
醫療鏈的系列談 第一篇 基本概念研究
摘要:本文從醫聯體的概念和現狀出發,進行了一些分析,並結合工業自動化中的PID原理,提出了醫療鏈的概念。醫療鏈包含4大部分:測量、分析、執行、迴圈。其中測量、分析、執行組成一個迴圈體,然後使用反饋機制不斷的執行迴圈,將醫療行為中的被動迴圈轉換為主動迴圈,提高醫療系統執行力。本文還深入討論了醫療鏈中的測量部分,分析了測量過程中的資料輸入、資料校驗、資料標準化和資料儲存,還引出了資料資產的概念。
關鍵字:醫聯體 醫療鏈 PID
一、引言
醫聯體是中國醫療行業近期發展的一個熱點,不少地方在進行相關的試點。在實踐中有了一些經驗和教訓。本文從醫聯體開始討論,借鑑其他社會行業的發展實踐,最終形成醫療鏈的概念,並討論一些資訊化技術手段在其過程中的作用。希望對醫聯體的發展提供一些參考意見。
二、醫聯體
首先說明一下醫聯體的概念,[1]根據百度百科說明:醫聯體是將同一個區域內的醫療資源整合在一起,由一所三級醫院,聯合若干所二級醫院和社群衛生服務中心組成,目的是引導患者分層次就醫,而非一味湧向三甲醫院。
在理想情況下,醫聯體在資源配置上是最優的,其分析如下:
對於三級醫院,醫療能力強大,床位緊張,需要將床位優先供應給危急重大疾病患者,而醫聯體能提供一種渠道,將病情穩定的病人順利移動到中小醫院,這樣能騰出床位;同時也能讓醫院的單床位日收入長期保持高位。
對於中小醫院,醫聯體機制能提供比較穩定的病人來源,提高床位使用率。
對於患者來說,可以保證療效的情況下逐漸降低醫療費用,而且在轉院時會選擇離家近的中小醫院,方便患者家屬的交通。
這種三方都得利的情況下,如果醫院像企業一樣是自由市場競爭的,則醫聯體無需政府推動就能自發的實現和普及。不過根據筆者瞭解,現行的醫聯體尚未產生預期的效果,原因很多。在此筆者借鑑其他社會行業的發展實踐,並根據醫療行業的特點,提出一種醫療鏈的概念,試圖啟用醫聯體,使其充分的發揮其應有的作用。
三、醫療鏈
筆者試著給醫療鏈下個定義:指病人從發病到康復,其各個診療環節始終處於可測量的環境下,大部分環節可控制可回溯,而且環節之間資訊無縫交通,這裡的環節所在地區不限於醫院,可以是病人家庭或者工作地點;而且各個環節聯合起來,形成迴圈反饋機制。這樣可以提高整個醫療體系的運作效率,實現其經濟社會效益最大化。
在這個定義中,最核心的就是迴圈反饋機制,首先說明這個機制。
在工業自動化中,迴圈反饋機制是其基礎,最常見的就是PID控制。[1]反饋理論的要素包括三個部分:測量、比較和執行。測量關心的變數,與期望值相比較,用這個誤差糾正調節控制系統的響應。圖1就是PID控制的原理圖:

圖1 PID原理圖
對醫療過程,我們也可以借鑑PID的思想,採用迴圈的機制,每個迴圈中都包含了測量、分析和執行。實際上也是發現問題、分析問題、解決問題這種樸素的生活哲學的體現。圖2為筆者對醫療鏈設計的架構圖:
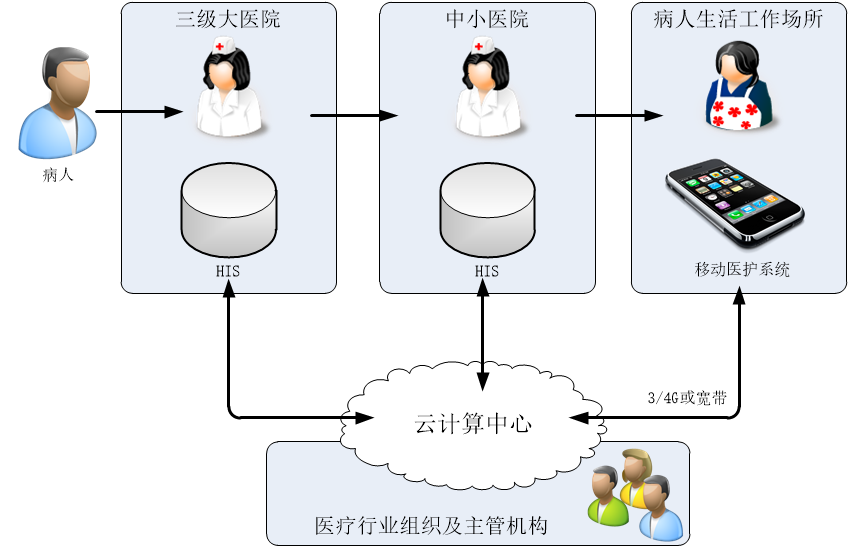
圖2 醫療鏈架構圖
醫療鏈包含4大部分:測量、分析、執行、迴圈。
測量大體就是檢查檢驗,分析大體就是下診斷,執行大體就是下醫囑執行醫囑,迴圈就是上述過程執行一遍又一遍。
醫療鏈需要實現一個閉合迴圈,不斷地測量、分析、執行。目前醫療過程中存在著被動迴圈,也就是生病了病人才被動的去醫院進行測量、分析、執行,病好了就沒啥動作。下次生病了又被動迴圈一遍。
而醫療鏈應該執行主動迴圈,也就是即使沒有病或病情穩定的時候也要主動測量、分析、執行。從被動迴圈到主動迴圈,可以說體現了從治病到治未病的醫療健康理念。
整個醫療鏈內容比較巨集大,限於篇幅,本文只從資訊化的角度來討論測量。
四、測量
醫學上的測量就是各種檢查檢驗。整個醫療系統中有很大一部分工作就是執行測量工作,產生大量的醫學測量資料。比如體溫單、醫學影像圖片、電子病歷文件等等。
筆者認為測量有三個步驟:資料輸入、資料校驗、資料標準化、資料儲存。
1.資料輸入
醫療鏈的執行需要依賴IT技術,而目前的IT技術基本上只能處理電子資料。因此所有的測量資料必須轉換為數字化內容輸入到IT系統中。所有不能轉換為數字化內容的測量結果可以認為對醫療鏈作用不大。
例如以前醫生手寫病歷,狀若天書,不可利用;而電子病歷的第一步就是強制醫生在電腦終端上輸入病歷文字,實現病歷文件的數字化。
另外現在有一些醫學測量儀器,沒有標準化的輸出介面,使得測量結果不能自動輸入到IT系統中,也就進不了醫療鏈大迴圈中。對此醫院採購裝置時應該要求廠商配置好標準化數字輸出介面。
這裡的裝置不僅僅指CT、B超等大型裝置,還可以是體溫計、體重計、血壓計之類的簡單裝置,所有裝置能方便接入計算機網路而自動輸入測量資料,而且儘量做到病人自助測量。自助測量可能存在比較大的誤差,不過可以頻繁的進行測量,然後使用統計學演算法來減少誤差。
更進一步的,對於病歷文字,可以讓有條件的病人自助錄入,可能實現的應用場景有:
第一,久病成醫,部分病人會自學相關醫學知識,能帶點專業的描述自己身體的切身感受,這是醫生做不到的。
第二,住院病人不分晝夜的躺在病床上,無聊得很,很想找事做;另一頭醫生討厭寫字。於是可以有個兩全其美的方法,那就是讓病人使用自助裝置記錄其自身感受,回顧醫生查房言談,這樣寫出幾千字也是可能的,而且這些文字對醫生寫病歷是一個很好的參考,甚至直接複製過來生成的病歷質量也不會差。
第三,當病人回家休養時,既然是休養那就比較清閒,此時也可以要求病人天天通過移動裝置或電腦終端錄入文字向醫生彙報病情,寫養病日記,這些文字真實可靠生動,也可組織進入病歷資料。
這樣,資料輸入做到極致就可以實現“護士不錄體溫、醫生不寫病歷”。讓醫護人員從繁瑣的低階勞動中解放出來,使其能投入更高階的勞動中。這也是筆者一直堅持的理念:“Less interface time , More face time”。
圖3 Less interface time , More face time
2.資料校驗
外界輸入的原始醫療測量資料需要經過校驗來確保其能反映出病人的客觀病情。在此筆者借鑑一下冷鏈的概念。
[1]根據百度百科說明:冷鏈(cold chain)是指易腐食品從產地收購或捕撈之後,在產品加工、貯藏、運輸、分銷和零售、直到消費者手中,其各個環節始終處於產品所必需的低溫環境下,以保證食品質量安全,減少損耗,防止汙染的特殊供應鏈系統。
對於醫療行業來說,醫療測量資料是一種比較容易“腐敗”的資料,因為人體的狀態會時刻變化,病情也會時刻變化,以前的醫療測量資料可能無法準確反映出人體的當前狀態,這種情況下,資料就“腐敗”了。因此理論上來說需要足夠頻繁的測量人體狀態資訊,產生最新的測量資料。不過舊的測量資料有一些沒有腐敗,需要篩查參考,還有些法律效力。因此資料即使疑似腐敗了也不能丟棄,仍然需要長期儲存並能呼叫。
對於醫療鏈的任何環節,測量資料的真實性是基礎,也就是說資料能反映客觀事實而不是造假的。真實性差的資料天生就是“腐敗”的資料,還要花精力判別剔除掉。
醫學測量資料有客觀性資料和主觀性資料。客觀性資料就是各種醫學測量儀器產生的資料,比如體溫計、體重計、血生化儀、B超、CT等等產生的資料。這種資料精確可靠,資料驗證也有定量標準。因此客觀性資料的真實性是有保障的。
主觀性資料就是醫生對各種資料作出的主觀上的判斷,比如醫學影像診斷分析報告。有些主觀性的資料還必須親自面對病人才能作出,比如中醫的望聞聽切等等。此時主觀性資料的真實性全靠醫生的技能和認真度了,資料驗證也不容易。
醫療鏈能提高部分主觀性資料的真實性。因為醫療鏈能做到人盡其用。在整個醫療鏈中,各種層次的專業人士地理上是分開的,而使用醫療鏈,能將資料傳送到更專業的人士,讓專業的人做專業的事,這樣能提高主觀性資料的真實性。最典型的例子就是區域PASC系統。
3.資料標準化
醫療鏈中有很多資料輸入點,這些資料意義千差萬別,軟硬體廠家很多,而資料需要隨著醫療鏈大迴圈而在各環節中流通,此時需要各個環節對同一個資料具有相同的理解而不產生歧義,此時資料標準化就很重要了。
目前醫療資料主要有業務資料、病歷文件資料和醫學影像資料。業務資料基本上都是存在關係型資料庫中的,雖然邏輯結構五花八門,但資料介面不難做,統計分析容易實現;醫學影像資料方面已經有了DICOM的國際標準;此時病歷文件的資料標準就是最大的問題了。
目前在業界病歷文件有以下幾種格式:
- 純文字格式。程式介面上就放一個大的TextBox來錄入內容。很顯然這不與時俱進。
- 類似WORD格式。程式介面上就是放一個MS Word、OpenOffice等類似二次開發的控制元件,存成專有二進位制格式,筆者還見過有編輯器廠家故意加密文件而不讓別人解析。雖然這樣對於醫院流程業務來說是滿足了,但產生的資料基本上是封閉的不能二次利用。
- XML格式。現在一些醫院採用專業的結構化電子病歷編輯器,產生的檔案格式是XML格式。XML的批量處理和分析已經不是難題,技術也得到普及,而且各大資料庫巨頭都在努力實現XML資料庫。使用XML格式能讓醫療鏈的資料有產量有質量,為醫療鏈的應用打下良好基礎。
在實踐中電子病歷文件資料格式五花八門,很多儲存格式不是開放的,更談不上標準化。對此國家的《電子病歷系統功能規範》第十條第一款第一點明確規定“支援對各種型別的病歷資料的轉換、儲存管理,並採用公開的資料儲存格式,使用非特定的系統或軟體能夠解讀電子病歷資料。”。如果認真執行這條規定,相信很多醫院的資訊化評級是做不上去的。
病歷文件資料標準化的實現路徑是“病歷文件格式標準”→“電子病歷編輯器控制元件”→“電子病歷系統”三個步驟,並根據實際情況來回反覆調整推進。
醫療機構在採購資訊化系統時也應該對病歷文件格式提出要求。目前病歷文件沒有具體的國家標準(HL7/CDA只是病歷資料交換標準,不是儲存標準)。不過目前選擇純XML格式那是不會錯的。
資料標準化不僅僅是病歷文件,還應該是整個醫療鏈中所有的測量資料進行標準化。比如對疾病分類已經有ICD編碼標準;而資料的測量位置、計量單位、測量頻率、測量裝置訊號規格等等也應該標準化。更進一步的不僅僅是醫療測量資料,醫療鏈產生的所有的資料都需要標準化。
4.資料儲存
醫療資料按道理是屬於病人的,在病人的授權下對醫療鏈的任何環節都應該能獲取醫療資料。但現實中,醫療資料都是存在各個醫院內網的資料庫中,外界無法獲取。
醫療鏈就需要採用雲端計算的方式來儲存和處理資料。在病人的授權下,醫療鏈任何環節都可以下載或上傳醫療資料。雲端計算中心一般是醫療行業組織或政府主管機構管理和維護。終端很多很紛雜,此時雲端計算體系的平穩執行有賴於上面討論的資料標準化了。
5.數字資產
根據醫療資料標準化,筆者可以延伸出數字資產的概念。
[1]按照百度百科的解釋,資產就是指任何公司、機構和個人擁有的任何具有商業或交換價值的東西。
醫療資料具有商業或交換價值,反統方的存在就證明了這點,在雲端計算時代更是以資料為基礎的。因此醫療資料就是醫療機構的核心資產。可以說程式不完美可以湊合著執行幾年,但對數字資產的完全把握是不容有失的。
數字資產是醫療鏈中所有人員長期辛勤勞動而日積月累出來的,非常寶貴,需要被重複利用才能更多的體現其價值,此時開放資料格式和資料標準就是基礎了。如果一開始採用了不開放不標準的資料格式,就像農民一開始播下了假種子,辛苦一年後白忙一場。
因此建議醫療機構以資產的角度看待資訊化系統,儘量採購優質資產,避免劣質資產。確保利益最大化。
五、小結
醫療鏈是一個很大的概念,包含測量、分析、執行和迴圈4大部分。本文只討論了測量部分,其他部分也有很多內容值得討論。另外社會行業中的物流鏈、金融鏈、供應鏈等等也可以參與到醫療鏈中,藉助其他社會行業的力量來持續改進社會醫療體系,增強其執行力,更好的完成其救死扶傷的功能。
相關推薦
醫療鏈的系列談 第一篇 基本概念研究
摘要:本文從醫聯體的概念和現狀出發,進行了一些分析,並結合工業自動化中的PID原理,提出了醫療鏈的概念。醫療鏈包含4大部分:測量、分析、執行、迴圈。其中測量、分析、執行組成一個迴圈體,然後使用反饋機制不斷的執行迴圈,將醫療行為中的被動迴圈轉換為主動迴圈,提高醫療系統執行力。本文還深入討論了醫療鏈中的測量部分,
單點登入(SSO)入門第一篇--基本概念
本文簡要介紹了SSO的概念,使用場景及其基本實現原理 一、SSO是什麼 SSO英文全稱為Single Sign On,即我們常說的單點登入,指的是在多個相關的應用系統中,使用者只需要使用使用者名稱密碼登入一次就可以訪問所有相互信任的應用系統。 二、為什麼要引入SS
Python數據分析與挖掘第一篇—基本介紹及環境搭建
sim python 模塊 功能 對數 numpy 分析 沒有 兩種 一,數據分析與挖掘簡介 所謂數據分析,是對已有的數據進行分析,提取一些有價值的信息,比如平均數,標準差等。而數據挖掘,是對大量的信息進行分析和挖掘,得到一些未知的,有價值的信息。如今日頭條類的新聞推送
第一篇 基本結構
lin 機會 idt html網頁 oct 不知道 運用 code 制作 ----------第一次寫html的東西,好久沒學了,還是想堅持學完,有時間更新一下吧,雖然寫的賊菜!---------- 我的水平真的停留在初學者。。。。。。 ----------用DWCC制作H
Python資料分析與挖掘第一篇—基本介紹及環境搭建
一,資料分析與挖掘簡介 所謂資料分析,是對已有的資料進行分析,提取一些有價值的資訊,比如平均數,標準差等。而資料探勘,是對大量的資訊進行分析和挖掘,得到一些未知的,有價值的資訊。如今日頭條類的新聞推送就是通過對使用者的資訊進行分析和挖掘,從而達到精準推送使用者感興趣的新聞。資料分析和資料探勘往往是密不可
概率複習 第一章 基本概念
本文用於複習概率論的相關知識點,因為好久不接觸了,忘了不少。這裡撿起來,方便學習其他知識。 總目錄 概率複習 第一章 基本概念 概率複習 第二章 隨機變數及其分佈 本章目錄 事件的運算 交換律 結合律 分配率 摩根定律 概率含義及性質 可列可加性: 有
MOOC浙江大學 資料結構 第一講 基本概念
1.2 什麼是演算法? 1.1 例3 double f(int n,double a[],double x) { int i; double p=a[0]; for(i=1;i<=n;i++) p += (a[i]*pow(x,i)); return p
透析java本質的36個話題-第一章基本概念筆記
記得大三時在圖書館看過這本書,當時一口氣就看完了,參加工作後又回過頭來再看,還是收益很多,我是先看的這本書,然後再看了深入理解jvm虛擬機器這本經典之作,必須反覆看。現在又回過頭來看 透析java本質的36個話題 這本書,全書一共5章,我謹以5篇博文紀念。 1、開門見山
乙太網鏈路聚合技術基本概念
乙太網鏈路聚合Eth-Trunk簡稱鏈路聚合,它通過將多條乙太網物理鏈路捆綁在一起成為一條 邏輯鏈路,從而實現增加鏈路頻寬的目的。,同時,這些捆綁在一起的鏈路通過相互間的動態備份, 可以有效地提高鏈路的可靠性。 隨著網路規模不斷擴大,使用者對骨幹鏈路的頻寬和可靠性提出越來越高的要求
js學習筆記-第一章基本概念-變數
注意點: 1、js是弱型別語言 <head> <meta charset="UTF-8"> <title></title> <script> //一種型別賦給另外一種型別是適用的,但不推
Python Flask Web 第一課 —— 基本概念和程式的基本結構
1. 初始化 所有的 Flask 程式都必須建立一個程式例項,所謂程式例項,在 Flask 框架下就是,Flask 類的例項物件(instance)。 from flask import Flask app = Flask(__name__) Web
mina第一篇:基本demo實現
今天看了下mina,實現了最簡單的功能,其實就是一個傳輸字串,但是受益匪淺. 廢話少說,先介紹步驟 1、準備好幾個包 log4j.jar mina-core-2.0.4.jar slf4j-api-1.6.3.jar slf4j-log4j12-1.6.3.j
嵌入式學習第一課——基本概念
通過對嵌入式課程的第一次學習,讓我對嵌入式有了更加深刻的理解。對於本次學習內大致分為以下幾方面:基本內容:1、什麼是嵌入式:2、為什麼學習嵌入式:3、學習嵌入式需要學習哪些課程:4、linux系統基本使用; 嵌入式系統是以應用為中心,以計算機技術為基礎,
Java面試系列第一篇-基本型別與引用型別
這篇文章總結一下我認為面試中最應該掌握的關於基本型別和引用型別的面試題目。 面試題目1:值傳遞與引用傳遞 對於沒有接觸過C++這類有引用傳遞的Java程式設計師來說,很容易誤將引用型別的引數傳遞理解為引用傳遞,而基本型別的傳遞理解為值傳遞,這是錯誤的。要理解值傳遞與引用傳遞,首先要理清值傳遞、引用
第一篇 : Docker的基本概念和框架
一、Docker簡介 什麼是容器 ? 一種虛擬化的方案 作業系統級別的虛擬化 只能執行相同或相似的核心作業系統 依賴於Linux核心特性:Namespace和Cgroups(Control Group) 容器技術有哪些優點 ?
執行查詢 第一篇:基本概念
SQL Server 是如何執行查詢指令碼的呢?首先,應用程式連線到SQL Server引擎, 向SQL Server傳送請求。一旦應用程式連線到資料庫引擎,SQL Server 建立會話(Session),用於表示客戶端和伺服器端之間資料交換的狀態。其次,SQL Server引擎分配Task來接受查詢請求,
第一章 機器學習基本概念
經驗 amp 獨立 示例 特征向量 三維 容易 如果 包含 1.機器學習主要是通過計算機在已有的數據上(經驗)產生相應的模型(學習算法),在面臨新的情況時,模型能給出相應的判斷。所以說機器學習是研究學習算法的學問。 2基本術語 2.1以西瓜是否成熟為例,(色澤=青綠;根蒂=
概率論與數理統計筆記 第一章 概率論的基本概念
討論 公式 mooc set 滿足 log lin let 關閉 概率論與數理統計筆記 第一章 概率論的基本概念 概率論與數理統計筆記(計算機專業) 作者: CATPUB 課程:中國大學MOOC浙江大學概率論與數理統計 部分平臺可能無法顯示公式,若公式顯示不正常可以前往CS
Oracle知識梳理(一)理論篇:基本概念和術語整理
http 知識梳理 屬性集 操作 url 本質 開發 表格 weight 理論篇:基本概念和術語整理 一、關系數據庫 關系數據庫是目前應用最為廣泛的數據庫系統,它采用關系數據模型作為數據的組織方式,關系數據模型由關系的數據結構,關系的操作集合和關系的完整
Python初探第一篇-變量與基本數據類型
分享圖片 list rem 列表 對象的引用 初始化 分割 追加 append() 變量 Python中的變量和c語言中有所區別,Python是動態類型的語言,因此不需要預先聲明變量的類型,在賦值的那一刻變量的類型和值就一起初始化。每個變量在使用前都必須賦值,變量賦值以