
Deep Forest,非神經網路的深度模型,周志華老師最新之作,三十分鐘理解!
歡迎轉載,轉載請註明:本文出自Bin的專欄blog.csdn.net/xbinworld。
技術交流QQ群:433250724,歡迎對演算法、技術感興趣的同學加入。
深度學習最大的貢獻,個人認為就是表徵學習(representation learning),通過端到端的訓練,發現更好的features,而後面用於分類(或其他任務)的輸出function,往往也只是普通的softmax(或者其他一些經典而又簡單的方法)而已,所以,只要特徵足夠好,分類函式本身並不需要複雜——博主自己在做research的時候也深有同感,以前很多paper其實是誤入歧途,採用的feature非常混淆模糊沒有區分性,卻指望在分類器上獲得好的結果,可能麼?深度學習可以說是回到了問題的本源上來,representation learning。
目前DL的成功都是建立在多層神經網路的基礎上的,那麼這種成功能否復刻到其他模型上呢?我相信,是可以的。南京大學的周志華老師嘗試提出一種深度的tree模型,叫做gcForest,用文中的術語說,就是“multi-Grained Cascade forest”,多粒度級聯森林。此外,還提出了一種全新的決策樹整合方法,使用級聯結構讓 gcForest 做表徵學習。
Title:Deep Forest: Towards An Alternative to Deep Neural Networks
作者:Zhi-Hua Zhou and Ji Feng
摘要
在這篇論文裡,我們提出了 gcForest,這是一種決策樹整合方法(decision tree ensemble approach),效能較之深度神經網路有很強的競爭力。深度神經網路需要花大力氣調參,相比之下 gcForest 要容易訓練得多。實際上,在幾乎完全一樣的超引數設定下,gcForest 在處理不同領域(domain)的不同資料時,也能達到極佳的效能。gcForest 的訓練過程效率高且可擴充套件。在我們的實驗中,它在一臺 PC 上的訓練時間和在 GPU 設施上跑的深度神經網路差不多,有鑑於 gcForest 天然適用於並行的部署,其效率高的優勢就更為明顯。此外,深度神經網路需要大規模的訓練資料,而 gcForest 在僅有小規模訓練資料的情況下也照常運轉。不僅如此,作為一種基於樹的方法,gcForest 在理論分析方面也應當比深度神經網路更加容易。[1]
級聯森林(Cascade Forest)
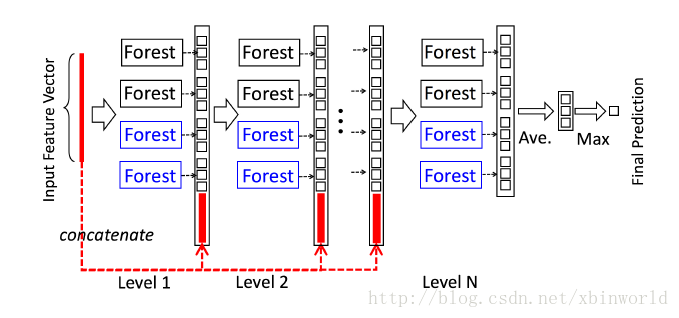
級聯森林結構的圖示。級聯的每個級別包括兩個隨機森林(藍色字型標出)和兩個完全隨機樹木森林(黑色)。假設有三個類要預測; 因此,每個森林將輸出三維類向量,然後將其連線以重新表示原始輸入。注意,要將前一級的特徵和這一級的特徵連線在一起——在最後會有一個例子,到時候再具體看一下如何連線。
論文中為了簡單起見,在實現中,使用了兩個完全隨機的樹森林(complete-random tree forests)和兩個隨機森林[Breiman,2001]。每個完全隨機的樹森林包含1000個完全隨機樹[Liu et al。,2008],每棵樹通過隨機選擇一個特徵在樹的每個節點進行分割實現生成,樹一直生長,直到每個葉節點只包含相同類的例項或不超過10個例項。類似地,每個隨機森林也包含1000棵樹,通過隨機選擇sqrt(d) 數量的特徵作為候選(d是輸入特徵的數量),然後選擇具有最佳 gini 值的特徵作為分割。每個森林中的樹的數值是一個超引數。
給定一個例項(就是一個樣本),每個森林會通過計算在相關例項落入的葉節點處的不同類的訓練樣本的百分比,然後對森林中的所有樹計平均值,以生成對類的分佈的估計。如下圖所示,其中紅色部分突出了每個例項遍歷到葉節點的路徑。葉節點中的不同標記表示了不同的類。
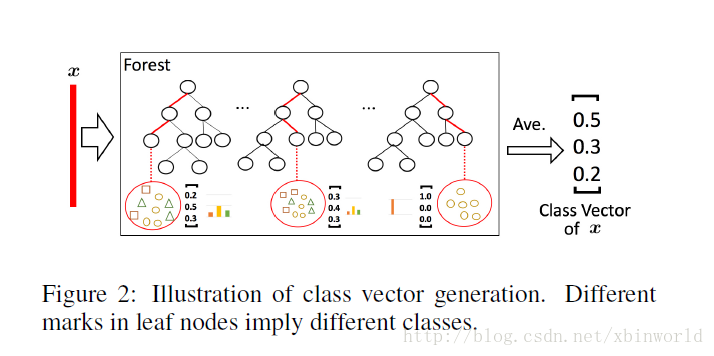
被估計的類分佈形成類向量(class vector),該類向量接著與輸入到級聯的下一級的原始特徵向量相連線。例如,假設有三個類,則四個森林每一個都將產生一個三維的類向量,因此,級聯的下一級將接收12 = 3×4個增強特徵(augmented feature)。
為了降低過擬合風險,每個森林產生的類向量由k折交叉驗證(k-fold cross validation)產生。具體來說,每個例項都將被用作 k -1 次訓練資料,產生 k -1 個類向量,然後對其取平均值以產生作為級聯中下一級的增強特徵的最終類向量。需要注意的是,在擴充套件一個新的級後,整個級聯的效能將在驗證集上進行估計,如果沒有顯著的效能增益,訓練過程將終止;因此,級聯中級的數量是自動確定的。與模型的複雜性固定的大多數深度神經網路相反,gcForest 能夠適當地通過終止訓練來決定其模型的複雜度(early stop)。這使得 gcForest 能夠適用於不同規模的訓練資料,而不侷限於大規模訓練資料。
(注:級聯數量自動確定可以有助於控制模型的複雜性,實際上在每一級的輸出結果都用ground truth label來訓練的,這裡和CNN的理解不同,CNN認為特徵是逐層抽象的,而本文在每一層都直接拿label的高層語義來訓練——我本人有一些擔憂,直接這樣的級聯會不會使得收益並不能通過級數的加深而放大?比如CNN目前可以做到上百層的net,而這裡會自動確定深度,也就是說可能沒辦法做的很深。希望隨著更多人的分析,可以在這一點上給出一些結論)
多粒度掃描(Multi-Grained Scanning)
深度神經網路在處理特徵關係方面是強大的,例如,卷積神經網路對影象資料有效,其中原始畫素之間的空間關係是關鍵的。(LeCun et al., 1998; Krizhenvsky et al., 2012),遞迴神經網路對序列資料有效,其中順序關係是關鍵的(Graves et al., 2013; Cho et al.,2014)。受這種認識的啟發,我們用多粒度掃描流程來增強級聯森林。
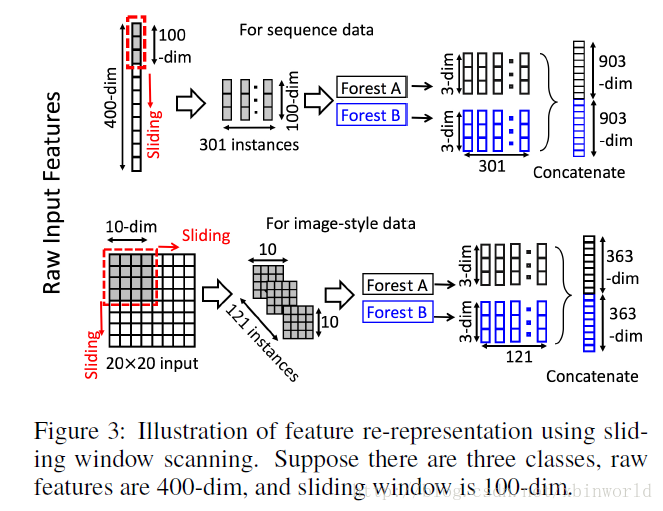
滑動視窗用於掃描原始特徵。假設有400個原始特徵,並且使用100個特徵的視窗大小。對於序列資料,將通過滑動一個特徵的視窗來生成100維的特徵向量;總共產生301個特徵向量。如果原始特徵具有空間關係,比如影象畫素為400的20×20的面板,則10×10視窗將產生121個特徵向量(即121個10×10的面板)。從正/負訓練樣例中提取的所有特徵向量被視為正/負例項;它們將被用於生成類向量:從相同大小的視窗提取的例項將用於訓練完全隨機樹森林和隨機森林,然後生成類向量並連線為轉換後的畫素。如上圖的上半部分所示,假設有3個類,並且使用100維的視窗;然後,每個森林產生301個三維類向量,導致對應於原始400維原始特徵向量的1,806維變換特徵向量。
通過使用多個尺寸的滑動視窗,最終的變換特徵向量將包括更多的特徵,如下圖所示。
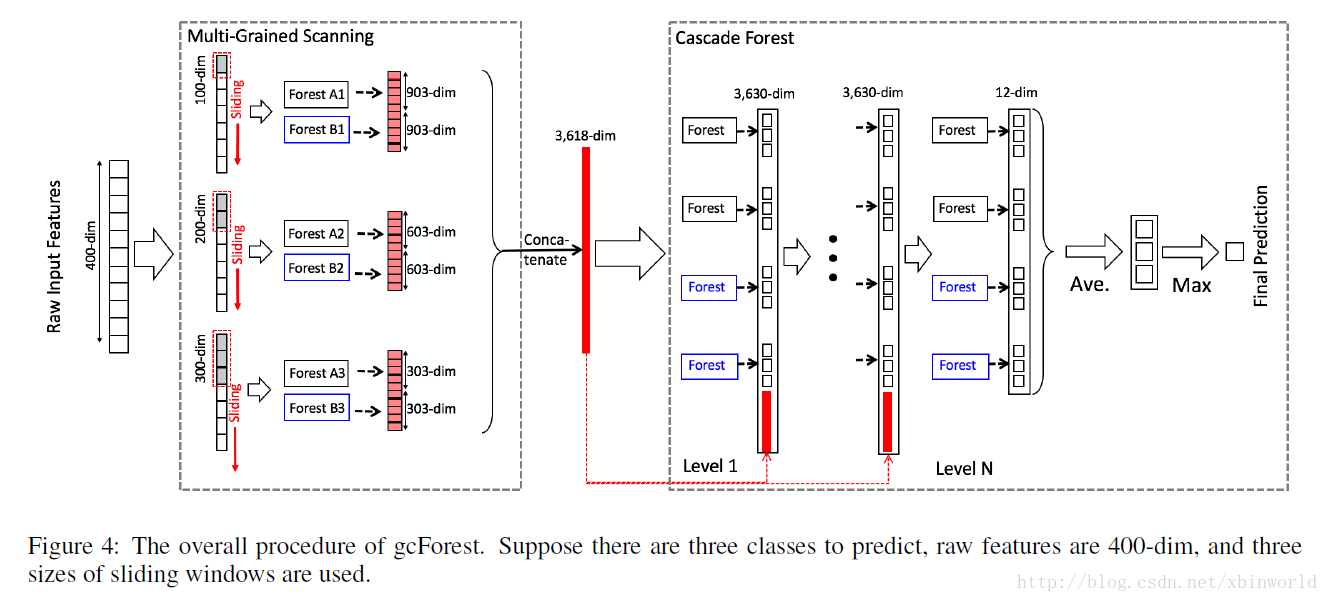
concat成一個3618-dim的原始資料,表示原始的一個數據樣本,第一級的輸出是12+3618=3630,後面也是一樣,直到最後第N級,只有12個輸出,然後在每一類別上做avg,然後輸出max那一類的label,那就是最終的預測類別。
實驗結果
這一部分也是網上大家有疑問的地方,主要是資料集選取都是比較小的實驗資料,這個方法能不能火還是要看在real data上能不能做到和DL一樣的效果。
下面簡單貼幾個結果
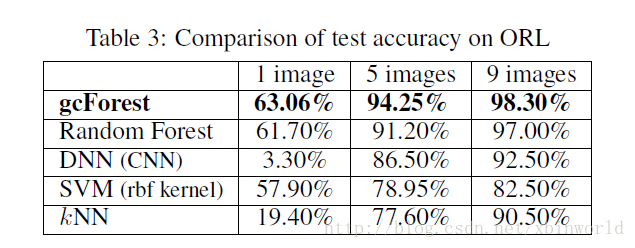
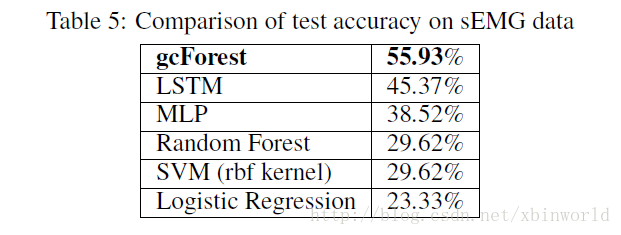
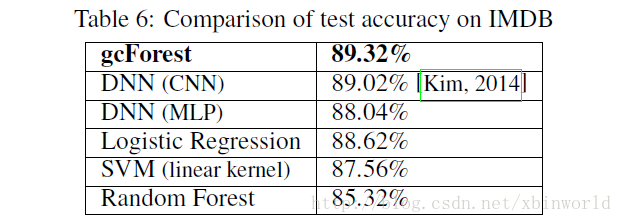
總結
帶著深度學習的關鍵在於特徵學習和巨大模型的能力這一認識,我們在本文中試圖賦予樹整合這些屬性,並提出了 gcForest 方法。與深度神經網路相比,gcForest在我們的實驗中表現了極高的競爭力或更好的效能。更重要的是,gcForest 具有少得多的超引數,並且對引數設定不太敏感;實際上在我們的實驗中,通過使用相同的引數設定在不同的域中都獲得了優異的效能,並且無論是大規模還是小規模的資料,它的工作都很好。此外,作為一種基於樹的方法,gcForest 應該比深度神經網路更容易進行理論分析,不過這超出了本文的討論範圍。我們很快會提供 gcForest 的程式碼。
出自原文[2]:“構建深度森林還存在其他可能性。作為一個會議論文,我們只朝這個方向進行了一點點探索。如果我們有更強大的計算設施,我們想嘗試大資料和深度森林,這將留待以後討論。原則上,深度森林應該能夠展示出深度神經網路的其他能力,如充當特徵提取器或預訓練模型。 值得一提的是,為了解決複雜的任務,學習模型可能需要更深入。然而,當前的深度模型總是神經網路。本文說明了如何構建深度森林,我們相信它是一扇門,可能替代深度神經網路的許多工。”
這篇文章通俗易懂,要詳細瞭解的話需要對決策樹,random forest稍有了解,可以去看一下我前面的部落格:機器學習方法(四):決策樹Decision Tree原理與實現技巧 以及 機器學習方法(六):隨機森林Random Forest,bagging;和離散類別特徵不同,本文都是基於連續特徵為資料特徵的,比如畫素等等,因此,決策樹都是基於連續特徵構建的。
僅通過本來說DL演算法可取代還為時過早,神經網路有其獨特性,而且存在著設計上的美——計算模式統一,端到端,沒有過多人文設計;而本文說實話,我還是覺得有很多人為設計的痕跡,希望更多的學者可以在tree based learning method方向上找到更多突破。
參考資料
相關推薦
Deep Forest,非神經網路的深度模型,周志華老師最新之作,三十分鐘理解!
歡迎轉載,轉載請註明:本文出自Bin的專欄blog.csdn.net/xbinworld。 技術交流QQ群:433250724,歡迎對演算法、技術感興趣的同學加入。深度學習最大的貢獻,個人認為就是表徵學習(representation learning),通過端到端的訓練,發現更好的features,而後面用
機器學習-第五章神經網路讀書筆記(周志華)
前言博主第一次接觸機器學習,內容可能有許多原文復現,但是我儘量用自己的話來講,覺得寫得還行的話點個喜歡,謝謝!讀書筆記第一目的是為了總結,第二是順便在部落格上記錄我的學習歷程,同時也希望讀者能有一點點收穫吧~如果不對的地方,還請多多指教!正文周志華的機器學習第五章講的是關於神
鄒博機器學習演算法最新版( 吳恩達前輩、唐宇迪老師、張志華老師多家對比,入門最優 ) --- 獻給想要入門、或者想要進階的朋友
慌慌張張,匆匆忙忙,生活本來就是這樣 很喜歡郝雲的《活著》這首歌,很生動的描述了現代年輕上班族的生活。 時光飛逝,從開始接觸機器學習 已經一年多了,現已成功從安卓移動端轉戰機器學習 現在也如願從事機器學習的工作,雖初出茅廬,卻也拿到了比較滿意的25+ 想起當
周志華:滿足這三大條件,可以考慮不用深度神經網路
出品 | AI科技大本營(公眾號ID:rgznai100)AI科技大本營按:4 月 15 日舉辦
Batch Size設定過大時,對神經網路效能的影響情況
之前的一片博文寫了Batch Size的作用和應該如何設定比較合適,同時還有Batch Size大小,與學習率 lr l r lr、訓練次數 epoch
神經網路機器翻譯模型介紹
以下是這個系列會引用的文獻: References: [1] Google’s Neural Machine Translation System:Bridging the Gap between Human and Machine Translation,
神經網路語言模型在語音識別的應用論文整理
本人整理了NN語言模型在語音識別領域的應用論文。全部為2015年-2018年的會議論文。相關的期刊論文特別少,而且創新性沒有會議高。論文幾乎全部是語音類的最高級別會議ICASSP(B類)和Interspeech. 如果懶得自己下的話,可以留下郵
吳恩達卷積神經網路——深度卷積網路:例項探究
經典網路 LeNet5 隨著網路的加深,影象的高度和寬度在縮小,通道數量增加 池化後使用sigmoid函式 AlexNet 與LeNet相似,但大得多 使用ReLu函式 VGG-16 網路大,但結構並不複雜 影象縮小的比例和通道增加的比例是有規律的 64->
NNLM(神經網路語言模型)
簡介 *NNLM是從語言模型出發(即計算概率角度),構建神經網路針對目標函式對模型進行最優化,訓練的起點是使用神經網路去搭建語言模型實現詞的預測任務,並且在優化過程後模型的副產品就是詞向量。 *進行神經網路模型的訓練時,目標是進行詞的概率預測,就是在詞環境下,預測下一個該是什麼詞,目標函式如
【基於tensorflow的學習】經典卷積神經網路、模型的儲存和讀取
CNN發展史: 1.經典卷積神經網路 以下僅列出關於CNN的深層次理解: 卷積層 tensorflow中卷積層的建立函式:_conv1 = tf.nn.conv2d(_input_r, tf.Variable(tf.random_normal([3, 3, 1, 6
視覺化神經網路翻譯模型(seq2seq+attention)
翻譯自(https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/) Sequence-to-sequence(序列到序列)是一
改善深層神經網路——深度學習的實用層面(5)
目錄 正則化 偏差大的解決辦法:在正則化引數合適的情況下增大網路(不影響方差) 方差大解決辦法:調整正則化引數或者準備更多資料增大資料集(不影響偏差) 正則化 邏輯迴歸正則化: 神經網路正則化: 6.Dropout正則化 除
卷積神經網路--LeNet5模型
1 簡介 LeNet-5模型是1998年Yann LeCun教授在論文Gradient-based learning applied to document recognition中提出的,是第一個成功應用於數字識別問題的卷積神經網路,在MNIST資料集上,Le
自然語言處理(四)神經網路語言模型及詞向量
神經網路語言模型 用句子 S S S的概率
迴圈神經網路(RNN)模型與前向反向傳播演算法
在前面我們講到了DNN,以及DNN的特例CNN的模型和前向反向傳播演算法,這些演算法都是前向反饋的,模型的輸出和模型本身沒有關聯關係。今天我們就討論另一類輸出和模型間有反饋的神經網路:迴圈神經網路(Recurrent Neural Networks ,以下簡稱RNN),它廣泛的用於自然語言處理中的語音
神經網路語言模型詳解
1 簡介 語言模型是自然語言處理領域的基礎問題,其在詞性標註、句法分析、機器翻譯、資訊檢索等任務中起到了重要作用。簡而言之,統計語言模型表示為:在詞序列中,給定一個詞和上下文中所有詞,這個序列出現的概率,如下式, 其中,是序列中第詞,, 可以使用 近似,這就是n-gram語言模型,詳細請閱讀[我們是這樣
NLP之神經網路語言模型之超級無敵最佳資料
語言模型 Attention Is All You Need(Transformer)原理小結 ELMo解析 OpenAI GPT解析 BERT解析 https://www.cnblogs.com/huangyc/p/9861453.html 從
AI之(神經網路+深度學習)
目前的人工智慧,或者說以深度學習為代表的一些方法論的研究,更像是古代的鍊金術,而不像是現代的化學
【python keras實戰】用keras搭建捲起神經網路訓練模型
端到端的MINIST訓練數字識別 MINIST資料集是由LeCun Yang 教授和他的團隊整理的,囊括了6萬個訓練集和1萬個測試集,每個樣本都是32*32的畫素值,並且是黑色的,沒有R、G、B三層。我們要做的就是把每一個圖片分類到0~9的類別中。 kera
論文淺嘗 | 神經網路與非神經網路簡單知識問答方法的強基線分析
來源:NAACL 2018連結:http://aclweb.org/anthology/N18-