
補貼之外,滴滴打車背後的技術體系會嚇你一跳
提起滴滴快的,人們的印象似乎還留在2014年初的那場曠日持久的補貼大戰上,殊不知,當人們還在關心合併之後補貼會不會減少時,滴滴快的已經完成了破蛹成蝶的蛻變,從一家營銷驅動公司變成了技術驅動公司。一個全球最大的移動出行資料“超級大腦“即將浮出水面。
滴滴快的:打造移動出行的超級大腦
“分秒”之間的多輪篩選,資料完成的使用者畫像系統,人們點滴的打車軌跡正在匯聚成就一個全新的商業生態。
週五晚上6點40分,李菲(化名)在離家不到3公里的地方,用打車軟體叫了一輛計程車,在不到1分鐘的時間、系統通知了附近43輛計程車之後顯示被搶單,與此同時,李菲的手機上收到一條簡訊:“我們額外支付了司機11元,這部分費用由土豪快的買單。”
這次打車給李菲帶來的愉悅感可想而知:之前望眼欲穿的苦等,現在則分秒可得。不過李菲或許不知道的是,從她按下快的介面的叫車鍵到系統啟動用車通知“分秒”之間,快的後臺已經完成了多輪篩選:根據使用者畫像和用車需求,匹配位置合適的計程車,再結合實時的地理位置和運能狀況確立給後者的補貼金額——這些計算都是在毫秒內實現。甚至在更早之前,快的已經根據她的歷史打車的行為特點,將其劃歸到了“屌絲”的標籤之下,由此她才頻繁收到金額不小的代金券。
2012年開始成立的滴滴快的迅速地網路了360個城市中近兩億“打車族“:每天,600多萬訂單生成,每個小時,數十萬訂單資料匯入滴滴快的後臺。而李菲們所不知道的是,他們的點滴打車軌跡正在匯聚成就一個全新的商業生態,而這也正是滴滴快的等打車軟體的未來疆場。
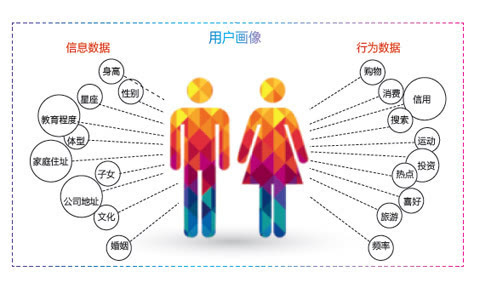
使用者畫像:屌絲和土豪的不同行為軌跡
滴滴快的“土豪式”補貼背後,其實也有著它自己的精打細算。隨著兩家公司的合併,行業已經從粗暴的跑馬圈地走入了精耕細作的時代,要花更少的錢獲取更多的使用者。
精準營銷的前提是對使用者的清晰認知。以簡單的代金券發放為例,滴滴快的的歷史資料呈現出兩大類四種不同的消費習慣—代金券敏感型:發代金券才用、發代金券用的更多;代金券不敏感型:發不發都用,發代金券也不用。在滴滴快的的使用者畫像系統中,上述四種群體會被分別冠以屌絲、普通、中產、土豪的標籤。針對四類客群的運營策略也會全然不同,最直接的就是代金券的刺激頻率以及刺激金額,而對“代金券”免疫的土豪群體,則更多地需要在服務上做文章。
而在實際場景中,影響乘客對應用軟體的使用黏度的因素要遠比代金券複雜得多,在這種情況下,滴滴快的對使用者的“貼身跟蹤”就能及時發現薄弱環節,因此從使用者開啟軟體到退出使用,其間的每一步情況都被快的記錄在案:哪一天退出的,哪一步退出的,退出之後“跳轉”到什麼軟體等等。
據此,滴滴快的也實現了使用者另外一個緯度的歸類,分清哪部分是忠實使用者,哪部分可能是潛在的忠實使用者,哪些則是已經流失的;更進一步來看流失的原因:因為代金券沒有了流失?軟體體驗不好流失?還是等車時間太長而流失?—這些都是下一步精準營銷的依據。
而對於滴滴快的而言,使用者分析不僅僅是針對乘客,也包括司機、計程車公司的所有相關方。儘管基礎資訊大同小異,都包括人的基本資訊、信用、行為資訊等;也有一些通用的刺激手法,比如積分、禮物等。不過,不同的使用者畫像就對應了不同的刺激程度,而結合不同的場景,還是許多特殊的營銷安排。
杭州市場就是一個很典型的例子。基於司機的地理位置資訊,滴滴快的發現每天中午或者是每天晚上10點以後,司機都會聚集在一些固定的地點,可能休息或者就餐。所以滴滴快的就會在這些場所提供一些工作餐或者是優惠食品,通過線下的活動來提升司機和滴滴快的的合作關係。

產品生成的邏輯:更精確地匹配供需
維護好使用者只是一個基礎,最終目的是為了打通供需,生成更加優化的服務和產品。這也正是資料之於打車軟體此類的O2O行業的重要性所在。資料能解決一個核心問題,就是做供需雙方的智慧匹配。
其實也很容易理解,公交、計程車、地鐵都是對出行人群不同需求的對號入座,不過這樣被稱之為“粗暴式”的分類法應用起來效率低下,以一個司空見慣的打車場景為例,在路邊攔車,可能許久都沒有空車經過,或者是好不容易等到的車,司機問了地址之後還可能拒載—呈現一種雜亂無章的狀態。
而在海量的資料基礎之下,出行的需求被不斷細分,而且是實時匹配。例如一個乘客下單之後,需求方的使用者影象和需求同時被識別,結合供方的車輛條件和位置地圖進行第一輪篩選,不過這個看似“正常”的訂單卻不一定符合實際,因為有一些訂單發出來是司機不願意接的,比如高峰時段的擁擠路段,那麼在這個時候就要進行訂單評估和內部調節,結合歷史資料制定一些刺激措施、疊加“乘客自行出的小費”來誘導司機,這樣一個符合供需雙方胃口的“合理”訂單就生成了,下一步要做的就是實時排程,要考慮當時的交通情況、車的朝向、車速、附近是否有突發性事件等等因素,選擇最為優化的方案。
完成了以上的步驟之後,滴滴快的才會把用車需求和獎勵方案推送給經過層層篩選之後的計程車,這樣李菲們打車的成功率大大提升了,而且所用的時間更短。“這是以前所有的產品做不到的,因為不能洞悉消費者的心理。在大資料應用下,消費者和供給方能夠省略中間環節直接議價,這是一個模式上的變革性的突破。”而最終海量的議價資料將提煉成為一種“商業情報”,來推動新的產品和新服務的推出,比如智慧定價系統,以從機場到望京這一段司機不願意接的單為例,可能70%的乘客額外加了20塊錢,少數人加了30塊錢,而有的只願意加10塊錢,那麼系統整合分析以後會得出21元錢是一個更合適的議價,那麼最終的定價可能消費者和司機雙方都可以接受。
因此,以這樣的邏輯推導生成的產品才更能有的放矢,因為其生成不是來自於企業對市場的臆斷,而是直接提煉於供需雙方的心理預期和真實需求。
“回程單”的產品創設就是一個很典型的例子。最初是滴滴快的的資料分析發現一個異常的資料現象,就是司機的搶單意願率在某一個時點會驟然下滑,過一段時間又會反彈,日日如此。通過對這個特殊節點分析,滴滴快的得出一個司機運營的特殊場景,就是司機收工的時間,接下來就是針對性地解決,因為不管司機是交班還是回家,肯定有一個固定的方向—這一點可以通過歷史資料分析出來。那麼滴滴快的要做的就是把同樣去往這個方向的乘客分配給對應的司機;這樣做是否就一定見效?所以下一步就要評估效果,看回程單是否真正提高了司機的搶單意願,確定之後才能作為常規產品推出。
產品的細分應用場景將會越來越依賴於大資料分析,從資料中洞察需求與商機,再結合大資料提供應用解決方案,將變成未來產品迭代的常規運作模式之一。這也是滴滴快的產品的生成邏輯。
由“女神去哪兒”所引發的盈利模式暢想
不過,打車軟體可以讓傳統的商業模式更加高效,更加酷,那麼它的盈利模式又是什麼?
當然,可以簡單地收取一種平臺佣金:司機做成一單交易,打車軟體從中進行提成。且不說現在很少有司機願意支付這種新興的“份子錢”,而且這樣一種缺少差異性的盈利模式需要寄生於壟斷的生態條件下,而打車軟體市場顯然不符合這個條件。
機會正隱藏在資料密碼中。2014年,快的打車釋出了名為“七夕,女神都去哪兒了”的全國各地女生用車報告。資料顯示,8月2日七夕節當日女生叫車時間最高峰為22點10分,其中叫車目的地為飯店佔比最高的前五名分別為廣州(49%)、重慶(40%)、上海(38%)、北京(35%)和深圳(34%),叫車目的地為酒店的佔比前五名則分別是,長沙(53%)、深圳(49%)、杭州(46%)、上海(45%)、北京(43%)。
對於滴滴快的來說,這不是娛樂八卦噱頭,這裡至少暗含了兩大“寶藏”,一個是知道特定時間的特定人群的聚集地,另一個則是特定人群在某段時間的消費行為。
滴滴快的在接下來的4、5月份將要上線的需求預測系統和運能預測系統就是基於對上述第一點的掌握,比如通過已經發布的滴滴打車熱力圖,司機藉此可以看到整個北京城的實時用車需求:什麼位置需求旺盛,同時運能嚴重不足。這樣也就避免了司機“聽天由命”的狀態:在馬路上毫無目的地空轉。
而掌握了某一群體特定時間的消費行為這件事則具有更大的想象空間,基於乘客目的地周邊的商鋪而提供的廣告服務,也是滴滴快的未來業務一個最重要的落腳點。這或許將顛覆傳統的網際網路廣告模式——傳統的廣告,消費者是比較被動的接受者,最終形成真實的購買行為的轉化率很低,而打車軟體承載的是人、時間、空間多維度結合的生活場景,個性化推薦更加投其所好,貼近實際,轉化率會高得多。這個判斷也來自於滴滴快的大量的資料分析,使用者研究顯示了其中30%有非常明確的商業需求,50%是潛在的消費群,那麼滴滴快的就可以在使用者出行途中來推送目的地的商鋪優惠資訊。
這只是一個粗略的模式雛形,如果有更細緻的使用者行為分析就可以使廣告推送更加的精準。比如滴滴快的對使用者行為跳轉的研究發現,使用者在叫車結束退出APP之後,很多會開啟團購網站搜尋電影票、餐飲券等等,那麼如果一個使用者想打車去星美國際影城,那麼滴滴快的和團購網站合作推出的團購票說不定就會正中使用者的心思。
這類結合出行過程和目的地分析的廣告模式將會煥發更大的生命力,同時也廣泛適用於其他的出行情境,包括計程車、專車、地鐵、公交一系列的出行方式在內。“只和人和目的地相關,可以在大的出行生態裡面做成相對通用的廣告系統,後續可以和更多其他的APP合作。”據滴滴快的內部人士透露,這一套讓“資料變現”的系統將在5月底的時候投入執行。

跨界的資料“火花”
儘管滴滴快的野心不小,想要構建一個全新的廣告“生態”,不過這顯然不是滴滴快的憑藉一己之力所能實現的,必須藉助於外部資料的匯入——這恐怕也是大資料應用最基本的要求,那就是開放和共享。
與阿里和美團等的合作就實現了雙方資料的相互補充,電商和團購企業缺乏出行資料,而滴滴快的目前缺失的是使用者的消費資料和信用資料,在此基礎上雙方就可以共建使用者畫像體系:工作地點、家庭地點、消費情況、價格敏感度等等。
在一個完整的使用者影象下,廣告推送就會更加的精準。比如定位到一個北京使用者打車去西單,在分析出其消費偏好的基礎上,就可以針對性地傳送特定商場特定店鋪的某一類產品的優惠資訊。“量身定做的實時實地的廣告價值將遠遠超過傳統廣告盲目推送的方式。”一些針對節日的廣告型別也會應運而生。以七夕節為例,就可以首先圈定跟節日消費相關的群體,提前兩天推送花店資訊,可以在節日當天直接送花上門,甚至可以製造一些小“浪漫”:或許可以設想一下當你的女朋友看到一輛豪車來接她下班時的驚喜,而車上還放著她喜歡的音樂,外加一束嬌豔的玫瑰花。
完美的暢想還不得不面對現實中固有的一些問題,一個來自於不同的行業標準和資料標準所帶來的資料通用的難題,而即便在技術共享上不存在障礙,而協商機制的建立也將是一個漫長的“對話”。
資料的價值評判每一家都是不一樣的,那麼就需要跨界的共贏機制的建立,這個在歷史經驗上是不存在的,只能去摸索磨合,這個過程肯定是痛苦的。
資料驅動模式的基礎:技術投入
儘管還存在不少待解難題,如今開始把關注焦點轉向資料驅動模式的快的,都已經與“補貼大戰”時不可同日而語。因為任何的新興業務,不論發展初期如何勢如破竹,也必然要經過一個商業模式的探索和沉澱,否則最終會被“價格戰”拖得精疲力竭。
經過初期的野蠻生長之後,還想獲得跨越式發展,就肯定需要在技術上的重點投入。補貼大戰之後,滴滴快的開始組建自己的大資料團隊,從百度、騰訊、阿里的雲端計算和大資料部門招了幾百號人,經過了最初的苦活、髒活、累活的痛苦歷程,進行了資料匯入、清洗、儲存、結構化等一系列最基礎的處理,最終建成了滴滴快的的大資料體系。據相關負責人介紹,目前擴建後團隊的核心力量正在進行大資料2.0系統的研發。這套內部代號為“地平線系統”的大資料架構,克服了1.0系統中突出的資料數量與資料質量、處理速度之間的矛盾,實現了資料純度、處理速度的跨越式升級。
這個“超級大腦”支撐了滴滴快的大資料應用所需要的所有基礎資料,在此之上是支援產品、商業、運營商業化的團隊,每個配備了20個人左右。這樣的架構實際上避免了基礎資料和應用資料之間的“汙染”問題,比如一個需求場景形成了A的畫像集合,其中結合B行業又會出現一個AB子集,應用到特殊的場景C之後又會形成一個同時滿足ABC的集合。如果每次都從基礎資料抽取的話,就很容易影響基礎資料的穩定性。
清晰的資料架構對於“每秒(毫秒)都產生海量資料”的快的來說,重要性不言而喻。而今,數百臺的機器支撐著的滴滴快的大資料系統,就像是公司的“心臟”:業務規模越大,越是重要。
這種投入不是任何一個公司都能夠負擔的,卻是每一個公司都應該及早想清楚的,過早投入的話,對精力和資本消耗太大,不過如果之前缺乏考慮,後面就要做很多工作才能把之前錯失的那些資料漏洞補回來。對於早期一直爭搶使用者市場、而無暇顧及資料應用的滴滴快的來說,這恐怕也是寶貴的“經驗之談”了。
原文地址:http://tech.huanqiu.com/internet/2015-05/6341834.html
相關推薦
補貼之外,滴滴打車背後的技術體系會嚇你一跳
提起滴滴快的,人們的印象似乎還留在2014年初的那場曠日持久的補貼大戰上,殊不知,當人們還在關心合併之後補貼會不會減少時,滴滴快的已經完成了破蛹成蝶的蛻變,從一家營銷驅動公司變成了技術驅動公司。一個全球最大的移動出行資料“超級大腦“即將浮出水面。 滴滴快的
想入行 AI,別讓那些技術培訓坑了你...
評價 -i cat 了解 產品 另有 興趣 自己的 看書 引子 IT 行業發展迅速,各種新名詞此起彼伏。身處這樣一個熱點行業,學習是必須的。不打算成為終身學習者的程序員,失業就在明天。可是,怎麽學呢?都已經畢業了,每天要上班,不能像以前讀書的時候,整天只是學習,學什麽都有老
Houdini技術體系 基礎管線(一) : Houdini與Houdini Engine的安裝
ins ice serve pro 並集 wid ima mage width Houdini 下載與安裝 在官網 https://www.sidefx.com/download/ 下載最新的Production Build 版本,當前是16.5版本,需要註冊帳號 P
百度谷歌都作惡,但到底哪家技術更厲害?你會選擇用哪個?
策劃編輯 | Vincent 作者 | Vincent 編輯 | Natalie AI 前線導讀: 前幾日,人民日報在推特和 Facebook 上釋出歡迎谷歌迴歸的訊息,並強調前提是要遵守中國的法律。耐人尋味的是,這兩個平臺上的訊息沒多久就全部刪除。
TCP 三次握手(相當於寄信需要回執,第一次握手:我寄給你一封信。第二次握手:你回我一封信。第三次握手:我再給你一個回執,這樣你才能確認我收到信了)
需要 flags 並發 如果 details live 丟失 tail 進行 TCP 連接是通過三次握手進行初始化的。三次握手的目的是同步連接雙方的序列號和確認號並交換 TCP 窗口大小信息。以下步驟概述了通常情況下客戶端計算機聯系服務器計算機的過程: 1. 客戶端向服務器
12個不為人知培養你潛意識的小習慣,會讓你一天更有效率
春天已經徹底來了,大家有沒有幹勁十足地建設社會主義和諧社會呀。但你的幹勁能持續多久呢?與其天天看雞湯文打雞血,不如從潛意識中激勵自己奮發向上。 這裡有 12 個小習慣,會在潛意識裡幫助你煥發激情,幹勁十足,走向人生巔峰。 1、在你每晚臨睡前,請像告訴 Siri 一樣
轉給更多女孩子知道!出門在外除了更加小心,這些APP或許會救你一命!
21歲女孩深夜遇害,在惋惜的同時,相信也再次給大家,尤其是女孩子們敲響了警鐘,出門
池化技術到達有多牛?看了執行緒和執行緒池的對比嚇我一跳!
情商高的人是能洞察並照顧到身邊所有人的情緒,而好的文章應該是讓所有人都能看懂。 **尼采曾經說過:人們無法理解他沒有經歷過的事情**。因此我會試著把技術文章寫的儘量具象化一些,力求讓所有人都能看懂,所以在正式開始之前,我們先從兩個生活事例說起。 尼采帥照: 
前言 系統架構師是一個既需要掌控整體又需要洞悉區域性瓶頸並依據具體的業務場景給出解決方案的團隊領導型人物。一個架構師得需要足夠的想像力,能把各種目標需求進行不同維度的擴充套件,為目標客戶提供更為全面的需求清單。 從一個程式設計師到架構師是一個很大的變化,架構師需要從大的方面考慮,而不只是考慮
用兩種方式估計北京一年出租出去的房子數量,並互相驗證。(滴滴打車-2014)
延伸 自由職業 方式 個人 學術 題目中的 其他 驗證 工作 詳解: 可以采取兩種方法。 方法一: (1)分析問題 北京一年出租出去的房子數量,租房是一個強需求,穩定有房的居民不會去租房,無房但已經租房的人不會去租房,無房且需要居住房子的人才會去租房,也是我們需要關註的群體
TFBOYS飯票上線引熱議,騙局之外,區塊鏈技術能重構娛樂產業嗎?
域名 行為 自己的 上線 模式 代言 系統 聯系方式 距離 昨天,TFBOYS飯票(TFBC)上線的消息開始刷屏互聯網。這個假借TFBOYS名義發起的,以提升TFBOYS價值為口號的偽區塊鏈項目,目前已經有接近2600人參加。連娛樂圈都開始摻和進來的時候,區塊鏈與大眾的距離
網站技術問題除了自己琢磨之外,亦可求助他人
網站技術這兩天一直在研究織夢後臺采集功能,以前是很少用織夢的,emlog和wordpress程序居多,現在發現在這方面自己的匱乏,只能盡快的彌補過去的不足之處,織夢運用之廣,企業網站,門戶網站,資訊類網站,自媒體頭條等等,覆蓋了各個行業,熟悉是必要的功課,以後會常和它打交道,不熟悉怎麽搞? 從網站的搭建
Java架構師分享自己的技術體系,程序員如何從碼農到專家
https 都是 全面 height contain auto 線程 for analysis 一、源碼分析 源碼分析是一種臨界知識,掌握了這種臨界知識,能不變應萬變,源碼分析對於很多人來說很枯燥,生澀難懂。 源碼閱讀,我覺得最核心有三點:技術基礎+強烈的求知欲+耐心。 我
全球首個AI合成主播發布,效果以假亂真!揭祕背後技術原理
邊策 李根 發自 凹非寺 量子位 報道 | 公眾號 QbitAI 搜狗又在烏鎮世界網際網路大會上搞了大新聞。 2016年,王小川在正式論壇裡秀出AI同傳,那是機器實時翻譯技術,首次在高規格國際會議上實戰應用。 而這一次,依然世界網際網路大會,搜狗聯手新華社,釋
人工智慧:一圖看懂人工智慧,人工智慧知識體系【歷史--內涵和外延--未來學--對社會經濟的影響--技術體系--應用領域】
圖片從 IT派 轉載 迎接AI時代的三種方式: 1.讓AI能,即創造和製造AI,並讓AI正常工作 2.讓AI賦能,利用別人創造的AI,賦能各行各業,即利用AI這一工具去服務使用者讓使用
阿里、百度、京東一線網際網路架構師都在用的技術體系,高併發,微服務,軟體系統架構
可以說,Java是現階段中國網際網路公司中,覆蓋度最廣的研發語言,掌握了Java技術體系,不管在成熟的大公司,快速發展的公司,還是創業階段的公司,都能有立足之地。 有不少朋友問,除了掌握Java語法,還要系統學習哪些Java相關的技術,今天分享一個,網際網路Java技術學習路線圖。 一:常見模式
除了技術知識之外,我還需要了解什麼知識?
有時候真的感覺,知識的貧乏,讀書能夠改變人的一生或者一個人的命運吧~多讀書總歸沒有錯。 1.比特幣相關知識 2.全球經濟為什麼崩盤,繼上次金融危機又發生了什麼事情 3.國家的經濟政策 4.為什麼虛擬加密貨幣會興起? 5.比特幣與區塊鏈之間的關係? 6.什麼是區
物聯網技術體系、網路架構和產業鏈條,入門知識大全
最初的物聯網概念,國內普遍認為的是MIT Auto-ID中心Ashton教授1999年在研究RFID時最早提出來的,當時還被稱之為感測網,其定義是:通過射頻識別(RFID)、紅外線感應、全球定位系統、鐳射掃描器等資訊感測裝置,按照約定的協議,任何物品與網際網路相連線,進行資訊
Spark技術體系與MapReduce,Hive,Storm幾種技術的關係與區別
大資料體系架構: Spark記憶體計算與傳統MapReduce區別: SparkSQL與Hive的區別: SparkSQL替換的是Hive的查詢引擎,Hive是一種基於HDFS的資料倉庫,並且提供了基於SQL模型的,針對存了大資料的資料倉庫,進行分散式互動查