
Hadoop對小檔案的解決方案
小檔案指的是那些size比HDFS的block size(預設64M)小的多的檔案。任何一個檔案,目錄和block,在HDFS中都會被表示為一個object儲存在namenode的記憶體中, 每一個object佔用150 bytes的記憶體空間。所以,如果有10million個檔案, 每一個檔案對應一個block,那麼就將要消耗namenode 3G的記憶體來儲存這些block的資訊。如果規模再大一些,那麼將會超出現階段計算機硬體所能滿足的極限。
控制小檔案的方法有:
1、應用程式自己控制
2、archive
3、Sequence File / Map File
4、CombineFileInputFormat***
5、合併小檔案,如HBase部分的compact
1、應用程式自己控制
final Path path = new Path("/combinedfile");
final FSDataOutputStream create = fs.create(path);
final File dir = new File("C:\\Windows\\System32\\drivers\\etc");
for(File fileName : dir.listFiles())
{
System.out.println(fileName.getAbsolutePath());
final FileInputStream fileInputStream = new 2、archive 命令列操作
3、Sequence File/Map File
Sequence File
通常對於”the small files problem”的迴應會是:使用SequenceFile。
這種方法是說,使用filename作為key,並且file contents作為value。實踐中這種方式非常管用。
如果有10000個100KB的檔案,可以寫一個程式來將這些小檔案寫入到一個單獨的 SequenceFile中去,然後就可以在一個streaming fashion(directly or using mapreduce)中來使用這個sequenceFile。不僅如此,SequenceFiles也是splittable的,所以mapreduce 可以break them into chunks,並且分別的被獨立的處理。和HAR不同的是,這種方式還支援壓縮。 block的壓縮在許多情況下都是最好的選擇,因為它將多個 records壓縮到一起,而不是一個record一個壓縮。
在儲存結構上, SequenceFile主要由一個Header後跟多條Record組成。
Header主要包含了Key classname, Value classname,儲存壓縮演算法,使用者自定義元資料等資訊,此外,還包含了一些同步標識,用於快速定位到記錄的邊界。
每條Record以鍵值對的方式進行儲存,用來表示它的字元陣列可依次解析成:記錄的長度、 Key的長度、 Key值和Value值,並且Value值的結構取決於該記錄是否被壓縮。
資料壓縮有利於節省磁碟空間和加快網路傳輸, SeqeunceFile支援兩種格式的資料壓縮,分別是: record compression和block compression。
record compression是對每條記錄的value進行壓縮
block compression是將一連串的record組織到一起,統一壓縮成一個block。
block資訊主要儲存了:塊所包含的記錄數、每條記錄Key長度的集合、每條記錄Key值的集合、每條記錄Value長度的集合和每條記錄Value值的集合
注:每個block的大小是可通過io.seqfile.compress.blocksize屬性來指定的。
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path seqFile=new Path("seqFile.seq");
//Reader內部類用於檔案的讀取操作
SequenceFile.Reader reader=new SequenceFile.Reader(fs,seqFile,conf);
//Writer內部類用於檔案的寫操作,假設Key和Value都為Text型別
SequenceFile.Writer writer=new SequenceFile.Writer(fs,conf,seqFile,Text.class,Text.class);
//通過writer向文件中寫入記錄
writer.append(new Text("key"),new Text("value"));
IOUtils.closeStream(writer);//關閉write流
//通過reader從文件中讀取記錄
Text key=new Text();
Text value=new Text();
while(reader.next(key,value))
{
System.out.println(key);
System.out.println(value);
}
IOUtils.closeStream(reader);//關閉read流MapFile
MapFile是排序後的SequenceFile,通過觀察其目錄結構可以看到
MapFile由兩部分組成,分別是data和index。
index作為檔案的資料索引,主要記錄了每個Record的key值,以及
該Record在檔案中的偏移位置。
在MapFile被訪問的時候,索引檔案會被載入到記憶體,通過索引對映關係可迅速定位到指定Record所在檔案位置,因此,相對SequenceFile而言, MapFile的檢索效率是高效的,缺點是會消耗一部分記憶體來儲存index資料。
需注意的是, MapFile並不會把所有Record都記錄到index中去,預設情況下每隔128條記錄儲存一個索引對映。當然,記錄間隔可人為修改,通過MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval屬性;
另外,與SequenceFile不同的是, MapFile的KeyClass一定要實現
WritableComparable介面 ,即Key值是可比較的。
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path mapFile=new Path("mapFile.map");
//Writer內部類用於檔案的寫操作,假設Key和Value都為Text型別
MapFile.Writer writer=new MapFile.Writer(conf,fs,mapFile.toString(),Text.class,Text.class);
//通過writer向文件中寫入記錄
writer.append(new Text("key"),new Text("value"));
IOUtils.closeStream(writer);//關閉write流
//Reader內部類用於檔案的讀取操作
MapFile.Reader reader=new MapFile.Reader(fs,mapFile.toString(),conf);
//通過reader從文件中讀取記錄
Text key=new Text();
Text value=new Text();
while(reader.next(key,value))
{
System.out.println(key);
System.out.println(value);
}
IOUtils.closeStream(reader);//關閉read流5、CombineFileInputFormat
相對於大量的小檔案來說,hadoop更合適處理少量的大檔案。
CombineFileInputFormat可以緩解這個問題,它是針對小檔案而設計的。
**注:**CombineFileInputFormat是一個抽象類,需要編寫一個繼承類。
使用CombineFileInputFormat作為Map任務的輸入規格描述,首先需要實現一個自定義的RecordReader。
CombineFileInputFormat的大致原理
它會將輸入多個數據檔案(小檔案)的元資料全部包裝到CombineFileSplit類裡面。也就是說,因為小檔案的情況下,在HDFS中都是單Block的檔案,即一個檔案一個Block,一個CombineFileSplit包含了一組檔案Block,包括每個檔案的起始偏移(offset),長度(length),Block位置(localtions)等元資料。
如果想要處理一個 CombineFileSplit,很容易想到,對其包含的每個InputSplit(實際上這裡面沒有這個,你需要讀取一個小檔案塊的時候,需要構造一 個FileInputSplit物件)。
在執行MapReduce任務的時候,需要讀取檔案的文字行(簡單一點是文字行,也可能是其他格式資料)。
那麼對於CombineFileSplit來說,你需要處理其包含的小檔案Block,就要對應設定一個RecordReader,才能正確讀取檔案資料內容。
通常情況下,我們有一批小檔案,格式通常是相同的,只需要在CombineFileSplit實現一個RecordReader的時候,
內建另一個用來讀取小檔案Block的RecordReader,這樣就能保證讀取CombineFileSplit內部聚積的小檔案。
我們基於Hadoop內建的CombineFileInputFormat來實現處理海量小檔案,需要做的工作,如下所示:
1、實現一個RecordReader來讀取CombineFileSplit包裝的檔案Block
2、繼承自CombineFileInputFormat實現一個使用我們自定義的RecordReader的輸入規格說明類。
3、處理資料的Mapper實現類
4、配置用來處理海量小檔案的MapReduce Job
package SmallFile;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.CombineFileRecordReader;
import org.apache.hadoop.mapreduce.lib.input.CombineFileSplit;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.LineRecordReader;
public class CombineSmallfileInputFormat extends
CombineFileInputFormat<LongWritable,BytesWritable>
{
@Override
public RecordReader<LongWritable, BytesWritable> createRecordReader(
InputSplit split, TaskAttemptContext context) throws IOException
{
CombineFileSplit combineFileSplit = (CombineFileSplit)(split);
CombineFileRecordReader<LongWritable,BytesWritable> recordReader =
new CombineFileRecordReader<LongWritable,BytesWritable>
(combineFileSplit, context,CombineSmallfileRecordReader.class);
try
{
recordReader.initialize(combineFileSplit, context);
}
catch (InterruptedException e)
{
e.printStackTrace();
}
return recordReader;
}
}
class CombineSmallfileRecordReader extends RecordReader<LongWritable,BytesWritable>
{
private CombineFileSplit combineFileSplit;
private LineRecordReader lineRecordReader = new LineRecordReader();
private Path[] paths;
private int totalLength;
private int currentIndex;
private float currentProgress = 0;
private LongWritable currentKey;
private BytesWritable currentValue;
public CombineSmallfileRecordReader(CombineFileSplit combineFileSplit,TaskAttemptContext context,Integer index)
{
super();
this.combineFileSplit = combineFileSplit;
this.currentIndex = index;
}
@Override
public void initialize(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException
{
FileSplit fileSplit = new FileSplit(combineFileSplit.getPath(currentIndex),
combineFileSplit.getOffset(currentIndex),combineFileSplit.getLength(currentIndex),
combineFileSplit.getLocations());
lineRecordReader.initialize(fileSplit, context);
this.paths = combineFileSplit.getPaths(); //分割槽所在的所有地址
context.getConfiguration().set("map.input.file.name",
combineFileSplit.getPath(currentIndex).getName()); //設定輸入檔名
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException
{
if(currentIndex>=0 && currentIndex<totalLength)
{
return lineRecordReader.nextKeyValue();
}
return false;
}
@Override
public LongWritable getCurrentKey() throws IOException, InterruptedException
{
currentKey = lineRecordReader.getCurrentKey();
return currentKey;
}
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException
{
byte[]value = lineRecordReader.getCurrentValue().getBytes();
currentValue.set(value, 0, value.length);
return currentValue;
}
@Override
public float getProgress() throws IOException, InterruptedException
{
if(currentIndex>=0 && currentIndex<totalLength)
{
currentProgress = currentIndex/totalLength;
return currentProgress;
}
return currentProgress;
}
@Override
public void close() throws IOException
{
lineRecordReader.close();
}
}相關推薦
Hadoop對小檔案的解決方案
小檔案指的是那些size比HDFS的block size(預設64M)小的多的檔案。任何一個檔案,目錄和block,在HDFS中都會被表示為一個object儲存在namenode的記憶體中, 每一個object佔用150 bytes的記憶體空間。所以,如果有10
基於Hadoop Sequencefile的小檔案解決方案
基於Hadoop Sequencefile的小檔案解決方案 一、概述 小檔案是指檔案size小於HDFS上block大小的檔案。這樣的檔案會給hadoop的擴充套件性和效能帶來嚴重問題。首先,在HDFS中,任何block,檔案或者目錄在記憶體中均以物件的形式儲存,每個物件約佔150byte,如果有10
[Hadoop]大量小檔案問題及解決方案
1. HDFS上的小檔案問題 小檔案是指檔案大小明顯小於HDFS上塊(block)大小(預設64MB)的檔案。如果儲存小檔案,必定會有大量這樣的小檔案,否則你也不會使用Hadoop(If you’re storing small files, then you probably have lot
Hadoop的JVM重用機制和小檔案解決
Hadoop的JVM重用機制和小檔案解決 一、hadoop2.0 uber功能 1) uber的原理:Yarn的預設配置會禁用uber元件,即不允許JVM重用。我們先看看在這種情況下,Yarn是如何執行一個MapReduce job的。首先,Resource Manager裡的App
VMware虛擬機Mac OS X無法調整擴展硬盤大小的解決方案(轉)
一個 vmware 100g vmware虛擬機 顯示 class 0.10 針對 虛擬機 使用VMware虛擬機搭建的MacOSX,在10.10以上可能會出現無法擴充磁盤大小的問題。 因為很多朋友在初次安裝MacOSX的時候都默認選擇40G的磁盤大小,結果用了沒兩天之後
hadoop行業技術創新解決方案
除了 並行處理 服務器 任務 自己的 得到 計算 gpo 個數 如今有很多公司都在努力挖掘他們擁有的大量數據,包括結構化、非結構化、半結構化以及二進制數據等,來探索對數據的深入利用。 大多數公司估計他們只分析了已有數據的12%,剩余88%還沒有被充分利用。大量的數據孤島和分
小程序解決方案 Westore - 組件、純組件、插件開發
stc 數據 ice 參數 detail 解決方案 註意 stringify oba 數據流轉 先上一張圖看清 Westore 怎麽解決小程序數據難以管理和維護的問題: 非純組件的話,可以直接省去 triggerEvent 的過程,直接修改 store.data 並且 u
liunx上安裝MySQL沒有預設my.cnf檔案解決方案
官網說:從5.7.18開始不在二進位制包中提供my-default.cnf檔案。參考:https://dev.mysql.com/doc/refman/5.7/en/binary-installation.html 經過測試,在5.7.18版本中,使用tar.gz安裝時,也就是壓縮包解壓出
hdfs 小檔案合併方案(附程式碼)
背景: presto計算落地出現了大量的小檔案,目前暫時沒有發現可以通過引數優化解決,所以開發了小檔案合併工具 工具架構如下 工具主要分為三部分: collector 負責將合併規則推送到redis佇列,合併規則物件定義如下, public class FileCo
解決方案 [微信小程式] megalo -- 網易考拉小程式解決方案
轉自:http://www.okeydown.com/(微信小程式網) 作者: webadmin 釋出時間: 2018-10-29 13:48:36 導語: megalo 是基於 Vue 的小程式框架(沒錯,又是基於 Vue 的小程式框架),但是它不僅僅支援微信小程式,
小程式跳轉小程式,長按識別小程式碼跳轉小程式解決方案
場景描述: 因為小程式跳轉的時候需要公眾號關聯,但是關聯的數量是有限的!因此該文章的處理方案是: a.關聯的小程式,直接可以點選開啟 b.沒有關聯的,那麼可以長按識別小程式碼來進入小程式 下面展示效果: 1.點選關聯有appid的時候,直接進入小程式 2.點選沒有appid的
Dubbo服務 上傳檔案解決方案以及Hessian協議
協議支援 Dubbo支援多種協議,如下所示: Dubbo協議 Hessian協議 HTTP協議 RMI協議 WebService協議 Thrift協議 Memcached協議 Redis協議 在通訊過程中,不同的服務等級一般對應著不同的服務質量,那麼選擇合適
iView Table元件寬度只變大不變小的解決方案
示例: <Table class="my-table"></Table> 開啟開發者工具其實你可以發現iView給table標籤的寬度加上了一個明確的寬度值,而且在父元素變小的時候這個值並沒有相應地變小,所以才會導致的iView Table元件只
小程式解決方案 Westore
## 資料流轉 先上一張圖看清 Westore 怎麼解決小程式資料難以管理和維護的問題: 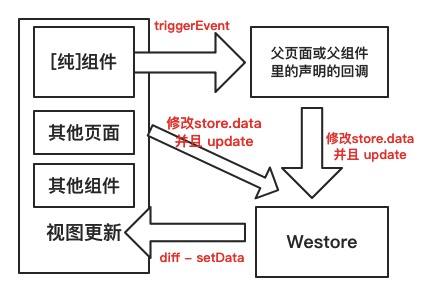 非純元件的話,可以
Hadoop上小檔案儲存處理
在Hadoop中小檔案是一個大問題 — 或者說, 至少, 他們在使用者的討論區域是比較熱門的話題. 在這篇文章中我將直面這個問題, 並提出一些常見的解決方案. 在HDFS中的小檔案問題 這裡討論的小檔案指的是那些在HDFS中小於HDFS塊大小(預設是64M)的檔案. 如果你儲存了很多這種小檔案, 或者你有很
Spring Cloud Finchley.RC2版本使用分散式配置中心去git倉庫讀取不到配置檔案解決方案
Finchley.RC2版本下java.lang.StringIndexOutOfBoundsException: String index out of range: -1報錯應該是這個版本的一個BUG。 在此版本有個HttpClientConfigurableHttpConnectionFactory這個
hibernate 多對多刪除解決方案
hibernate多對多當中,我們常常希望只刪除一方已及對應的關係,但不想刪除另一方,怎麼樣達到呢? (這裡只提刪除) 表user和表role多對多,中間表user_role(userId,roleId),user是主控方,role是從方, 在spring+hibernate
PHP微信小程式解決方案PhpMall
DiyGw是一個基於TwoTHink開源的內容管理框架,由Onethink基礎上升級到最新的ThinkPHP5.0.6版本開發,提供更方便、更安全的WEB應用開發體驗,採用了全新的架構設計和名稱空間機制,融合了模組化、驅動化和外掛化的設計理念於一體,開啟了國內WEB應用傻瓜
IE9 IE10 無法上傳檔案 解決方案
IE9和IE10都無法上傳,這是由於IE瀏覽器的版本升級問題。修改方法如下:if(window.ActiveXObject) { var io = document.createElement('<iframe id="' + frameId + '" na
Hololens開發之環境配置的小坑解決方案備註
工具的話,我用的Unity 2017.1和VS 2015 這裡主要要說的是,Unity在HoloLens中開發和釋出時,會因為版本差異導致各種問題,這裡建議的是,除非特殊情況,還是不要用最新的版本了。。。然後現在HoloLens的tools最新是在Unity 2017.2及以上的版本的,如果像我一