
白話文學強化學習-3
馬爾可夫決策模型
書接上回,上次說完了折扣率,最後的公式是
再整理下就是
接下來開始真是介紹馬爾可夫決策模型,以下簡稱MDP(Markov Decision Processes)
官方定義(來自百度百科):
馬爾可夫決策過程是基於馬爾可夫過程理論的隨機動態系統的最優決策過程。馬爾可夫決策過程是序貫決策的主要研究領域。它是馬爾可夫過程與確定性的動態規劃相結合的產物,故又稱馬爾可夫型隨機動態規劃,屬於運籌學中數學規劃的一個分支。
馬爾可夫決策過程是一個五元組
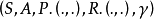
這裡多了兩個新面孔P(.,.),R(.,.),這裡一一解釋下,首先我們之前的代表這在時間序列t時獲得的獎勵這裡可以代表一個實數,但是在MDP中這個R需要改變下,因為當前時間序列t之所以能獲得獎勵是因為我們在時選擇了才產生了,但是當前下能選擇的未必只有一個動作可能有m個動作,那每一個m的動作都可能會產生不同的r,所以在MDP中R應該代表的是一個函式,入參是當前的state和選擇的action,返回的則是對應的獎勵,表示成,用程式碼翻譯的話
def 而新面孔P,則是狀態動作的轉移概率,也可以看成一個函式,即probability,完整的P應該是
同樣翻譯成程式碼的話
def P(state, action):
...
return the_probability_of_next_state_and_reward
P就比R複雜很多了,舉一個西瓜書上的例子:
家裡養了一株植物,植物的狀態S有3個缺水,健康,死亡 而我們的目標是培養一個智慧機器人學會怎麼去養活並且養好這株植物,那這個機器人能執行的動作就兩個一個是澆水,一個什麼都不做,所以MDP定義出來就會是:
R和P就比較複雜了
如果植物
當前狀態-》選擇的動作-》結果
缺水-》澆水-》80%健康 獎勵1 | 20%缺水 獎勵-1
缺水-》不澆水-》60%缺水 獎勵-1 | 40%死亡 獎勵-10
健康-》澆水-》50%健康 獎勵1 | 50%死亡 獎勵-10
健康-》不澆水 -》 80%健康 獎勵1 | 20% 缺水 獎勵-1
上述的概率都是我隨便假設的,僅僅是討論作用
而死亡是結束狀態,不需要P,因為到了這個狀態,當次的強化學習過程就結束了
那R和P換成上面的函式形態則是
=0.9
之所以公式會變成這樣就是因為在當前s下選擇一個動作a,轉移到下一個s’並不是一個100%確定的事情了,所以對應的獎勵r就會變成上面概率乘以獎勵之和。
以上就是MDP的五元組
今日總結:可以看出MDP裡最複雜的地方就是P,但是我們這個P從哪裡來呢?先不說,下回我們就要說到策略了,我們下回再見~
相關推薦
白話文學強化學習-3
馬爾可夫決策模型 書接上回,上次說完了折扣率γ\gammaγ,最後的公式是 Gt=Rt+1+γRt+2+γ2Rt+3+...+γn−1RnG_t=R_{t+1} + \gamma R_{t+2} +
白話文學強化學習系列
白話文學強化學習-0 由於本人也還只是菜鳥,希望大佬輕噴~ 老古話說的好,溫故而知新,決定把之前所學的感想記錄下來, 便於之後的複習瀏覽。由於本人語文不行,加之機器學習領域專業術語太多,所以想到用大
人工智障學習筆記——強化學習(3)蒙特卡洛方法
上一章我們瞭解了馬爾可夫決策過程的動態規劃方法,但是動態要求一個完全已知的環境模型,這在現實中是很難做到的。另外,當狀態數量較大的時候,動態規劃法的效率也將是一個問題。所以本章我們引用一種不需要完整的環境模型的方法概念——蒙特卡羅方法。蒙特卡洛是一個賭城的名字。又叫統計模擬方
白話文學強化學習-1
強化學習介紹 強化學習(reinforcement learning),又稱再勵學習、評價學習,是一種重要的機器學習方法,在智慧控制機器人及分析預測等領域有許多應用。 強化學習用人話來解釋的話,假設CV(計算機視覺)和NLP(自然語言處理)是教會計算機如何看和
強化學習 3—— 使用蒙特卡洛取樣法(MC)解決無模型預測與控制問題
## 一、問題引入 回顧上篇[強化學習 2 —— 用動態規劃求解 MDP](https://blog.csdn.net/november_chopin/article/details/107896549)我們使用策略迭代和價值迭代來求解MDP問題 #### 1、策略迭代過程: - 1、評估價值 (Eva
強化學習(David Silver)3:動態規劃
哈哈 avi 過程 來源 con 隨機 選擇 進行 解決 1、簡介 1.1、動態規劃 動態規劃的性質:最優子結構;無後向性 動態規劃假定MDP所有信息已知,解決的是planning問題,不是RL問題 1.2、兩類問題 預測問題:給定策略,給出MDP/MRP和策略,計算策略值
強化學習--綜述3之強化學習的分類
強化學習的分類 RL 演算法可以分為基於模型的方法(Model-based)與免模型的方法(Model-free)。 1)前者主要發展自最優控制領域。通常先通過高斯過程(GP)或貝葉斯網路(BN)等工具針對具體問題建立模型,然後再通過機器學習的方法或最優控制的方法,如模型預測控制
MIT6.S094深度學習與無人駕駛整理筆記(3)——————深度強化學習與運動規劃
1.一個神經元類似一個與非門,神經元電路與與非閘電路相比,可以執行與非門的操作,且還能學習由與非閘電路表示的任意的邏輯功能,並不需要人類工程師對其干涉,並還能進一步對其優化。 缺點:輸出不是很平滑不能用階躍函式,機器學習的過程一般是逐漸調整這些權值的過程,看他如何影響神經網
強化學習系列3:Open AI的baselines和Spinning Up
1. Baselines簡介 Baselines是一個傳統強化學習的資源庫,github地址為:https://github.com/openai/baselines Baselines需要python3的環境,建議使用3.6版本。安裝openmpi和相關庫(tensorflow、gym
強化學習導論(3)有限馬爾可夫決策過程
本章我們介紹有限馬爾可夫決策過程(Finite MDPs),這個問題和賭博機一樣涉及到評估的反饋,但這裡還多了一個方面--在不同的情況作出不同的選擇。MDPs是經典的序列判定決策模型,就是說,你不是作
【強化學習筆記】4.3 無模型的強化學習方法-蒙特卡羅演算法與重要性取樣
異策略與重要性取樣 因為異策略中的行動策略和目標策略不一樣,也就是說行動策略產生的資料分佈與目標策略的資料分佈存在偏差,即即行動策略的軌跡概率分佈和改善策略的軌跡概率分佈不一樣,因此在使用資料進行目標策略評估的時候需要考慮該影響,常用的方法是重要性取樣
強化學習 相關資源
ren info round count question posit pre tar tor 最近因為某個不可描述的原因需要迅速用強化學習完成一個小實例,但是之前完全不懂強化學習啊,雖然用了人家的代碼但是在找代碼的過程中還是發現了很多不錯的強化學習資源,決定mark下
maven學習3,如何創建一個web項目
eve sources ive put ear 類型 clear packaging pid Maven學習 (三) 使用m2eclipse創建web項目 1.首先確認你的eclipse已經安裝好m2eclipse的環境,可以參照上兩篇Maven學習
JS基礎學習3
++ pytho cat 代碼塊 return語句 控制語句 其他 實現 選擇 1.控制語句 (1)if控制語句 if-else基本格式 if (表達式){ 語句1; ...... }else{ 語句2; ..... } 功能說明 如果表達式的值為true則執行語句1,
docker學習(3)--Dockfile詳解
基於 環境 設置 多個 詳解 連接 當前 true truct 轉載請註明出處:http://www.cnblogs.com/lighten/p/6900556.html 1.基本說明 Dockfile是一個用於編寫docker鏡像生成過程的文件,其有特定的語法。在
TCP學習(3)--TCP釋放連接的過程(四次揮手)
出版 http tex div 發送 沒有 fonts 微笑 clas 一.TCP釋放連接的過程(四次揮手) TCP釋放連接的步驟例如以下圖所看到的。 如今如果clientA和server端B都處於數據傳送狀態。TCP連接斷開的過程例如以下: 1.c
ios網絡學習------3 用非代理方法實現異步post請求
erro form b2c enc 界面 關聯 error pre mut #pragma mark - 這是私有方法。盡量不要再方法中直接使用屬性,由於一般來說屬性都是和界面關聯的,我們能夠通過參數的方式來使用屬性 #pragma mark post登錄方法 -(v
【ES】學習3-請求體查詢
ext 組合 https 傳遞 guide should 學習 text class 1.空查詢 GET /index_2014*/type1,type2/_search {} GET /_search { "from": 30, "size": 10 }
機器學習--如何將NLP應用到深度學習(3)
關系 http 命令 構建 time 原理 最簡 gcc 復雜 數據收集以後,我們下面接著要幹的事情是如何將文本轉換為神經網絡能夠識別的東西。 詞向量 作為自然語言,只有被數學化才能夠被計算機認識和計算。數學化的方法有很多,最簡單的方法是為每個詞分配一個編號,這種
html學習3 首字母縮寫標簽
bsp title ec2 蘋果 style cnblogs his -c log <!doctype html> <html> <body style="background-color:#EC2B2E"> <h1>thi