一下準則:
- 檢視名稱必須遵循識別符號的規則,該名稱不得與該架構的如何表的名稱相同
- 你可以對其他檢視建立檢視。允許巢狀檢視,但巢狀不得超過32層。檢視最多可以有1024個欄位
- 不能將規則和default定義於檢視相關聯
- 檢視的查詢不能包含compute子句、compute by子句或into關鍵字
- 定義檢視的查詢不能包含order by子句,除非在select 語句的選擇列表中還有top子句
下列情況必須指定檢視中每列的名稱:
- 檢視中的如何列都是從算術表示式、內建函式或常量派生而來
- 檢視中有兩列或多列具有相同名稱(通常由於檢視定義包含聯接,因此來自兩個或多個不同的列具有相同的名稱)
- 希望檢視中的列指定一個與其原列不同的名稱(也可以在檢視中重新命名列)。無論是否重新命名,檢視列都回繼承原列的資料型別
建立檢視
--建立檢視
if (exists (select * from sys.objects where name = 'v_stu'))
drop view v_stu
go
create view v_stu
as
select id, name, age, sex from student;修改檢視
alter view v_stu
as
select id, name, sex from student;
alter view v_stu(編號, 名稱, 性別)
as
select id, name, sex from student
go
select * from v_stu;
select * from information_schema.views;加密檢視
--加密檢視
if (exists (select * from sys.objects where name = 'v_student_info'))
drop view v_student_info
go
create view v_student_info
with encryption --加密
as
select id, name, age from student
go
--view_definition is null
select * from information_schema.views
where table_name like 'v_stu';相關推薦
SQL Server 索引和檢視
索引 索引定義 索引就是資料表中資料和相應的儲存位置的列表,利用索引可以提高在表或檢視中的查詢資料的速度。 索引分類 資料庫中索引主要分為兩類:聚集索引和非聚集索引。SQL Server 2005還提供了唯一索引、索引檢視、全文索引、xm
SQL Server 索引和視圖
student 索引 1、 什麽是索引 索引就是數據表中數據和相應的存儲位置的列表,利用索引可以提高在表或視圖中的查找數據的速度。 2、 索引分類 數據庫中索引主要分為兩類:聚集索引和非聚集索引。SQL Server 2005還提供了唯一索引、索引視圖、全文索引、xml
SQL Server 索引和表體系結構(非聚集索引)
非聚集索引 概述 對於非聚集索引,涉及的資訊要比聚集索引更多一些,由於整個篇幅比較大涉及接下來的要寫的“包含列的索引”,“索引碎片”等一些知識點,可能要結合起來閱讀理解起來要更容易一些。非聚集索引和聚集索引一樣都是B-樹結構,但是非聚集索引不改變資料的儲存方式,所以一個表允許建多個非聚集索引;非
SQL Server 索引和表體系結構(聚集索引)
聚集索引 概述 關於索引和表體系結構的概念一直都是討論比較多的話題,其中表的各種儲存形式是討論的重點,在各個網站上面也有很多關於這方面寫的不錯的文章,我寫這篇文章的目的也是為了將所有的知識點儘可能的組織起來結合自己對這方面的瞭解些一篇關於的詳細文章出來,同時也會列出一些我自己有疑惑的地方拿出來
SQL Server 索引和表體系結構(包含列索引)
包含列索引 概述 包含列索引也是非聚集索引,索引結構跟聚集索引結構是一樣,有一點不同的地方就是包含列索引的非鍵列只儲存在葉子節點;包含列索引的列分為鍵列和非鍵列,所謂的非鍵列就是INCLUDE中包含的列,至少需要有一個鍵列,且鍵列和非鍵列不允許重複,非鍵列最多允許1023列(也就是表的最多列-1),由於索
SQL Server資料庫開發(4.索引和檢視)
一、索引 定義:是資料表中資料和相應儲存位置的列表。 作用:可以提高在表或檢視中查詢資料的速度。 1.分類:聚集索引,非聚集索引 聚集索引:指表中資料行的物理儲存順序與索引順序完全相同。 非聚集索引:不該表表中資料行的物理儲存位置,資料與索引分開儲存,通過索引指向的地址與表中的資
資料庫學習SQL Server 第三章 約束、索引和檢視
第三章 約束、索引和檢視@TOC 1.簡介 約束,比如說要求欄位非空,就是最簡單的非空約束; 表格阻止更改和重新建立的問題(工具–選項–設計–取消阻止保護) 2.CHEAK約束 表設計器,右鍵–選擇cheak約束,比如要求收入=工資+獎金的約束,若新增值的時候,
資料庫學習SQL Server 第三章 約束、索引和檢視
第三章 約束、索引和檢視@TOC 1.簡介 約束,比如說要求欄位非空,就是最簡單的非空約束; 表格阻止更改和重新建立的問題(工具–選項–設計–取消阻止保護) 2.CHEAK約束 表設計器,右鍵–選擇cheak約束,比如要求收入=工資+獎金的約束,若新增值的時候,不遵循chea
Sql Server 索引以及頁和區
順序存儲 alt cluster 思考 文檔 數據存儲 div 數據頁 博客 索引(Index),相信大家都知道就是給表中的數據添加了一個目錄,使我們可以快速檢索到我們想要的數據,但這個目錄是什麽?SqlServer又是如何管理的?要搞明白這些,我們就要先了解sqlserv
SQL Server 建立和使用索引 (轉載)
使用CREATE INDEX語句建立索引: CREATE[ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX索引名 ON {表名|檢視名} (列名[ ASC | DESC ] [ ,...n ] ) 例: 在資料庫HrSystem中為表Employees建立基於IDC
SQL Server 索引碎片產生原理重建索引和重新組織索引
填充 效果 hive gen 原理 alt body iss lec 數據庫存儲本身是無序的,建立了聚集索引,會按照聚集索引物理順序存入硬盤。既鍵值的邏輯順序決定了表中相應行的物理順序 多數情況下,數據庫讀取頻率遠高於寫入頻率,索引的存在 為了讀取速度犧牲寫入速度 頁 為最
SQL Server 索引碎片產生原理重建索引和重新組織索引 SQL Server索引的維護 - 索引碎片、填充因子 <第三篇>
資料庫儲存本身是無序的,建立了聚集索引,會按照聚集索引物理順序存入硬碟。既鍵值的邏輯順序決定了表中相應行的物理順序 多數情況下,資料庫讀取頻率遠高於寫入頻率,索引的存在 為了讀取速度犧牲寫入速度 頁 為最小單位 8kb 區 物理連續的頁(8頁)的集合 內部碎片 資料庫頁內部產生的碎片,外部反
臨時表和表變數區別,SQL Server裡的檢視和臨時表在哪裡?
臨時表與永久表相似,但臨時表儲存在 tempdb 中,當不再使用時會自動刪除。 臨時表有兩種型別:本地和全域性。它們在名稱、可見性以及可用性上有區別。本地臨時表的名稱以單個數字元號 (#) 打頭;它們僅對當前的使用者連線是可見的;當用戶從 SQL Server 例項斷開連
SQL第四章(索引和檢視)
1、索引 資料表中資料和相應儲存位置的列表 特點:提高在表或檢視中查詢資料的速度 分類: ①聚集索引 表中資料行的物理儲存順序與索引順序完全相同 /*--聚集索引--*/ --主鍵會自動生成同名聚集索引,不能再建立
SQL Server索引中的碎片和填充因子
簡介 在SQL Server中,儲存資料的最小單位是頁,每一頁所能容納的資料為8060位元組.而頁的組織方式是通過B樹結構(表上沒有聚集索引則為堆結構,不在本文討論之列)如下圖: 在聚集索引B樹中,只有葉子節點實際儲存資料,而其他根節點和中
SQL Server索引碎片整理實際操作記錄
刪除 inner dog man and 嘗試 語句 ssd ext SQL Server 版本是 2008 R2。 查詢數據庫索引碎片情況的 SQL 語句(來源): SELECT OBJECT_NAME(ind.OBJECT_ID) AS TableName,
SQL Server 索引重建手冊
ats 監視 影響 查詢 pil 數據庫 com ati 最大 步驟一: 查詢索引碎片,腳本如下,庫比較大時執行時間會很長,雖然對數據庫影響不大,依然建議在非高峰時段執行。(執行之前請先選定要查詢碎片的數據庫) Declare @dbid int Select @dbi
[翻譯]——SQL Server索引的介紹:SQL Server索引級的階梯
找到 重要 creat statistic 完全 published png work 定位 SQL Server索引的介紹:SQL Server索引級的階梯 By David Durant, 2014/11/05 (first published: 2011/02/17)
SQL Server索引設計 <第五篇>
字段排序 暫停 最快 get include 對象 聚合函數 要花 可能性 SQL Server索引的設計主要考慮因素如下: 檢查WHERE條件和連接條件列; 使用窄索引; 檢查列的選擇性; 檢查列的數據類型; 考慮列順序; 考慮索引
SQL Server索引的維護 - 索引碎片、填充因子 <第三篇>
sys 使用 text tree 如何 drop some 檢索 作用 實際上,索引的維護主要包括以下兩個方面: 頁拆分 碎片 這兩個問題都和頁密度有關,雖然兩者的表現形式在本質上有所區別,但是故障排除工具是一樣的,因為處理是相同的。 對