
Java IO系列3 位元組流之DataInputStream與DataOutputStream
編碼與字符集
什麼把這個專題放在這,因為DataInputStream與DataOutputStream裡有個
readUTF()或writeUTF(String str)方法。
由於這方面的內容我看的資料還有限,難免出錯,看到下面的內容後自己去找資料證實。不要相信別人的話,要自己求證。以下內容僅供參考
編碼和字符集不是一個概念,字符集表示碼點與字元之間的對映關係,至於怎麼儲存,字符集也不關心,具體儲存交給編碼,但是編碼要依賴於字符集。
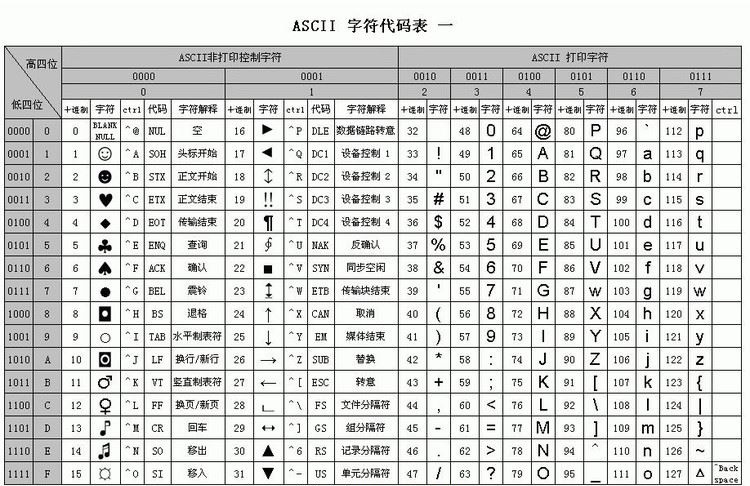
ASCII碼
用一個位元組儲存字元,但是隻用了7位,即27 = 128個字元
ASCII表上的數字0–31分配給了控制字元,用於控制像印表機等一些外圍裝置。
數字 32–126 分配給了能在鍵盤上找到的字元,當您檢視或列印文件時就會出現。
數字127代表 DELETE 命令。
擴充套件ASCII
擴充套件的ASCII字元滿足了對更多字元的需求。擴充套件的ASCII包含ASCII中已有的128個字元(數字0–32顯示在下圖中),又增加了128個字元,總共是256個。即使有了這些更多的字元,許多語言還是包含無法壓縮到256個字元中的符號。因此,出現了一些ASCII的變體來囊括地區性字元和符號。例如,許多軟體程式把ASCII表(又稱作ISO8859-1)用於北美、西歐、澳大利亞和非洲的語言。
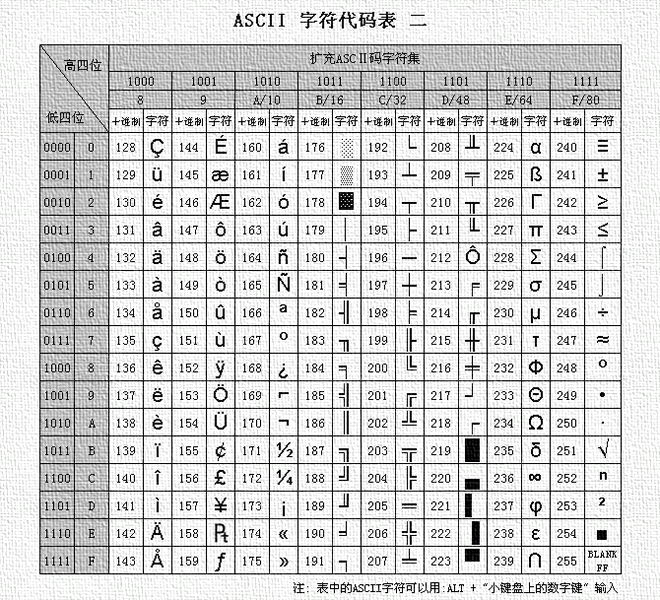
因為ASCII就一套,ASCII字符集也可以叫ASCII編碼
Unicode字符集及其以Unicode字符集的編碼
Unicode字符集下有多個編碼方案UTF-8、UTF-16、UTF-32.
1.Unicode並不涉及字元是怎麼在位元組中表示的,它僅僅指定了字元對應的數字
2.Unicode只是一個用來對映字元和數字的標準。它對支援字元的數量沒有限制,也不要求字元必須佔兩個、三個或者其它任意數量的位元組。
3.目前Unicode碼點的範圍是U+0000~U+10FFFF。U+10FFFF是多大呢?大概是111萬,按Unicode官方的說法,就這樣了,以後也不擴充了,一百多萬足夠用了,目前也只是定義了10萬多個字元左右
Unicode的範圍目前是U+0000~U+10FFFF,理論大小為10FFFF+1=11000016。後一個1代表是65536,因為是16進位制,所以前一個1是後一個1的16倍,所以總共有1×16+1=17個的65536的大小,粗略估算為17×6萬=102萬,所以這是一個百萬級別的數。
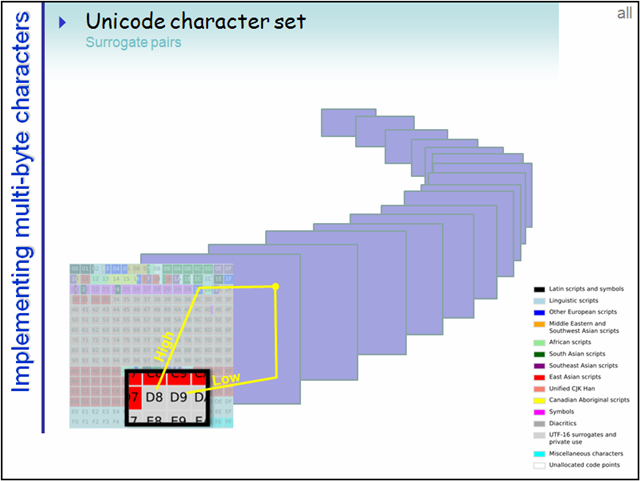
為了更好分類管理如此龐大的碼點數,把每65536個碼點作為一個平面,總共17個平面。
平面,BMP,SP
碼點的全部範圍可以均分成17個65536大小的部分,這裡面的每一個部分就是一個平面(Plane)。編號從0開始,第一個平面稱為Plane 0.
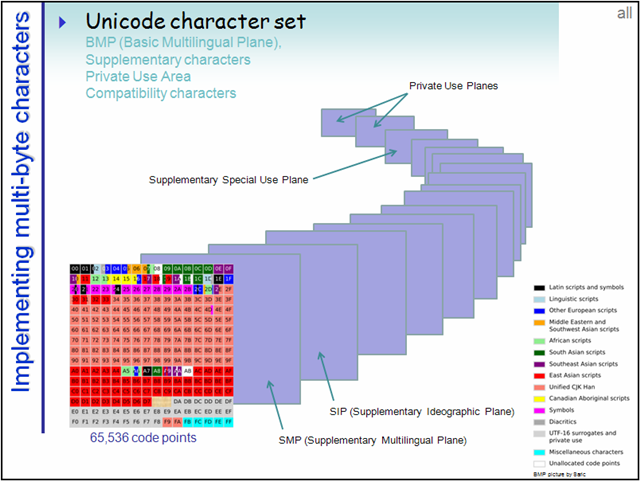
第一個平面即是BMP(Basic Multilingual Plane 基本多語言平面),也叫Plane 0,它的碼點範圍是U+0000~U+FFFF。這也是我們最常用的平面,日常用到的字元絕大多數都落在這個平面內。
UTF-16只需要用兩位元組編碼此平面內的字元。
後續的16個平面稱為SP(Supplementary Planes,增補平面)。顯然,這些碼點已經是超過U+FFFF的了,所以已經超過了16位空間的理論上限,對於這些平面內的字元,UTF-16採用了四位元組編碼。
其中很多平面還是空的,還沒有分配任何字元,只是先規劃了這麼多。
另:有些還屬於私有的,如上圖中的最後兩個Private Use Planes,在此可自定義字元。
正則表示式[\u4E00-\u9FA5]來匹配中文位置,嚴格來說這只是Unicode最主要的一段中文區域。
有的中文也落在了增補平面內。
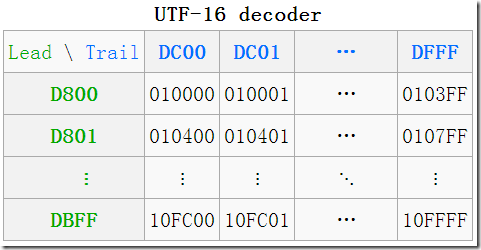
代理區

BMP縮圖中有一片空白,這就是所謂的代理區(Surrogate Area)
可以看到這段空白從D8~DF。其中D800–DBFF屬於高代理區(High Surrogate Area),後面的DC00–DFFF屬於低代理區(Low Surrogate Area),各自的大小均為4×256=1024。
還可以看到在它之前是韓文的區域,之後E0開始到F8的則是屬於私有的(private),可以在這裡定義自己專用的字元。
至此我們對Unicode的碼點,平面都有了一定的瞭解,但我們還沒有觸及一個重要的方面,那就是碼點到最終編碼的轉換,在Unicode中,這稱為UTF。
UTF-32
我們說碼點最大的10FFFF也就21位,而UTF-32採用的定長四位元組則是32位,所以它表示所有的碼點不但毫無壓力,反而綽綽有餘,所以只要把碼點的表示形式以前補0的形式補夠32位即可。這種表示的最大缺點是佔用空間太大。
再來看稍複雜一點的UTF-8。
UTF-8
UTF-8是變長的編碼方案,可以有1,2,3,4四種位元組組合。在前面的定長與變長篇章我們提到UTF-8採用了高位保留方式來區別不同變長,如下:
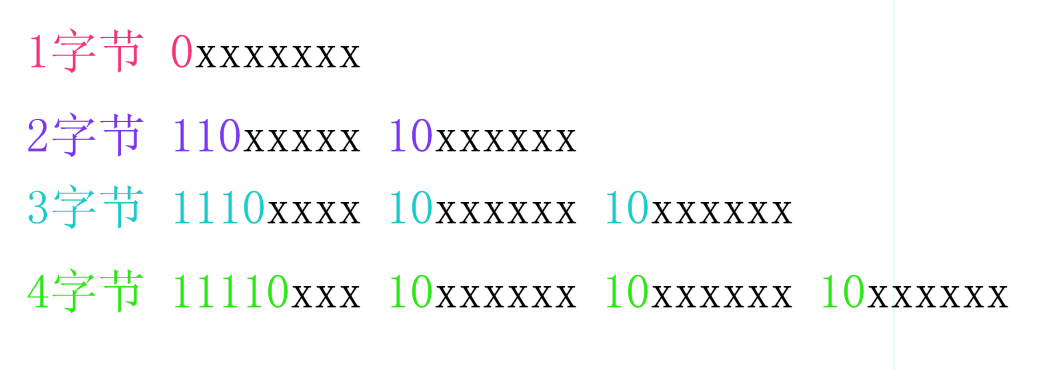
碼點與位元組如何對應?
哪些碼點用哪種變長呢?可以先把碼點變成二進位制,看它有多少有效位(去掉前導0)就可以確定了。
- 一位元組有效編碼位有7位,27=128,碼點U+0000~U+007F(0~127)使用一位元組。
一位元組留給了ASCII,所以UTF-8相容ASCII。
- 二位元組有效編碼位只有5+6=11位,最多隻有211=2048個編碼空間,所以數量眾多的漢字是無法容身於此的了。碼點U+0080~U+07FF(128~2047)使用二位元組。
注意:這裡碼點從128~2047,因為去掉了一位元組的碼點,所以不會佔滿2048個編碼空間,是有冗餘的,但你不能把適用於一位元組的碼點放到這裡來編碼。下同。
- 三位元組模式可看到光是保留位就達到4+2+2=8位,相當一位元組,所以只剩下兩位元組16位有效編碼位,它的容量實際也只有65536。碼點U+0800~U+FFFF(2048~65535)使用三位元組編碼。
一些漢字字典收錄的漢字達到了驚人的10萬級別。基本上,常用的漢字都落在了這三位元組的空間裡,這就是我們常說的漢字在UTF-8裡用三位元組表示。當然了,這麼說並不嚴謹,如果這10萬的漢字都被收錄進來的話,那些偏門的漢字自然只能被擠到四位元組空間上去了。
- 四位元組的可以看到它的有效位是3+6+6+6=21位,前面說到最大的碼點10FFFF也是21位,U+FFFF以上的增補平面的字元都在這裡來表示。
UTF-16
UTF-16是一種變長的2或4位元組編碼模式。對於BMP內的字元使用2位元組編碼,其它的則使用4位元組組成所謂的代理對來編碼。
代理區是UTF-16為了編碼增補平面中的字元而保留的,總共有2048個位置,均分為高代理區(D800–DBFF)和低代理區(DC00–DFFF)兩部分,各1024,這兩個區組成一個二維的表格,共有1024×1024=210×210=24×216=16×65536,所以它恰好可以表示增補的16個平面中的所有字元。
下面的圖片來自wiki
下圖來自http://rishida.net/docs/unicode-tutorial/part2
FilterOutputStream與FilterInputStream
這兩個都分別是InputStream和OutputStream的子類。也是DataInputStream與DataOutputStream的父類,而且,FilterInputStream和FilterOutputStream是具體的子類,實現了InputStream和OutputStream這兩個抽象類中為給出實現的方法。
但是,FilterInputStream和FilterOutputStream僅僅是“裝飾者模式”封裝的開始,它們在各個方法中的實現都是最基本的實現,都是基於構造方法中傳入引數封裝的InputStream和OutputStream的原始物件。
比如,在FilterInputStream類中,封裝了這樣一個屬性
protected volatile InputStream in;
而對應的構造方法是:
protected FilterInputStream(InputStream in) {
this.in = in;
}
read()方法的實現則為:
public int read() throws IOException {
return in.read();
}
其它方法的實現,以及FilterOutputStream也都是同理類似的。
我們注意到FilterInputStream和FilterOutputStream並沒給出其它額外的功能實現,只是做了一層簡單地封裝。那麼實現額外功能的實際是FilterInputStream和FilterOutputStream的各個子類。
DataInputStream與DataOutputStream
這也是比較重要的一對Filter實現。那麼說起功能,實際上就不得不提到他們除了extends FilterInputStream/FilterOutputStream外,還額外實現了DataInput和DataOutput介面。
我們可以先來看下DataInput和DataOutput這兩個interface。
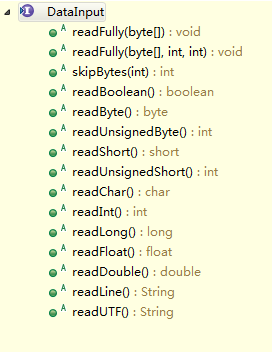

而DataInputStream/DataOutputStream這一對實際上所做的也就是這兩個介面所定義的方法。再DataInputStream/DataOutputStream中,這些方法做了拼接和拆分位元組的工作。通過這些方法,我們可以方便的讀取、寫出各種我們實際所面對的型別的資料,而不必具體去在位元組層面上做細節操作。
public class DataInputStream extends FilterInputStream implements DataInput
public
class DataInputStream extends FilterInputStream implements DataInput {
//in:資料來源
public DataInputStream(InputStream in) {
super(in);
}
//位元組陣列,80位元組,當我們readUTF時,先不解碼,直接把資料存進bytearr裡,若果超過80,重新new一個更大的
private byte bytearr[] = new byte[80];
//上面的是原始資料位元組,chararr是經過解碼後的資料,若果超過80,重新new一個更大的
private char chararr[] = new char[80];
//把資料讀進b[]數組裡,迴圈讀取,一個一個位元組的讀
public final int read(byte b[]) throws IOException {
return in.read(b, 0, b.length);
}
//把資料從b[]陣列的off位置讀進len個長度的位元組,迴圈讀取,一個一個位元組的讀
public final int read(byte b[], int off, int len) throws IOException {
return in.read(b, off, len);
}
//一次讀取最多b.length個位元組到b[]數組裡
public final void readFully(byte b[]) throws IOException {
readFully(b, 0, b.length);
}
//一次讀取最多len個位元組到b[]數組裡,偏移值off
//該方法與read(byte b[], int off, int len)簽名很像,但是read是一個一位元組(可能會出現迴圈)的讀,readFully是整個資料塊讀
public final void readFully(byte b[], int off, int len) throws IOException {
if (len < 0)
throw new IndexOutOfBoundsException();
int n = 0;
while (n < len) {
int count = in.read(b, off + n, len - n);
if (count < 0)
throw new EOFException();
n += count;
}
}
//跳過多少位元組,返回值是實際跳過多少位元組取值範圍[0,n]
public final int skipBytes(int n) throws IOException {
int total = 0;
int cur = 0;
//
while ((total<n) && ((cur = (int) in.skip(n-total)) > 0)) {
total += cur;
}
return total;
}
//讀取一個boolean值,佔據一個位元組
public final boolean readBoolean() throws IOException {
int ch = in.read();
if (ch < 0)
throw new EOFException();
return (ch != 0);
}
//讀取一個位元組
public final byte readByte() throws IOException {
int ch = in.read();
if (ch < 0)
throw new EOFException();
return (byte)(ch);
}
//讀取一個無符號的位元組
public final int readUnsignedByte() throws IOException {
int ch = in.read();
if (ch < 0)
throw new EOFException();
return ch;
}
//讀取一個short型 2個位元組,分2步讀取一個位元組,然後把這2個位元組合併,強轉short
public final short readShort() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
if ((ch1 | ch2) < 0)
throw new EOFException();
return (short)((ch1 << 8) + (ch2 << 0));
}
//讀取一個無符號short型 2個位元組,分2步讀取一個位元組,然後把這2個位元組合併
public final int readUnsignedShort() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
if ((ch1 | ch2) < 0)
throw new EOFException();
return (ch1 << 8) + (ch2 << 0);
}
//讀取一個char ,2個位元組,然後把這2個位元組合併,強轉char
public final char readChar() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
if ((ch1 | ch2) < 0)
throw new EOFException();
return (char)((ch1 << 8) + (ch2 << 0));
}
//讀取一個int ,4位元組,然後把這4個位元組合併
public final int readInt() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
int ch3 = in.read();
int ch4 = in.read();
if ((ch1 | ch2 | ch3 | ch4) < 0)
throw new EOFException();
return ((ch1 << 24) + (ch2 << 16) + (ch3 << 8) + (ch4 << 0));
}
//readLong(),readDouble() 時的緩衝區
private byte readBuffer[] = new byte[8];
//一次性讀取一個long型值 ,8位元組,然後把這8個位元組合併
public final long readLong() throws IOException {
readFully(readBuffer, 0, 8);
return (((long)readBuffer[0] << 56) +
((long)(readBuffer[1] & 255) << 48) +
((long)(readBuffer[2] & 255) << 40) +
((long)(readBuffer[3] & 255) << 32) +
((long)(readBuffer[4] & 255) << 24) +
((readBuffer[5] & 255) << 16) +
((readBuffer[6] & 255) << 8) +
((readBuffer[7] & 255) << 0));
}
//讀取一個float型的值,4位元組
public final float readFloat() throws IOException {
return Float.intBitsToFloat(readInt());
}
//讀取一個double型的值,8位元組
public final double readDouble() throws IOException {
return Double.longBitsToDouble(readLong());
}
private char lineBuffer[];
@Deprecated
public final String readLine() throws IOException {
char buf[] = lineBuffer;
if (buf == null) {
buf = lineBuffer = new char[128];
}
int room = buf.length;
int offset = 0;
int c;
loop: while (true) {
switch (c = in.read()) {
case -1:
case '\n':
break loop;
case '\r':
int c2 = in.read();
if ((c2 != '\n') && (c2 != -1)) {
if (!(in instanceof PushbackInputStream)) {
this.in = new PushbackInputStream(in);
}
((PushbackInputStream)in).unread(c2);
}
break loop;
default:
if (--room < 0) {
buf = new char[offset + 128];
room = buf.length - offset - 1;
System.arraycopy(lineBuffer, 0, buf, 0, offset);
lineBuffer = buf;
}
buf[offset++] = (char) c;
break;
}
}
if ((c == -1) && (offset == 0)) {
return null;
}
return String.copyValueOf(buf, 0, offset);
}
public final String readUTF() throws IOException {
return readUTF(this);
}
public final static String readUTF(DataInput in) throws IOException {
//先讀取2位元組的utf的長度資訊 2^16-1 = 65535
//因為writeUTF的時候長度不許>=64K(即65535個位元組)
int utflen = in.readUnsignedShort();
byte[] bytearr = null;
char[] chararr = null;
// 如果in本身是“資料輸入流”,
// 則,設定位元組陣列bytearr = "資料輸入流"的成員bytearr
// 設定字元陣列chararr = "資料輸入流"的成員chararr
// 否則的話,新建陣列bytearr和chararr
if (in instanceof DataInputStream) {
DataInputStream dis = (DataInputStream)in;
if (dis.bytearr.length < utflen){
dis.bytearr = new byte[utflen*2];
dis.chararr = new char[utflen*2];
}
chararr = dis.chararr;
bytearr = dis.bytearr;
} else {
bytearr = new byte[utflen];
chararr = new char[utflen];
}
//單位元組、雙位元組、三位元組
int c, char2, char3;
int count = 0;
int chararr_count=0;
// 從“資料輸入流”中讀取資料並存儲到位元組陣列bytearr中;從bytearr的位置0開始儲存,儲存長度為utflen。
// 注意,這裡是儲存到位元組陣列!而且讀取的是全部的資料。
in.readFully(bytearr, 0, utflen);
//如果是ascii碼就直接存在bytearr裡面了,畢竟老外寫的原始碼,都是用ascii碼機率比較高,就省去下面for中的判斷了
// 將“位元組陣列bytearr”中的資料 拷貝到 “字元陣列chararr”中
// 注意:這裡相當於“預處理的輸入流中單位元組的符號”,因為UTF-8是1-4個位元組可變的。
while (count < utflen) {
c = (int) bytearr[count] & 0xff;
// UTF-8的單位元組資料的值都不會超過127;所以,超過127,則退出。
if (c > 127) break;
count++;
chararr[chararr_count++]=(char)c;
}
// 處理完輸入流中單位元組的符號之後,接下來我們繼續處理。
while (count < utflen) {
// 下面語句執行了2步操作。
// (01) 將位元組由 “byte型別” 轉換成 “int型別”。
// 例如, “11001010” 轉換成int之後,是 “00000000 00000000 00000000 11001010”
// (02) 將 “int型別” 的資料左移4位
// 例如, “00000000 00000000 00000000 11001010” 左移4位之後,變成 “00000000 00000000 00000000 00001100”
c = (int) bytearr[count] & 0xff;
switch (c >> 4) {
case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
/* 0xxxxxxx*/
// 若 UTF-8 是單位元組,即 bytearr[count] 對應是 “0xxxxxxx” 形式;
// 則 bytearr[count] 對應的int型別的c的取值範圍是 0-7。
count++;
chararr[chararr_count++]=(char)c;
break;
// 若 UTF-8 是雙位元組,即 bytearr[count] 對應是 “110xxxxx 10xxxxxx” 形式中的第一個,即“110xxxxx”
// 則 bytearr[count] 對應的int型別的c的取值範圍是 12-13。
case 12: case 13:
/* 110x xxxx 10xx xxxx*/
count += 2;
if (count > utflen)
throw new UTFDataFormatException(
"malformed input: partial character at end");
char2 = (int) bytearr[count-1];
if ((char2 & 0xC0) != 0x80)
throw new UTFDataFormatException(
"malformed input around byte " + count);
chararr[chararr_count++]=(char)(((c & 0x1F) << 6) |
(char2 & 0x3F));
break;
// 若 UTF-8 是三位元組,即 bytearr[count] 對應是 “1110xxxx 10xxxxxx 10xxxxxx” 形式中的第一個,即“1110xxxx”
// 則 bytearr[count] 對應的int型別的c的取值是14 。
case 14:
/* 1110 xxxx 10xx xxxx 10xx xxxx */
count += 3;
if (count > utflen)
throw new UTFDataFormatException(
"malformed input: partial character at end");
char2 = (int) bytearr[count-2];
char3 = (int) bytearr[count-1];
if (((char2 & 0xC0) != 0x80) || ((char3 & 0xC0) != 0x80))
throw new UTFDataFormatException(
"malformed input around byte " + (count-1));
chararr[chararr_count++]=(char)(((c & 0x0F) << 12) |
((char2 & 0x3F) << 6) |
((char3 & 0x3F) << 0));
break;
// 若 UTF-8 是四位元組,即 bytearr[count] 對應是 “11110xxx 10xxxxxx 10xxxxxx 10xxxxxx” 形式中的第一個,即“11110xxx”
// 則 bytearr[count] 對應的int型別的c的取值是15
default:
/* 10xx xxxx, 1111 xxxx */
throw new UTFDataFormatException(
"malformed input around byte " + count);
}
}
// The number of chars produced may be less than utflen
return new String(chararr, 0, chararr_count);
}
}
public class DataOutputStream extends FilterOutputStream implements DataInput
public
class DataOutputStream extends FilterOutputStream implements DataOutput {
/**
* The number of bytes written to the data output stream so far.
* If this counter overflows, it will be wrapped to Integer.MAX_VALUE.
*/
protected int written;
/**
* bytearr is initialized on demand by writeUTF
*/
private byte[] bytearr = null;
public DataOutputStream(OutputStream out) {
super(out);
}
private void incCount(int value) {
int temp = written + value;
if (temp < 0) {
temp = Integer.MAX_VALUE;
}
written = temp;
}
public synchronized void write(int b) throws IOException {
out.write(b);
incCount(1);
}
public synchronized void write(byte b[], int off, int len)
throws IOException
{
out.write(b, off, len);
incCount(len);
}
public void flush() throws IOException {
out.flush();
}
public final void writeBoolean(boolean v) throws IOException {
out.write(v ? 1 : 0);
incCount(1);
}
public final void writeByte(int v) throws IOException {
out.write(v);
incCount(1);
}
public final void writeShort(int v) throws IOException {
out.write((v >>> 8) & 0xFF);
out.write((v >>> 0) & 0xFF);
incCount(2);
}
public final void writeChar(int v) throws IOException {
out.write((v >>> 8) & 0xFF);
out.write((v >>> 0) & 0xFF);
incCount(2);
}
public final void writeInt(int v) throws IOException {
out.write((v >>> 24) & 0xFF);
out.write((v >>> 16) & 0xFF);
out.write((v >>> 8) & 0xFF);
out.write((v >>> 0) & 0xFF);
incCount(4);
}
private byte writeBuffer[] = new byte[8];
public final void writeLong(long v) throws IOException {
writeBuffer[0] = (byte)(v >>> 56);
writeBuffer[1] = (byte)(v >>> 48);
writeBuffer[2] = (byte)(v >>> 40);
writeBuffer[3] = (byte)(v >>> 32);
writeBuffer[4] = (byte)(v >>> 24);
writeBuffer[5] = (byte)(v >>> 16);
writeBuffer[6] = (byte)(v >>> 8);
writeBuffer[7] = (byte)(v >>> 0);
out.write(writeBuffer, 0, 8);
incCount(8);
}
public final void writeFloat(float v) throws IOException {
writeInt(Float.floatToIntBits(v));
}
public final void writeDouble(double v) throws IOException {
writeLong(Double.doubleToLongBits(v));
}
public final void writeBytes(String s) throws IOException {
int len = s.length();
for (int i = 0 ; i < len ; i++) {
out.write((byte)s.charAt(i));
}
incCount(len);
}
public final void writeChars(String s) throws IOException {
int len = s.length();
for (int i = 0 ; i < len ; i++) {
int v = s.charAt(i);
out.write((v >>> 8) & 0xFF);
out.write((v >>> 0) & 0xFF);
}
incCount(len * 2);
}
public final void writeUTF(String str) throws IOException {
writeUTF(str, this);
}
static int writeUTF(String str, DataOutput out) throws IOException {
int strlen = str.length();
int utflen = 0;
int c, count = 0;
/* use charAt instead of copying String to char array */
for (int i = 0; i < strlen; i++) {
c = str.charAt(i);
if ((c >= 0x0001) && (c <= 0x007F)) {
utflen++;
} else if (c > 0x07FF) {
utflen += 3;
} else {
utflen += 2;
}
}
if (utflen > 65535)
throw new UTFDataFormatException(
"encoded string too long: " + utflen + " bytes");
byte[] bytearr = null;
if (out instanceof DataOutputStream) {
DataOutputStream dos = (DataOutputStream)out;
if(dos.bytearr == null || (dos.bytearr.length < (utflen+2)))
dos.bytearr = new byte[(utflen*2) + 2];
bytearr = dos.bytearr;
} else {
bytearr = new byte[utflen+2];
}
bytearr[count++] = (byte) ((utflen >>> 8) & 0xFF);
bytearr[count++] = (byte) ((utflen >>> 0) & 0xFF);
int i=0;
for (i=0; i<strlen; i++) {
c = str.charAt(i);
if (!((c >= 0x0001) && (c <= 0x007F))) break;
bytearr[count++] = (byte) c;
}
for (;i < strlen; i++){
c = str.charAt(i);
if ((c >= 0x0001) && (c <= 0x007F)) {
bytearr[count++] = (byte) c;
} else if (c > 0x07FF) {
bytearr[count++] = (byte) (0xE0 | ((c >> 12) & 0x0F));
bytearr[count++] = (byte) (0x80 | ((c >> 6) & 0x3F));
bytearr[count++] = (byte) (0x80 | ((c >> 0) & 0x3F));
} else {
bytearr[count++] = (byte) (0xC0 | ((c >> 6) & 0x1F));
bytearr[count++] = (byte) (0x80 | ((c >> 0) & 0x3F));
}
}
out.write(bytearr, 0, utflen+2);
return utflen + 2;
}
public final int size() {
return written;
}
}
相關推薦
Java IO系列3 位元組流之DataInputStream與DataOutputStream
編碼與字符集 什麼把這個專題放在這,因為DataInputStream與DataOutputStream裡有個 readUTF()或writeUTF(String str)方法。 由於這方面的內容我看的資料還有限,難免出錯,看到下面的內容後自己去找資
Java IO系列4 位元組流之PushbackInputStream
PushbackInputStream 原理是在內部儲存一個位元組緩衝區,如果unRead一個位元組,就會向這個緩衝區倒著寫入資料,下一次read的時候,就會把該緩衝區裡的位元組讀取出來。 當緩衝區裡沒資料時,跟別的位元組輸入流一樣 但是當有資料時
Java IO 筆記 3 --- 物件流
如果想整個的存入,讀取,自定義的物件,就用到了,操作物件的流 — ObjectOutputStream, ObjectInputStream,被操作的物件,要實現 Serializable(標記介面) 注:流裡面的一對,不是兩個,是輸入和輸出相對應
java io系列14:DataInputStream(資料輸入流)的認知、原始碼和示例
本章介紹DataInputStream。我們先對DataInputStream有個大致認識,然後再深入學習它的原始碼,最後通過示例加深對它的瞭解。 轉載請註明出處:http://www.cnblogs.com/skywang12345/p/io_14.html DataInputStream
Java IO 3-位元組流與字元流的區別
java以流的形式操縱IO,又將流分為兩種:位元組流與字元流,對JavaIO流操作不清楚的可以參考 那位元組流與字元流之間又有什麼區別呢 區別 位元組流用於操作檔案資料,網路傳輸等場景,而字元流適用於與字串,中文有關的內容處理,因為Writer/R
系統學習 Java IO (十二)----資料流和物件流 DataInputStream/DataOutputStream & ObjectInputStream/ObjectOutputStream
DataInputStream/DataOutputStream 允許應用程式以與機器無關方式從底層輸入流中讀取基本 Java 資料型別。 要想使用資料輸出流和輸入流,必須按指定的格式儲存資料,才可以將資料輸入流將資料讀取進來,所以通常使用 DataInputStream 來讀取 DataOutputStr
Java io流 之FileOutputStream與FileInputStream 詳解
FileOutputStream 檔案輸出流 方法程式碼詳解: public class Demo01 { public static void main(String[] a
Java IO系列之初始IO
什麼是IO流? IO指的是輸入/輸出(Input/Output),而流是一種抽象概念,這裡我們可以把流想像成是一條長河,在上游有一水庫提供水源,河邊住著一戶人,隨時都可以從河邊取到水,
IO相關3(string流)
nes for val 的人 有用 ugo oid 支持 struct sstream 頭文件定義了三個類型來支持內存 IO,這些類型可以向 string 寫入數據,從 string 讀取數據,就像 string 是一個 IO 流一樣。 istringstream 從 st
Java——IO類,轉換流簡化寫法
lose exception rip border 兩個類 xhtml 成員方法 tab 指示 body, table{font-family: 微軟雅黑} table{border-collapse:
系統學習 Java IO (十)----回退流 PushbackInputStream
目錄:系統學習 Java IO---- 目錄,概覽 PushbackInputStream 旨在從 InputStream 解析資料時使用。 有時您需要先讀取幾個位元組以檢視將要發生的事情,然後才能確定如何解釋當前位元組, PushbackInputStream 允許這樣做。 實際上,它允許將讀取的位元組推
系統學習 Java IO (十一)----列印流 PrintStream
目錄:系統學習 Java IO---- 目錄,概覽 PrintStream 類可以將格式化資料寫入底層 OutputStream 。 PrintStream 類可以格式化基本型別,如int,long等格式化為文字,而不是其位元組值。 這就是為什麼它被稱為 PrintStream ,因為它將原始位元組格式化為
nested exception is com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException: 3 位元組
maven切換資料庫連線配置時出現 nested exception is com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException: 3 位元組的 UTF-8 序列的位元組 3 無效。
com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException: 3 位元組的 UTF-8 序列的位元組 3 無效。
在tomcat啟動時報錯,核心錯誤 org.springframework.beans.factory.BeanDefinitionStoreException: IOException parsing XML document from URL [jar:file:
com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException: 3 位元組的 UTF-8 序列的位元組 x 無效
在啟動Tomcat專案時,控制檯報錯:nested exception is com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException: 3 位元組的 UTF-8 序列的位元組 2 無效。 該錯誤是由於一些配置檔案如:
Java IO詳解(六)------序列化與反序列化(物件流)
1、什麼是序列化與反序列化? 序列化:指把堆記憶體中的 Java 物件資料,通過某種方式把物件儲存到磁碟檔案中或者傳遞給其他網路節點(在網路上傳輸)。這個過程稱為序列化。通俗來說就是將資料結構或物件轉換成二進位制串的過程 反序列化:把磁碟檔案中
Java——I/O(位元組流、字元流與轉換流 )
位元組流和字元流 位元組流(byte):InputStream、OutputStream 字元流(char):Reader、Writer 位元組流與字元流的區別: 位元組流是原生的操作,而字元流是經過處理後的操作。 一般使用位元組流——無論是網路傳
Java併發系列 | AbstractQueuedSynchronizer原始碼分析之概要分析
學習Java併發程式設計不得不去了解一下java.util.concurrent這個包,這個包下面有許多我們經常用到的併發工具類,例如:ReentrantLock, CountDownLatch, CyclicBarrier, Semaphore等。而這些類的底層實現都依賴於AbstractQueu
Java I/O 使用位元組流/字元流進行檔案拷貝
例項 利用位元組流複製檔案 /** * 利用位元組流複製檔案 * @throws IOException */ @Test public void testByteCopy() throws IOException { InputStrea
JAVA io筆記10 列印流
package FileText; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.BufferedReader; import java.io.File; impor