
DL之NN:(sklearn自帶資料集為1797個樣本*64個特徵)利用NN之sklearn、NeuralNetwor.py實現手寫數字圖片識別95%準確率
先檢視sklearn自帶digits手寫資料集(1797*64)


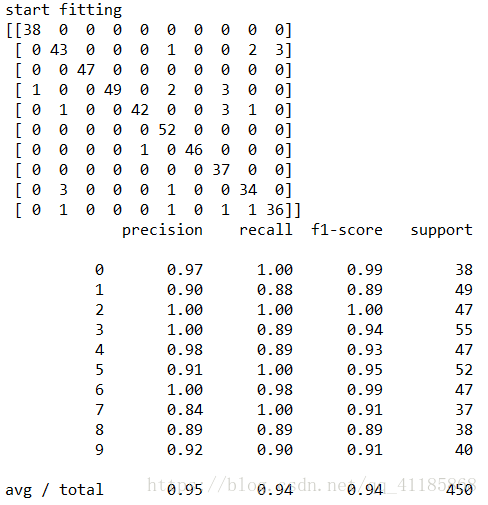
import numpy as np from sklearn.datasets import load_digits from sklearn.metrics import confusion_matrix, classification_report from sklearn.preprocessing import LabelBinarizer from NeuralNetwork import NeuralNetwork from sklearn.cross_validation import train_test_split digits = load_digits() X = digits.data y = digits.target X -= X.min() X /= X.max() nn = NeuralNetwork([64, 100, 10], 'logistic') X_train, X_test, y_train, y_test = train_test_split(X, y) labels_train = LabelBinarizer().fit_transform(y_train) labels_test = LabelBinarizer().fit_transform(y_test) print ("start fitting") nn.fit(X_train, labels_train, epochs=3000) predictions = [] for i in range(X_test.shape[0]): o = nn.predict(X_test[i]) predictions.append(np.argmax(o)) print (confusion_matrix(y_test, predictions) ) print (classification_report(y_test, predictions) )
相關推薦
DL之NN:(sklearn自帶資料集為1797個樣本*64個特徵)利用NN之sklearn、NeuralNetwor.py實現手寫數字圖片識別95%準確率
先檢視sklearn自帶digits手寫資料集(1797*64)import numpy as np from sklearn.datasets import load_digits from skl
DL之NN:NN演算法(本地資料集50000張訓練集圖片)進階優化之三種引數改進,進一步提高手寫數字圖片識別的準確率
首先,改變之一:先在初始化權重的部分,採取一種更為好的隨機初始化方法,我們依舊保持正態分佈的均值不變,只對標準差進行改動,初始化權重改變前, def large_weight_initializer(self): self.biases = [np.ran
TF之RNN:(TF自帶函式下載MNIST55000訓練集圖片)基於順序的RNN分類案例手寫數字圖片識別實現高精度99%準確率
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('MNIST_data', one_hot
sklearn 學習實踐之——基於自帶資料集(波士頓房價、鳶尾花、糖尿病等)構建分類、迴歸模型
只要是接觸機器學習的,很少有沒聽過sklearn的,這個真的可以稱得上是機器學習快速進行的神器了,在研究生的時候搭建常用的機器學習模型用的就是sklearn,今天應部門的一些需求,簡單的總結了一點使用方法,後面還會繼續更新,今天僅使用sklearn自帶的資料
unity開發之七:unity2017自帶高通ar使用方法(填坑)
一:首先我們先把2017.2自帶的高通ar包下載下來,然後才有選擇的選項 二:我們開始建AR專案 首先我們往場景中新增ARCamera,我們發現我們輸入key,需要如下的操作:,然後我們去官網申
ML之分類預測之ElasticNet之PLoR:在二分類資料集上呼叫Glmnet庫訓練PLoR模型(T2)
ML之分類預測之ElasticNet之PLoR:在二分類資料集上呼叫Glmnet庫訓練PLoR模型(T2) 輸出結果 設計思路 核心程式碼 for iStep in range(
【SciKit-Learn學習筆記】1:SVM預測digits資料集,繪製隨機波動樣本的學習曲線
學習《scikit-learn機器學習》時的一些實踐。 SVM預測digits資料集 sklearn裡的各種模型物件統一了介面,fit()做訓練,predit()做預測,用score()獲得對模型測試結果的打分。 這裡的打分不是acc,應該是決定係數。 檢視資料形式
【深度學習】3:BP神經網路與MNIST資料集實現手寫數字識別
前言:這是一篇基於tensorflow框架,建立的只有一層隱藏層的BP神經網路,做的圖片識別,內容也比較簡單,全當是自己的學習筆記了。 –—-—-—-—-—-—-—-—-—-—-—-—–—-—-—-—-—-—-—-——-—-—-—-—-—-—-—-—-—-—-
TensorFlow(九):卷積神經網絡實現手寫數字識別以及可視化
writer orm true 交叉 lar write 執行 one 界面 上代碼: import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist =
TensorFlow(十二):使用RNN實現手寫數字識別
rop mea pre rnn ext ini tro truncate tutorial 上代碼: import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data #
Tensorflow入門教程之手寫數字MINST識別
Tensorflow入門教程之手寫數字MINST識別 MNIST是在機器學習領域中的一個經典問題。該問題解決的是把28x28畫素的灰度手寫數字圖片識別為相應的數字,其中數字的範圍從0到9. MNIST 資料下載 Yann LeCun's MNIST page也提供了訓練集與測試集資料
初識GAN之MNIST手寫數字的識別
初識GAN,因為剛好在嘗試用純python實現手寫數字的識別,所以在這裡也嘗試了一下。筆者也是根據網上教程一步步來的,不多說了,程式碼如下: from tensorflow.examples.tutorials.mnist import input_data i
Kaggle神經網路實戰:CNN實現手寫數字辨識
簡要介紹 本文是基於Kaggle入門專案Digit Recognizer的處理方案,在MINST資料集上訓練可以識別手寫數字的模型。專案連結 程式碼來自專案Kernels,使用tensorflow實現CNN網路,完整圖文及程式碼請參照Kernel原文
MNIST資料集實現手寫數字識別(基於tensorflow)
主要應用了下面幾個方法來提高準確率; 使用隨機梯度下降(batch) 使用Relu啟用函式去線性化 使用正則化避免過擬合 使用帶指數衰減的學習率 使用滑動平均模型 使用交叉熵損失函式來刻畫預測值和真實值之間的差距的損失函式 第一步,匯入MNIST資料集 from
使用mnist資料集實現手寫數字識別
mnist資料集中數字是0到9,要求實現多分類,需要使用softmax函式。此次實現單隱層神經網路即只有一個輸入層和一個輸出層的神經網路來訓練並實現手寫數字識別。 softmax只作用在輸出層,要求輸出層輸出一個1*10維的向量,向量中每一個元素的位置代表相應的
KNN演算法——實現手寫數字識別(Sklearn實現)
KNN專案實戰——手寫數字識別 1、資料集介紹 需要識別的數字已經使用圖形處理軟體,處理成具有相同的色彩和大小:寬高是32畫素x32畫素的黑白影象。儘管採用本文格式儲存影象不能有效地利用記憶體空間,但是為了方便理解,我們將圖片轉換為文字格式。 數字的文字格式如下:
TF之CNN:利用sklearn(自帶手寫圖片識別資料集)使用dropout解決學習中overfitting的問題+Tensorboard顯示變化曲線
import tensorflow as tf from sklearn.datasets import load_digits #from sklearn.cross_validation import train_test_split from sklearn.model_selection import
機器學習之路: tensorflow 自定義 損失函數
cond pre port var IV 學習 col float ria git: https://github.com/linyi0604/MachineLearning/tree/master/07_tensorflow/ 1 import tensor
ML之預測:以某個資料集為例從0到1深入理解科學預測之分類問題的思路框架
ML之預測:以某個資料集為例從0到1深入理解科學預測之分類問題的思路框架 總體思路設計框架 1、獲取資料集,並確定新資料集的規模 資料集規模為(208*61) 2、確定資料集每個屬性的型別 &
碼農裝13寶典系列之五:Ubuntu自定義字型縮放級別
目前主流顯示器都有一個很高的解析度,而使用預設的解析度會使字型顯示過小,單純地調整解析度又容易讓字看起來發虛。 系統提供了一個字型縮放級別調整的功能。Windows初始化時就已經為使用者設定好了,而Ubuntu只有兩個選項:100%、200%,顯然不能滿足需求。 那怎麼辦? 這裡需要