
【模式匹配】更快的Boyer-Moore演算法
1. 引言
前一篇中介紹了字串KMP演算法,其利用失配時已匹配的字元資訊,以確定下一次匹配時模式串的起始位置。本文所要介紹的Boyer-Moore演算法是一種比KMP更快的字串匹配演算法,它到底是怎麼快的呢?且聽下面分解。
不同於KMP在匹配過程中從左至右與主串字元做比較,Boyer-Moore演算法是從模式串的尾字元開始從右至左做比較。下面討論的一些遞推式都與BM演算法的這個特性有關。
思想
首先,我們一般化匹配失敗的情況,設主串\(y\)、模式串\(x\)的失配位置為i+j與i,且主串、模式串的長度各為\(n\)與\(m\),如下圖:

已匹配上的字元結構:
\[ y[i+j+1 \dots j+m-1] = x[i+1 \dots m-1] \]
失配後下一次匹配時,模式串應如何對齊於主串呢?從上圖中看出,我們可以利用兩方面的資訊:
- 已經匹配上的字元結構,
- 主串失配位置的字元
前一篇中的KMP演算法只利用第一條資訊,而Boyer-Moore演算法則是將這兩方面的資訊都利用到了,故模式串的移動更為高效。同時,根據這兩方面資訊(已匹配資訊與失配資訊),Boyer-Moore演算法引申出來兩條移動規則:好字尾移動(good-suffix shift)與壞字元移動(bad-character shift)。
例項
Moore教授在這裡給出BM演算法一個例項,比如主串=HERE IS A SIMPLE EXAMPLE,模式串=EXAMPLE

在第一次匹配中,模式串在尾字元發生失配,而主串的失配字元為S,且S不屬於模式串的字元;因此下一次匹配時模式串指標應向右移動7位(壞字元移動)。第二次匹配如下圖:

第二次匹配也是在模式串尾字元發生失配,但不同的是主串的失配字元為P屬於模式串的字元;因此下一次匹配時模式串的P(從右開始第一次出現)應對齊於主串的失配字元P(壞字元移動)。第三次匹配如下圖:

在第三次匹配中,模式串的字尾MPLE完全匹配上主串,主串的失配字元為I,不屬於模式串的字元;那麼下一次匹配是模式串指標應怎麼移動呢(是壞字元移動,還是好字尾移動?)?BM演算法採取的辦法:移動步數=\(\max\{壞字元移動步數,\ 好字尾移動步數\}\)
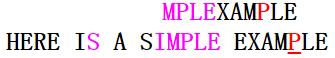
第四次匹配的情況與第二次類似,應按壞字元移動,第五次匹配(模式串與主串完全匹配)如下圖:
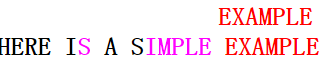
2. BM演算法詳述
好字尾移動
因已匹配上的字元結構正好為模式串的字尾,故名之為好字尾。好字尾移動一般分為兩種情況:
- 移動後,模式串有子串能完全匹配上好字尾;
- 移動後,模式串只有能部分匹配上好字尾的子串
我們用陣列bmGs[i]表示模式串的失配位置為i時好字尾移動的步數。第一類情況如下圖:

第二類情況如下圖:

接下來的問題是應如何計算bmGs[i]呢?我們引入suff函式,其定義如下:
\[ suff[i]=\max \{k:\ x[i-k+1\dots i]=x[m-k\dots m-1\},1\le i < m \]
表示了模式串中末字元為x[i]的子串能匹配模式串字尾的最大長度。其中,suff[i]=m。
對於第一類情況,令
i+1=m-suff[a],則x[i+1..m-1]=x[m-suff[a]..m-1];根據suff函式的定義,有x[m-suff[a]..m-1]=x[a-suff[a]-1..a];則x[i+1..m-1]=x[a-suff[a]-1..a],即可得到bmGs[i]=bmGs[m-suff[a]-1]=m-1-a。對於第二類情況,由字元的部分匹配可得
x[0..m-1-bmGs[i]]=x[bmGs[i]..m-1],即suff[m-1-bmGs[i]]=m-bmGs[i]。令m-bmGs[i]=a,有suff[a-1]=a。因為是部分匹配,故bmGs[i] = m-a > i+1,則i < m-a-1。綜上,當i < m-a-1且suff[a-1]=a時,bmGs[i]=m-a。有可能上述兩種情況都沒能被匹配上,則
bmGs[i]=m。
綜合上述三類情況,bmGs陣列計算的實現程式碼(參看[2]):
void preBmGs(char *x, int m, int bmGs[]) {
int i, j, suff[XSIZE];
suffixes(x, m, suff);
// case 3, default value
for (i = 0; i < m; ++i)
bmGs[i] = m;
j = 0;
// case 2
for (i = m - 1; i >= 0; --i)
if (suff[i] == i + 1)
for (; j < m - 1 - i; ++j)
if (bmGs[j] == m)
bmGs[j] = m - 1 - i;
// case 1
for (i = 0; i <= m - 2; ++i)
bmGs[m - 1 - suff[i]] = m - 1 - i;
}壞字元移動
壞字元移動是根據主串失配位置的字元y[i+j]而進行的移動。同樣地,我們用陣列bmBc[c]表示主串失配位置字元為c時壞字元移動的步數。壞字元移動一般分為兩種情況:
模式串
x[0..i-1]有字元y[i+j]且第一次出現,如下圖:
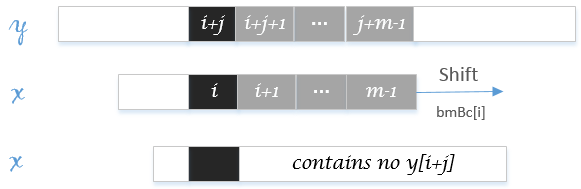
整個模式串都不包含該字串,如下圖:

據此,可以將bmBc[c]定義如下:
\[ bmBc[c]=\min \{i: 1\le i < m \ and \ x[m-1-i]=c \} \]
表示距模式串末字元最近的c字元;若c字元未出現在模式串中,則bmBc[c]=m。C實現程式碼:
void preBmBc(char *x, int m, int bmBc[]) {
int i;
for (i = 0; i < ASIZE; ++i)
bmBc[i] = m;
for (i = 0; i < m - 1; ++i)
bmBc[x[i]] = m - i - 1;
}suff函式計算
bmGs[i]的計算依賴於suff函式;如何更為高效的計算suff函式成為了接下來需要考慮的問題。符號標記的定義如下:
i表示當前位置;f記錄上一輪匹配的起始位置;g記錄上一輪匹配的失配位置。
這裡所說的匹配指的是與模式串字尾的匹配。同樣地,一般化匹配過程,如下圖:
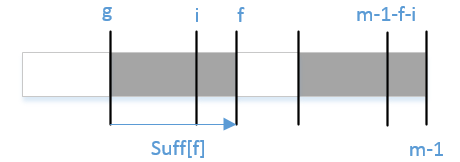
當g < i < f則必有x[i]=x[m-1-(f-i)]=x[m-1-f+i];
- 若
suff[m-1-f+i] < i-g,則suff[i]=suff[m-1-f+i]; - 否則,
suff[i]與suff[m-1-f+i]沒有關係,要根據定義進行計算。
C實現程式碼:
void suffixes(char *x, int m, int *suff) {
int f, g, i;
suff[m - 1] = m;
g = m - 1;
for (i = m - 2; i >= 0; --i) {
if (i > g && suff[i + m - 1 - f] < i - g)
suff[i] = suff[i + m - 1 - f];
else {
if (i < g)
g = i;
f = i;
while (g >= 0 && x[g] == x[g + m - 1 - f])
--g;
suff[i] = f - g;
}
}
}複雜度分析
3. 參考資料
相關推薦
【模式匹配】更快的Boyer-Moore演算法
1. 引言 前一篇中介紹了字串KMP演算法,其利用失配時已匹配的字元資訊,以確定下一次匹配時模式串的起始位置。本文所要介紹的Boyer-Moore演算法是一種比KMP更快的字串匹配演算法,它到底是怎麼快的呢?且聽下面分解。 不同於KMP在匹配過程中從左至右與主串字元做比較,Boyer-Moore演算法是從模式
【模式匹配】KMP演算法的來龍去脈
1. 引言 字串匹配是極為常見的一種模式匹配。簡單地說,就是判斷主串\(T\)中是否出現該模式串\(P\),即\(P\)為\(T\)的子串。特別地,定義主串為\(T[0 \dots n-1]\),模式串為\(P[0 \dots p-1]\),則主串與模式串的長度各為\(n\)與\(p\)。 暴力匹配 暴力匹配
【模式匹配】Aho-Corasick自動機
1. 多模匹配 AC自動機(Aho-Corasick Automaton)是多模匹配演算法的一種。所謂多模匹配,是指在字串匹配中,模式串有多個。前面所介紹的KMP、BM為單模匹配,即模式串只有一個。假設主串\(T[1 \cdots m]\),模式串有k個\(\mathbb{P} = \{ P_1, \cdot
【模式匹配】之 —— KMP演算法詳解及證明
本文所述KMP演算法原始碼可在這裡下載: Name Date Reason for change Revision 超然 2013.03.19 First version 1.0 超然 2013.04.15 Added
【圖片匹配】--- SIFT_Opencv3.1.0_C++_ubuntu
文件 read 等待 s2d imread mage clas create detect 最近在搗鼓圖片相似性匹配算法。這裏先說一點必要的題外話: 如果是在同一個object不同角度拍攝的多張圖片中,使用SIFT可以有不錯的效果; 如果是尋找類別相同的圖片(可能不是同
PHP PC端微信掃碼支付【模式二】詳細教程-附帶源碼(轉)
idt class pid 方法 按鈕 -c 商戶 開源 玩意兒 博主寫這破玩意兒的時候花了大概快兩天時間才整體的弄懂邏輯,考慮了一下~還是把所有代碼都放出來給大家~抱著開源大無私的精神!誰叫我擅長拍黃片呢?同時也感謝我剛入行時候那些無私幫過我的程序員們! 首先還是
CF 612C. Replace To Make Regular Bracket Sequence【括號匹配】
pos cal set while ostream problem \n push || 【鏈接】:CF 【題意】:給你一個只含有括號的字符串,你可以將一種類型的左括號改成另外一種類型,右括號改成另外一種右括號 問你最少修改多少次,才能使得這個字符串匹配,輸出次數 【分析】
【POJ - 2226】Muddy Fields(匈牙利演算法 或 網路流dinic,二分圖匹配,最小點覆蓋,矩陣中優秀的建圖方式 )
題幹: Rain has pummeled the cows' field, a rectangular grid of R rows and C columns (1 <= R <= 50, 1 <= C <= 50). While good for the gra
【模式分解】無損連線&保持函式依賴
首先引入定義 無損分解指的是對關係模式分解時,原關係模型下任一合法的關係值在分解之後應能通過自然聯接運算恢復起來。反之,則稱為有損分解。 保持函式依賴的分解指的是對關係分解時,原關係的閉包與分解後關係閉包的並集相等。
POJ 3189 Steady Cow Assignment 【二分】+【多重匹配】
<題目連結> 題目大意: 有n頭牛,m個牛棚,每個牛棚都有一定的容量(就是最多能裝多少隻牛),然後每隻牛對每個牛棚的喜好度不同(就是所有牛圈在每個牛心中都有一個排名),然後要求所有的牛都進牛棚,牛棚在牛心中的排名差計算方法為:所有牛中最大排名和最小排名之差+1(包括區間端點)。問最小的排名差。
織夢熊掌號外掛,dedecms如何接入熊掌號API提交功能【完美匹配】
百度熊掌號是內容和服務提供者入駐百度生態的認證賬號,致力於幫助內容和服務提供者便捷、高效地連線全網使用者,並充分利用百度生態開放的優勢,獲取流量、沉澱使用者、塑造品牌,實現自身價值的快速增長。 這裡我們只是使用了他的搜尋資源平臺的入口,提供我們網站資源。具體還要資料開放平臺
Bailian2976 Bailian1936 All in All【字串匹配】
2976:All in All 描述 給定兩個字串s和t,請判斷s是否是t的子序列。即從t中刪除一些字元,將剩餘的字元連線起來,即可獲得s。 輸入 包括若干個測試資料。每個測試資料由兩個ASCII碼的數字和字母串s和t組成,s和t的長度不超過100000。 輸出 對每個測試資料,如果s是t的子序列則輸出“Ye
【GDAL學習】更多柵格資料處理函式——滑動視窗與過濾器
例如設計一個3 x 3的滑動視窗,寫演算法執行就有兩種方式: 1.pixel by piexl每個進行逐畫素運算,效率太低,速度慢 2.使用 slice切片形式迴圈,效率高,速度快 兩個作業就是分別用pixel和slice方式完成高通濾波操作進行對比 1.As
資料結構——使用Java棧實現【括號匹配】
給定一個只包括 '(',')','{','}','[',']'的字串,判斷字串是否有效。 有效字串需滿足: 左括號必須用相同型別的右括號閉合。 左括號必須以正確的順序閉合。 注意空字串可被認為是有效字串。 參考leetcode.com或leetcode-cn.com
【立體匹配】Stereo Processing by Semiglobal Matching and Mutual Information(SGM)
Stereo Processing by Semiglobal Matching and Mutual Information 基於半全域性匹配和互資訊的立體處理 Stereo Processing by Semiglobal Matching and Mu
【特徵匹配】Harris及Shi-Tomasi原理及原始碼解析
演算法原理:呼叫cornerMinEigenVal()函式求出每個畫素點自適應矩陣M的較小特徵值,儲存在矩陣eig中,然後找到矩陣eig中最大的畫素值記為maxVal,然後閾值處理,小於qualityLevel*maxVal的特徵值排除掉,最後函式確保所有發現的角點之間具有足夠的距離。void cv::goo
【字串匹配】【BKDRhash||KMP】
題目描述 給定一個字串 A 和一個字串 B ,求 B 在 A 中的出現次數。A 和 B中的字元均為英語大寫字母或小寫字母。 A 中不同位置出現的 B 可重疊。 輸入格式 輸入共兩行,分別是字串 A 和字串 B 。 輸出格式 輸出一個整數,表示 B 在 A 中的出現次數。
【模式識別】SVM核函式
以下是幾種常用的核函式表示:線性核(Linear Kernel)多項式核(Polynomial Kernel)徑向基核函式(Radial Basis Function)也叫高斯核(Gaussian Kernel),因為可以看成如下核函式的領一個種形式:徑向基函式是指取值僅僅依
【模式識別】Fisher線性判別
Fisher是一種將高維空間對映到低維空間降維後進行分類的方法 1.投影: 對xn→的分量作線性組合可得標量 yn=w⃗ Txn→ 什麼樣的對映方法是好的,我們需要設計一個定量的標準去找w⃗ 來
【模式識別】Boosting
Boosting簡介分類中通常使用將多個弱分類器組合成強分類器進行分類的方法,統稱為整合分類方法(Ensemble Method)。比較簡單的如在Boosting之前出現Bagging的方法,首先從從整體樣本集合中抽樣採取不同的訓練集訓練弱分類器,然後使用多個弱分類器進行vo