
Hadoop2.6(新版本)----MapReduce工作原理
下面我畫了一張圖,便於理解MapReduce得整個工作原理
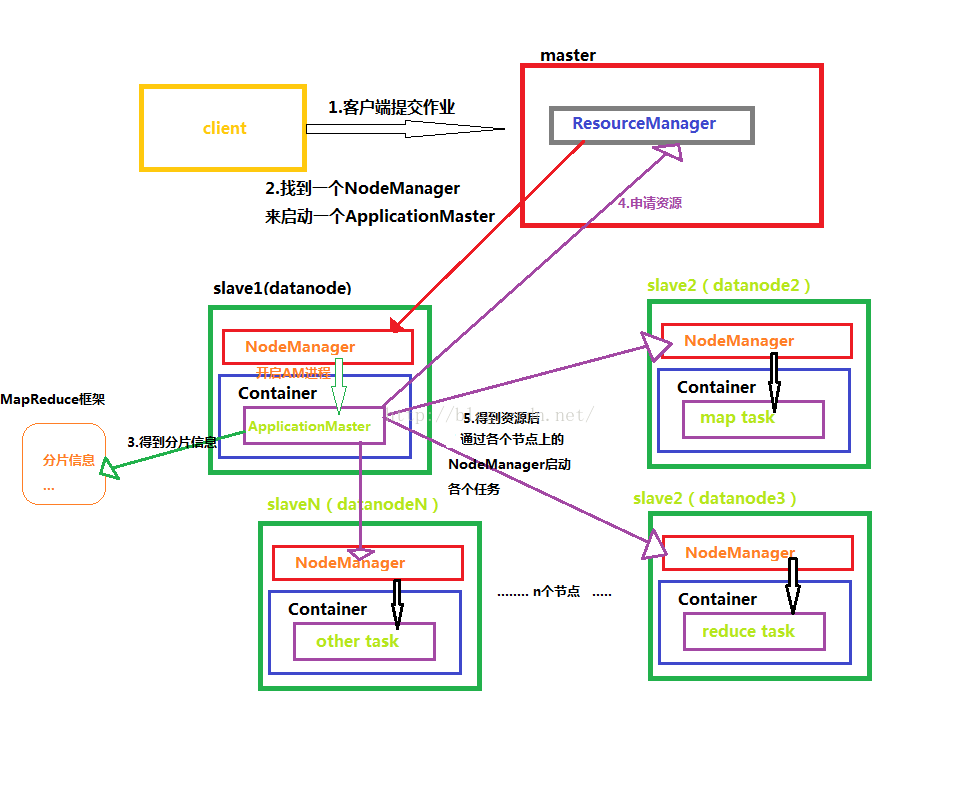
下面對上面出現的一些名詞進行介紹
ResourceManager:是YARN資源控制框架的中心模組,負責叢集中所有的資源的統一管理和分配。它接收來自NM(NodeManager)的彙報,建立AM,並將資源派送給AM(ApplicationMaster)。
NodeManager:簡稱NM,NodeManager是ResourceManager在每臺機器的上代理,負責容器的管理,並監控他們的資源使用情況(cpu,記憶體,磁碟及網路等),以及向 ResourceManager提供這些資源使用報告。
ApplicationMaster:以下簡稱AM。YARN中每個應用都會啟動一個AM,負責向RM申請資源,請求NM啟動container,並告訴container做什麼事情。
Container
1. Container是YARN中資源的抽象,它封裝了某個節點上一定量的資源(CPU和記憶體兩類資源)。
2. Container由ApplicationMaster向ResourceManager申請的,由ResouceManager中的資源排程器非同步分配給ApplicationMaster;3. Container的執行是由ApplicationMaster向資源所在的NodeManager發起的,Container執行時需提供內部執行的任務命令(可以是任何命令,比如java、Python、C++程序啟動命令均可)以及該命令執行所需的環境變數和外部資源(比如詞典檔案、可執行檔案、jar包等)。
另外,一個應用程式所需的Container分為兩大類,如下:
(1) 執行ApplicationMaster的Container:這是由ResourceManager(向內部的資源排程器)申請和啟動的,使用者提交應用程式時,可指定唯一的ApplicationMaster所需的資源;
(2) 執行各類任務的Container:這是由ApplicationMaster向ResourceManager申請的,並由ApplicationMaster與NodeManager通訊以啟動之。
以上兩類Container可能在任意節點上,它們的位置通常而言是隨機的,即ApplicationMaster可能與它管理的任務執行在一個節點上。
整個MapReduce的過程大致分為 Map-->Shuffle(排序)-->Combine(組合)-->Reduce
下面通過一個單詞計數案例來理解各個過程
1)將檔案拆分成splits(片),並將每個split按行分割形成<key,value>對,如圖所示。這一步由MapReduce框架自動完成,其中偏移量即key值
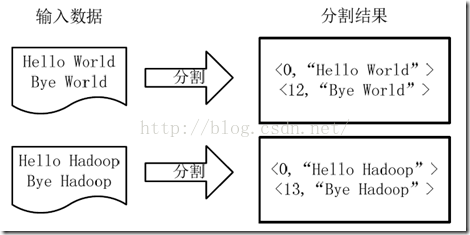
分割過程
將分割好的<key,value>對交給使用者定義的map方法進行處理,生成新的<key,value>對,如下圖所示。
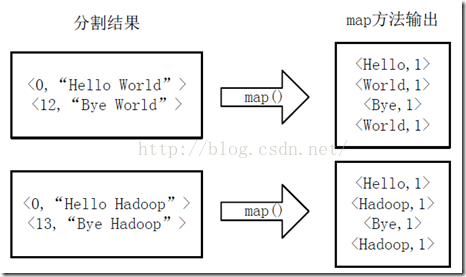
執行map方法
得到map方法輸出的<key,value>對後,Mapper會將它們按照key值進行Shuffle(排序),並執行Combine過程,將key至相同value值累加,得到Mapper的最終輸出結果。如下圖所示。
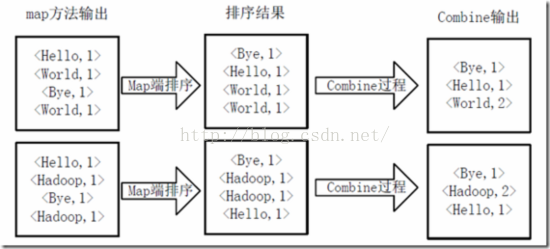
Map端排序及Combine過程
Reducer先對從Mapper接收的資料進行排序,再交由使用者自定義的reduce方法進行處理,得到新的<key,value>對,並作為WordCount的輸出結果,如下圖所示。
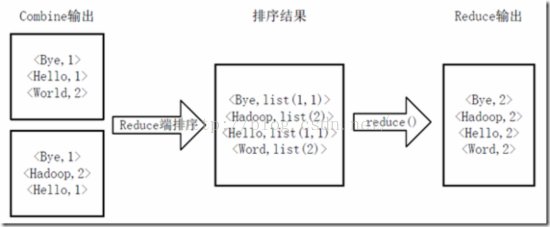
Reduce端排序及輸出結果
下面看怎麼用Java來實現WordCount單詞計數的功能
首先看Map過程
Map過程需要繼承org.apache.hadoop.mapreduce.Mapper包中 Mapper 類,並重寫其map方法。
/**
*
* @author 湯高
* Mapper<LongWritable, Text, Text, IntWritable>中 LongWritable,IntWritable是Hadoop資料型別表示長整型和整形
*
* LongWritable, Text表示輸入型別 (比如本應用單詞計數輸入是 偏移量(字串中的第一個單詞的其實位置),對應的單詞(值))
* Text, IntWritable表示輸出型別 輸出是單詞 和他的個數
* 注意:map函式中前兩個引數LongWritable key, Text value和輸出型別不一致
* 所以後面要設定輸出型別 要使他們一致
*/
//Map過程
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/***
*
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//預設的map的value是每一行,我這裡自定義的是以空格分割
String[] vs = value.toString().split("\\s");
for (String v : vs) {
//寫出去
context.write(new Text(v), ONE);
}
}
}
Reduce過程
Reduce過程需要繼承org.apache.hadoop.mapreduce包中 Reducer 類,並 重寫 其reduce方法。Map過程輸出<key,values>中key為單個單詞,而values是對應單詞的計數值所組成的列表,Map的輸出就是Reduce的輸入,所以reduce方法只要遍歷values並求和,即可得到某個單詞的總次數。
//Reduce過程
/***
* @author 湯高
* Text, IntWritable輸入型別,從map過程獲得 既map的輸出作為Reduce的輸入
* Text, IntWritable輸出型別
*/
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable v:values){
count+=v.get();//單詞個數加一
}
context.write(key, new IntWritable(count));
}
}最後執行MapReduce任務
public static void main(String[] args) {
Configuration conf=new Configuration();
try {
//args從控制檯獲取路徑 解析得到域名
String[] paths=new GenericOptionsParser(conf,args).getRemainingArgs();
if(paths.length<2){
throw new RuntimeException("必須輸出 輸入 和輸出路徑");
}
//得到一個Job 並設定名字
Job job=Job.getInstance(conf,"wordcount");
//設定Jar 使本程式在Hadoop中執行
job.setJarByClass(WordCount.class);
//設定Map處理類
job.setMapperClass(WordCountMapper.class);
//設定map的輸出型別,因為不一致,所以要設定
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//設定Reduce處理類
job.setReducerClass(WordCountReducer.class);
//設定輸入和輸出目錄
FileInputFormat.addInputPath(job, new Path(paths[0]));
FileOutputFormat.setOutputPath(job, new Path(paths[1]));
//啟動執行
System.exit(job.waitForCompletion(true) ? 0:1);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}即可求得每個單詞的個數
下面把整個過程的原始碼附上,有需要的朋友可以拿去測試
package hadoopday02;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
//計數變數
private static final IntWritable ONE = new IntWritable(1);
/**
*
* @author 湯高
* Mapper<LongWritable, Text, Text, IntWritable>中 LongWritable,IntWritable是Hadoop資料型別表示長整型和整形
*
* LongWritable, Text表示輸入型別 (比如本應用單詞計數輸入是 偏移量(字串中的第一個單詞的其實位置),對應的單詞(值))
* Text, IntWritable表示輸出型別 輸出是單詞 和他的個數
* 注意:map函式中前兩個引數LongWritable key, Text value和輸出型別不一致
* 所以後面要設定輸出型別 要使他們一致
*/
//Map過程
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/***
*
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//預設的map的value是每一行,我這裡自定義的是以空格分割
String[] vs = value.toString().split("\\s");
for (String v : vs) {
//寫出去
context.write(new Text(v), ONE);
}
}
}
//Reduce過程
/***
* @author 湯高
* Text, IntWritable輸入型別,從map過程獲得 既map的輸出作為Reduce的輸入
* Text, IntWritable輸出型別
*/
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable v:values){
count+=v.get();//單詞個數加一
}
context.write(key, new IntWritable(count));
}
}
public static void main(String[] args) {
Configuration conf=new Configuration();
try {
//args從控制檯獲取路徑 解析得到域名
String[] paths=new GenericOptionsParser(conf,args).getRemainingArgs();
if(paths.length<2){
throw new RuntimeException("必須輸出 輸入 和輸出路徑");
}
//得到一個Job 並設定名字
Job job=Job.getInstance(conf,"wordcount");
//設定Jar 使本程式在Hadoop中執行
job.setJarByClass(WordCount.class);
//設定Map處理類
job.setMapperClass(WordCountMapper.class);
//設定map的輸出型別,因為不一致,所以要設定
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//設定Reduce處理類
job.setReducerClass(WordCountReducer.class);
//設定輸入和輸出目錄
FileInputFormat.addInputPath(job, new Path(paths[0]));
FileOutputFormat.setOutputPath(job, new Path(paths[1]));
//啟動執行
System.exit(job.waitForCompletion(true) ? 0:1);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}好了,整個MapReduce的工作流程就分析到這裡了,上面全是個人學習歸納的,如果有什麼需要改善的地方,歡迎大家指正,一起進步
碼字不易,轉載請指明出處http://blog.csdn.net/tanggao1314/article/details/51275812
相關推薦
Hadoop2.6(新版本)----MapReduce工作原理
最近在研究Hadoop,發現網上的一些關於Hadoop的資料都是以前的1.X版本的,包括MapReduce的工作原理,都是以前的一些過時了的東西,所以自己重新整理了一些新2.X版本的MapReduce的工作原理 下面我畫了一張圖,便於理解MapReduce得整個工作原理 下
12-帶內管理、帶外管理 //0.8.6(GNS3版本)
console 清除 關閉 nag gin 運行 tex password size 帶內管理、帶外管理區別:流量在一根線上走就是帶內管理,有Console線就是帶外管理![]一、實驗拓撲:二、實驗要求:1、R1、R2、R3運行EIGRP 90協議,並配置各自的Loopba
Java使用JDBC連線Hive(新版本)API封裝
網上找了很多封裝的API,發現都是過時了的,執行報各種錯誤,經過了幾天的調錯,終於可以使用java程式碼操作hive了 首先看看所需的包 所有的分析都在程式碼裡面 注意:網上很多程式碼對於DDL都執行 res = stmt.executeQuery(
團隊作業6——展示博客(Alpha版本)
版本 需求 教師 培養 描述 美工設計 拷貝 nbsp 平衡 團隊成員介紹:蘇上鑫(2014211123081):吳偉君(2014211123080):周峰(201421123090):http://www.cnblogs.com/Mr-zfmmm/周誌強(20142112
解決CentOS(6和7版本),/etc/sysconfig/下沒有iptables的問題
name 命令 install star spa lib cep pro centos 6 一、Centos 6版本解決辦法: 1.任意運行一條iptables防火墻規則配置命令: iptables -P OUTPUT ACCEPT 2.對iptables服務進行保存:
設計模式:6大設計原則(PHP版本)
英文名稱 屬性信息 map 圖片 AC src pri 負責 模式 1.單一職責 單一職責原則的英文名稱是Single Responsibility Principle,簡稱是SRP,單一職責原則的定義是:應該有且僅有一個原因引起類的變更。 樣例1:
Mac Hadoop2.6(CDH5.9.2)偽分布式集群安裝
home address oca tno 操作系統 fault locate java contents 操作系統: MAC OS X 一、準備 1、 JDK 1.8 下載地址:http://www.oracle.com/technetwork/java/javase
Hadoop2.6 ---- MapReduce工作原理
MapReduce得整個工作原理 下面對上面出現的一些名詞進行介紹 ResourceManager:是YARN資源控制框架的中心模組,負責叢集中所有的資源的統一管理和分配。它接收來自NM(NodeManager)的彙報,建立AM,並將資源派送給AM(ApplicationMaster)
在ESXi主機上部署vCenter Server 6.7(Windows版本)
vCenter Server 6.7版本出現後,官方推薦使用LINUX版本,對於WINDOWS版本,不少的朋友在安裝過程中出現各種問題,何老師給大家做一個演示。 vCenter Server 6.7對硬體以及作業系統提出了新的要求,特別對於Windows版vCenter Server,記憶體如果小於8GB會
iOS應用程式上傳AppStore(新版本上傳)
本篇部落格記錄的是將iOS應用上傳AppStore,具體是把新的版本上傳,與新專案上傳差不多,只不過更新版本的上傳要稍微簡單些,這裡不會介紹證書的配置哦。 1.進入蘋果開發者中心-->進入iTunes Connect-->點選進入我的app-->點選你之前
Hadoop2.6.0的FileInputFormat的任務切分原理分析(即如何控制FileInputFormat的map任務數量)
前言 首先確保已經搭建好Hadoop叢集環境,可以參考《Linux下Hadoop叢集環境的搭建》一文的內容。我在測試mapreduce任務時,發現相比於使用Job.setNumReduceTasks(int)控制reduce任務數量而言,控制map任務數量一直是一個困擾我的
(重要!)進入工作後的新知識
1.何為saas模式?soft as a service(軟體即服務),saas提供商為企業搭建資訊化所需要的所有網路基礎設施及軟體、硬體運作平臺、並負責所有前期的設施、後期的維護等一系列服務。企業無需購買軟硬體,建設機房,招聘it人員,即可通過網際網路使用資訊系統。就像開啟
Matlab 攝像機標定+畸變校正(新版本MATLAB)
本文目的在於記錄如何使用MATLAB做攝像機標定,並通過opencv進行校正後的顯示。首先關於校正的基本知識通過OpenCV官網的介紹即可簡單瞭解:對於攝像機我們所關心的主要引數為攝像機內參,以及幾個畸變係數。上面的連線中後半部分也給瞭如何標定,然而OpenCV自帶的標定程式
Windows遠端桌面實現之六(新版本框架更新,以及網頁HTML5音訊採集通訊)
by fanxiushu 2018-08-21 轉載或引用請註明原始作者。 到
linux核心原始碼目錄結構(2.6.35.7版本)
以下內容源於朱有鵬嵌入式課程的學習,如有侵權,請告知刪除。 1、單個檔案 (1)Kbuild,Kbuild是kernel build的意思,就是核心編譯的意思。這個檔案就是linux核心特有的核心編譯體系需要用到的檔案。 (2)Makefile,這個是linux核心的總m
54 Three.js 使用THREE.PointCloudMaterial(新版本:THREE.PointsMaterial)樣式化粒子
var renderer; function initRender() { renderer = new THREE.WebGLRenderer({antialias: true}); //renderer.setClearColor(new THREE.C
kafka----kafka API(java版本)
spring mvc+my batis dubbo+zookeerper kafka restful redis分布式緩存 Apache Kafka包含新的Java客戶端,這些新的的客戶端將取代現存的Scala客戶端,但是為了兼容性,它們仍將存在一段時間。可以通過一些單獨的jar包調用這些客
團隊作業5——測試與發布(Alpha版本)
發布說明 實現 http 基礎 相差 還需 導致 延遲 要求 Alpha版本測試報告 一、測試找出的bug (1)練習模式的測試 在測試中發現的bug如下: ① 連續兩個運算數當做一個處理(如1和2連續輸入當做12處理) ② 練習模式沒有提示答案 ③
集美大學網絡1413第九次作業成績(團隊五) -- 測試與發布(Alpha版本)
ima worker str ges 運行 .cn png www text NO.NE團隊的項目鏈接有效,六個核桃和六指神功團隊可以請教下他們,避免因IP地址無效或者因tomcat不打開就不能訪問的情況,畢竟助教沒辦法知道此時此刻它是開著還是關閉啊啊啊。。。 題目 團隊作
團隊作業八—第二次團隊沖刺(Beta版本) 第 1 天
textview mat 地址 源碼 tps 之間 res height blog 一、每個人的工作 (1) 昨天已完成的工作 由於是才剛開始沖刺,所以沒有昨天的工作 (2) 今天計劃完成的工作; 對界面的優化和一些細節的完善 (3) 工作中遇到的困難; 工作中出現了