
分散式檔案系統名字空間實現研究
1、名字空間概述
名字空間(Namespace)即檔案系統檔案目錄的組織方式,是檔案系統的重要組成部分,為使用者提供視覺化的、可理解的檔案系統檢視,從而解決或降低人類與計算機之間在資料儲存上的語義間隔。目前樹狀結構的檔案系統組織方式與現實世界的組織結構最為相似,被人們所廣泛接受。因此絕大多數的檔案系統皆以Tree方式來組織檔案目錄,包括各種磁碟檔案系統(EXTx, XFS, JFS, Reiserfs, ZFS, Btrfs, NTFS, FAT32等)、網路檔案系統(NFS, AFS, CIFS/SMB等)、叢集檔案系統(Lustre, PNFS, PVFS, GPFS, PanFS等)、分散式檔案系統(GoogleFS, HDFS, MFS, KFS, TaobaoFS, FastDFS等)。
隨著面向物件儲存和雲端儲存的發展,出現了一種稱為偏平化(Flat)的檔案系統組織方式,典型代表有Lustre, PanFS, Amazon S3, Google Storage。這種方式把所有檔案目錄看作物件Object,每一個物件有一個全域性唯一的標識UUID,戶使用此UUID(而非路徑)來訪問儲存系統。然而,UUID僅僅對計算機有意義,在使用者介面層往往還是需要提供樹狀檔案系統檢視,再由系統在Path和UUID之間進行轉換。在物件儲存層,物件或物件資料分片以檔案形式儲存在磁碟檔案系統之上,物理儲存層仍然是樹狀儲存結構。另外,對於法規遵從資料儲存領域廣泛使用的固定內容儲存系統CAS(Content addressed storage, 內容定址儲存),採用基於物件的儲存系統,機制與此類似。
具體實現上,磁碟檔案系統的名字空間直接在磁碟上來實現,通常以B*/B+/B-樹的形式來組織,元資料和資料儲存在相同的介質上。而對於分散式檔案系統來說,元資料和資料和儲存和訪問是分離的,這是由高效能、可用性、可擴充套件性等設計要求所決定的。通常,資料的存取由I/O伺服器來實現,而元資料由元資料伺服器來負責。名字空間是元資料伺服器的核心任務之一,此外可能還要負責安全機制(如授權與認證)、鎖機制、I/O負載均衡等。因此,由於元資料與資料的分離,分散式檔案系統名字空間實現的自由度比較大,實現方式有更多的選擇空間。這裡將要介紹四種分散式檔案系統名字空間實現機制,均為樹狀檔案系統檢視,大致分為基於檔案系統的實現和基於全記憶體的實現,但不包括基於資料庫的實現。基於資料庫來實現檔案系統名字間有眾所周知的效能問題,尤其是遞迴遍歷檔案目錄空間。
2、四種檔案系統名字空間實現
(1)基於檔案系統的設計
這是一種"站在巨人肩膀上"的設計。磁碟檔案系統本身就是樹狀結構檢視,因此可以利用這現成的機制在元資料伺服器上實現名字空間。對於分散式檔案系統中的每一個目錄或檔案,在元資料伺服器的本地檔案系統之上一一對應建立一個目錄或檔案(以下稱為元目錄和元檔案),兩者之間的對映關係如圖1所示。元目錄用來表示DFS中的目錄,其元目錄屬性儲存DFS目錄屬性;元檔案用來表示DFS中的檔案,元檔案屬性儲存DFS檔案屬性,元檔案內容則用來儲存元資料,包括更詳細的檔案屬性、訪問控制資訊、資料分片資訊、資料儲存位置等資訊。

圖1 基於檔案系統的設計(DFS與本地檔案系統名字對映)
基於檔案系統我們以極小的代價構建了DFS的名字空間,實現起來簡單快速。元檔案僅用來儲存資料檔案的元資料,一般都是小於1KB的小檔案,如果檔案目錄數量達到千萬量級就會形成LOSF(Lots of small files)的效能問題。實際應用中如何來解決這種問題呢?目前主要有兩種解決方法,一是採用適合海量小檔案儲存的檔案系統。Reiserfs對小檔案儲存進行了特別優化,它不僅檔案查詢效率高,而且節省磁碟儲存空間,實際測試結果也驗證了這一點。二是採用高效能的儲存介質,尤其是IOPS指標。非常幸運,固態硬碟SSD技術上已經比較成熟,成本不斷降低,非常適合高效能的儲存應用。SSD的特點是IOPS高,普通SSD讀寫IPOS可以達到10000 ~ 50000,高階SSD甚至可以達到100000以上,而FC、SAS、SATA磁碟的IPOS基本小於300,遠遠小於SSD。因此,採用SSD和Reiserfs檔案系統,效能能夠得到大幅提升,大多數應用問題不大。
(2)基於全記憶體的分層設計
這種方式與HDFS實現相仿。與基於檔案系統的實現不同,名字空間完全在元資料伺服器的記憶體中,使用層次結構來表示,如圖2所示。這種層次結構相當於一棵樹,每個結點表示DFS的一個目錄或檔案,結點的孩子結點理論上沒有數量限制(取決於記憶體可用量),孩子結點使用動態陣列來表示。結點資料結構如下所示,其中metadata表示(1)中檔案目錄類似的元資料資訊,children是孩子結點動態陣列,使用二分法實現插入、查詢和刪除操作,嚴格按照名稱進行升序排序。
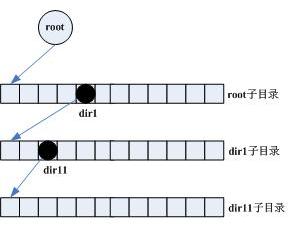
圖2 基於全記憶體的分層設計
對於檔案系統ls操作,首先對路徑進行解析並拆分成獨立的目錄名,然後從root結點開始查詢,孩子結點陣列使用logN的二分搜尋BinarySearch查詢,直到找到對應的目錄結點,然後遍歷結點的孩子結點陣列即可。假設目錄深度為h,目錄寬度為n,則查詢目錄檔案的時間複雜度為O(h * log(n))。對於檔案系統來說,這種查詢時間複雜度顯得有點高,尤其是目錄層次很深、子目錄檔案數量龐大的分散式檔案系統。HDFS的設計思想源自GFS,可是在名字空間設計上還是與GFS存在一定的差距,可謂形似而神不似。另外,全記憶體設計對記憶體需求比較高,假設每個目錄檔案的元資料大小為100位元組,則1千萬目錄檔案的元資料大小總量約等於1,000,000,000 = 1GB。如果需要支援更多的目錄檔案,則需要應增加記憶體量。
(3)基於全記憶體的Hash設計
這種方式與GFS實現相仿。GFS論文中指出其名字空間採用了全記憶體設計、偏平式組織、字首壓縮演算法、二分查詢演算法、沒有支援ls的資料結構,論文中還指出ls操作的效率較低。GFS沒有開源,不像HDFS可以查閱原始碼,因此也無法完全重現GFS的名字空間實現,基本全記憶體的Hash設計可能比較接近其設計。這種設計採用Hash和二分查詢相結合的來實現,即目錄以完整的絕對路徑進行hash定位,該目錄下的孩子結點使用二分查詢進行定位,如圖3所示。它與分層設計的主要不同在於,只需要一次hash和一次二分查詢,而分層設計需要多次的二分查詢,在效能上更優。我們僅對目錄進行Hash,名字空間具有一定的偏平性,但沒有達到GFS的完全偏平;子檔案目錄不包括父路徑部分,相當於作了字首壓縮,但不如分層字首壓縮徹底。大膽猜測,GFS可能採用了全HASH設計或全列表設計,ls操作通過字首匹配來實現,即具有相同字首的檔案屬於同一個目錄,如此實現名字空間。
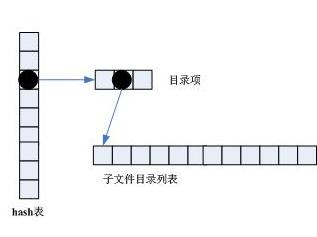
圖3 基於記憶體的hash設計
這種設計下,查詢指定檔案或執行ls,首先將路徑分解成父路徑名和目錄檔名,對父路徑名進行hash運算定位至其孩子結點列表,然後二分查詢指定檔案,或者遍歷孩子結點列表實現ls操作。假設目錄寬度為n,查詢時間複雜性為log(n),在記憶體佔用量上要稍稍大於分層設計,因為目錄結點均重複一次。這種設計具有支援ls的資料結構,相對於GFS來說,執行ls效率要高出許多,如果GFS是全Hash設計則需要遍歷整個檔案空間進行字首匹配,如果GFS是全列表設計則需要以父路徑名進行二分查詢然後區域性字首匹配。
(4)基於全記憶體的雙重Hash設計
這種方式是對基於全記憶體hash設計的改進。它先對目錄進行第一次hash運算,然後對子檔案目錄進行第二次hash運算,從而將查詢時間複雜性從log(n)進一步降低至O(2),如圖4所示。目錄Hash表是全域性的,而目錄結點的Hash表是區域性的,每一個目錄結點都包含一個Hash表,僅用來儲存本目錄下的子檔案目錄資訊,目錄結點資料結構如下所示。

圖4 基於記憶體的雙重hash設計
對於檔案系統ls操作,對路徑名進行一次hash運算定位到目錄結點,然後對目錄結點中的hash表進行遍歷即可。檔案查詢時,首先將路徑名分解成父路徑名和檔案目錄名,對父路徑名進行hash運算定位父目錄結點,然後對檔案目錄名進行hash運算並在父目錄結點中的hash表進行定位。目錄結點中的hash表初始為未建立,直到第一次建立子檔案目錄時方才建立,hash表項數量定義為平均目錄包含的子檔案目錄數量,在效能和記憶體空間節省之間進行折中。如果記憶體充足,hash表項數量應該儘量設定大些,以達到更好的雜湊效果。與基於全記憶體的Hash設計相比,這種設計查詢效能上更上層樓,記憶體消耗相應有所增加。
3、對比分析與應用選擇
上述分散式檔案系統名字空間的四種實現方式,按照實現位置劃分,可分為基於檔案系統的實現和基於記憶體的實現。基於檔案系統實現的優點是實現簡單,記憶體要求低,可以執行在普通的機器上,缺點是效能可能較低。如果採用SSD+Reiserfs實現,效能應該不是大問題,但成本也隨之提高許多。基於記憶體實現的優點是效能高,缺點是對記憶體要求極高,實現起來比較複雜,並需要對記憶體的名字空間進行永續性保護措施防止意外宕機或出錯。基於記憶體的三種實現,效能方面雙重hash設計 > hash設計 > 分層設計,記憶體需求方面則相反。實際實現和應用中,應該結合成本預算和效能需求進行選擇,選擇的原則是,在滿足設計要求的前提下儘量爭取價效比最大化。
相關推薦
分散式檔案系統名字空間實現研究
1、名字空間概述 名字空間(Namespace)即檔案系統檔案目錄的組織方式,是檔案系統的重要組成部分,為使用者提供視覺化的、可理解的檔案系統檢視,從而解決或降低人類與計算機之間在資料儲存上的語義間隔。目前樹狀結構的檔案系統組織方式與現實世界的組織結構最為相似,被人們所廣泛
Hadoop分散式檔案系統利用 java API 實現
(前提:自己的linux系統中的叢集已搭建完畢 )1 . 首先在電腦中安裝 hadoop 配置環境變數: 右鍵點選“計算機”--> 屬性 --> 高階系統設定 --> 環境變數 建立一個 “HADOOP_HOME”,值為hadoop安裝
分散式檔案系統MFS的基本用法以及高可用實現
實驗主機環境(redhat 6.5 x86_64bit) ip hostname softwares to install 192.168.1.8 cobbler1 mfs-master cgi-server keepali
fastdfs-安裝部署fastdfs實現分散式檔案系統(一)
在移動網際網路時代,智慧終端,包括手機,平板電腦,物聯網的發展,個人產生的圖片,視訊檔案,文件檔案,其他資料已經非常的多,那麼對於如何處理這些海量的資料,是一個非常重要的環節,一方面要保證資料的安全和完整性,同時又要能夠容易的橫向擴容的存貯系統升級。那麼就需要用到分散式檔案
fastdfs分散式檔案系統之TrackerServer連線池實現
非常感謝 http://blog.csdn.net/Mr_Smile2014/article/details/52441824 公司使用fastdfs檔案系統來儲存檔案和圖片,為了避免每個系統都直接通過客戶端直接訪問fastdfs檔案系統,所以我們做了一個
分散式檔案系統FastDFS簡介、搭建、與SpringBoot整合實現圖片上傳
之前大學時搭建過一個FastDFS的圖片伺服器,當時只是抱著好奇的態度搭著玩一下,當時搭建採用了一臺虛擬機器,tracker和storage服務在一臺機器上放著,最近翻之前的部落格突然想著在兩臺機器上搭建試一下,順便整合了SpringBoot實現了一下圖片的上傳服務。 新的閱讀體驗地址:http://www
Atitit 分散式檔案系統 hdfs nfs fastfs 目錄 1. 分散式檔案系統 1 2. 什麼是FastDFS 1 2.1. FastDFS特性: 1 2.1.1. fastdfs是否可在
Atitit 分散式檔案系統 hdfs nfs fastfs 目錄 1. 分散式檔案系統 1 2. 什麼是FastDFS 1 2.1. FastDFS特性: 1 2.1.1. fastdfs是否可在windows系統下安裝?可以的話,哪位可以..._百度知道 2
使用python的hdfs包操作分散式檔案系統(HDFS)
===================================================================================== 寫在前邊的話: 之前做的Hadoop叢集,組合
FastDFS分散式檔案系統配置與部署
一文搞定FastDFS分散式檔案系統配置與部署 閱讀目錄 1 分散式檔案系統介紹 2 系統架構介紹 3 FastDFS效能方案 4 Linux基本命令操作 5 安裝VirtualBox虛擬機器並配置Ubuntu
第3章:Hadoop分散式檔案系統(2)
資料流 讀取檔案資料的剖析 為了知道客戶端與HDFS,NameNode,DataNode互動過程中資料的流向,請看圖3-2,這張圖顯示了讀取檔案過程中主要的事件順序。 客戶端通過呼叫FileSystem物件的open()方法開啟一個希望從中讀取資料的檔案,對於HDFS來說,FileSystem是一個Dis
1、HDFS分散式檔案系統
1、HDFS分散式檔案系統 分散式儲存 分散式計算 2、hadoop hadoop含有四個模組,分別是 common、 hdfs和yarn。 common 公共模組。 HDFS hadoop distributed file system,hadoop分散式檔案系統,負責檔案的
【架構】分散式追蹤系統設計與實現
分散式系統為什麼需要 Tracing? 先介紹一個概念:分散式跟蹤,或分散式追蹤。 電商平臺由數以百計的分散式服務構成,每一個請求路由過來後,會經過多個業務系統並留下足跡,併產生對各種Cache或DB的訪問,但是這些分散的資料對於問題排查,或是流程優化都幫助有限。
hadoop[4]-hdfs分散式檔案系統的基本工作機制
一、Namenode 和 Datanode HDFS採用master/slave架構。一個HDFS叢集是由一個Namenode和一定數目的Datanodes組成。Namenode是一箇中心伺服器,負責管理檔案系統的名字空間(namespace)以及客戶端對檔案的訪問。叢集中的Datanode一般是一個節點一
Hadoop分散式檔案系統搭建以及基本操作
1. 環境搭建 jdk-1.8 jdk下載地址 export JAVA_HOME = /usr/lib/java/jdk1.7.0_21 export PATH =$JAVA_HOME/bin:$PATH hadoop-2.7.3 hadoop各個版本
CentOS 7 安裝配置分散式檔案系統 FastDFS 5.11
CentOS 7 安裝配置分散式檔案系統 FastDFS 5.11 前言: FastDFS是現在比較流行的分散式檔案系
流行的開源分散式檔案系統比較
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
部署MooseFS分散式檔案系統
MooseFS是一個分散式檔案系統,其本身具有高可用性,高拓展性,開放原始碼,高容錯,等在資料的讀寫效能方面,通過dd測試,MooseFS也就是寫入的速度稍微好於NFS,讀上沒有差別. MooseFS的檔案系統結構體系可分為以下四種角色,分別對應不同的功能: 1.管理伺服器managing server
MooseFS分散式檔案系統介紹
一、簡介 MooseFS是一個具備冗餘容錯功能的分散式網路檔案系統,它將資料分別存放在多個物理伺服器或單獨磁碟或分割槽上,確保一份資料有多個備份副本。對於訪問的客戶端或者使用者來說,整個分散式網路檔案系統叢集看起來就像一個資源一樣。從其對檔案操作的情況看,MooseFS就相當於一個類UNIX檔案系統。
如何搭建MFS分散式檔案系統(二)
chunkServer資料儲存節點上的操作記錄 1)關閉防火牆(selinux也要關閉,執行setenforce 0) [[email protected] ~]# /etc/init.d/iptables stop 2)建立mfs使用者和組 [[email protec
如何搭建MFS分散式檔案系統
1什麼是分散式檔案系統? 是一個具有容錯性的網路分散式檔案系統,它將資料分散存放在多個物理伺服器或單獨磁碟或分割槽上,確保一份資料 有多個備份副本,對於訪問MFS的客戶端或者使用者來說,整個分散式網路檔案系統叢集看起來就像一個資源一樣,也就是說呈現給使用者的是一個統一的資源。