
Matlab實現CNN(一)
卷積神經網路CNN是深度學習的一個重要組成部分,由於其優異的學習效能(尤其是對圖片的識別)。近年來研究異常火爆,出現了很多模型LeNet、Alex net、ZF net等等。由於大多高校在校生使用matlab比較多,而網上的教程程式碼基本都基於caffe框架或者python,對於新入門的同學來說甚是煎熬,所以本文采用matlab結合MNIst手寫資料庫完成對手寫數字的識別。本人水平有限,如有紕漏,還望各路大神,幫忙指正。
一、卷積網路原理
1、動機
卷積神經網路(CNN)是多層感知機(MLP)的一個變種模型,它是從生物學概念中演化而來的。從Hubel和Wiesel早期對貓的視覺皮層的研究工作,我們知道在視覺皮層存在一種細胞的複雜分佈,,這些細胞對於外界的輸入區域性是很敏感的,它們被稱為“感受野”(細胞),它們以某種方法來覆蓋整個視覺域。這些細胞就像一些濾波器一樣,它們對輸入的影象是區域性敏感的,因此能夠更好地挖掘出自然影象中的目標的空間關係資訊。
此外,視覺皮層存在兩類相關的細胞,S細胞(Simple Cell)和C(Complex Cell)細胞。S細胞在自身的感受野內最大限度地對影象中類似邊緣模式的刺激做出響應,而C細胞具有更大的感受野,它可以對影象中產生刺激的模式的空間位置進行精準地定位。
視覺皮層作為目前已知的最為強大的視覺系統,廣受關注。學術領域出現了很多基於它的神經啟發式模型。比如:NeoCognitron [Fukushima], HMAX [Serre07] 以及本教程要討論的重點 LeNet-5 [LeCun98]。
2、稀疏連線
CNNs通過加強神經網路中相鄰層之間節點的區域性連線模式(Local Connectivity Pattern)來挖掘自然影象(中的興趣目標)的空間區域性關聯資訊。第m層隱層的節點與第m-1層的節點的區域性子集,並具有空間連續視覺感受野的節點(就是m-1層節點中的一部分,這部分節點在m-1層都是相鄰的)相連。可以用下面的圖來表示這種連線。
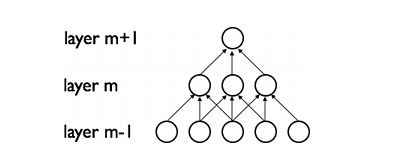
假設,m-1層為視網膜輸入層(接受自然影象)。根據上圖的描述,在m-1層上面的m層的神經元節點都具有寬度為3的感受野,m層每一個節點連線下面的視網膜層的3個相鄰的節點。m+1層的節點與它下面一層的節點有著相似的連線屬性,所以m+1層的節點仍與m層中3個相鄰的節點相連,但是對於輸入層(視網膜層)連線數就變多了,在本圖中是5。這種結構把訓練好的濾波器(corresponding to the input producing the strongest response)構建成了一種空間區域性模式(因為每個上層節點都只對感受野中的,連線的區域性的下層節點有響應)。根據上面圖,多層堆積形成了濾波器(不再是線性的了),它也變得更具有全域性性了(如包含了一大片的畫素空間)。比如,在上圖中,第m+1層能夠對寬度為5的非線性特徵進行編碼(就畫素空間而言)。
3、權值共享
在CNNs中,每一個稀疏濾波器hi在整個感受野中是重複疊加的,這些重複的節點形式了一種特徵圖(feature map),這個特種圖可以共享相同的引數,比如相同的權值矩陣和偏置向量。

在上圖中,屬於同一個特徵圖的三個隱層節點,因為需要共享相同顏色的權重, 他們的被限制成相同的。在這裡, 梯度下降演算法仍然可以用來訓練這些共享的引數,只需要在原演算法的基礎上稍作改動即可。共享權重的梯度可以對共享引數的梯度進行簡單的求和得到。
二、網路的分析
上面這些內容,基本就是CNN的精髓所在了,下面結合LeNet做具體的分析。
結構圖: 
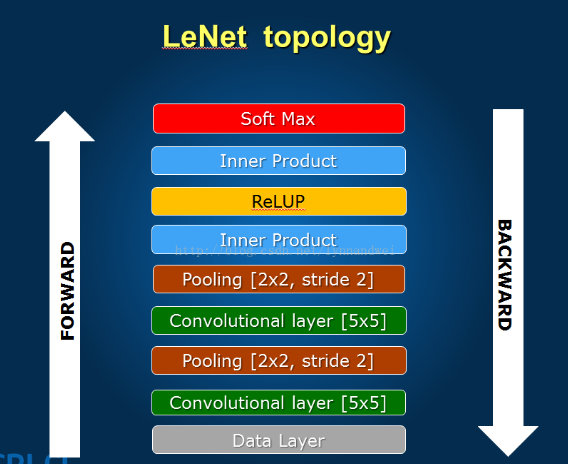
LeNet算上輸入輸出一共為八層,下面逐層分析。
第一層:資料輸入層
CNN的強項在於圖片的處理,lenet的輸入為32*32的矩陣圖片。這裡需要注意的點:
1、資料的歸一化,這裡的歸一化是廣義的,不一定要歸到0-1,但要是相同的一個區間範圍,一般我們的灰度圖為0-255。
2、資料的去均值,如果樣本有非零的均值,而且與測試部分的非零均值不一致,可能就會導致識別率的下降。當然這不一定發生,我們這麼做是為了增加系統的魯棒性。 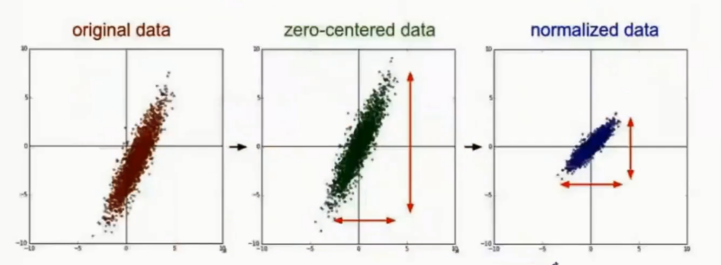
第二層:卷積層c1
卷積層是卷積神經網路的核心,通過不同的卷積核,來獲取圖片的特徵。卷積核相當於一個濾波器,不同的濾波器提取不同特徵。打個比方,對於手寫數字識別,某一個卷積核提取‘一’,另一個卷積核提取‘|’,所以這個數字很有可能就判定為‘7’。當然實際要比這複雜度得多,但原理大概就是這個樣子。
第三層:pooling層
基本每個卷積層後邊都會接一個pooling層,目的是為了降維。一般都將原來的卷積層的輸出矩陣大小變為原來的一半,方便後邊的運算。另外,pooling層增加了系統的魯棒性,把原來的準確描述變為了概略描述(原來矩陣大小為28*28,現在為14*14,必然有一部分資訊丟失,一定程度上防止了過擬合)。
第四層:卷積層
與之前類似,在之前的特徵中進一步提取特徵,對原樣本進行更深層次的表達。注意:這裡不是全連線。這裡不是全連線。這裡不是全連線。X代表連線,空白代表不連。 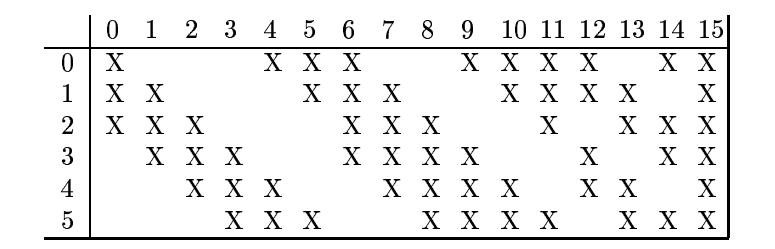
第五層:pooling層
與之前類似。
第六層:卷積層(全連線)
這裡有120個卷積核,這裡是全連線的。將矩陣卷積成一個數,方便後邊網路進行判定。
第七層:全連線層
和MLP中的隱層一樣,獲得高維空間資料的表達。
第八層:輸出層
這裡一般採用RBF網路,每個RBF的中心為每個類別的標誌,網路輸出越大,代表越不相似,輸出的最小值即為網路的判別結果。
三、卷積網路的BP訓練
前面的都很好理解,卷積神經網路的難度在於BP過程。網上zouxy09的博文寫的很好,可以看一下,自己搞明白。傳送門:CNN的BP推導
四、程式碼部分
關於MNIST資料集,網上有很多現成的程式碼對其進行提取,但提取出來的都是亂序的很不利於使用。這裡有提取好的分類後的,詳情傳送門
簡單起見,我們的程式碼選用一層卷積層。
CNN_simple_mian.m
%%% matlab實現LeNet-5
%%% 作者:xd.wp
%%% 時間:2016.10.22 14:29
%% 程式說明
% 1、池化(pooling)採用平均2*2
% 2、網路結點數說明:
% 輸入層:28*28
% 第一層:24*24(卷積)*20
% tanh
% 第二層:12*12(pooling)*20
% 第三層:100(全連線)
% 第四層:10(softmax)
% 3、網路訓練部分採用800個樣本,檢驗部分採用100個樣本
clear all;clc;
%% 網路初始化
layer_c1_num=20;
layer_s1_num=20;
layer_f1_num=100;
layer_output_num=10;
%權值調整步進
yita=0.01;
%bias初始化
bias_c1=(2*rand(1,20)-ones(1,20))/sqrt(20);
bias_f1=(2*rand(1,100)-ones(1,100))/sqrt(20);
%卷積核初始化
[kernel_c1,kernel_f1]=init_kernel(layer_c1_num,layer_f1_num);
%pooling核初始化
pooling_a=ones(2,2)/4;
%全連線層的權值
weight_f1=(2*rand(20,100)-ones(20,100))/sqrt(20);
weight_output=(2*rand(100,10)-ones(100,10))/sqrt(100);
disp('網路初始化完成......');
%% 開始網路訓練
disp('開始網路訓練......');
for iter=1:20
for n=1:20
for m=0:9
%讀取樣本
train_data=imread(strcat(num2str(m),'_',num2str(n),'.bmp'));
train_data=double(train_data);
% 去均值
% train_data=wipe_off_average(train_data);
%前向傳遞,進入卷積層1
for k=1:layer_c1_num
state_c1(:,:,k)=convolution(train_data,kernel_c1(:,:,k));
%進入激勵函式
state_c1(:,:,k)=tanh(state_c1(:,:,k)+bias_c1(1,k));
%進入pooling1
state_s1(:,:,k)=pooling(state_c1(:,:,k),pooling_a);
end
%進入f1層
[state_f1_pre,state_f1_temp]=convolution_f1(state_s1,kernel_f1,weight_f1);
%進入激勵函式
for nn=1:layer_f1_num
state_f1(1,nn)=tanh(state_f1_pre(:,:,nn)+bias_f1(1,nn));
end
%進入softmax層
for nn=1:layer_output_num
output(1,nn)=exp(state_f1*weight_output(:,nn))/sum(exp(state_f1*weight_output));
end
%% 誤差計算部分
Error_cost=-output(1,m+1);
% if (Error_cost<-0.98)
% break;
% end
%% 引數調整部分
[kernel_c1,kernel_f1,weight_f1,weight_output,bias_c1,bias_f1]=CNN_upweight(yita,Error_cost,m,train_data,...
state_c1,state_s1,...
state_f1,state_f1_temp,...
output,...
kernel_c1,kernel_f1,weight_f1,weight_output,bias_c1,bias_f1);
end
end
end
disp('網路訓練完成,開始檢驗......');
count=0;
for n=1:20
for m=0:9
%讀取樣本
train_data=imread(strcat(num2str(m),'_',num2str(n),'.bmp'));
train_data=double(train_data);
% 去均值
% train_data=wipe_off_average(train_data);
%前向傳遞,進入卷積層1
for k=1:layer_c1_num
state_c1(:,:,k)=convolution(train_data,kernel_c1(:,:,k));
%進入激勵函式
state_c1(:,:,k)=tanh(state_c1(:,:,k)+bias_c1(1,k));
%進入pooling1
state_s1(:,:,k)=pooling(state_c1(:,:,k),pooling_a);
end
%進入f1層
[state_f1_pre,state_f1_temp]=convolution_f1(state_s1,kernel_f1,weight_f1);
%進入激勵函式
for nn=1:layer_f1_num
state_f1(1,nn)=tanh(state_f1_pre(:,:,nn)+bias_f1(1,nn));
end
%進入softmax層
for nn=1:layer_output_num
output(1,nn)=exp(state_f1*weight_output(:,nn))/sum(exp(state_f1*weight_output));
end
[p,classify]=max(output);
if (classify==m+1)
count=count+1;
end
fprintf('真實數字為%d 網路標記為%d 概率值為%d \n',m,classify-1,p);
end
endinit_kernel.m
function [kernel_c1,kernel_f1]=init_kernel(layer_c1_num,layer_f1_num)
%% 卷積核初始化
for n=1:layer_c1_num
kernel_c1(:,:,n)=(2*rand(5,5)-ones(5,5))/12;
end
for n=1:layer_f1_num
kernel_f1(:,:,n)=(2*rand(12,12)-ones(12,12));
end
endconvolution.m
function [state]=convolution(data,kernel)
%實現卷積層操作
[data_row,data_col]=size(data);
[kernel_row,kernel_col]=size(kernel);
for m=1:data_col-kernel_col+1
for n=1:data_row-kernel_row+1
state(m,n)=sum(sum(data(m:m+kernel_row-1,n:n+kernel_col-1).*kernel));
end
end
endpooling.m
function state=pooling(data,pooling_a)
%% 實現取樣層pooling操作
[data_row,data_col]=size(data);
[pooling_row,pooling_col]=size(pooling_a);
for m=1:data_col/pooling_col
for n=1:data_row/pooling_row
state(m,n)=sum(sum(data(2*m-1:2*m,2*n-1:2*n).*pooling_a));
end
end
endconvolution_f1.m
function [state_f1,state_f1_temp]=convolution_f1(state_s1,kernel_f1,weight_f1)
%% 完成卷積層2操作
layer_f1_num=size(weight_f1,2);
layer_s1_num=size(weight_f1,1);
%%
for n=1:layer_f1_num
count=0;
for m=1:layer_s1_num
temp=state_s1(:,:,m)*weight_f1(m,n);
count=count+temp;
end
state_f1_temp(:,:,n)=count;
state_f1(:,:,n)=convolution(state_f1_temp(:,:,n),kernel_f1(:,:,n));
end
endCNN_upweight.m
function [kernel_c1,kernel_f1,weight_f1,weight_output,bias_c1,bias_f1]=CNN_upweight(yita,Error_cost,classify,train_data,state_c1,state_s1,state_f1,state_f1_temp,...
output,kernel_c1,kernel_f1,weight_f1,weight_output,bias_c1,bias_f1)
%%% 完成引數更新,權值和卷積核
%% 結點數目
layer_c1_num=size(state_c1,3);
layer_s1_num=size(state_s1,3);
layer_f1_num=size(state_f1,2);
layer_output_num=size(output,2);
[c1_row,c1_col,~]=size(state_c1);
[s1_row,s1_col,~]=size(state_s1);
[kernel_c1_row,kernel_c1_col]=size(kernel_c1(:,:,1));
[kernel_f1_row,kernel_f1_col]=size(kernel_f1(:,:,1));
%% 儲存網路權值
kernel_c1_temp=kernel_c1;
kernel_f1_temp=kernel_f1;
weight_f1_temp=weight_f1;
weight_output_temp=weight_output;
%% Error計算
label=zeros(1,layer_output_num);
label(1,classify+1)=1;
delta_layer_output=output-label;
%% 更新weight_output
for n=1:layer_output_num
delta_weight_output_temp(:,n)=delta_layer_output(1,n)*state_f1';
end
weight_output_temp=weight_output_temp-yita*delta_weight_output_temp;
%% 更新bias_f1以及kernel_f1
for n=1:layer_f1_num
count=0;
for m=1:layer_output_num
count=count+delta_layer_output(1,m)*weight_output(n,m);
end
%bias_f1
delta_layer_f1(1,n)=count*(1-tanh(state_f1(1,n)).^2);
delta_bias_f1(1,n)=delta_layer_f1(1,n);
%kernel_f1
delta_kernel_f1_temp(:,:,n)=delta_layer_f1(1,n)*state_f1_temp(:,:,n);
end
bias_f1=bias_f1-yita*delta_bias_f1;
kernel_f1_temp=kernel_f1_temp-yita*delta_kernel_f1_temp;
%% 更新weight_f1
for n=1:layer_f1_num
delta_layer_f1_temp(:,:,n)=delta_layer_f1(1,n)*kernel_f1(:,:,n);
end
for n=1:layer_s1_num
for m=1:layer_f1_num
delta_weight_f1_temp(n,m)=sum(sum(delta_layer_f1_temp(:,:,m).*state_s1(:,:,n)));
end
end
weight_f1_temp=weight_f1_temp-yita*delta_weight_f1_temp;
%% 更新 bias_c1
for n=1:layer_s1_num
count=0;
for m=1:layer_f1_num
count=count+delta_layer_f1_temp(:,:,m)*weight_f1(n,m);
end
delta_layer_s1(:,:,n)=count;
delta_layer_c1(:,:,n)=kron(delta_layer_s1(:,:,n),ones(2,2)/4).*(1-tanh(state_c1(:,:,n)).^2);
delta_bias_c1(1,n)=sum(sum(delta_layer_c1(:,:,n)));
end
bias_c1=bias_c1-yita*delta_bias_c1;
%% 更新 kernel_c1
for n=1:layer_c1_num
delta_kernel_c1_temp(:,:,n)=rot90(conv2(train_data,rot90(delta_layer_c1(:,:,n),2),'valid'),2);
end
kernel_c1_temp=kernel_c1_temp-yita*delta_kernel_c1_temp;
%% 網路權值更新
kernel_c1=kernel_c1_temp;
kernel_f1=kernel_f1_temp;
weight_f1=weight_f1_temp;
weight_output=weight_output_temp;
end程式執行結果:

檢驗200個,196個識別正確,4個識別錯誤。

相關推薦
Matlab實現CNN(一)
卷積神經網路CNN是深度學習的一個重要組成部分,由於其優異的學習效能(尤其是對圖片的識別)。近年來研究異常火爆,出現了很多模型LeNet、Alex net、ZF net等等。由於大多高校在校生使用matlab比較多,而網上的教程程式碼基本都基於caffe框架或者python,
C++ 實現反射(一)
反射,就是根據一個類名,即可根據類名獲取類資訊,建立新物件。反射在很多語言都天然支援,然而不包括 C++,但我們肯定會經常遇到這種根據類名生成物件的場景,這就需要我們自己動手來實現了。反正 C++ 這麼強大,一定沒有問題 :) version 1 我們略做思考,就可以想到一種最簡
JDK9 ConcurrentHashMap實現原理(一)
文章目錄 JDK9 ConcurrentHashMap實現原理(一) 資料結構 私有屬性 靜態屬性 相關節點 構造器 Hash值計算 新增元素 初始化陣列
OpenCV下車牌定位演算法實現程式碼(一)
分類: 影象處理
Matlab學習筆記(一)--繪圖
1、固定座標軸 1.1 axis函式 axis([xmin xmax ymin ymax zmin zmax]) 如果只給出前4個引數,則MATLAB按照給出的x,y的最小值和最大值選擇座標系的範圍,以便繪製二維曲線。如果給出全部引數,則系統按照給出的3個座標軸的最小值和最大
Redisson 分散式鎖實現分析(一)
設計分散式鎖要注意的問題 互斥 分散式系統中執行著多個節點,必須確保在同一時刻只能有一個節點的一個執行緒獲得鎖,這是最基本的一點。 死鎖 分散式系統中,可能產生死鎖的情況要相對複雜一些。分散式系統是處在複雜網路環境中的,當一個節點獲取到鎖,如果它在釋放鎖之前掛掉了,
深入探究immutable.js的實現機制(一)
Immutable.js 採用了持久化資料結構和結構共享,保證每一個物件都是不可變的,任何新增、修改、刪除等操作都會生成一個新的物件,且通過結構共享等方式大幅提高效能。網上已經有很多文章簡單介紹了 Immutable.js 的原理,但基本都是淺嘗輒止,我也是搜了很久
java併發機制的底層實現原理(一):volatile深入分析
java程式碼最終會被類載入器載入到JVM中,然後轉化為彙編指令在CPU上執行。java中所使用的併發機制依賴於JVM的實現和CPU的指令。 1.volatile的應用 volatile是一個輕量級的synchronize,它保證了共享變數的可見性,確保了所有執
Rxjava2.x 原始碼分析,以及手動實現Rxjava(一)
這兩年Rxjava火的一塌糊塗,不會點Rxjava+Okhttp+Retrofit+MVP+Dagger2架構都不好意思說自己混Android的。Rxjava 到底是什麼和Rxjava到底怎麼用,這裡就不講了,網上太多了,具體可以參考 這位大佬 和扔物線的。 Rxjava
【iOS】圖表實現-Charts(一)
前幾天把AAChartsKit的使用簡單寫了寫,官方使用說明已經寫的很詳細了。我也就不多說了,今天就講講Charts的使用。 0.簡介 近期專案需要使用到折線圖這樣的圖表功能,因此接觸到了Charts這個框架,不得不說這個圖表框架很強大,但是在GitHub上Charts的介紹也比較簡單的介紹(直說了和MP
嘗試模擬實現struts2(一)
由於在另一篇文章中已經分析過Struts2的執行流程,所以直接開始嘗試。 宣告:只是簡單實現過程,沒有使用代理。 首先:因為struts2會當使用者訪問action時候加入一個過濾器,將使用者請求攔下來。使用者請求路徑"./action/StudentInfo" 所以我們也在web.xm
嘗試模擬實現RMI(一)
關於RMI的基礎理解在我之前的文章中有所介紹。點我 這次是根據RMI的基礎理解從而想到嘗試模擬實現RMI。 大體思路: 我們的目標是建立RpcServer以及RpcClient後,從RpcClient中得到相應介面或類的代理物件,並且執行介面中的方法。 而這的執行是通過代理機
嘗試模擬實現AOP(一)
大體思路: 除了模擬實現IOC準備的東西外,還需要準備一套有關攔截器的類以及相關注解; 包括類InterceptorFactory、InterceptorScanner、,註解After、Before、ThorwException、Aspect; 一個描述攔截器的類Interc
RBAC許可權管理系統實現思路(一)
RBAC(Role-Based Access Contro) 是基於角色的許可權訪問控制,系統根據登入使用者的角色不同,從而給予不同的系統訪問許可權,角色的許可權隨角色創立時進行分配。 首先,許可權控制很多系統中都需要,但是不同的系統對於許可權的敏感程度不同,
用DirectX實現魔方(一)
關於魔方 魔方英文名字叫做Rubik's Cube,是由匈牙利建築學教授和雕塑家Ernő Rubik於1974年發明,最初叫做Magic Cube(這大概也是中文名字的來歷吧),1980年Ideal Toys公司開始銷售此玩具,並將名字改為Rubik's Cube。 魔方在80年代最為風靡,至今未衰。截至
模仿NGUI實現SoftClip(一)
用過NGUI的童鞋都知道UIPanel可以設定一個矩形的Clip區域,它下轄的UIWidget都只能在Clip區域內顯示。今天我就模仿UIPanel實現類似的Clip功能,讓一個3D面片只能在我所指定的矩形區域內顯示。相信看完這篇文章,UIPanel的Clip原理也就不再神祕
【Spring原始碼--AOP的實現】(一)AopProxy代理物件的建立
public Object getProxy(ClassLoader classLoader) { if (logger.isDebugEnabled()) { logger.debug("Creating CGLIB2 proxy: target source is " + this.a
必須知道的八大種排序演算法【java實現】(一) 氣泡排序、快速排序
氣泡排序 氣泡排序是一種簡單的排序演算法。它重複地走訪過要排序的數列,一次比較兩個元素,如果他們的順序錯誤就把他們交換過來。走訪數列的工作是重複地進行直到沒有再需要交換,也就是說該數列已經排序完成。這個演算法的名字由來是因為越小的元素會經由交換慢慢“浮”到數列的頂端。 氣泡排序的示例: 氣
MATLAB學習過程(一)
前言 MATLAB的強大我至今都不敢相信,對於我們電氣專業,不會MATLAB就跟沒讀過書一樣,Simulink 模組的模擬是最最最重要的,只有以後搞這一行理論,都是與它打交道。 以前只用MATLAB做過資料處理跟簡單的模擬,尤其是時間序列分析,我可以算是最拿
C/C++:各種基本演算法實現小結(一)—— 單鏈表
各種基本演算法實現小結(一)—— 單鏈表 (均已測試通過) ============================================================ 單鏈表(測試通過) 測試環境: Win-TC