
hbase bulk load 小實踐及一些總結
很早就知道bulk load這個東西,也大致都清楚怎麼回事,居然直到前幾天才第一次實踐... 
這篇文章大致分為三個部分:
1. 使用hbase自帶的importtsv工具
2. 自己實現寫mr生成hfile並載入
3. bulk load本身及對依賴的第三方包的一些總結
第一部分:
匯入的檔案是data.txt,符合tsv格式,如下:

做一些準備工作:
a. 在hdfs上穿件/test目錄,並將data.txt傳至該目錄下
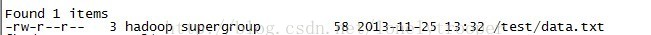
b. 建立hbase表bl_tmp

c. 將依賴的jar加到$HADOOP_HOME/conf/hadoop-env.sh (每個人的不一定一樣,加你需要的)
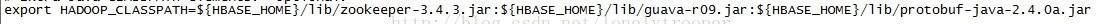
執行hbase自帶的imprttsv工具,這裡輸出路徑是output,列的定義由-Dimporttsv.columns指定:
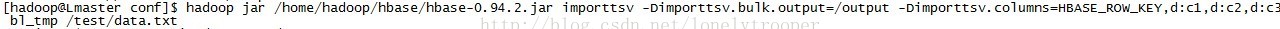
程式正常執行,執行成功後,檢視/output目錄,output目錄下會根據列族名生成一個自錄,這裡是d,d目錄下為具體的hfile檔案:

執行completebulkload工具將hfile裝載到表bl_tmp中:
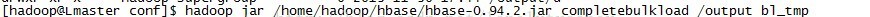
裝載完之後,d目錄下的hfile不存在了,這時查詢bl_tmp表,如下:
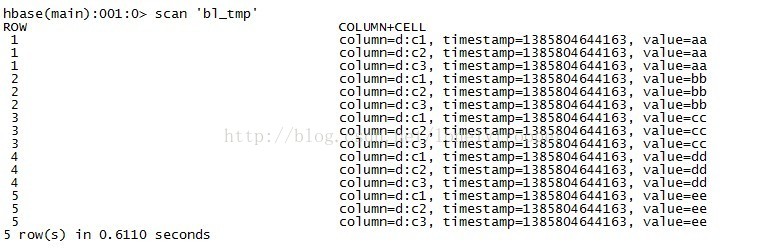
第二部分:
原始碼直接貼了,簡明扼要,沒什麼好說的... 關鍵的點詳見前邊兩篇簡要介紹相關原始碼的博文...
import java.io.IOException; import java.util.Date; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat; import org.apache.hadoop.hbase.mapreduce.PutSortReducer; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public final class HBaseBulkLoadDemo extends Configured implements Tool { public static class BulkLoadDemoMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> { private static final byte[] FAMILY_NAME = "d".getBytes(); private static final byte[] COLUMN_A = "colA".getBytes(); private static final byte[] COLUMN_B = "colB".getBytes(); private static final byte[] COLUMN_C = "colC".getBytes(); protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] fields = line.split("\t"); byte[] rowkeybytes = Bytes.toBytes(fields[0]); ImmutableBytesWritable rowkey = new ImmutableBytesWritable(rowkeybytes); Put put = new Put(rowkeybytes); put.add(FAMILY_NAME, COLUMN_A, fields[1].getBytes()); put.add(FAMILY_NAME, COLUMN_B, fields[2].getBytes()); put.add(FAMILY_NAME, COLUMN_C, fields[3].getBytes()); context.write(rowkey, put); } } /** * @param args * @throws Exception */ public static void main(String[] args) throws Exception { System.exit(ToolRunner.run(new HBaseBulkLoadDemo(), args)); } public int run(String[] args) throws Exception { Configuration conf = HBaseConfiguration.create(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 3) { System.err.println("Usage: <tableName> <inputDir> <outputDir>"); System.exit(2); } HTable table = new HTable(conf, otherArgs[0]); Job job = new Job(conf); job.setJarByClass(HBaseBulkLoadDemo.class); job.setJobName("HBaseBulkLoadDemo " + new Date()); job.setMapperClass(BulkLoadDemoMapper.class); job.setReducerClass(PutSortReducer.class); job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); FileInputFormat.addInputPath(job, new Path(otherArgs[1])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[2])); HFileOutputFormat.configureIncrementalLoad(job, table); return job.waitForCompletion(true) ? 0 : 1; } }
程式用打包後,扔到叢集上執行,為驗證結果,注意先truncate掉bl_tmp表並刪掉/output目錄。
另外一點,這裡執行自己打的包,如果你沒有打依賴包的話,因為你用到hbase-version.jar,所以你需要把它加到HADOOP_CLASSPATH上:
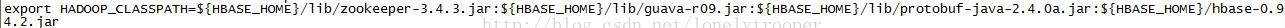
執行自己打的jar包:
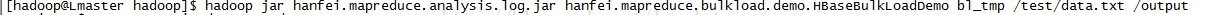
程式正確執行,檢視/output下的輸出:
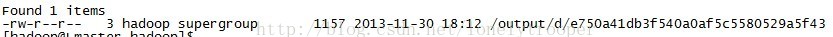
將資料裝在進bl_tmp仍然可以用completebulkload工具,或者你可以自己寫一個工具,非常簡單,就是構造一個LoadIncrementalHFile物件,並呼叫它的doBulkLoad方法就好了。 然後檢視這時的bl_tmp(注意列名,與importtsv時不一樣...):
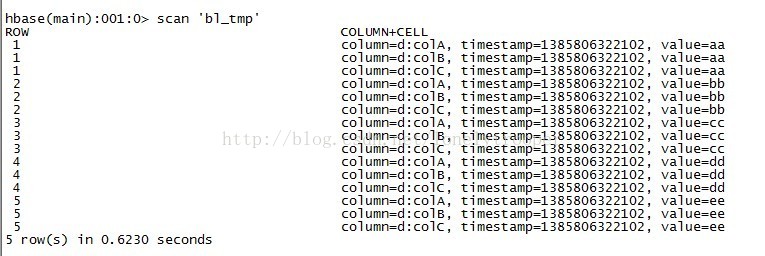
第三部分:
關於bulkload本身:
1.這種方式適合初次匯入,對於大資料量,效率非常可觀,並且不需要表offline
2.目前貌似只適合每次對一個單列族匯入..
3.資料量很大時,因為reduce個數與region個數對應,所以導數前記得對錶進行預分割槽。
4.自己實現時,map階段的輸出只能是<ImmutableBytesWritable,KeyValue>或者<ImmutableBytesWritable,Put>,對應的reducer分別是KeyValueSortReducer和PutSortReducer。
關於hadoop對jar的載入方式及bulk load時第三方jar的一些說明,自己在實踐的時候起初迷惑了很久,所以特意總結了下:
1.hadoop jar在執行時一定會將HADOOP_CLASSPATH加到CLASSPATH上(感興趣可以cat hadoop看下),並且將hadoop jar執行的目標jar拷貝到子節點。
2.依賴的第三方jar,一般三種方式處理,要麼-libjars,要麼加到HADOOP_HOME/lib下(所有子節點),要麼打包進目標jar。
3.執行hadop jar hbase-version.jar importtsv時,由於將依賴的jar加到了HADOOP_CLASSPATH,並且在主節點本地可以找到,所以依託TableMapReduceUtil.addDependencyJars方法的作用,依賴的第三方jar在執行時被作為分散式快取拷貝到了子節點,程式得以正確執行。
完... 
相關推薦
hbase bulk load 小實踐及一些總結
很早就知道bulk load這個東西,也大致都清楚怎麼回事,居然直到前幾天才第一次實踐... 這篇文章大致分為三個部分: 1. 使用hbase自帶的importtsv工具 2. 自己實現寫mr生成hfile並載入 3. bulk load本身及對依賴的第三方包的一些總結
移動開發實踐及‘坑’總結
設計 頁面 復制代碼 html posit use 比較 國外 itl 1.input placeholder問題 在chrome 模擬移動端調試時[左邊圖],顯示的非常正常,但是在真機上[右邊圖],placeholder裏面的內容明顯靠上,非常的不美觀
大資料之hbase(五) --- 匯出Hbase的表文件到HDFS,Hbase Bulk Load Hbase,MySQL資料通過MR匯入到Hbase表中
一、匯出Hbase的表文件到HDFS -------------------------------------------------------------------------- 1.複製hbase的jar檔案和metrices-core-xxx.jar檔案到
swagger實踐 及一些踩過的坑
首先就是我們專案中用的swagger2,編輯的時候已經升級到3.0.0了 有空嘗試下。 然後至少要是個spring的專案,支援@configuration這個註解的版本,我們專案中用的spring4.1.0。 然後就是開開心心的碼程式碼了 @Conf
Pytorch遷移學習小技巧 以及 Pytorch小技巧的一些總結
遷移學習技巧 內容概要: 遷移學習的概念 Pytorch預訓練模型以及修改 不同修改預訓練模型方式的情況 一些例子:只針對dense layer的重新訓練 ,凍結初始層的權重重新訓練 遷移學習的概念 神經網路需要用資料來訓練,它從資料中獲得資
小程序canvas使用,及一些坑,以及自己的一些小總結
開發 背景圖 height java gda 數據 利用 let 宋體 自己做了一個小程序,主要用於給頭像加圖標的那種,和qq似的,主要用canvas做的, 第一回用,掉了很多坑,所以今天系統的總結一下自己所做的,如果大家有不理解的地方,歡迎提問 canvas可以用來畫一
關於ueditor的一些用法,及模板使用方面的一些總結
baidu 配置 bsp sta nbsp htm 設置 用法 blog 將自定義模板設為默認 http://www.bmqy.net/9234.html 設置自定義模板 http://www.cnblogs.com/liupeng61
網絡配置註意事項及一些小竅門
達內 網絡 安全 竅門 思科 華為1、建議老設備加入現網:(1)IOS配置更新成與現網一致的;(2)所有的配置清除;(3)確認無誤後再上線。2、思科IOS快捷鍵: CTRL+A/CTRL+E,將光標快速移動到命令最前面/最後面。在執行show running-config以後直接結束顯示回到命令輸入狀態,按t
使用Ubuntu14.04中的一些小問題及處理辦法
apt-get 情況下 找不到 安裝 sam ubuntu14 -s 聲音 型號 1、沒有聲音打開終端,運行alsamixer,把自動靜音(Auto-Mute)那一項關閉,聲音就出來了。 2、找不到無線網卡方法一:在安裝時就插上網線,並且在安裝選項上勾上安裝第三方軟件……這
【實踐】Yalmip使用Knitro的一些總結
完整 步驟 bubuko pro 打開 ecg LV start features Yalmip使用Knitro的一些總結 1.軟件 Knitro 11.0.1 Win64(包含安裝包和確定機器ID的軟件):鏈接:https://pan.baidu.com/s/
HBase內建過濾器的一些總結
轉載自:https://blog.csdn.net/cnweike/article/details/42920547 HBase為篩選資料提供了一組過濾器,通過這個過濾器可以在HBase中的資料的多個維度(行,列,資料版本)上進行對資料的篩選操作,也就是說過濾器最終能夠篩選的資料能夠細化到具體的
STL基本使用方法總結及一些補充
(Hint:如果在main函式中定義STL的話會比較費時間,對於某些題目來說會超時,所以一般將STL定義為全域性變數,這樣的話快很多~) 一、vector向量容器 標頭檔案#include <vector> 1.建立vector物件(1)不指定容器大小vector<i
HBase技術與應用實踐 | HBase2.0重新定義小物件實時存取
本次分享來自中國HBase技術社群第七屆MeetUp成都站,分享嘉賓天引 阿里巴巴 技術專家專注在大資料領域,擁有多年分散式、高併發、大規模系統的研發與實踐經驗,先後參與HBase、Phoenix、Lindorm等產品的核心引擎研發,目前負責阿里上萬節點的HBase As a Service的發展與落地。 分
Sqlit3資料庫的詳細講解及一些在python中的小技巧
資料庫的基本概念。 庫 schema:好像整個表格文件。好像一個物流公司共佔地100畝,蓋了50個倉庫,A01倉庫負責儲存河南客戶貨物,A02倉庫負責儲存廣州xx專案物料。每一個倉庫對應一個專案。 表 table:對應Excel表格裡sheet1 sheet2。由行內內
點選按鈕刪除bootstrapTable選中行,js模組化及一些問題的總結
頁面效果展示 html程式碼: <div class="col-md-12" style="height: 15%"> <form action="web?module=stwmgr&action=Develop&method=se
小白學習Vi/Vim編輯器安裝及使用總結
Table of Contents 1.vi/vim是什麼? 2.vim模式有哪些?如何切換? 3.使用vim如何開啟檔案? 4.關閉檔案 5.移動游標 6.翻屏: 7
Linux小技巧-返回上一次目錄、及一些control快捷鍵
1、Linux回到上一次目錄 cd - - == $OLDPWD 可以 echo $OLDPWD檢視 cd - == cd $OLDPWD 一不小心輸入cd 直接回車就會跑
利用Git 上傳程式碼到Coding的簡單操作步驟及一些錯誤總結
今天看到git可以上傳程式碼到coding.net,感覺還是不錯的,於是自己動手上傳了一次,在期間發現了很多的問題,在這裡總結一下,希望能幫到未上傳成功的程式設計師們! 1:先自己註冊coding.net賬號! 2.安裝git 客戶端 安裝過程中的詳細說明可參考: https://jingyan.baidu
HBase利用bulk load批量匯入資料
OneCoder只是一個初學者,記錄的只是自己的一個過程。不足之處還望指導。 看網上說匯入大量資料,用bulk load的方式效率比較高。bulk load可以將固定格式的資料檔案轉換為HFile檔案匯入,當然也可以直接匯入HFile檔案。所以
C#中的自定義控制元件中的屬性、事件及一些相關特性的總結
今天學習了下C#使用者控制元件開發新增自定義屬性的事件,主要參考了MSDN,總結並實驗了一些用於開發自定義屬性和事件的特性(Attribute)。 在這裡先說一下我的環境: 作業系統:Windows7旗艦版(Service Pack 1) VS版本:Microsoft