
從零使用強化學習訓練AI玩兒遊戲(7)——使用DQN(TensorFlow)
阿新 • • 發佈:2019-01-31
上一篇我們使用了DQN來玩簡單的走迷宮遊戲,但是DQN能勝任比走迷宮遊戲更復雜的遊戲。這一篇我們就從GYM中選一款遊戲來通過訓練神經網路,讓他自己玩。
我們選擇CartPole這款遊戲,在之前的Q-learning中我們有用過這款遊戲,在Q-learning上效果非常的差。
由於CartPole這個遊戲的reward是隻要杆子是立起來的,他reward就是1,失敗就是0,顯然這個reward對於連續性變數是不可以接受的,所以我們通過observation修改這個值。點選pycharm右上角的搜尋符號搜尋CartPole進入他環境的原始碼中,再進入step函式,看到裡面返回值state的定義
x, x_dot, theta, theta_dot = state通過這四個值定義新的reward是
x, x_dot, theta, theta_dot = observation_
r1 = (env.x_threshold - abs(x))/env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta))/env.theta_threshold_radians - 0.5
reward = r1 + r2主程式是:
import gym from RL_brain import DeepQNetwork env = gym.make('CartPole-v0') env = env.unwrapped print(env.action_space) print(env.observation_space) print(env.observation_space.high) print(env.observation_space.low) RL = DeepQNetwork(n_actions=env.action_space.n, n_features=env.observation_space.shape[0], learning_rate=0.01, e_greedy=0.9, replace_target_iter=100, memory_size=2000, e_greedy_increment=0.001,) total_steps = 0 for i_episode in range(100): observation = env.reset() ep_r = 0 while True: env.render() action = RL.choose_action(observation) observation_, reward, done, info = env.step(action) # theta越小,越靠近中心,獎勵應該越大 x, x_dot, theta, theta_dot = observation_ r1 = (env.x_threshold - abs(x))/env.x_threshold - 0.8 r2 = (env.theta_threshold_radians - abs(theta))/env.theta_threshold_radians - 0.5 reward = r1 + r2 RL.store_transition(observation, action, reward, observation_) ep_r += reward if total_steps > 1000: RL.learn() if done: print('episode: ', i_episode, 'ep_r: ', round(ep_r, 2), ' epsilon: ', round(RL.epsilon, 2)) break observation = observation_ total_steps += 1 RL.plot_cost()
因為這個遊戲的觀測值只有四個,輸出值也只有一個,所以不需要太大的神經網路,還是用之前單細胞神經網路就行了程式碼在上一篇的最後。
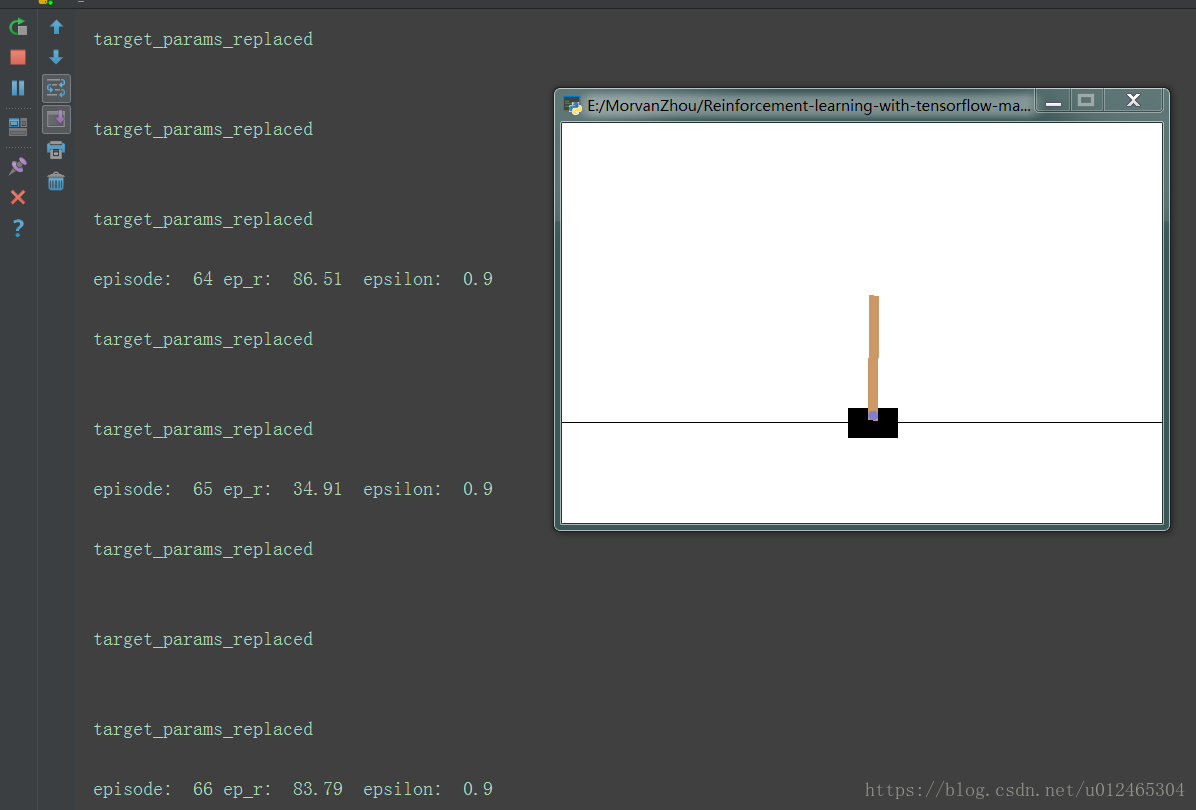
在非常短的訓練時間內我們就能很明顯的看出訓練效果,剛開始基本上沒走幾步就會掉下去,直到後來能堅持83.79秒,甚至到最後一直不掉下去。我們再返回去看一下Q-learning的表現效果,即使運算幾十分鐘仍然是立不起來的。
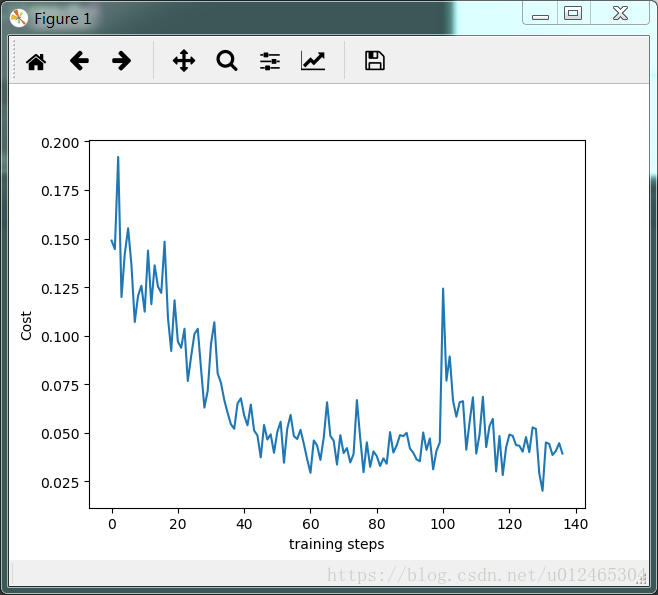
DQN的cost值如下圖所示,只要引數調整的好整體是趨於下降的,但是由於隨機性,和DQN的探索總是會有新的東西出來,所以有的時候會有突變,上下波動也比較大。
下一篇我們就要使用Keras搭建一個更復雜的神經網路,來玩一個更復雜的遊戲。