
[Hadoop]大量小檔案問題及解決方案
1. HDFS上的小檔案問題
小檔案是指檔案大小明顯小於HDFS上塊(block)大小(預設64MB)的檔案。如果儲存小檔案,必定會有大量這樣的小檔案,否則你也不會使用Hadoop(If you’re storing small files, then you probably have lots of them (otherwise you wouldn’t turn to Hadoop)),這樣的檔案給hadoop的擴充套件性和效能帶來嚴重問題。當一個檔案的大小小於HDFS的塊大小(預設64MB),就將認定為小檔案否則就是大檔案。為了檢測輸入檔案的大小,可以瀏覽Hadoop DFS 主頁 http://machinename:50070/dfshealth.jsp ,並點選Browse filesystem(瀏覽檔案系統)。
首先,在HDFS中,任何一個檔案,目錄或者block在NameNode節點的記憶體中均以一個物件表示(元資料)(Every file, directory and block in HDFS is represented as an object in the namenode’s memory),而這受到NameNode實體記憶體容量的限制。每個元資料物件約佔150byte,所以如果有1千萬個小檔案,每個檔案佔用一個block,則NameNode大約需要2G空間。如果儲存1億個檔案,則NameNode需要20G空間,這毫無疑問1億個小檔案是不可取的。
其次,處理小檔案並非Hadoop的設計目標,HDFS的設計目標是流式訪問大資料集(TB級別)。因而,在HDFS中儲存大量小檔案是很低效的。訪問大量小檔案經常會導致大量的尋找,以及不斷的從一個DatanNde跳到另一個DataNode去檢索小檔案(Reading through small files normally causes lots of seeks and lots of hopping from datanode to datanode to retrieve each small file),這都不是一個很有效的訪問模式,嚴重影響效能。
最後,處理大量小檔案速度遠遠小於處理同等大小的大檔案的速度。每一個小檔案要佔用一個slot,而task啟動將耗費大量時間甚至大部分時間都耗費在啟動task和釋放task上。
2. MapReduce上的小檔案問題
Map任務(task)一般一次處理一個塊大小的輸入(input)(預設使用FileInputFormat)。如果檔案非常小,並且擁有大量的這種小檔案,那麼每一個map task都僅僅處理非常小的input資料,因此會產生大量的map tasks,每一個map task都會額外增加bookkeeping開銷(each of which imposes extra bookkeeping overhead)。一個1GB的檔案,拆分成16個塊大小檔案(預設block size為64M),相對於拆分成10000個100KB的小檔案,後者每一個小檔案啟動一個map task,那麼job的時間將會十倍甚至百倍慢於前者。
Hadoop中有一些特性可以用來減輕bookkeeping開銷:可以在一個JVM中允許task JVM重用,以支援在一個JVM中執行多個map task,以此來減少JVM的啟動開銷(通過設定mapred.job.reuse.jvm.num.tasks屬性,預設為1,-1表示無限制)。(譯者注:如果有大量小檔案,每個小檔案都要啟動一個map task,則必相應的啟動JVM,這提供的一個解決方案就是重用task 的JVM,以此減少JVM啟動開銷);另 一種方法是使用MultiFileInputSplit,它可以使得一個map中能夠處理多個split。
3. 為什麼會產生大量的小檔案
至少有兩種場景下會產生大量的小檔案:
(1)這些小檔案都是一個大邏輯檔案的一部分。由於HDFS在2.x版本開始支援對檔案的append,所以在此之前儲存無邊界檔案(例如,log檔案)(譯者注:持續產生的檔案,例如日誌每天都會生成)一種常用的方式就是將這些資料以塊的形式寫入HDFS中(a very common pattern for saving unbounded files (e.g. log files) is to write them in chunks into HDFS)。
(2)檔案本身就是很小。設想一下,我們有一個很大的圖片語料庫,每一個圖片都是一個獨一的檔案,並且沒有一種很好的方法來將這些檔案合併為一個大的檔案。
4. 解決方案
這兩種情況需要有不同的解決方 式。
4.1 第一種情況
對於第一種情況,檔案是許多記錄(Records)組成的,那麼可以通過呼叫HDFS的sync()方法(和append方法結合使用),每隔一定時間生成一個大檔案。或者,可以通過寫一個程式來來合併這些小檔案(可以看一下Nathan Marz關於Consolidator一種小工具的文章)。
4.2 第二種情況
對於第二種情況,就需要某種形式的容器通過某種方式來對這些檔案進行分組。Hadoop提供了一些選擇:
4.2.1 HAR File
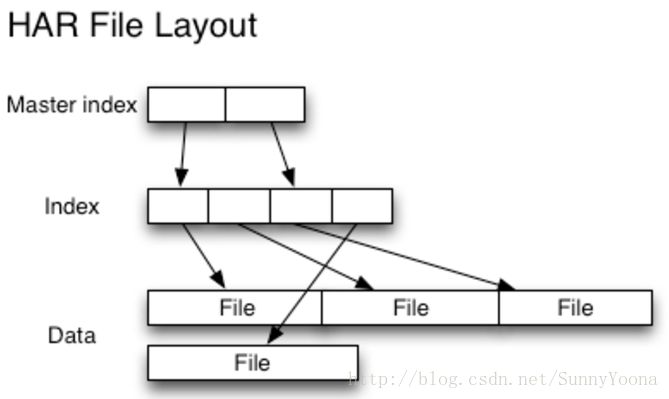
Hadoop Archives (HAR files)是在0.18.0版本中引入到HDFS中的,它的出現就是為了緩解大量小檔案消耗NameNode記憶體的問題。HAR檔案是通過在HDFS上構建一個分層檔案系統來工作。HAR檔案通過hadoop archive命令來建立,而這個命令實 際上是運行了一個MapReduce作業來將小檔案打包成少量的HDFS檔案(譯者注:將小檔案進行合併幾個大檔案)。對於client端來說,使用HAR檔案沒有任何的改變:所有的原始檔案都可見以及可訪問(只是使用har://URL,而不是hdfs://URL),但是在HDFS中中檔案數卻減少了。
讀取HAR中的檔案不如讀取HDFS中的檔案更有效,並且實際上可能較慢,因為每個HAR檔案訪問需要讀取兩個索引檔案以及還要讀取資料檔案本身(如下圖)。儘管HAR檔案可以用作MapReduce的輸入,但是沒有特殊的魔法允許MapReduce直接操作HAR在HDFS塊上的所有檔案(although HAR files can be used as input to MapReduce, there is no special magic that allows maps to operate over all the files in the HAR co-resident on a HDFS block)。 可以考慮通過建立一種input format,充分利用HAR檔案的區域性性優勢,但是目前還沒有這種input format。需要注意的是:MultiFileInputSplit,即使在HADOOP-4565(https://issues.apache.org/jira/browse/HADOOP-4565)的改進,但始終還是需要每個小檔案的尋找。我們非常有興趣看到這個與SequenceFile進行對比。 在目前看來,HARs可能最好僅用於儲存文件(At the current time HARs are probably best used purely for archival purposes.)。
4.2.2 SequenceFile
通常對於"小檔案問題"的迴應會是:使用序列檔案(SequenceFile)。這種方法的思路是,使用檔名(filename)作為key,並且檔案內容(file contents)作為value,如下圖。在實踐中這種方式非常有效。我們回到10,000個100KB小檔案問題上,你可以編寫一個程式將它們放入一個單一的SequenceFile,然後你可以流式處理它們(直接處理或使用MapReduce)操作SequenceFile。這樣同時會帶來兩個優勢:(1)SequenceFiles是可拆分的,因此MapReduce可以將它們分成塊並獨立地對每個塊進行操作;(2)它們同時支援壓縮,不像HAR。 在大多數情況下,塊壓縮是最好的選擇,因為它將壓縮幾個記錄為一個塊,而不是一個記錄壓縮一個塊。(Block compression is the best option in most cases, since it compresses blocks of several records (rather than per record))。

將現有資料轉換為SequenceFile可能很慢。 但是,完全可以並行建立SequenceFile的集合。(It can be slow to convert existing data into Sequence Files. However, it is perfectly possible to create a collection of Sequence Files in parallel.)Stuart Sierra寫了一篇關於將tar檔案轉換為SequenceFile的文章(https://stuartsierra.com/2008/04/24/a-million-little-files ),像這樣的工具是非常有用的,我們應該多看看。展望未來,最好設計資料管道,將源資料直接寫入SequenceFile(如果可能),而不是作為中間步驟寫入小檔案。
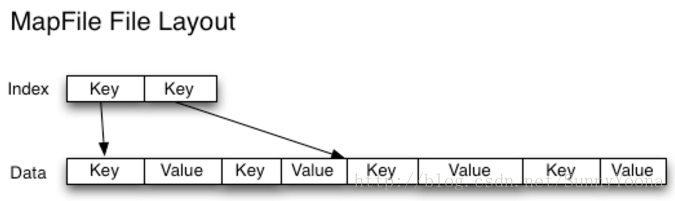
與HAR檔案不同,沒有辦法列出SequenceFile中的所有鍵,所以不能讀取整個檔案。Map File,就像對鍵進行排序的SequenceFile,只維護了部分索引,所以他們也不能列出所有的鍵,如下圖。
SequenceFile是以Java為中心的。 TFile(https://issues.apache.org/jira/browse/HADOOP-4565 )設計為跨平臺,並且可以替代SequenceFile,不過現在還不可用。
4.2.3 HBase
如果你生產很多小檔案,那麼根據訪問模式,不同型別的儲存可能更合適(If you are producing lots of small files, then, depending on the access pattern, a different type of storage might be more appropriate)。HBase以Map Files(帶索引的SequenceFile)方式儲存資料,如果您需要隨機訪問來執行MapReduce式流式分析,這是一個不錯的選擇( HBase stores data in MapFiles (indexed SequenceFiles), and is a good choice if you need to do MapReduce style streaming analyses with the occasional random look up)。如果延遲是一個問題,那麼還有很多其他選擇 - 參見Richard Jones對鍵值儲存的調查(http://www.metabrew.com/article/anti-rdbms-a-list-of-distributed-key-value-stores/)。