
從零使用強化學習訓練AI玩兒遊戲(9)——使用DQN(Keras+CNN)
做了這麼。。。。。終於到達這一步了。
上一篇我們用簡單的全連線神經網路實現了DQN玩兒了一個簡單的遊戲,今天我們要用一個複雜的神經網路來玩兒一個複雜的遊戲,SpaceInvaders-v0,就玩這個遊戲吧,看起來很棒的樣子,隨便選的。
在這個遊戲中observaction是一個螢幕RGB的圖片,shape是(210,160,3) = 100800個數據正好試一下卷積神經網路,action 6箇中4是傳送子彈 2、3分別是左右,reward就是你打沒打死那個外星人所得到的獎勵,就是圖片上的分數,reward分別是5,10,15,20,25,30,每往上增加一層的外星人加5分,然後時不時的有一個紫色的外星人出現,打中他加200分,這裡可以考慮做不做歸一化處理,我這裡先不做歸一化處理直接使用它的reward。然後我看國外的論文中也有用opencv先做一個影象處理的,我這裡也先不做了就用原圖。

看來我還是太小看這個神經網路的訓練,還有太高估我渣渣電腦的能力了,居然還想不做影象預處理直接跑。。。。。。根本跑不動啊。。。。我還是老老實實加opencv預處理吧,還有opencv比較熟悉。
所以使用這個教程安裝opencv,在這個教程中我沒有進入Windows的終端,而是進入anaconda prompt進行安裝的,要不然找不到pip命令。
做灰度化處理後的效果:
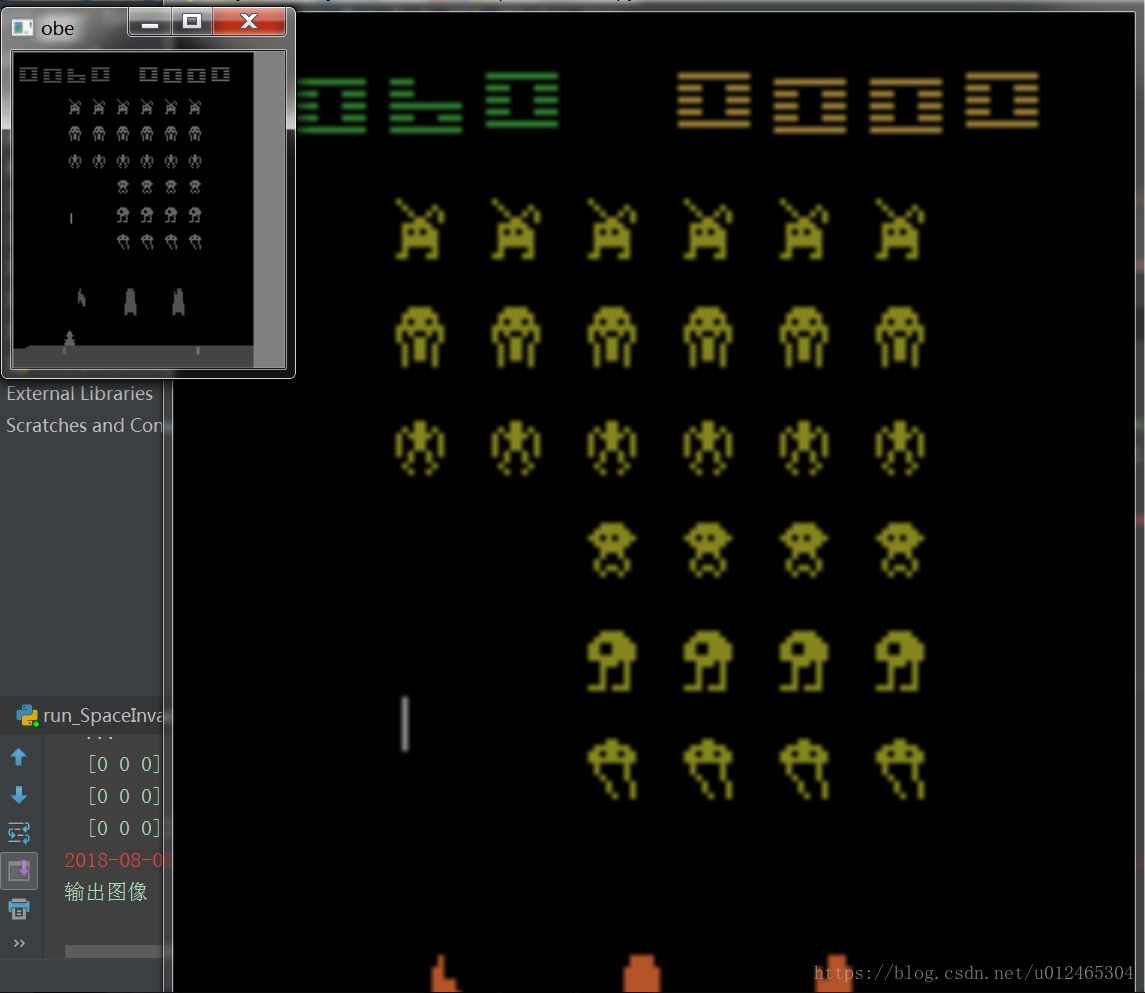
加了opencv處理後還是很慢,但是比之前好多了
接下來還需要繼續優化神經網路,讓訓練的速度變快。
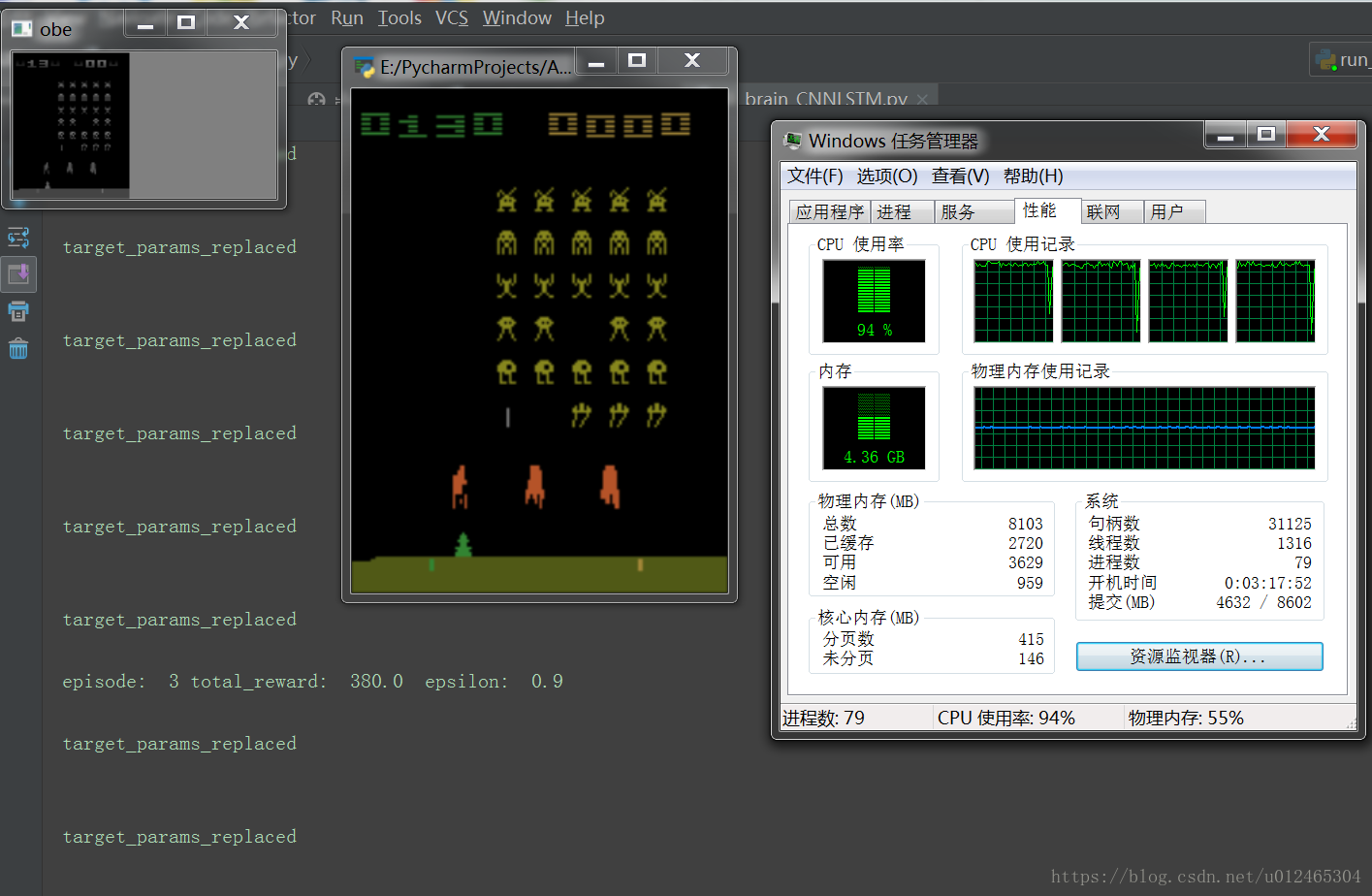
真正遇到大資料做機器學習的時候就知道自己的電腦有多差了。。。。。。。可優化後的學習速度都需要1.1s左右,導致整個遊戲完全沒法看,所以我開了一個執行緒來控制是否學習,也就是說關閉學習的時候能從遊戲介面中看出學習的成果,但還是太慢了。。。。。。。所以接下來可能在網上租一個伺服器,或者去實驗室用實驗室的伺服器來跑一跑看看效果。
接下來看看我搭的神經網路是什麼樣的,看起來很大的樣子,其實說到底也就是四層,前兩層是卷積神經網路,配備了pooling減少資料損失,然後加上兩層全連線網路,本來這個地方是要放LSTM的,但是我的電腦更跑不動了。。。。。。所以先用全連線。等我找到好的伺服器再修改。
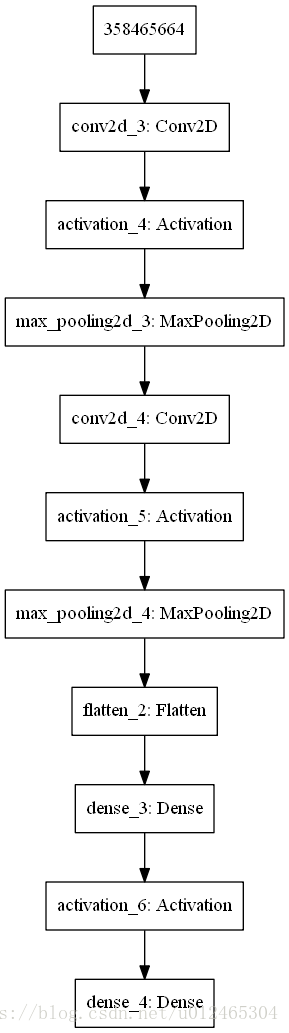
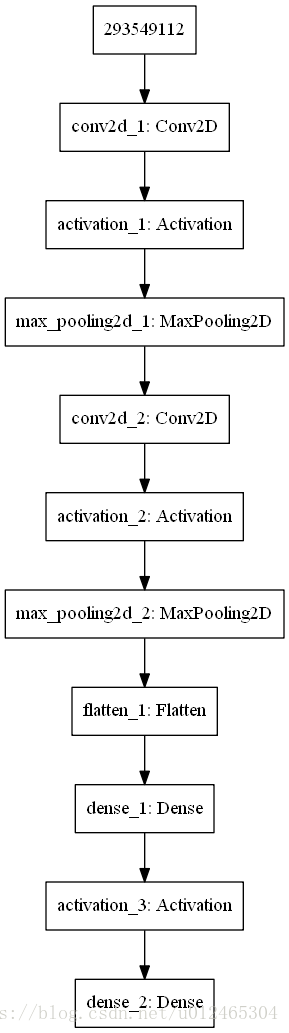
這個是搭建兩個神經網路的程式碼,Keras搭建的,真的超級方便。(詳見註釋)
def _build_net(self): # ------------------ 建造估計層 ------------------ # 因為神經網路在這個地方只是用來輸出不同動作對應的Q值,最後的決策是用Q表的選擇來做的 # 所以其實這裡的神經網路可以看做是一個線性的,也就是通過不同的輸入有不同的輸出,而不是確定類別的幾個輸出 # 這裡我們先按照上一個例子造一個兩層每層單個神經元的神經網路 self.model_eval = Sequential([ # 輸入第一層是一個二維卷積層(100, 80, 1) Convolution2D( # 就是Conv2D層 batch_input_shape=(None, self.observation_shape[0], self.observation_shape[1], self.observation_shape[2]), filters=15, # 多少個濾波器 卷積核的數目(即輸出的維度) kernel_size=5, # 卷積核的寬度和長度。如為單個整數,則表示在各個空間維度的相同長度。 strides=1, # 每次滑動大小 padding='same', # Padding 的方法也就是過濾後資料xy大小是否和之前的一樣 data_format='channels_last', # 表示影象通道維的位置,這裡rgb影象是最後一維表示通道 ), Activation('relu'), # 輸出(100, 80, 15) # Pooling layer 1 (max pooling) output shape (50, 40, 15) MaxPooling2D( pool_size=2, # 池化視窗大小 strides=2, # 下采樣因子 padding='same', # Padding method data_format='channels_last', ), # output(50, 40, 30) Convolution2D(30, 5, strides=1, padding='same', data_format='channels_last'), Activation('relu'), # (10, 8, 30) MaxPooling2D(5, 5, 'same', data_format='channels_first'), # (10, 8, 30) Flatten(), # LSTM( # units=1024, # return_sequences=True, # True: output at all steps. False: output as last step. # stateful=True, # True: the final state of batch1 is feed into the initial state of batch2 # ), Dense(512), Activation('relu'), Dense(self.n_actions), ]) # 選擇rms優化器,輸入學習率引數 rmsprop = RMSprop(lr=self.lr, rho=0.9, epsilon=1e-08, decay=0.0) self.model_eval.compile(loss='mse', optimizer=rmsprop, metrics=['accuracy']) # ------------------ 構建目標神經網路 ------------------ # 目標神經網路的架構必須和估計神經網路一樣,但是不需要計算損失函式 self.model_target = Sequential([ Convolution2D( # 就是Conv2D層 batch_input_shape=(None, self.observation_shape[0], self.observation_shape[1], self.observation_shape[2]), filters=15, # 多少個濾波器 卷積核的數目(即輸出的維度) kernel_size=5, # 卷積核的寬度和長度。如為單個整數,則表示在各個空間維度的相同長度。 strides=1, # 每次滑動大小 padding='same', # Padding 的方法也就是過濾後資料xy大小是否和之前的一樣 data_format='channels_last', # 表示影象通道維的位置,這裡rgb影象是最後一維表示通道 ), Activation('relu'), # 輸出(210, 160, 30) # Pooling layer 1 (max pooling) output shape (105, 80, 30) MaxPooling2D( pool_size=2, # 池化視窗大小 strides=2, # 下采樣因子 padding='same', # Padding method data_format='channels_last', ), # output(105, 80, 60) Convolution2D(30, 5, strides=1, padding='same', data_format='channels_last'), Activation('relu'), # (21, 16, 60) MaxPooling2D(5, 5, 'same', data_format='channels_first'), # 21 * 16 * 60 = 20160 Flatten(), # LSTM( # units=1024, # return_sequences=True, # True: output at all steps. False: output as last step. # stateful=True, # True: the final state of batch1 is feed into the initial state of batch2 # ), Dense(512), Activation('relu'), Dense(self.n_actions), ])
我準備用一下午時間跑一跑,看看會不會有效果。
訓練了20個小時後的reward結果,由於隨機性的問題肯定會有一些浮動,但是整體的趨勢還是看的出來是在上升的。
我們就按波谷點來看,可以看出一個上升趨勢。
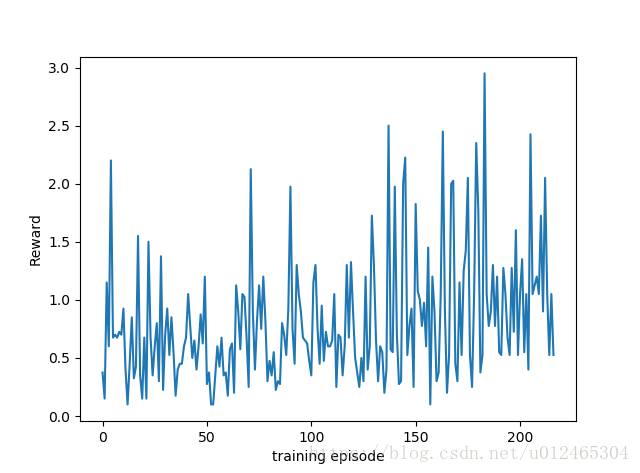
跑了這麼久,有點懷疑是不是神經網路架構有問題,所以拜讀了一下deepmind玩這個遊戲的文章Playing Atari with Deep Reinforcement Learning,發現其實我們的架構是相同的,所以應該是我的硬體太差了遲遲沒有特別好的效果出來。

惹不起,原來他訓練了1千萬的資料,我算了一下 如果我訓練一千萬個數據大概需要十一天。。。。。。所以我們大概看看結果就好了吧。。。。。。。

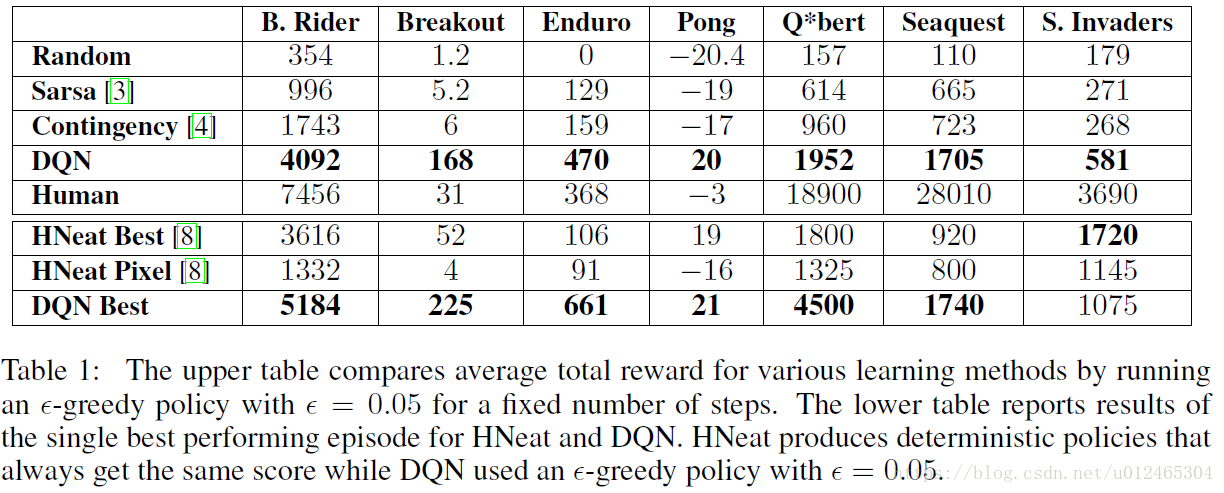
下面這幅圖是deepmind訓練各種遊戲後得到的平均分和最高分,可以看到DQN其實在我們選的這款遊戲S.invders上達到500多分已經算得上他的平均了。其實這款遊戲對神經網路來說算是有點難的了,因為他的策略要求更高。The games Q*bert, Seaquest, Space Invaders, on which we are far from human performance, are more challenging
because they require the network to find a strategy that extends over long time scales.
所以我想應該是要加入LSTM會有更好的效果,但是實在是找不到跑這麼大資料量的啊。。。。。。哎~~~窮
相關推薦
從零使用強化學習訓練AI玩兒遊戲(9)——使用DQN(Keras+CNN)
做了這麼。。。。。終於到達這一步了。 上一篇我們用簡單的全連線神經網路實現了DQN玩兒了一個簡單的遊戲,今天我們要用一個複雜的神經網路來玩兒一個複雜的遊戲,SpaceInvaders-v0,就玩這個遊戲吧,看起來很棒的樣子,隨便選的。 在這個遊戲中observacti
從零使用強化學習訓練AI玩兒遊戲(7)——使用DQN(TensorFlow)
上一篇我們使用了DQN來玩簡單的走迷宮遊戲,但是DQN能勝任比走迷宮遊戲更復雜的遊戲。這一篇我們就從GYM中選一款遊戲來通過訓練神經網路,讓他自己玩。 我們選擇CartPole這款遊戲,在之前的Q-learning中我們有用過這款遊戲,在Q-lea
從零使用強化學習訓練AI玩兒遊戲(2)——學習Gym
本文目前主要是寫給自己的一個筆記,接下來這段時間會逐步記錄我是怎麼通過學習使用TensorFlow+Keras訓練神經網路自己玩兒遊戲,如果能間接幫助到他人就最好不過了,不喜勿噴。上一篇
Photon Server遊戲伺服器從零開始學習(六)遊戲登入與註冊操作
為了在客戶端與伺服器端使用共同的code,建立共有引用Common: public enum OperationCode:byte //區分請求和響應的型別 { Default,//預設請求 Login, //登入 Register
用50行Python程式碼從零開始實現一個AI平衡小遊戲!
集智導讀: 本文會為大家展示機器學習專家 Mike Shi 如何用 50 行 Python 程式碼建立一個 AI,使用增強學習技術,玩耍一個保持杆子平衡的小遊戲。所用環境為標準的 OpenAI Gym,只使用 Numpy 來建立 agent。 學習Python中有不明白推薦加入交流群號
Photon Server遊戲伺服器從零開始學習(一)部署第一個伺服器程式
概述 Photon引擎是一款實時的Socket伺服器和開發框架,快速、使用方便、容易擴充套件。 服務端架構在windows系統平臺上,採用C#語言編寫。 客戶端SDK提供了多種平臺的開發API,包括DotNet、Unity3D、C/C++以及ObjC等。
從零開始學習html(五)與瀏覽者交互,表單標簽——下
定位 開始 系統 isp ctr 程序 顯示 text 輸入 六、使用下拉列表框進行多選 1 <!DOCTYPE HTML> 2 <html> 3 <head> 4 <meta http-equiv="Content-T
從零開始學習iOS開發1:認識xcode
連接 啟動圖標 主動 認識 tor 音樂 滴滴打車 啟動 and 在開始之前還是不得不提一下iPhone應用開發的工具,我當然之前是沒接觸過iPhone開發,也沒使用過apple的不論什麽一種設備。所以我的概念中僅僅知道xcode是最專業的iOS開發工具。如今它是免費
從零開始學習html(十)CSS格式化排版——下
而是 復習 nbsp 1.5 如果 spl 排版 居住 blog 六、文字排版--刪除線 1 <!DOCTYPE HTML> 2 <html> 3 <head> 4 <meta http-equiv="Content-T
從零開始學習html(十二)CSS布局模型——下
位操作 女生 margin 沒有 定位元素 top 並且 變化 開始 五、什麽是層模型? 什麽是層布局模型?層布局模型就像是圖像軟件PhotoShop中非常流行的圖層編輯功能一樣, 每個圖層能夠精確定位操作,但在網頁設計領域,由於網頁大小的活動性,層布局沒能受到熱捧。 但是
從零開始學習html(十三) CSS代碼縮寫,占用更少的帶寬
tin imp important 都是 -h 20px 帶寬 記得 樣式 一、盒模型代碼簡寫 1 <!DOCTYPE HTML> 2 <html> 3 <head> 4 <meta http-equiv="Conten
從零開始學習html(十四)單位和值
type 當我 總結 學生 專註 bfc span blog 設置顏色 一、顏色值 1 <!DOCTYPE HTML> 2 <html> 3 <head> 4 <meta charset="utf-8"> 5
從零開始學習html(十五)css樣式設置小技巧——下
right ron pos 瀏覽器 spl pan esc 插入 ccf 六、垂直居中-父元素高度確定的單行文本 1 <!DOCTYPE HTML> 2 <html> 3 <head> 4 <meta charset="
從零基礎學習python
fix pytho 零基礎 基礎 tar install 基礎學習 默認 prefix wget http://www.python.org/ftp/python/2.7.8/Python-2.7.8.tgz tar -zxvf Python-2.7.8.tgz cd Py
從零開始學習音視頻編程技術(三) 開發環境搭建(Qt4.86手動設置環境,主要就是設置g++和qmake,比較透徹,附下載鏈接)
路徑 details 分享 baidu 末尾 是我 其中 找到 source 1.先下載安裝Qt 我們使用的版本是4.8。 可以自行百度下載也可以從下面的網盤地址下載: Qt庫和編譯器下載: 鏈接:http://pan.baidu.com/s/1hrUxLIG 密碼
從零開始學習MXnet(五)MXnet的黑科技之顯存節省大法
無法 返回 deep logs all 筆記 linear call data 寫完發現名字有點拗口。。- -# 大家在做deep learning的時候,應該都遇到過顯存不夠用,然後不得不去痛苦的減去batchszie,或者砍自己的網絡結構呢? 最後跑出來的效果不
從零開始學習OpenCL開發(一)架構
處理器 多媒體 c++ stl context 實驗 通用 必看 是你 同時存在 1 異構計算、GPGPU與OpenCL OpenCL是當前一個通用的由很多公司和組織共同發起的多CPU\GPU\其他芯片 異構計算(heterogeneous)的標準,它是跨平臺的。旨在充
從零開始學習jQuery (一) 開天辟地入門篇
完全 不同 喝茶 圖靈 lac 格式化 元素 script 引入 從零開始學習jQuery (一) 開天辟地入門篇 本系列文章導航 從零開始學習jQuery (一) 開天辟地入門篇 從零開始學習jQuery (二) 萬能的選擇器 從零開始學習jQuery (
從零開始學習weka數據挖掘
數據挖掘 weka 人工智能 作為一個免費、公開、開源的數據挖掘工作平臺,Weka集合了大量能承擔數據挖掘任務的機器學習算法,包括預處理、分類、回歸、聚類、關聯規則以及在新的交互式界面上的可視化操作等;目前,Weka最新版本為weka-3-7-11,可以利用weka進行大數據的挖掘和分析處理。WEK
Python,我從零開始學習T^T D7
int res key def yar bsp cti for 多個 當函數遇到不確定數量參數腫麽破?*args和**kwargs前來報道! *args **kwargs 當函數的參數不確定時,可以使用*args 和**kwargs,*args