
目標檢測——細讀YOLO V1
阿新 • • 發佈:2019-01-19
Yolo(You Only Look Once)是一個end-to-end的目標檢測演算法。作者在論文中提出,人類的視覺系統是快速和準確的, 人們瞥一眼影象,立即知道影象中的物體是什麼,它們在哪裡以及它們如何相互作用。而對於Rcnn系列的方法,都是需要先找到有可能有物體的框(anchor box),然後進行前背景分類,nms消除重疊框,重新進行座標迴歸和分類,這個流程就比較複雜,並且每個步驟的元件的優化都比較麻煩,無論是訓練還是最終的測試,速度都非常慢。
因此,yolo的作者提出,將目標檢測的問題轉化為一個迴歸問題,只通過一個步驟就能找到目標的位置。
Yolo的檢測步驟:
- 將影象劃分成的網格,如果一個目標物體的中心點落在一個網格中,那麼這個網格就負責預測這個目標。
- 每個網格預測B個邊框和置信度分數。
- 邊框用表示,表示目標邊框的中心相對於網格的位置(論文裡沒說是相對於網格的中心還是左上角之類的,實際情況兩種應該沒什麼差別),而是相對於整個影象的大小。
- 置信度表示預測框與實際框之間的IOU。
- 每個網格還預測個類的概率,也就是在這個網格有物體的情況下,是某個類的概率。值得一提的是,一個網格只預測一組類的概率,和預測的框的數量沒有關係。
- 最終,網路的輸出就為的tensor。
一些細節的討論:
- yolo的輸出就是一個的tensor,其實最終就是跟了一個全連線,只是人為的將輸出劃分為有意義的部分。
- 把輸入圖劃分成的網格很好理解,但是為什麼每個網格預測個框,卻只預測了一組類呢?這也是我開始讀yolo的時候覺得很奇怪的地方。我們可以設想一下這兩種情況:(1)兩個或多個同類物體的中心在同一個網格中, (2) 兩個或多個不同類物體的中心在同一個網格中。這兩種情況,yolo的訓練是如何進行的?在參考了一些原始碼之後,我得出的結論是,yolo放棄了一個網格中預測多個不同類的能力,預設每個網格只能有一個類,這也導致一個網格最多預測出B個同類的框。可以看出來,這種結構也導致了yolo對於密集物體檢測效果不好。還有,在訓練的時候,如果有多個物體落在同一個網格中,那麼yolo只能選擇一個(darknet原始碼把yolo幾個版本都雜糅進去,不太好看,但是看了幾個其他版本的程式碼是這樣的)。
- 按照作者的說法,預測個框,可以讓每個predictor變得“專業化”,簡單來說,每個predictor “擅長”預測特定的大小,方向,或者類別的物體,這有助於提高整體的recall。
- yolo在優化框的時候,座標使用平方和誤差,對於寬和高同樣使用平方和誤差,但是優化的目標從改為,作者的解釋是,對於同樣小的誤差來說,小的框有這種誤差遠比大的框有這種誤差要更糟糕一些,所以取了平方根,期望能夠在框的size小的時候能有相對較大的loss。
- 關於置信度, 給出的置信度包含了兩部分,一個是該box包含物體的可能性,另一個是這個box框的有多準。用公式來描述就是:。
- 最後測試的時候,用置信度乘分類概率,一個框就可以得到一個特定的置信度分數,這個分數代表了某類在框中的概率以及框的準確率。用公式描述就是:
網路結構與訓練
下圖就是yolo的網路結構,其中
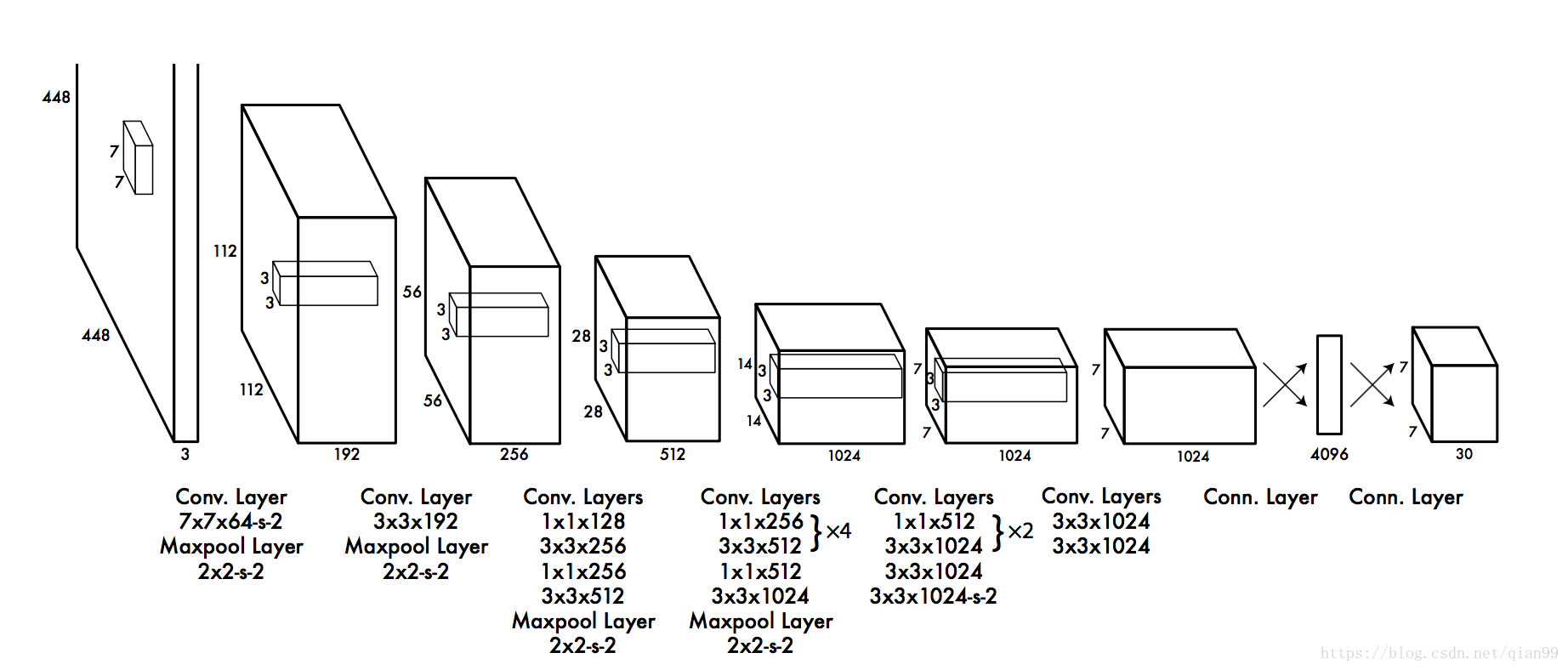
在訓練yolo的時候,作者發現,大部分的網格中是沒有物體的,這就導致了,訓練中,這些網格的梯度“主導”了整個訓練,導致一開始,置信度都趨向於0,模型很容易就“訓飛”。
因此,在訓練的時候,作者對這兩部分loss進行了加權,邊框預測的loss,引數為, 不包含物體的部分的loss,引數為。
下面是訓練的損失函式:
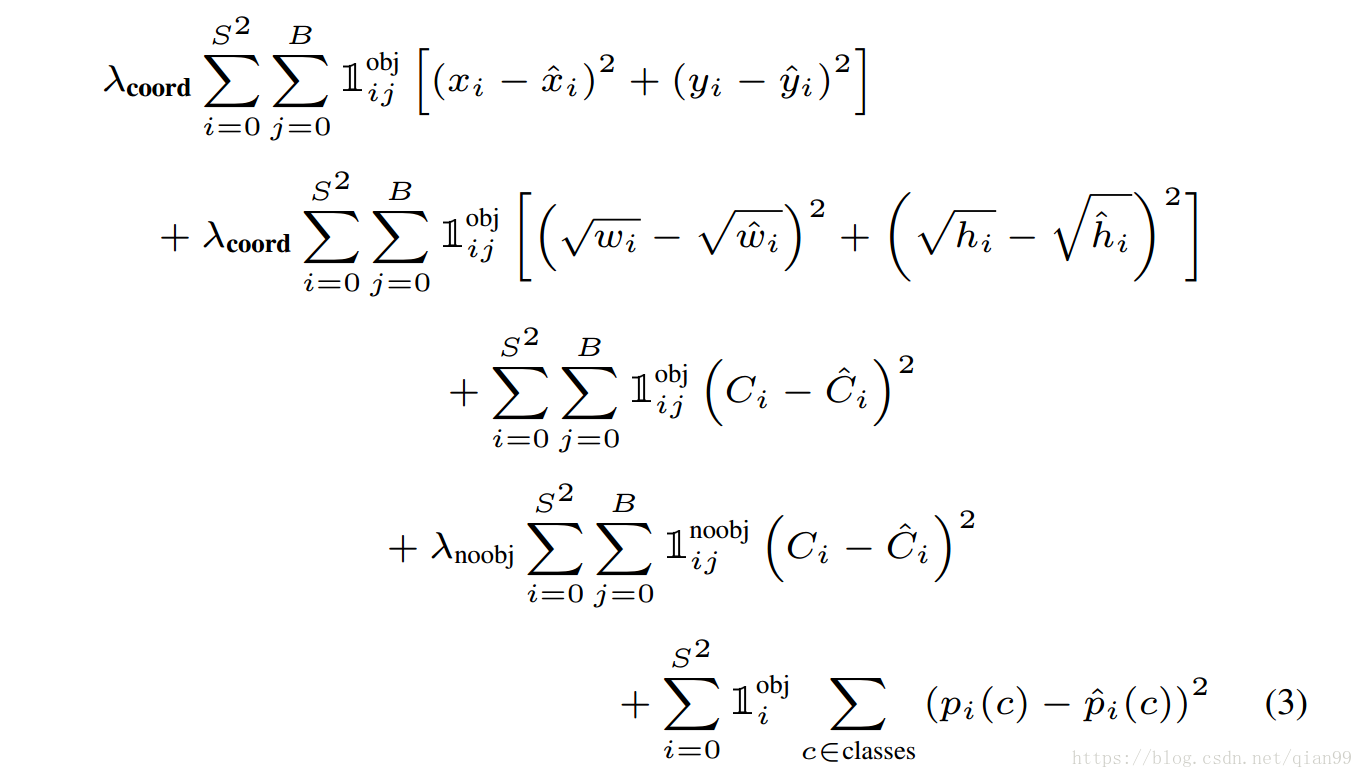
其中, 表示,在第個網格,由負責的框中是否有物體。表示,在第個網格,由負責的框中是否沒有物體。表示,在第個網格中是否存在物體。對於第三行,也就是在這個框內有物體的時候,預測分類沒問題,但是第四行,這個框內就沒有物體,這時ground truth的分類是什麼呢?參考程式碼,我的結論是,這裡的ground truth是不屬於任何類,這不代表我們要把分類的數量增加一個維度。在神經網路中,分類的輸出通常用one hot 編碼表示,也就是一個的向量,第類就讓