
hadoop之 hadoop用途方向
hadoop實際應用:
Hadoop+HBase建立NoSQL分散式資料庫應用
Flume+Hadoop+Hive建立離線日誌分析系統
Flume+Logstash+Kafka+Spark Streaming進行實時日誌處理分析
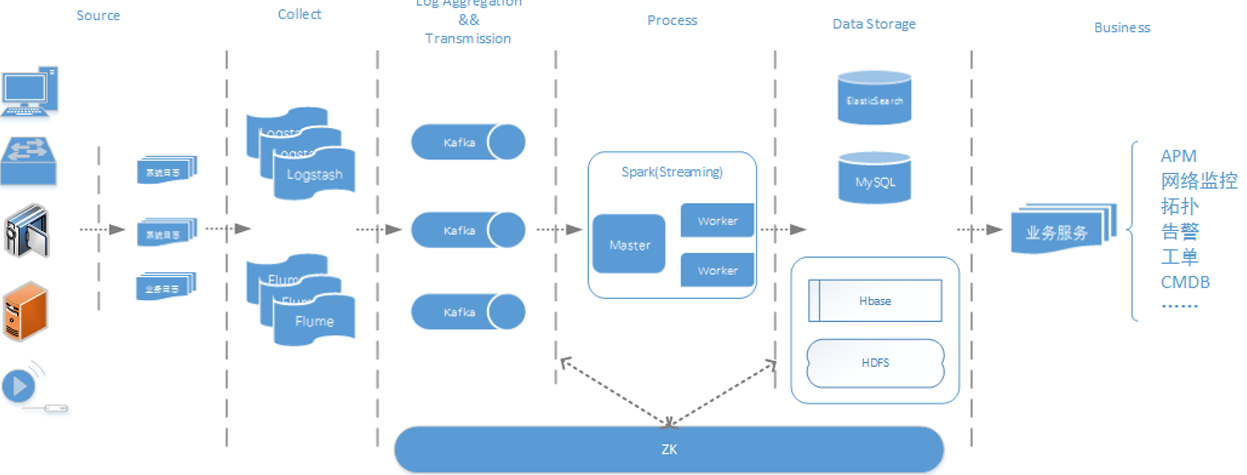
酷狗音樂的大資料平臺
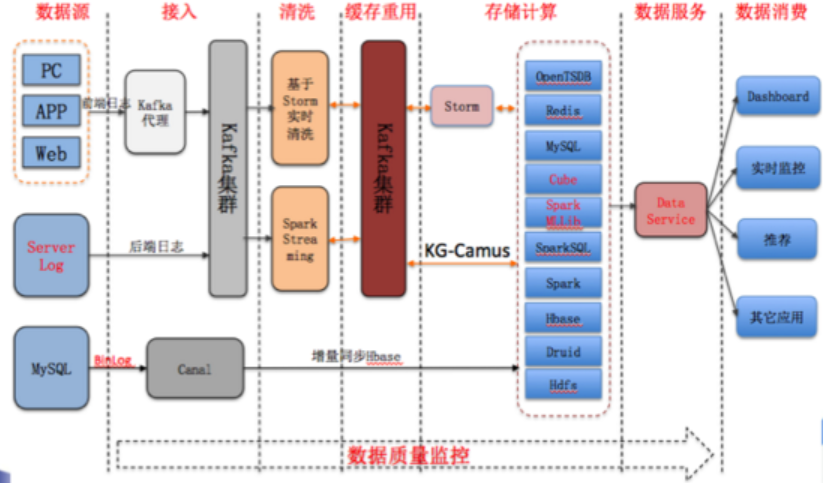
京東的智慧供應鏈預測系統
說明:整理於網路
http://www.cnblogs.com/zhangs1986/p/6528227.html
http://blog.sina.com.cn/s/blog_687194cd01017lgu.html
相關推薦
hadoop之 hadoop用途方向
hadoop實際應用: Hadoop+HBase建立NoSQL分散式資料庫應用 Flume+Hadoop+Hive建立離線日誌分析系統 Flume+Logstash+Kafka+Spark Streaming進行實時日誌處理分析 酷狗音樂的大資料平臺 京東的智慧供應鏈預測系統 說明:整理於網路 h
hadoop之 hadoop 機架感知
信息 內容 其它 heartbeat 循環 yun 一次 能力 高效 1.背景 Hadoop在設計時考慮到數據的安全與高效,數據文件默認在HDFS上存放三份,存儲策略為本地一份,同機架內其它某一節點上一份,不同機架的某一節點上一份。這樣如果本地數據損壞,節點可以從同一機架內
hadoop之 hadoop能為企業做什麼?
hadoop是什麼? Hadoop是一個開源的框架,可編寫和執行分不是應用處理大規模資料,是專為離線和大規模資料分析而設計的,並不適合那種對幾個記錄隨機讀寫的線上事務處理模式。Hadoop=HDFS(檔案系統,資料儲存技術相關)+ Mapreduce(資料處理),Hadoop的資料來源可以是任何形式,在處理
初識Hadoop之Hadoop單機版搭建
最近閒來無事,和朋友志聲大神一起想學習Hadoop,最晚弄機器的弄到兩點多,今天動手和志聲一起安裝Hadoop的環境,剛開始也是一頭霧水啊,Hadoop官網 的教程我也是醉了,說的牛頭不對馬嘴,最後只能通過各種百度解決了問題,最後把安裝的一些操作都記錄下來,希望
全文索引-lucene,solr,nutch,hadoop之nutch與hadoop
aof java get 查詢 自己 結構 目的 strong 之間 全文索引-lucene。solr。nutch,hadoop之lucene 全文索引-lucene。solr,nutch,hadoop之solr 我在去年的時候,就想把lucene,sol
Hadoop之WordCount詳解
ride 開始 zookeepe ati 程序 form 數組 -c 狀態 花了好長時間查找資料理解、學習、總結 這應該是一篇比較全面的MapReduce之WordCount文章了 耐心看下去 1,創建本地文件 在hadoop-2.6.0文件夾下創建一個文件夾data,在其
Hadoop之Combiners編程
cer 大量 使用 ges 一個 分享 類型 log .com 每一個map可能會產生大量的輸出,combiner的作用就是在map端對輸出先做一次合並,以減少傳輸到reducer的數據量。 combiner最基本是實現本地key的歸並,c
Hadoop之HDFS文件操作
文件操作命令 help 文件夾 利用 jpg 查看 作文 rgs fill 摘要:Hadoop之HDFS文件操作常有兩種方式。命令行方式和JavaAPI方式。本文介紹怎樣利用這兩種方式對HDFS文件進行操作。 關鍵詞:HDFS文件 命令行
大數據系列之Hadoop框架
apr png 關系型 big sqoop ted 服務器 定制 操作 Hadoop框架中,有很多優秀的工具,幫助我們解決工作中的問題。 Hadoop的位置 從上圖可以看出,越往右,實時性越高,越往上,涉及到算法等越多。 越往上,越往右就越火…… Hadoop框架中一
2.淺析Hadoop之YARN
返回 ica 組件 任務管理 管理者 節點 container 狀態 nod YARN也是主從架構,主節點是ResourceManager,從節點是NodeManager,是一種資源分配及任務管理的組件 針對每個任務還有ApplicationMaster應用管理者和Cont
Hadoop學習------Hadoop安裝方式之(一):單機部署
root權限 出錯 密碼登錄 例子 .tar.gz sta /usr 成功 tput Hadoop 默認模式為單機(非分布式模式),無需進行其他配置即可運行。非分布式即單 Java 進程,方便進行調試。 1、創建用戶 1.1創建hadoop用戶組和用戶 一般我們不會
Hadoop學習------Hadoop安裝方式之(三):分布式部署
之間 root用戶 jar .sh author tables eth1 report 標識 這裏為了方便直接將單機部署過的虛擬機直接克隆,當然也可以不這樣做,一個個手工部署。 創建完整克隆——>下一步——>安裝位置。等待一段時間即可。 我這邊用了三臺虛擬
hadoop之 HDFS-Hadoop存檔
文件的 指定 文件創建 ruby 所有 元數據 不能 選項 輸入 每個文件按塊方式存儲, 每個塊的元數據存儲在namenode的內存中 Hadoop存檔文件或HAR文件是一個更高效的文件存檔工具,它將文件存入HDFS塊,在減少內存使用的同時,允許對文件進行透明地訪問 Ha
一臉懵逼學習hadoop之HDFS的java客戶端編寫
txt 維護 刪除文件 trac 實例 for nod delete reat 1:eclipse創建一個項目,然後導入對應的jar包: 鼠標右擊項目,點擊properties或者alt+enter快捷鍵--->java build path--->libra
hadoop之 安全模式及SafeModeException
urn 修改 auto 運行 節點 hold -i rep pac 問題: hadoop啟動的時候報錯 HTTP ERROR 500 Problem accessing /nn_browsedfscontent.jsp. Reason: Cannot iss
七、Hadoop學習筆記————調優之Hadoop參數調優
node 參數 受限 .com 資源 mage 預留空間 嘗試 nod dfs.datanode.handler.count默認為3,大集群可以調整為10 傳統MapReduce和yarn對比 如果服務器物理內存128G,則容器內存建議為100比較合理 配置總
Hadoop 之 Hive 安裝與配置
file 接下來 重新 軟件 driver name arc /etc ted Hive 作為基於Hadoop的一個數據倉庫工具,可將sql語句轉換為MapReduce任務進行運行。 通過類SQL語句快速實現簡單的MapReduce統計,不用開發專門的MapReduce應用
小白學習大數據測試之hadoop初探
itl atan 運行 -o dfs 應用 一起 ext testing Hadoop的歷史這裏就不多說了,網上很多資料,總而言之對於hadoop谷歌和雅虎對於ta的貢獻功不可沒。更多介紹請自行查看這裏:https://baike.baidu.com/item/Hadoop
小白學習大數據測試之hadoop再次探索
pan red 系統 ini 多說 自動 hdfs ide style 引子雖然通過《小白學習大數據測試之hadoop初探》以及把hadoop的基本核心說明白了,但是似乎對於小白來說還是會有點懵逼。。。。那麽這次我們就在來看看大數據粗暴理解大數據甭管什麽,簡單粗暴的理解為大
Hadoop之HDFS
src 輸出 about lin pen 中一 文件是否存在 分配 input HDFS即Hadoop Distributed File System分布式文件系統,它的設計目標是把超大數據集存儲到分布在網絡中的多臺普通商用計算機上,並且能夠提供高可靠性和高吞吐量的服務