
Thinking in SQL系列之六:資料探勘Apriori關聯分析再現啤酒尿布神話
原創: 牛超 2017-03-19
Mail:[email protected]
說起資料探勘機器學習,印象中很早就聽說過關於啤酒尿布的神話,這個問題經常出現在資料倉庫相關的文章中,由此可見啤酒尿布問題對資料探勘領域影響的深遠端度。先看看它的成因:“啤酒與尿布”的故事產生於20世紀90年代的美國沃爾瑪超市中,沃爾瑪的超市管理人員分析銷售資料時發現了一個令人難於理解的現象:在某些特定的情況下,“啤酒”與“尿布”兩件看上去毫無關係的商品會經常出現在同一個購物籃中,這種獨特的銷售現象引起了管理人員的注意,經過後續調查發現,這種現象出現在年輕的父親身上,買尿布的同時經常順便帶一瓶啤酒回家。
在對這個問題津津樂道的同時,可能並不是所有的人都會關注它的實現細節。啤酒尿布問題歸屬於關聯分析,即從一組資料集中發現項之間的隱藏關係,是一種典型的無監督學習。關聯規則的項集可以是同構的如啤酒->尿布,也可以是異構的如夏天->空調備貨。
本篇文章Apriori演算法主要是基於頻繁集的關聯分析,也是十大經典資料探勘演算法之一,本文中所出現的關聯分析預設都是指基於頻繁集的關聯分析。
以下為個人收集整理的Apriori演算法的相關描述以輔助記憶,如有誤導之處,請指正。
項的集合稱為項集。包含k個項的項集稱為k項集。
項集I表示為{i1,i2,...ik-1,ik},i可以是啤酒、尿布、牛奶等等。
集合D表示訓練集,訓練集中對應多筆交易(可理解為購物小票),每筆交易對應都是I的子集(不同商品)。
候選項集,經過關聯組合構造的項集。候選項集經過剪枝處理形成頻繁項集。
頻繁項集,即滿足最小支援度條件的項集,同時它的所有子集必須是頻繁的,理解為經常同時出現在同一購物籃中的一組商品。
支援度公式:support = P(A並B),由於訓練集交易總次數相對固定,因此可簡化為A並B的發生頻次(分母相同可忽略)。
Apriori演算法具有一個非常重要的性質,即先驗性質,說的是頻繁項集的所有子集也一定是頻繁的。一般在演算法的實現中利用了該性質的反語,即一個項集如果不是頻繁項集,其超項集也一定不是頻繁項集。利用該性質可以大大減少演算法對資料的遍歷次數。
兩個K項集(頻繁集)需要進行連線以生成超項集(候選集),連線條件是二者有K-1項相同或者K為初始頻繁集。
極大頻繁項集,滿足最小支援度條件的最終的頻繁項集。
關聯規則表示為A->B,其中A、B均為I的子集,且A與B的交集為空,
根據計算出來的K項集最終推導的關聯規則要滿足置信度條件,理解為大於已設定的概率值。
置信度公式:confidence = P(A)|P(A並B) = support(A並B)/support(A)
根據上面的描述,我們可以發現,這個演算法多次出現候選集、頻繁集、子集的概念,如何構建與操作集合是Apriori演算法的關鍵,而最擅長集合操作的語言正是SQL。也是基於本系列,Thinking
in SQL,看看如何用SQL來再現經典的啤酒尿布銷售神話。
與窮舉法不同,根據頻繁集的性質,Aprior演算法採用逐層搜尋的方法,包含以下5個步驟:
1.首先根據集合D初始化候選集(K-1),依據最小支援度條件得到K-1項頻繁集。
2.K-1項頻繁集自連接獲取K項候選集。第一輪K-1項頻繁集就是在步驟1構造的,而其他輪是由步驟3得到(頻繁集由候選集剪枝得到)。
3.對於候選集進行剪枝。如何剪枝呢?如果候選集的支援度小於最小支援度,那麼就會被剪掉;另外,候選集的子集有不是頻繁集的,也會被剪掉(這步處理較為複雜)。
4.遞迴步驟2,3,演算法的終止條件是:如果自連線得到的已經不再是頻繁集,取最後一次得到的頻繁集作為結果。
5.構建候選的關聯規則,並利用最小置信度剪枝以形成最終的關聯規則。
對這個演算法有進一步認識之後,下面就需要著手實現了,簡要的說明一下我的思路:
1. 構建並匯入用於機器學習的訓練集
2. 建立集合型別以便於SQL與PLSQL互動
3. 建立支援度計算函式,用於輸出項集支援度
4. 建立構建極大頻繁集的函式(遞迴生成頻繁集,剪枝操作依賴步驟3的支援度函式)
5. 主體查詢SQL,利用步驟4建立的函式,構建關聯規則,根據最小置信度剪枝輸出結果
具體實現步驟如下(個人環境ORACLE XE 11.2):
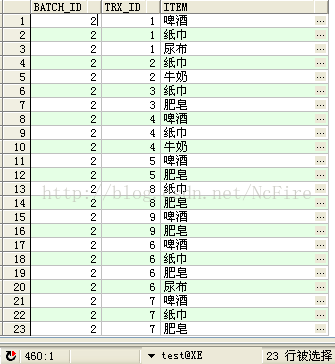
1.構建訓練集D,建立表DM_APRIORI_LEARNING_T用於存放訓練集
CREATE TABLE DM_APRIORI_LEARNING_T
(
BATCH_ID NUMBER ,--批次ID,區分訓練集D
TRX_ID NUMBER ,--交易票據ID
ITEM VARCHAR2(100) --商品
) ;
2. 建立集合型別以便SQL與PLSQL互動。每個項集的項數可能不相同,歸屬於一個項集ID。
CREATE OR REPLACE TYPE DM_APRIORI_SET_OBJ IS OBJECT (
GID NUMBER ,--項集ID
ITEM VARCHAR2(100),--項
SUPPORT NUMBER --支援度
);
CREATE OR REPLACE TYPE DM_APRIORI_SET_TAB IS TABLE OF DM_APRIORI_SET_OBJ;3. 建立函式用於項集支援度計算,返回項集支援度的集合,依賴APRIORI訓練集表,其中P_BATCH_ID用於界定訓練集,P_TAB用於傳入候選項集,重點關注如何判斷項集能被訓練集全匹配以及匹配次數的SQL實現,需要面向集合來思考,即Thinking in SQL。
CREATE OR REPLACE FUNCTION FUN_DM_APRIORI_SUPPORT(P_BATCH_ID NUMBER,
P_TAB DM_APRIORI_SET_TAB,
P_DEBUG NUMBER DEFAULT 0)
RETURN DM_APRIORI_SET_TAB IS
RTAB DM_APRIORI_SET_TAB; --結果頻繁集
BEGIN
WITH TA AS
(SELECT A.GID, A.ITEM, COUNT(1) OVER(PARTITION BY A.GID) KCNT --每組項的個數
FROM TABLE(P_TAB) A --候選集
),
TB2 AS
( --匹配事實,以便計算支援度
SELECT A.GID,
A.ITEM,
A.KCNT,
T.TRX_ID GID2,
COUNT(1) OVER(PARTITION BY A.GID, T.TRX_ID) MATCH_CNT --每組匹配交易次數
FROM TA A
JOIN DM_APRIORI_LEARNING_T T
ON A.ITEM = T.ITEM
AND T.BATCH_ID = P_BATCH_ID) --計算項集GID在訓練集中同時出現的頻次SUPPORT
SELECT DM_APRIORI_SET_OBJ(GID, NULL, COUNT(1) / KCNT) --計算支援度
BULK COLLECT
INTO RTAB
FROM TB2
WHERE MATCH_CNT = KCNT --項數與交易匹配次數相同才算全匹配
GROUP BY GID, KCNT;
RETURN RTAB;
END;
4. 建立遞迴函式用於構造K項頻繁集的超集,根據指定引數遞迴地構造極大頻繁項集,而且這裡可以指定P_MAXLVL最大K值以限制遞迴層次(預設無限制),重點關注頻繁集連線構建候選超集的SQL實現,這是該演算法的核心部分,Thinking in SQL,遮蔽ROW BY ROW迴圈處理的思路,注意如果沒有面向集合的思維可能會迷失。
CREATE OR REPLACE FUNCTION FUN_DM_APRIORI_FREQ_SET --Apriori關聯規則剪枝
(P_BATCH_ID NUMBER, --批次
P_TAB DM_APRIORI_SET_TAB, --前一輪傳遞的頻繁集
P_CURK NUMBER, --構造頻繁集前的K原值
P_SUPPORT NUMBER, --最小支援度
P_MAXLVL NUMBER DEFAULT NULL --最大遞迴層次,最大K值
) RETURN DM_APRIORI_SET_TAB IS
ATAB DM_APRIORI_SET_TAB; --前一輪傳遞的頻繁K-1項集
RTAB DM_APRIORI_SET_TAB; --構造生成的頻繁K項集
BEGIN
--初始化ATAB
IF P_CURK = 1 THEN
SELECT DM_APRIORI_SET_OBJ(ROWNUM, ITEM, SUPPORT)
BULK COLLECT INTO ATAB
FROM (SELECT ITEM, COUNT(1) SUPPORT
FROM DM_APRIORI_LEARNING_T
WHERE BATCH_ID = P_BATCH_ID
GROUP BY ITEM
HAVING COUNT(1) >= P_SUPPORT);
IF P_MAXLVL = 1 THEN
RETURN ATAB;
END IF;
ELSE
ATAB := P_TAB;
END IF;
WITH TA AS
(SELECT * FROM TABLE(ATAB)),
TB0 AS
( --K=1時構造K+1項集
SELECT RANK() OVER(ORDER BY A.GID, B.GID) GID, A.ITEM ITEM1, B.ITEM ITEM2
FROM TA A
JOIN TA B
ON A.ITEM < B.ITEM
AND P_CURK = 1 --注意這個條件開關
),
TB AS
( --K>1時構造K+1項集
SELECT RANK() OVER(ORDER BY GID1, GID2) GID, GID1, GID2, ITEM
FROM (SELECT A.GID GID1,
B.GID GID2,
A.ITEM,
COUNT(1) OVER(PARTITION BY A.GID, B.GID) MATCH_CNT
FROM TA A
JOIN TA B
ON A.ITEM = B.ITEM
AND A.GID < B.GID)
WHERE P_CURK > 1
AND MATCH_CNT = P_CURK - 1 --項集連線條件:K-1項相同
),
TC AS
( --候選集構造
SELECT DISTINCT C.GID, A.ITEM --非第一輪的候選集構造
FROM TB C
JOIN TA A
ON (C.GID1 = A.GID OR C.GID2 = A.GID)
AND A.ITEM NOT IN (SELECT K.ITEM FROM TB K WHERE K.GID = C.GID)
UNION ALL
SELECT GID, ITEM
FROM TB
UNION ALL --K=1分段
SELECT GID, ITEM --初始候選集
FROM TB0 UNPIVOT(ITEM FOR COL IN(ITEM1, ITEM2))),
TE AS
(SELECT GID,
ITEM,
LISTAGG(ITEM) WITHIN GROUP(ORDER BY ITEM) OVER(PARTITION BY GID) VLIST --項集LIST,便於計算
FROM TC),
TF AS
( --K+1項集
SELECT ROWNUM RNUM, GID, ITEM
FROM TE A
WHERE GID = (SELECT MIN(GID) FROM TE B WHERE A.VLIST = B.VLIST)),
--以下為計算所有K集子集是否全部頻繁
TG AS
( --K+1=>K集子集 C(K+1,K)= C(K+1,1)
SELECT A.RNUM, A.GID, B.ITEM
FROM TF A
JOIN TF B
ON A.GID = B.GID
AND A.ITEM != B.ITEM),
TH AS
(SELECT G.RNUM, G.GID, COUNT(1) OVER(PARTITION BY G.GID) CNT2 --每個群中匹配K次的項數
FROM TG G
JOIN TA A --TA為已知的頻繁項集
ON G.ITEM = A.ITEM
GROUP BY G.RNUM, G.GID, A.GID
HAVING COUNT(1) = P_CURK --K集元素需各自匹配K次
),
TI AS
(SELECT * FROM TH WHERE CNT2 = P_CURK + 1 --留下頻繁項集
),
TKC AS
( --候選項集(所有子集頻繁)
SELECT TF.GID, TF.ITEM
FROM TF
JOIN TI
ON TF.RNUM = TI.RNUM
AND TF.GID = TI.GID),
TKCA AS
( --構造候選子集引數
SELECT CAST(MULTISET (SELECT GID, ITEM, NULL FROM TKC) AS
DM_APRIORI_SET_TAB) STAB
FROM DUAL),
TK2 AS
( --剪枝 過濾支援度
SELECT TKC.*, TS2.SUPPORT
FROM TKCA
CROSS JOIN TABLE(FUN_DM_APRIORI_SUPPORT(P_BATCH_ID, TKCA.STAB)) TS2 --候選子集支援度
JOIN TKC
ON TKC.GID = TS2.GID
AND TS2.SUPPORT >= P_SUPPORT)
SELECT DM_APRIORI_SET_OBJ(GID, ITEM, SUPPORT) BULK COLLECT
INTO RTAB
FROM TK2;
IF P_MAXLVL = P_CURK + 1 THEN
RETURN RTAB; --滿足最大項
ELSIF RTAB.COUNT = 0 THEN
RETURN ATAB; --項集為空,取前次項集
ELSE
--遞迴取項集
RETURN FUN_DM_APRIORI_FREQ_SET(P_BATCH_ID,
RTAB,
P_CURK + 1,
P_SUPPORT,
P_MAXLVL);
END IF;
END;
函式建立好了之後,可以做幾個簡單的查詢以幫助理解:
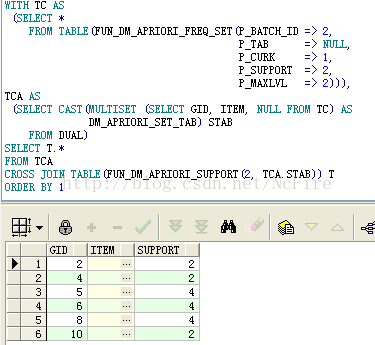
a.查詢極大頻繁項集的計算結果,可以看到結果一共2個3項集
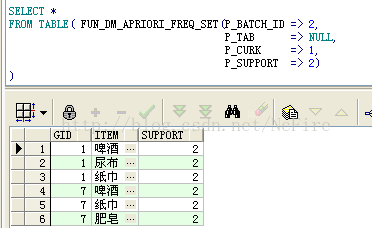
b.查詢初始項集,指定最大搜索層次為1,結果是6個1項集
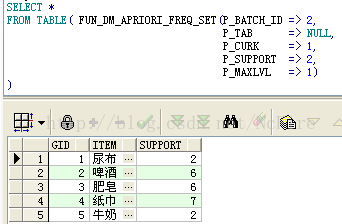
c.查詢頻繁2項集,指定最大搜索層次為2,結果是6個2項集
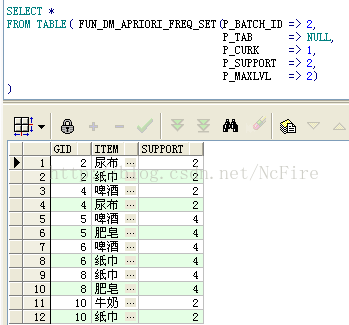
d.查詢頻繁2項集對應的支援度,注意CAST與MULTISET的用法,不解釋了
5. 主體查詢SQL,利用步驟3、4建立的函式,構建關聯規則,根據最小置信度剪枝輸出結果,為了保持通用性,使用引數集PARAMS(支援度2,置信度60%)來驅動全盤,Thinking in SQL,一氣呵成,如下:
WITH PARAMS AS
(SELECT 2 BATCH_ID, 2 SUPPORT, 0.6 CONF FROM DUAL),
TA AS
( --頻繁集
SELECT GID, ITEM, SUPPORT, COUNT(1) OVER(PARTITION BY GID) KCNT --集的項數
FROM PARAMS P
CROSS JOIN TABLE(FUN_DM_APRIORI_FREQ_SET(P.BATCH_ID, NULL, 1, P.SUPPORT))),
TB AS
( --k集的子集準備
SELECT ROWNUM GID,
TA.GID OGID,
TA.ITEM,
TA.KCNT,
TA.SUPPORT KSUPPORT,
LEVEL LVL,
'{' || LTRIM(SYS_CONNECT_BY_PATH(ITEM, ','), ',') || '}' ITEM_LIST --項集描述,用於規則輸出
FROM TA
CONNECT BY LEVEL <= KCNT - 1
AND PRIOR ITEM < ITEM
AND PRIOR GID = GID),
TC AS
( --k集的子集
SELECT A.GID, A.OGID, A.ITEM_LIST, A.KCNT, A.LVL, B.ITEM
FROM TB A
JOIN TB B
ON A.OGID = B.OGID
AND B.LVL <= A.LVL
AND B.GID = (SELECT MAX(C.GID)
FROM TB C
WHERE C.OGID = B.OGID
AND C.LVL = B.LVL
AND C.GID <= A.GID)),
TCA AS --組裝集合引數
(SELECT BATCH_ID,
SUPPORT,
CONF,
CAST(MULTISET (SELECT GID, ITEM, NULL FROM TC) AS
DM_APRIORI_SET_TAB) STAB
FROM PARAMS),
TD AS
( --子集支援度計算
SELECT A.GID,
B.OGID,
B.KCNT,
B.KSUPPORT,
B.LVL,
B.ITEM_LIST,
A.SUPPORT,
TCA.CONF
FROM TCA
CROSS JOIN TABLE(FUN_DM_APRIORI_SUPPORT(TCA.BATCH_ID, TCA.STAB)) A
JOIN TB B
ON A.GID = B.GID),
TE AS
(SELECT A.GID AGID,
A.OGID,
A.ITEM_LIST AITEM_LIST,
A.KSUPPORT,
A.SUPPORT,
B.GID BGID,
B.ITEM_LIST BITEM_LIST,
A.CONF,
A.KSUPPORT / A.SUPPORT REAL_CONF --置信度結果
FROM TD A
JOIN TD B
ON A.OGID = B.OGID
AND A.LVL + B.LVL = A.KCNT --a並b 屬於極大頻繁集的元素
AND NOT EXISTS ( --a交b為空
SELECT ITEM
FROM TC
WHERE GID = A.GID
INTERSECT
SELECT ITEM FROM TC WHERE GID = B.GID))
SELECT AITEM_LIST || '->' || BITEM_LIST RULE_DESC, REAL_CONF
FROM TE
WHERE REAL_CONF >= CONF --剪枝 過濾置信度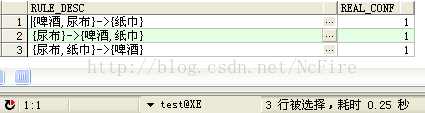
啤酒尿布這類經典演算法能夠讓我們拓展思維,並非侷限於縱向拓展(術業專攻,自認能力有限),否則會陷入“太學術”的誤區死角。跳出深究演算法本身,也不要只關注購物籃分析,通過頭腦風暴地橫向思維擴充套件可以發現很多應用場景。例如身為開發DBA在工作過程中經常會分析一類問題:哪些表會經常同時被關聯查詢;哪些列會同時出現在謂詞中;如何建立組合索引、冗餘加速列、冗餘加速表會對系統整體效能有戰略提升效果。可以通過定期挖掘分析生產庫的SQL形成訓練集,通過操控頻繁集找到表間關聯項集,謂詞列關聯項集與關聯規則,也可以結合尤拉定理給出支援度權重。從而為高效的資料庫設計運營提供有效的決策依據。當然現實中的開發工作無法讓人思考太多戰略技術層要素,對效能的要求也只不過是追求一時的快感。因此雖然工作N年很多設想只能區域性落地。敏捷+結果為導向難免會讓人懷揣游擊戰的心理,相信很多人會有同感。
回到主題,SQL語言處理資料有天生的優勢,Thinking in SQL,面向集合思考問題,通過關係運算(並、交、乘、除)處理資料,ORACLE高效的SQL引擎會負責迴圈處理。結合ORACLE高階開發技巧,通過不斷地總結歸納,注入靈魂演算法,ORACLE資料庫也能定製機器學習能力。
相關推薦
Thinking in SQL系列之六:資料探勘Apriori關聯分析再現啤酒尿布神話
原創: 牛超 2017-03-19 Mail:[email protected] 說起資料探勘機器學習,印象中很早就聽說過關於啤酒尿布的神話,這個問題經常出現在資料倉庫相關的文章中,由此可見啤酒尿布問題對資料探勘領域影響的深遠端度。先看看它的成因:“啤酒
Thinking in SQL系列之五:資料探勘K均值聚類演算法與城市分級
原創: 牛超 2017-02-21 Mail:[email protected] 引言:前一篇文章開始不再介紹簡單演算法,而是轉到資料探勘之旅。感謝CSDN將我前一篇機器學習C4.5決策樹演算法的博文推送到了首頁,也非常榮幸能夠得到雲和恩墨的蓋老師的
Thinking in SQL系列之四:資料探勘C4.5決策樹演算法
原創: 牛超 2017-02-11 Mail:[email protected] C4.5是一系列用在機器學習和資料探勘的分類問題中的演算法。它的目標是監督學習:給定一個數據集,其中的每一個元組都能用一組屬性值來描述,每一個元組屬於一個互斥的類別中的某一
Office 365 系列之六:通過管理中心批量導入用戶
office365 創建賬號、分配許可 本章節跟大家介紹通過 Office 365 管理中心批量導入用戶並分配許可。 登陸 Office 365 管理中心,切換到“活動用戶”頁面,點擊“批量添加” 點擊“下載僅具有標頭的 CSV 文件”或“下載具有標頭和示例用戶信息的 CSV
mongo 3.4分片集群系列之六:詳解配置數據庫
初始化 kpi 更新 並且 color tag 成員 gin sha 這個系列大致想跟大家分享以下篇章(我會持續更新的↖(^ω^)↗): 1、mongo 3.4分片集群系列之一:淺談分片集群 2、mongo 3.4分片集群系列之二:搭建分片集群--哈希分片 3、mongo
Exchange 2013系列之六:郵箱高可用DAG部署
Exchange AD Windows Server 數據庫可用性組 (DAG) 是內置於 Microsoft Exchange Server中的高可用性和站點恢復框架的基礎組件。DAG 是一組郵箱服務器(最多可包含 16 個郵箱服務器),其中承載了一組數據庫,可提供從影響單個服務器或數據庫的故障
碼農裝13寶典系列之六:更換流暢的國內映象源
編輯配置檔案:/etc/apt/sources.list deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse deb https://mirrors.tun
ORACLE PL/SQL程式設計之六: 把過程與函式說透(窮追猛打,把根兒都拔起!)
本篇主要內容如下: 6.1 引言 6.2 建立函式 6.3 儲存過程 6.3.1 建立過程 6.3.2 呼叫儲存過程 6.3.3 AUTHID 6.3.4 PRAGMA AUTONOMOUS_TRANSACTION 6.3.5 開發儲存過程步驟 6.3.6
skyfans之每天一個Liunx命令系列之六:free
今天我們繼續來學習linux基本命令 今天學習的是什麼命令呢,那就是PERFORMANCE MONITORING AND STATISTICS(效能監測與統計)中的 free (記憶體)命令。 此命令是我們作為一個運維人員必須要知道並且會的命令。 Ready
Docker系列之六:Volume 卷的使用——在Dockerfile中的用法
系列連結 Docker系列之一:Docker介紹及在Ubuntu上安裝 Docker系列之二:Docker 入門 Docker系列之三:使用Docker映象和倉庫 Docker系列之四:Dockerfile的使用 Docker系列之五:Volume 卷的使用——以Redis為例
.Neter玩轉Linux系列之六:Linux下MySQL的安裝、配置、使用
基礎篇 實戰篇 一、Linux安裝MySQL (1)下載安裝包:https://dev.mysql.com/downloads/mysql/ (2)解壓並安裝 命令:tar zxvf 檔名 解壓完成之後,重名一下資料夾名字。 命令:mv 檔名1
玩轉大資料系列之二:資料分析與處理
經過了資料採集和同步之後,就可以在阿里雲上進行資料分析和處理,來玩轉您的資料了。本文向您介紹在阿里雲大資料各產品中,以及各產品之間怎樣來完成您的資料處理和資料分析。 MaxCompute 基於MaxCompute的大資料計算(MaxCompute + RDS) 使用MaxCompute分析IP
玩轉大資料系列之三:資料報表與展示
經過了資料採集與資料同步、資料分析和處理,我們應該考慮將處理好的資料做成報表或者大屏展示給老闆們看,以便老闆們可以更加精準地做出戰略決策,為業務的發展指明方向。 提到資料報表,不得不說說Quick BI。Quick BI提供海量資料實時線上分析服務,支援拖拽式操作、提供了豐富的視覺化效果,可以幫助您輕鬆自如
spring boot 系列之六:深入理解spring boot的自動配置
我們知道,spring boot自動配置功能可以根據不同情況來決定spring配置應該用哪個,不應該用哪個,舉個例子: Spring的JdbcTemplate是不是在Classpath裡面?如果是,並且DataSource也存在,就自動配置一個JdbcTemplate的Bean Thymeleaf是不
ZooKeeper系列之六:ZooKeeper四字命令
ZooKeeper 支援某些特定的四字命令字母與其的互動。它們大多是查詢命令,用來獲取 ZooKeeper 服務的當前狀態及相關資訊。使用者在客戶端可以通過 telnet 或 nc 向 ZooKeeper 提交相應的命令。 ZooKeeper 常用四字命令見下表 1 所示:
DPDK系列之六:qemu-kvm網路後端的加速技術
一、前言在文章《DPDK系列之五:qemu-kvm網路簡介》中可以看到qemu-kvm為不同需求的虛擬機器提供了不同的網路方案,這些網路方案的效能最終都取決於位於宿主機上的網路backend的實現方式。本文對於不同的backend技術進行分析。轉載自https://blog.
f2fs系列之六:checkpoint
rev ++ sid then bit all int opp 操作 f2fs 的checkpoint 維護data、node和meta data(SIT,NAT)的數據一致性,把一起寫到SSA區域的數據分別寫回到SIT/NAT區域。 checkpoint 相關數據結構 s
《Core Java 2》與《Thinking in Java》之我見:)
我認為可以直接讀《Core Java》,裡面部分深入的內容可以先略過去不看,先看簡單的。看完一遍之後,對Java應該有一定的理解。它的例子不錯,對於幫助理解Java的概念和程式設計很有幫助。看完之後,可以回頭再看以前略過
Java分析系列之六:JVM Heap Dump(堆轉儲檔案)的生成和MAT的使用
前面的文章詳細講述了分析Thread Dump檔案,實際在處理Java記憶體洩漏問題的時候,還需要分析JVM堆轉儲檔案來進行定位。 目錄 [隱藏] JVM Heap Dump(堆轉儲檔案)的生成 正如Thread Dump檔案記錄了當時JVM中執行緒執行的情況一樣,He
Thinking in BigData(12)大資料之有指導資料探勘方法模型序(3)
接著上面部落格繼續探討:有指導資料探勘方法模型步驟 5、修復問題資料 所有資料都是髒的。所有的資料都是有問題。究竟是不是問題有時可能隨著資料探勘技術的變化而變化。對於某些技術,例如決策樹,缺失值和離群點並不會造成很大的麻煩,但是對於其他技術,