
老白聊資料-關於銷售預測的那些事
小白混跡了幾年,現在是個老白了,看似啥玩意都懂點,啥玩意也都不精通,今天和大家說的是關於銷售預測的那些事,因為最近看了JDD大賽,也和幾個參賽隊員交流,有些有意思的想法,和大家分享一下。
最近在關注京東金融舉辦的JDD大賽,這個比賽比較有意思。大賽也是分了幾道賽題,比如豬臉識別,信貸需求預測,店鋪銷售預測,登入行為識別,總的而言,比較貼近業務實際使用場景。比賽也是分了演算法組和商業組,演算法組是純粹的PK演算法的效果,而商業組,除了完成演算法的構建和評分排名,進入決賽的隊伍還要寫作BP,構建一個基於賽題基礎的商業模型。總體說,從京東金融的業務需要出發,本身題目具備商業價值,具體賽題資訊如下圖:
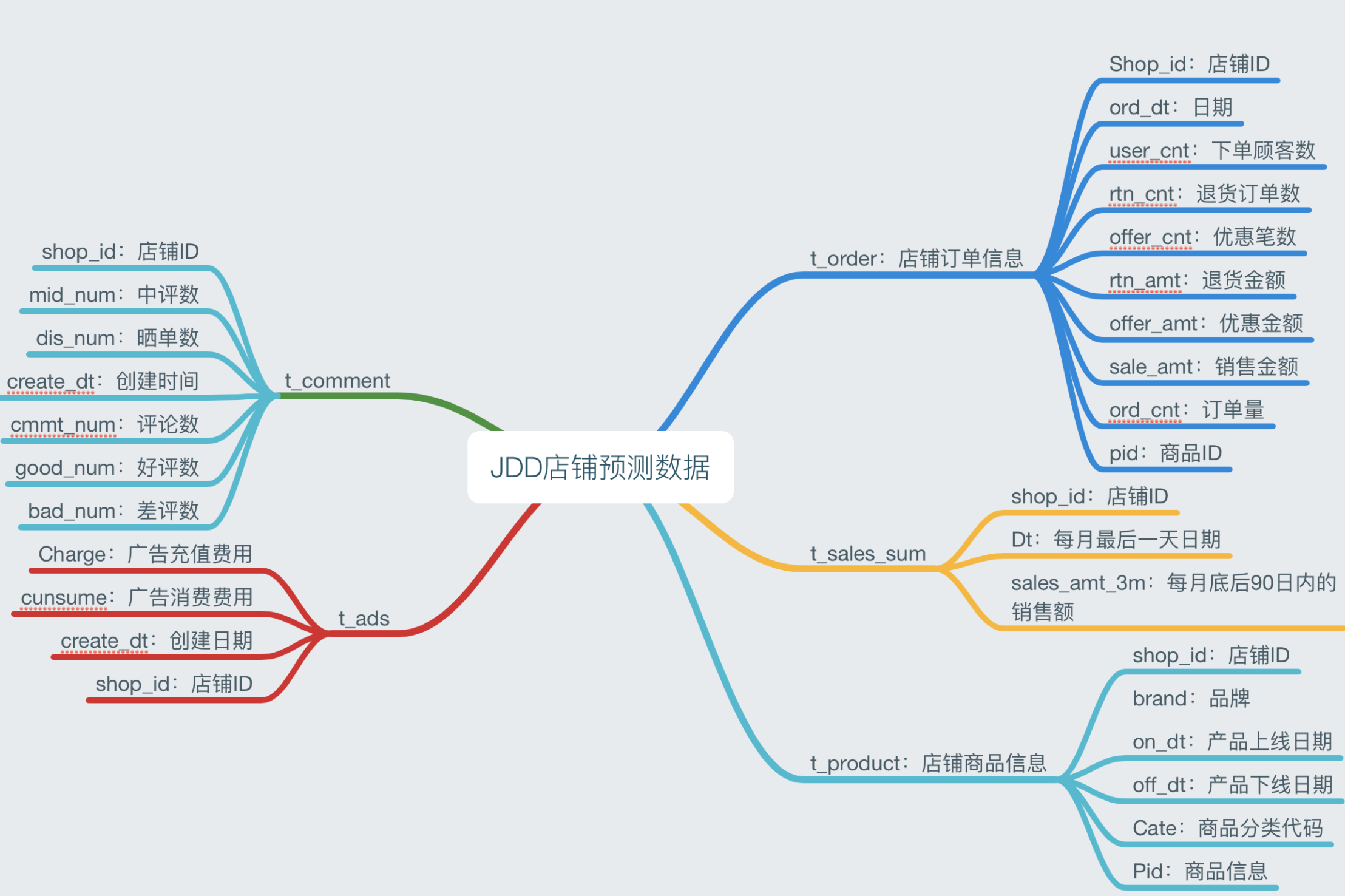
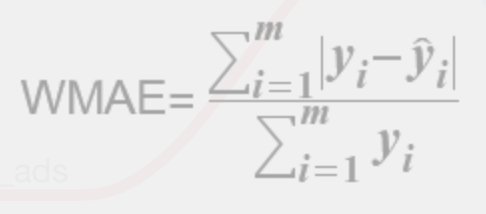 換句話說,誰的得分越低,就是誤差更小,誰的預測效果更好。
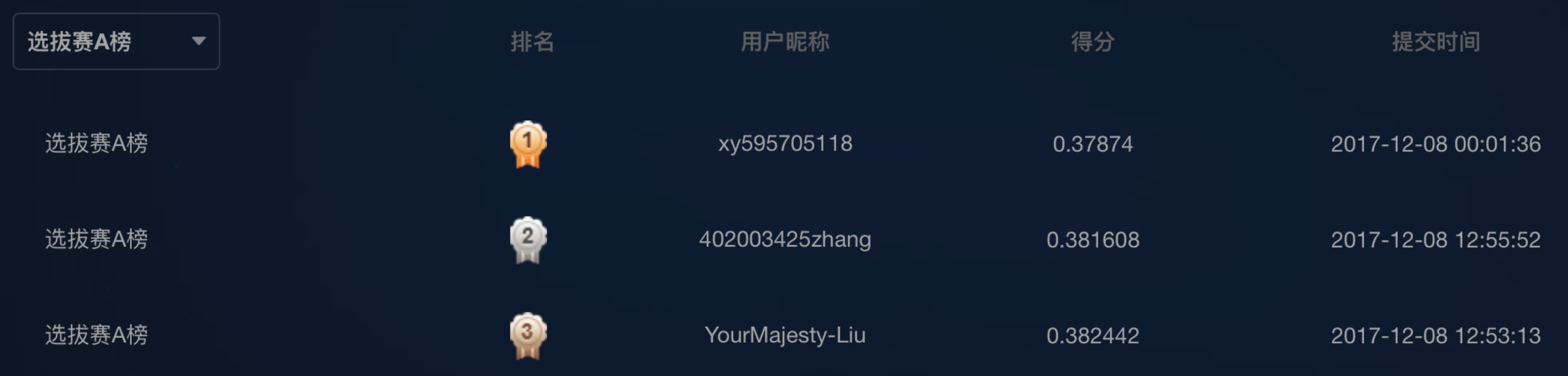
我查看了店鋪銷售預測商業組的排行榜,發現了一些有意思的事情,你會看到大家的得分基本沒有拉開差距,第一名是0.393,而第三名是0.3945,也就是說大家在方法使用上,或者資料理解上,基本上差異性很小。可能在具體的嘗試過程中,由於資料的準備不同,帶來了一些細微差異,換句話這個榜單前三名的隨機性很強,基本沒什麼差別。我們並沒有看到出現那種差距極大的隊伍出現。即使我們去看演算法組的第一名得分也只是0.37。
商業組前10名得分
換句話說,誰的得分越低,就是誤差更小,誰的預測效果更好。
我查看了店鋪銷售預測商業組的排行榜,發現了一些有意思的事情,你會看到大家的得分基本沒有拉開差距,第一名是0.393,而第三名是0.3945,也就是說大家在方法使用上,或者資料理解上,基本上差異性很小。可能在具體的嘗試過程中,由於資料的準備不同,帶來了一些細微差異,換句話這個榜單前三名的隨機性很強,基本沒什麼差別。我們並沒有看到出現那種差距極大的隊伍出現。即使我們去看演算法組的第一名得分也只是0.37。
商業組前10名得分

 那這個基本可以忽略的差距說明了什麼問題,為什麼沒有出現一騎絕塵的隊伍,對此我們此時需要回到這道題目本身來思考。
首先銷售預測問題的一些成熟演算法和模型,我們不需要多言,你是時間序列也好,還是ARIMA,LR,BPNN也罷,總的說演算法就那麼多,想解決這個問題,是無法脫離這些的。那麼為什麼預測的水平上不去,仍舊高達30%的誤差?其實在官方給出的資料中,貌似給定了一定的預測所使用資料的邊界,也許資料本身就代表了這道題目的侷限性。
我們會發現,官方給出來的用於預測的資料中,涵蓋了廣告充值,評論,上下架時間的資料。似乎想從這個資料方面,來極限考驗參賽團隊的演算法和資料準備實力。
但是再換一個維度思考,也許這是京東認為的對於銷售預測相對有用的維度資料,當然了也涵蓋部分商品資訊,比如品牌和分類,似乎從中都是要找到與銷售數字的相關性,進而提升預測準確性,不過我們發現商品相關資訊,也只是關於品類這樣維度的資料。
從銷售預測本身來看,如果我們繪製一條某店鋪銷售曲線,我們會發現,頭部有一兩件商品的銷售佔比很高,二其他很多產品銷售佔比很低,或者是我們將店鋪商品進行歸類,某一類商品可能佔據極高的銷售數字。這就是我們以前總提到的一個20/80原則,也叫做帕累托法則,也就是20%的人貢獻80%的業績。在這個資料中,其實這種情況也存在,比如少數商品貢獻多數收入的問題,少數店鋪貢獻多數收入。因此,在預測時,20/80原則實際上也是一種預測問題的處理思路,少數店鋪的銷售貢獻依賴少數商品,當然也依賴廣告或者評論的影響。不過從目前大家的分看,也許這幾個因素的權重總計在60%左右。
那麼剩下40%的因素在哪裡?因為理論上,我們的得分是0才對。
在這裡和大家的討論是如何提高預測準確率的一種思考,換句話,也是尋找40%的因素的一種思路。
首先把銷售預測問題換個角度來看,就是判斷消費者購買的意願高低,再細緻來看,就是消費者的購買動機或者購買決策的判斷,一旦找到那個準確的相關度最高的動機,那麼就意味著,銷售的預測精度就會大幅度提升。從初賽這些人員的預測結果看,以現有的演算法,意味著這些因素與購買動機的的相關度,僅限於這個得分了。
我們之前用於銷售預測的資料考慮了營銷因素(廣告),社交因素(評論),商品開發(上下架時間),但我們發現這些都是巨集觀因素,但是今天的消費者慢慢趨於理性,會考慮評論因素,也會貨比三家,儘管價格還是一個很重要的因素。
但是我們發現作用很大的評論資料,在這裡,被官方處理為正面評論,中性評論,負面評論,得說一句,這種資料的處理在資料集開放之前就做好了用1,0,-1來代替,但是對於語義的處理,劃分三類標籤,會出現一些偏差,畢竟如何理解正面,中性,負面,這個人的經驗是不同的。這或許是本賽題中一個思考的方向。
不過如果排除這個因素我們會發現,似乎還是無法說明誤差為什麼很大,這時我們需要跳出來看,我們似乎忘記了很多的微觀因素,比如商品本身的品質,引數,元素,顏色等等,這些不起眼的東西,也許正是最重要的驅動消費者購買的最重要動機。
在銷售預測問題上,如果我們能夠挖掘到使用者購買的微觀動機,也就是商品本身是否具備潛力和暢銷特性,那麼就能很好的捕捉到店鋪的經營狀態。
回看這道比賽題目,我們是要完成對未來的預測,所以我們要掌握到未來的除了營銷計劃,還有本身商品的屬性,未來的空間,當你能夠精準捕捉到哪些商品能夠具備爆款屬性時,就意味著,你看到了80%的銷售收入機會,同時,基於微觀商品的屬性,我們也會挖掘到哪些商品是滯銷的,是不適合進行推廣和上架的。對店鋪的授信同時,對於店鋪的經營,如果能夠形成的有效干預,則未來的雙向合作業務基礎才紮實。
簡單說,我們需要進行商品本身DNA的拆解,找到那些重要的影響購買的元素,而一旦捕捉到,則意味著,我們能夠掌握的潛力和經營方向可以更加明確。這個可以舉個例在,比如服飾行業,我們可以對一一件衣服進行解構,比如版型,面料,圖案,型別,風格,季節等,基於這些潛藏在衣服中的要素,進行從微觀元素組合起來的預測分析,尋找爆款元素和相對應的產品,因為這些控制了較大的銷售份額,同時那些滯銷的元素也能尋找出來,並且可以進行防範和處理,減少不必要的損失。
當然銷售預測的問題,我們都預測的是未來,如果在開始我們能夠提供未來可以很好銷售的產品,那麼銷售的預測也將迎刃而解。這看似是廢話,其實,當中我們會發現怎麼找到爆款產品,如何挖掘爆款,就潛藏在我們已有的資料之中。
而整體銷售的預測,除了巨集觀因素的配合,這些內在微觀因素則是基礎,因為他們是構成消費者購買的驅動力之一,而每個商品的精準捕捉銷售可能性,也就計算出來整體的銷售可能性。
最後再說一點的是,其實你看評論資料,我們不能簡單的歸結成1,0,-1,消費者的評論中隱藏了很多對於產品某一方面的鐘愛或者厭惡,而這恰恰是其他消費群體看到後,是否產生驅動力購買的關鍵,以此出發,我們剛才的思路就可以順下來。
關於銷售預測的問題,今天就聊這麼多。
如果大家感興趣交流,可以加微訊號:i-analysis,繼續交流
那這個基本可以忽略的差距說明了什麼問題,為什麼沒有出現一騎絕塵的隊伍,對此我們此時需要回到這道題目本身來思考。
首先銷售預測問題的一些成熟演算法和模型,我們不需要多言,你是時間序列也好,還是ARIMA,LR,BPNN也罷,總的說演算法就那麼多,想解決這個問題,是無法脫離這些的。那麼為什麼預測的水平上不去,仍舊高達30%的誤差?其實在官方給出的資料中,貌似給定了一定的預測所使用資料的邊界,也許資料本身就代表了這道題目的侷限性。
我們會發現,官方給出來的用於預測的資料中,涵蓋了廣告充值,評論,上下架時間的資料。似乎想從這個資料方面,來極限考驗參賽團隊的演算法和資料準備實力。
但是再換一個維度思考,也許這是京東認為的對於銷售預測相對有用的維度資料,當然了也涵蓋部分商品資訊,比如品牌和分類,似乎從中都是要找到與銷售數字的相關性,進而提升預測準確性,不過我們發現商品相關資訊,也只是關於品類這樣維度的資料。
從銷售預測本身來看,如果我們繪製一條某店鋪銷售曲線,我們會發現,頭部有一兩件商品的銷售佔比很高,二其他很多產品銷售佔比很低,或者是我們將店鋪商品進行歸類,某一類商品可能佔據極高的銷售數字。這就是我們以前總提到的一個20/80原則,也叫做帕累托法則,也就是20%的人貢獻80%的業績。在這個資料中,其實這種情況也存在,比如少數商品貢獻多數收入的問題,少數店鋪貢獻多數收入。因此,在預測時,20/80原則實際上也是一種預測問題的處理思路,少數店鋪的銷售貢獻依賴少數商品,當然也依賴廣告或者評論的影響。不過從目前大家的分看,也許這幾個因素的權重總計在60%左右。
那麼剩下40%的因素在哪裡?因為理論上,我們的得分是0才對。
在這裡和大家的討論是如何提高預測準確率的一種思考,換句話,也是尋找40%的因素的一種思路。
首先把銷售預測問題換個角度來看,就是判斷消費者購買的意願高低,再細緻來看,就是消費者的購買動機或者購買決策的判斷,一旦找到那個準確的相關度最高的動機,那麼就意味著,銷售的預測精度就會大幅度提升。從初賽這些人員的預測結果看,以現有的演算法,意味著這些因素與購買動機的的相關度,僅限於這個得分了。
我們之前用於銷售預測的資料考慮了營銷因素(廣告),社交因素(評論),商品開發(上下架時間),但我們發現這些都是巨集觀因素,但是今天的消費者慢慢趨於理性,會考慮評論因素,也會貨比三家,儘管價格還是一個很重要的因素。
但是我們發現作用很大的評論資料,在這裡,被官方處理為正面評論,中性評論,負面評論,得說一句,這種資料的處理在資料集開放之前就做好了用1,0,-1來代替,但是對於語義的處理,劃分三類標籤,會出現一些偏差,畢竟如何理解正面,中性,負面,這個人的經驗是不同的。這或許是本賽題中一個思考的方向。
不過如果排除這個因素我們會發現,似乎還是無法說明誤差為什麼很大,這時我們需要跳出來看,我們似乎忘記了很多的微觀因素,比如商品本身的品質,引數,元素,顏色等等,這些不起眼的東西,也許正是最重要的驅動消費者購買的最重要動機。
在銷售預測問題上,如果我們能夠挖掘到使用者購買的微觀動機,也就是商品本身是否具備潛力和暢銷特性,那麼就能很好的捕捉到店鋪的經營狀態。
回看這道比賽題目,我們是要完成對未來的預測,所以我們要掌握到未來的除了營銷計劃,還有本身商品的屬性,未來的空間,當你能夠精準捕捉到哪些商品能夠具備爆款屬性時,就意味著,你看到了80%的銷售收入機會,同時,基於微觀商品的屬性,我們也會挖掘到哪些商品是滯銷的,是不適合進行推廣和上架的。對店鋪的授信同時,對於店鋪的經營,如果能夠形成的有效干預,則未來的雙向合作業務基礎才紮實。
簡單說,我們需要進行商品本身DNA的拆解,找到那些重要的影響購買的元素,而一旦捕捉到,則意味著,我們能夠掌握的潛力和經營方向可以更加明確。這個可以舉個例在,比如服飾行業,我們可以對一一件衣服進行解構,比如版型,面料,圖案,型別,風格,季節等,基於這些潛藏在衣服中的要素,進行從微觀元素組合起來的預測分析,尋找爆款元素和相對應的產品,因為這些控制了較大的銷售份額,同時那些滯銷的元素也能尋找出來,並且可以進行防範和處理,減少不必要的損失。
當然銷售預測的問題,我們都預測的是未來,如果在開始我們能夠提供未來可以很好銷售的產品,那麼銷售的預測也將迎刃而解。這看似是廢話,其實,當中我們會發現怎麼找到爆款產品,如何挖掘爆款,就潛藏在我們已有的資料之中。
而整體銷售的預測,除了巨集觀因素的配合,這些內在微觀因素則是基礎,因為他們是構成消費者購買的驅動力之一,而每個商品的精準捕捉銷售可能性,也就計算出來整體的銷售可能性。
最後再說一點的是,其實你看評論資料,我們不能簡單的歸結成1,0,-1,消費者的評論中隱藏了很多對於產品某一方面的鐘愛或者厭惡,而這恰恰是其他消費群體看到後,是否產生驅動力購買的關鍵,以此出發,我們剛才的思路就可以順下來。
關於銷售預測的問題,今天就聊這麼多。
如果大家感興趣交流,可以加微訊號:i-analysis,繼續交流
相關推薦
老白聊資料-關於銷售預測的那些事
小白混跡了幾年,現在是個老白了,看似啥玩意都懂點,啥玩意也都不精通,今天和大家說的是關於銷售預測的那些事,因為最近看了JDD大賽,也和幾個參賽隊員交流,有些有意思的想法,和大家分享一下。 最近在關注京東金融舉辦的JDD大賽,這個比賽比較有意思。大賽也是分了幾道賽題,比如豬臉識別,信貸需求預測,店鋪銷售預測,
老白聊資料-為什麼你的營銷總是沒有效?
最近在反覆思考資料分析的價值究竟該如何落地,這個問題,其實大家都在反覆追問很多行業大咖,也在不斷嘗試實踐。 對我來說,我覺得資料分析在企業中的應用無非就是三個方面:營銷,風險,經營。 通俗的講,營銷更多是面向客群運營的最後一步,基本上是圍繞場景和客群展開的; 風險,則是解決如何降低成本,控制不必要的浪費
聊一聊整車廠的那些事——售後配件業務
大於 狀況 mil 協作 正文 現狀 ESS 大數 沒有 此文已由作者王文開授權網易雲社區發布。歡迎訪問網易雲社區,了解更多網易技術產品運營經驗。前言:本文主要介紹了整車廠售後配件業務的整體狀況和痛點,並且展示了網易有數是如何助力整車廠的售後部門,發現其業務問題、定位問題、
取得十分鐘內、一小時內、一天內 的資料 « 關於網路那些事...
MySQL 取得指定分鐘、指定小時或指定天數內的資料 方式介紹: 取得10分鐘內的資料 SELECT * FROM `members` WHERE `last_
Android 程序保活資料彙總與華為白名單那些事
現在發現App在後臺執行越來越難了。App在華為手機後臺死的非常快,之前看網上說華為有白名單,網上也通過改包名的方式來驗證了。但是半信半疑的,直到諮詢了華為的客服給了一個郵箱 [email protected],回覆的資料 應用加白名單簡化流程v0.1
誰說顏值與實力不能並存?3.14最美女神入駐TechNeo,邀你一起聊AI與區塊鏈那些事
AI 區塊鏈 盼望著盼望著,春天來了,白色 情人節的腳步近了。轟趴派對必然少不了美女大咖駕到,她們不僅貌美如花,才華橫溢,最重要的是,在 區塊鏈、人工智能 這些熱門領域,都是響當當的行家!2018,讓我們玩兒點兒不一樣的最美女神Party,What?搞事情?Part one 女神拋出話題女神大咖會在
香港資料中心你不知道的那些事
香港資料中心 越來越多企業轉向雲端計算,以支援其數字化轉型專案的創新,並在競爭中保持領先地位。根據分析公司IDC的資料,全球公共雲服務和基礎設施支出預計今年將達到1600億美元,並在2021年增加到2770億美元。在這數字化轉型的時代裡,由於成本效益、彈性擴充套件性以及廣泛的功能範圍,雲的吸引力很容易理
資料顯示格式設定那些事
資料庫中儲存的資料通常會有一些程式碼值欄位,如員工編號、部門程式碼、類別 ID 等等,報表展示時如果直接展示程式碼值形式,使用人員無法理解該值的具體含義,所以要求將編碼值轉換成對應的使用人員能夠理解的中文形式,又或者資料庫中儲存的出生日期是 date 形式,展現時要將其轉換成標準的 2018 年 1
資料結構與演算法的那些事
先佔坑,再補充。 常用演算法: (1)排序:快排、歸併排序、插入排序、希爾排序、桶排序; (2)分治演算法(divide-and-conquer),回溯演算法,貪婪演算法,動態規劃(DP); (3)二分查詢(binary search); 一、排序演算法 演
資料採集與分析的那些事——從資料埋點到AB測試
作者:網易有數鄭棟。 一、為什麼企業需要一套完善的使用者行為埋點和分析平臺 產品初創期間,需要分析天使使用者的行為來改進產品,甚至從使用者行為中得到新的思路或發現來調整產品方向;產品成長過程,通過對使用者行為的多角度(多維)分析、對使用者群體的劃分以及相應行為特徵的分析和比較,來指導產品設計、運營活動,並
JAVA小白的進擊之路!!!2018.11.05日 關於java序列化的那些事
2018.11.05 序列化:把物件轉換為位元組序列 反序列換:把在位元組序列轉換為物件 用途:1、把物件的位元組序列永久的儲存在硬碟中,通常存放在一個檔案中。 2、在網路上傳送物件的位元組序列 案例:web伺服器中的session物件,當有10萬用戶併發
資料搬遷,從GCP Storage 遷移到阿里雲儲存(OSS) « 關於網路那些事...
通常在建構系統中,擴充新服務,在遷移過程,有時會需要將雲端資料進行搬移 最近剛好一個系統需要將GCP上面的Storage資料遷移到阿里雲OSS 在這裡做一個紀錄
python資料分析:商品資料化運營(中)——基於引數優化的Gradient Boosting的銷售預測
本案例需要使用超引數交叉檢驗和優化方法GridSearchCV以及整合迴歸方法GradientBoostingRegressor GridSearchCV與GradientBoostingRegressor GridSearchCV GridSearchCV用於系統地遍歷多種
資料傳輸方式 « 關於網路那些事...
資料傳輸方式紀錄 資料傳輸常見Json, XML 的方式傳送,但這裡我們要說明的是在細節一點的格式傳輸方式 Byte 格式傳輸 一般各種格式的資料,傳輸前都必須轉為
資料結構中單鏈表的那些事
在面試中面試資料結構中關於連結串列的基本操作,從未到頭列印單鏈表、逆置\翻轉單鏈表、合併兩個有序連結串列,合併後連結串列依然有序、查詢單鏈表的中間結點,只能遍歷一次單鏈表、刪除連結串列的倒數第K個結點,要求只能遍歷一次單鏈表等連結串列的操作,都是面試中常考題,所
【資料庫】load data infile上億條的海量資料匯入mysql的那些事
因為做股票金融的,每天產生的資料量是很大的,一個月幾十億的交易記錄,也常有出現,特別是今年大跌之前大漲那會。 作為程式設計師,問題來了,有時需要將一些並不是特別符合規範的csv檔案匯入資料庫中,而且每個檔案有十幾萬行,而這樣的檔案幾萬個,於是幾十億的記錄如何匯入資料庫呢?
資料檔案offline 時oracle 幹了那些事?
SQL> oradebug setmypid Statement processed. SQL> oradebug unlimit Statement processed. SQL> oradebug event 10046 trace name co
安卓實戰開發之JNI從小白到偽老白深入瞭解JNI動態註冊native方法及JNI資料使用
前言 或許你知道了jni的簡單呼叫,其實不算什麼百度谷歌一大把,雖然這些jni絕大多數情況下都不會讓我們安卓工程師來弄,畢竟還是有點難,但是我們還是得打破砂鍋知道為什麼這樣幹吧,至少也讓我們知道呼叫流程和資料型別以及處理方法,或許你會有不一樣的發現。
聊一聊高併發高可用那些事 - Kafka篇
> **目錄**  > **為什麼需要訊息佇列** 1.非同步 :一個下單流程,你需要扣積分,扣優惠卷,發簡訊等,有些耗時又不需要
哈夫曼編碼(Huffman coding)的那些事,(編碼技術介紹和程序實現)
信號 truct 依次 while 交換 需要 .text 示例 system 前言 哈夫曼編碼(Huffman coding)是一種可變長的前綴碼。哈夫曼編碼使用的算法是David A. Huffman還是在MIT的學生時提出的,並且在1952年發表了名為《