
【論文筆記02】Text Understanding with the Attention Sum Reader Network
1 問題及資料集
1.1 問題
給定較長一段話的context和一個較短的問題,以及一些candidate answers,訓練出可以準確預測正確答案的模型,本模型主要針對命名實體和常用名詞這兩種詞性的單詞進行填空。
1.2資料集
(1)CNN&Daily Mail
(2)CBT
2 已有方法
(1)Attentive and Impatient Readers
(2)Attentive
(3)Chen et al. 2016
(4)MemNNs
(5)Pointer Networks
(6)Dynamic Entity Representation
3 本文提出的方法
ASReader模型使用注意力機制計算每個單詞的注意力權重之和,從而從上下文中選擇答案,而不是像在之前的模型一樣,使用文件與問題的相似度或提取特徵構建特徵工程等方式來定位答案。
4 具體內容
4.1 網路結構
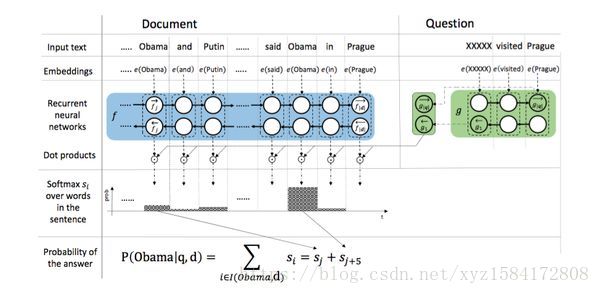
4.2具體過程
step1:通過一層Embedding層將document和query中的word分別對映成向量。
step2:用一個單層雙向GRU來encode document,得到context representation,每個time step的拼接來表示該詞
step3:用一個單層雙向GRU來encode query,用兩個方向的last state拼接來表示query。
step4:每個word vector與query vector作點積後歸一化的結果作為attention weights,就query與document中的每個詞之前的相關性度量。
step5
4.3 評估方法
average ensemble by top 20%:更改初始化引數,訓練多個模型,然後取在驗證集上效果最好的前20%個模型做bagging.
average ensemble:取前效果排名前70%的model做bagging
greedy ensemble:根據效果排序從效果最好的模型開始bagging,如果bagging後的模型在驗證集上效果更好就加入,一直持續到最後。
5.實驗結果
5.1.CNN/Daily Mail
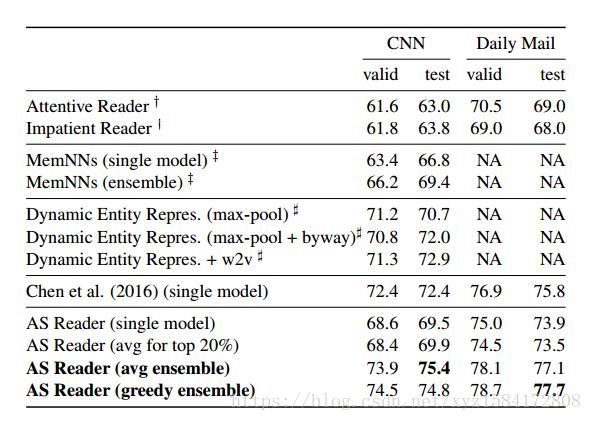
5.2.CBT
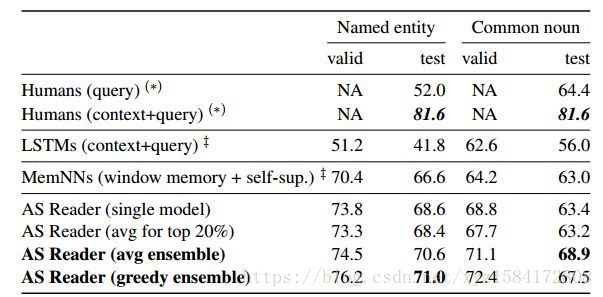
6 小結
(1)利用點積來計算注意力權重,簡化了模型,但是能達到同樣或者更好的效果。
(2)利用注意力權重之和來選擇答案,而不是像以前的工作那樣通過權重提取特徵從而預測答案,但該模型更傾向於選擇重複次數較多的單詞作為答案。

資源來源
論文地址
論文程式碼
相關論文筆記
相關推薦
【論文筆記02】Text Understanding with the Attention Sum Reader Network
1 問題及資料集 1.1 問題 給定較長一段話的context和一個較短的問題,以及一些candidate answers,訓練出可以準確預測正確答案的模型,本模型主要針對命名實體和常用名詞這兩種詞性的單詞進行填空。 1.2資料集 (1)CNN&Dail
【論文筆記1】RNN在影象壓縮領域的運用——Variable Rate Image Compression with Recurrent Neural Networks
一、引言 隨著網際網路的發展,網路圖片的數量越來越多,而使用者對網頁載入的速度要求越來越高。為了滿足使用者對網頁載入快速性、舒適性的服務需求,如何將影象以更低的位元組數儲存(儲存空間的節省意味著更快的傳輸速度)並給使用者一個低解析度的thumbnails(縮圖)的previ
【論文筆記2】影象壓縮神經網路在Kodak資料集上首次超越JPEG——Full Resolution Image Compression with Recurrent Neural Networks
一、引言 這篇論文提出了一種基於神經網路的全解析度的有損影象壓縮方法,在變壓縮比的情況下無需重複訓練,所以說整個網路只需要訓練一次。論文的內容主要包括如下三個部分: (1)提出了三種影象壓縮框架,分別是基於LSTM的RNN網路、基於關聯LSTM(associative
【論文筆記-Stereo】Pyramid Stereo Matching Network
論文思想 使用ResNet提取特徵 用dilated convolution增大感受野 用Pyramid pooling module,提取各個scale的特徵,使之包含global的context資訊 用feature volume shift構
【C++筆記02】VS2017使用建立MFCActiveX控制元件專案
無從下手的感覺,只要從基本編輯器工具使用和基礎的操作開始學習,一步一步堆積起來了。在VS2017中建立,針對我的操作做一個筆記。啟動VS2017軟體,最好以管理員身份執行啟動軟體,在VS2017介面的選單欄中,檔案-新建-專案(Ctrl+Shift+N),開啟新建專案,選擇已
【論文筆記07】End-To-End Memory Networks
1 背景 (1)在記憶網路中,主要由4個模組組成:I、G、O、R,前面也提到I和G模組其實並沒有進行多複雜的操作,只是將原始文字進行向量表示後直接儲存在記憶槽中。而主要工作集中在O和R模組,O用來選擇與問題相關的記憶,R用來回答,而這兩部分都需要監督,也就是需要
【論文筆記09】Teaching Machines to Read and Comprehend
本文主要做出了兩個大的貢獻: 給出了閱讀理解資料集的構造方法,並開源了兩個閱讀理解資料集; 提出了三種神經網路模型作為baseline,以方便後面的研究者進行相關的研究。 1 資料構造 主要是從新聞網站中抓取新聞作為文章,新聞的摘要去掉一個實體詞成為quer
【論文筆記4】深入理解行人重識別網路的Loss
打完天池比賽後,可能由於長時間的持續輸出,精神上有些疲憊感,於是選擇去幹一些不是很費腦力的活兒,比如繼續充充電,看些論文補充一些理論知識。這兩天看了幾篇羅老師部落格裡總結的Person Re-Identification這塊的論文,包括羅老師自己發的兩篇論文。幾篇論文中都用到
【論文筆記系列】AutoML:A Survey of State-of-the-art (上)
之前已經發過一篇文章來介紹我寫的AutoML綜述,最近把文章內容做了更新,所以這篇稍微細緻地介紹一下。由於篇幅有限,下面介紹的方法中涉及到的細節感興趣的可以移步到論文中檢視。 論文地址:https://arxiv.org/abs/1908.00709 1. Introduction 以往的模型都是靠大佬們
論文筆記《Chinese Lexical Analysis with Deep Bi-GRU-CRF Network》
Chinese Lexical Analysis with Deep Bi-GRU-CRF Network 百度自然語言處理部的一篇論文,提出了一個結合分詞,詞性標註和命名實體識別的工具。 論文指出百度已經開發了各種分詞,詞性標註,實體識別的工具,相互獨立以
【論文筆記】FOTS: Fast Oriented Text Spotting with a Unified Network
pdf連結:https://arxiv.org/pdf/1801.01671.pdf資料集的相關情況:1.ICDAR2013ICDAR2013包括四個資料夾,分別是:訓練影象集:Challenge2_Training_Task12_Images訓練標註集:Challenge2
Semantic Parsing via Staged Query Graph Generation: Question Answering with Knowledge Base【論文筆記】
一、摘要 我們對知識庫問答提出一個新穎的語義解析框架。我們定義了一個類似於知識庫子圖的查詢圖,可以直接對映為邏輯形式。語義解析被簡化為查詢圖生成,被表述為分階段搜尋問題。與傳統方法不同,我們的方法在早期就利用知識庫來修剪搜尋空間,從而簡化語義匹配問題。通過應用實體鏈指系統和深度卷
Question Answering over Freebase with Multi-Column Convolutional Neural Networks【論文筆記】
一、概要 通過知識庫回答自然語言問題是一個重要的具有挑戰性的任務。大多數目前的系統依賴於手工特徵和規則。本篇論文,我們介紹了MCCNNs,從三個不同層面(答案路徑,答案型別,答案上下文)來理解問題。同時,在知識庫中我們共同學習實體和關係的低維詞向量。問答對用於訓練模型以對候選答案
Question Answering with Subgraph Embeddings【論文筆記】
一、摘要 這篇論文提出一個系統,在大範圍主題的知識庫中,學習使用較少的手工特徵來回答問題。我們的模型學習單詞和知識庫組成的低維詞向量。這些表示用於根據候選答案對自然語言問題打分。使用成對的問題和對應答案的結構化表示,和成對的問題釋義來訓練系統,在最近的文獻基準中產生有競爭力的結果。 &n
Information Extraction over Structured Data: Question Answering with Freebase【論文筆記】
Information Extraction over Structured Data:Question Answering with Freebase 一、摘要
【論文筆記】用形狀做擋風玻璃上的雨滴檢測《Detection Of Raindrop With Various Shapes On A Windshield》
《Detection of Raindrop with Various Shapes on a Windshield》 1 介紹 2 雨滴檢測方法 在白天和夜晚使用不同的演算法。通過整幅影象的強度水平判斷是白天還是夜晚。 2.1 白天的雨滴檢測方法 這個方法假設
【論文筆記】Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
寫在前面: 我看的paper大多為Computer Vision、Deep Learning相關的paper,現在基本也處於入門階段,一些理解可能不太正確。說到底,小女子才疏學淺,如果有錯
【論文筆記】Deep Structured Output Learning for Unconstrained Text Recognition
寫在前面: 我看的paper大多為Computer Vision、Deep Learning相關的paper,現在基本也處於入門階段,一些理解可能不太正確。說到底,小女子才疏學淺,如果有錯誤及理解不透
【論文筆記】One Millisecond Face Alignment with an Ensemble of Regression Trees
參考文獻: Kazemi V, Sullivan J. One millisecond face alignment with an ensemble of regression trees[C]//Computer Vision and Pattern
【論文筆記】Text-Recognition_簡略版_201606
【1】Shi B, Wang X, Lv P, et al. Robust Scene Text Recognition with Automatic Rectification[J]. arXiv p