
爬蟲學習筆記--爬B站評論
由於鬆愛協會的小夥伴邀請,我研究了一下爬取b站上協會的一些精彩評論
由於評論是動態的,所以要用到 selenium 之前的博文裡已經有關於selenium的安裝注意事項
還要用到Firefox的firebug 去獲取xpath資訊
target = app.find_element_by_xpath(".//*[@id='recommend_report']/div[1]/span")
app.execute_script("arguments[0].scrollIntoView();", target)#定位到特定的元素
time.sleep(3)這裡注意一下 由於有些資訊要 下拉滾動條才可以 獲取到 那麼這裡有一個下拉滾動條 定位到某一元素的方法
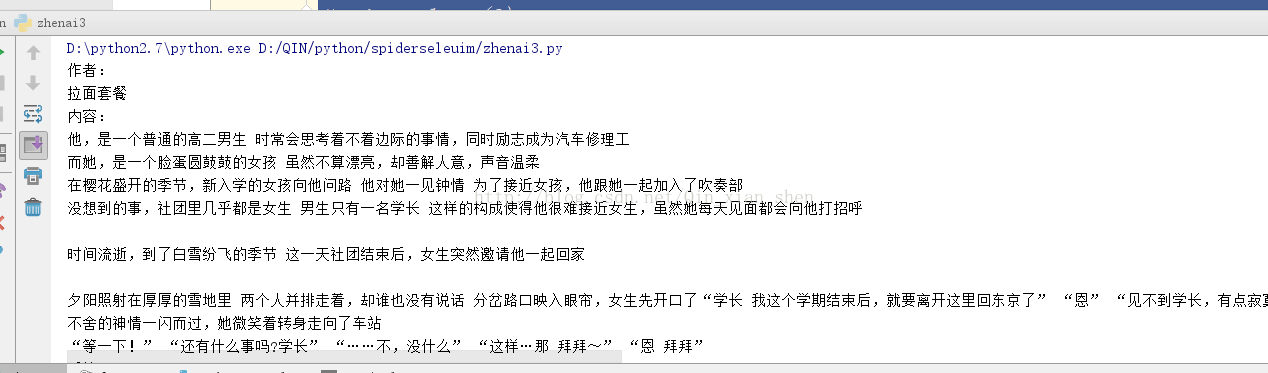
貼上程式碼
#coding=utf-8 from selenium import webdriver import sys import time from selenium.webdriver.common.keys import Keys reload(sys) sys.setdefaultencoding("utf-8") # fp = webdriver.PhantomJS() # fp.set_preference("permissions.default.stylesheet",2) # fp.set_preference("permissions.default.image",2) app = webdriver.Firefox() app.get("https://www.bilibili.com/video/av3553625/?from=search&seid=10292605247919873793") target = app.find_element_by_xpath(".//*[@id='recommend_report']/div[1]/span") app.execute_script("arguments[0].scrollIntoView();", target)#定位到特定的元素 time.sleep(3) target2 = app.find_element_by_xpath(".//*[@id='bbComment']/div[1]/div[4]/div[4]/span/a"); app.execute_script("arguments[0].scrollIntoView();", target2) time.sleep(3) target2.click() # js="var q=document.documentElement.scrollTop=100000" # app.execute_script(js) # time.sleep(3) for i in range(20): if(i==7): continue name = app.find_element_by_xpath(".//*[@id='bbComment']/div[1]/div[4]/div["+str(i+1)+"]/div[2]/div[1]/a[1]") test = app.find_element_by_xpath(".//*[@id='bbComment']/div[1]/div[4]/div["+str(i+1)+"]/div[2]/p") if (i != 13 and i != 17): pinglun1 = app.find_element_by_xpath(".//*[@id='bbComment']/div[1]/div[4]/div["+str(i+1)+"]/div[2]/div[3]/div[1]/div/div[1]/span") if (i != 13 and i != 17): pinglun2 = app.find_element_by_xpath(".//*[@id='bbComment']/div[1]/div[4]/div["+str(i+1)+"]/div[2]/div[3]/div[2]/div/div[1]/span") if(i !=12 and i !=13 and i != 17): pinglun3 = app.find_element_by_xpath(".//*[@id='bbComment']/div[1]/div[4]/div["+str(i+1)+"]/div[2]/div[3]/div[3]/div/div[1]/span") print ("作者:") print (name.text.strip()) print ("內容:") print test.text.strip() print ("後續:") if (i != 13 and i != 17): print pinglun1.text.strip() if (i != 13 and i != 17): print pinglun2.text.strip() if (i != 12 and i != 13 and i != 17): print pinglun3.text.strip() print ("\n") time.sleep(3) # # tests = app.find_elements_by_css_selector("p.text") # for i in range(len(tests)): # test = tests[i].text.strip() # print test app.quit()
這裡只抓取了一頁的評論 還可以再完善抓更多頁面
相關推薦
爬蟲學習筆記--爬B站評論
由於鬆愛協會的小夥伴邀請,我研究了一下爬取b站上協會的一些精彩評論 由於評論是動態的,所以要用到 selenium 之前的博文裡已經有關於selenium的安裝注意事項 還要用到Firefox的firebug 去獲取xpath資訊 target = app.fi
靜覓爬蟲學習筆記8-爬取貓眼電影
nal rip score item 之前 req exceptio pool html 不知道是不是我學習太晚的原因,貓眼電影這網站我用requests進行爬取源碼直接返回給我一個您的訪問被禁止。作為萌新的我登時就傻了,還好認真聽了之前的課,直接換selenium抓了
Python爬蟲學習筆記之模擬登陸並爬去GitHub
過程 eight res 開發者工具 @value clas 之前 自己 8.0 (1)環境準備: 請確保已經安裝了requests和lxml庫 (2)分析登陸過程: 首先要分析登陸的過程,需要探究後臺的登陸請求是怎樣發送的,登陸之後又有怎樣的
Python爬蟲學習筆記(七)——智高考數據爬取
pid items bubuko strong eai res har href name 介紹 智高考是一個高考誌願網站,也是基於Ajax的。高中的時候我在wyz大神的幫忙下,嘗試過爬取信息來為填誌願做準備。但是當時沒有系統學習過爬蟲,幾乎都是靠大神帶飛,因此今天再次嘗試
乾貨(附原始碼) | 爬取一萬條b站評論,分析9.7分的新番憑啥這麼火?
7月番《工作細胞》最終話在十一前放出。這部動漫在b站上評分高達9.7。除了口碑之外,熱度也居高不下,更值得關注的是連很多平時不關注動漫的小夥伴也加入了追番大軍。這次我們的目標是爬取b站上的所有短評進行分析,用資料說明為什麼這部動漫會如此受歡迎。 01 工作細胞 《工作細胞》
python爬蟲學習筆記三:圖片爬取
圖片爬取的程式碼 r.content 檔案的二進位制格式 Python引入了with語句來自動幫我們呼叫close()方法: open(path, ‘-模式-‘,encoding=’UTF-8’) w:以寫方式開啟, a:以追加模式開啟 (從 EOF 開始, 必要時建
Python資料爬蟲學習筆記(13)爬取微信文章資料
一、需求:在微信搜尋網站中,通過設定搜尋關鍵詞以及搜尋頁面數,爬取出所有符合條件的微信文章: 二、搜尋頁URL分析階段: 1、在搜尋框中輸入任意關鍵詞,在出現的搜尋結果頁面點選下一頁,將每一頁的URL複製下來進行觀察: 2、注意到頁碼由page=X決定,搜尋關鍵
Python資料爬蟲學習筆記(21)爬取京東商品JSON資訊並解析
一、需求:有一個通過抓包得到的京東商品的JSON連結,解析該JSON內容,並提取出特定id的商品價格p,json內容如下: jQuery923933([{"op":"7599.00","m":"9999.00","id":"J_5089253","p":"7099.00"}
【Python3 爬蟲學習筆記】動態渲染頁面爬取 2
動作鏈 在互動操作中,一些互動動作都是針對某個節點執行的。比如,對於輸入框,我們就呼叫它的輸入文字和清空文字方法;對於按鈕,就呼叫它的點選方法。其實,還有另外一些操作,它們沒有特定的執行物件,比如滑鼠拖曳、鍵盤按鍵等,這些動作用另一種方式來執行,那就是動作鏈。
【Python3 爬蟲學習筆記】動態渲染頁面爬取 4 —— 使用Selenium爬取淘寶商品
並不是所有頁面都可以通過分析Ajax來完成抓取。比如,淘寶,它的整個頁面資料確實也是通過Ajax獲取的,但是這些Ajax介面引數比較複雜,可能會包含加密祕鑰等,所以如果想自己構造Ajax引數,還是比較困難的。對於這種頁面,最方便快捷的抓取方法就是通過Seleni
b站評論爬取
lse max round temp reply ajax ons ksum {} var userData = {}; var startPage = 0; var endPage = 0; var startTime = ""; var endTime = ""; va
python爬蟲學習筆記分析Ajax爬取果殼網文章
有時在使用requests抓取頁面會遇到得到的結果與在瀏覽器 中看到的結果不一樣,在瀏覽器檢查元素中可以看到的正常的顯示的網頁資料,但是requests請求得到的結果卻沒有。這是因為requests請求得到的時原始的html文件,而瀏覽器中的介面確實經過JavaScript處理資料生成的結果
【Python3 爬蟲學習筆記】動態渲染頁面爬取 3 —— Selenium的使用 3
切換Frame 網頁中有一種節點叫作iframe,也就是子Frame,相當於頁面的子頁面,它的結構和外部頁面的結構完全一致。Selenium開啟頁面後,它預設是在父級Frame裡面操作,而此時如果頁面中海油子Frame,它是不能獲取到子Frame裡面的額節點的。
python爬蟲學習筆記(一)—— 爬取騰訊視訊影評
前段時間我忽然想起來,以前本科的時候總有一些公眾號,能夠為我們提供成績查詢、課表查詢等服務。我就一直好奇它是怎麼做到的,經過一番學習,原來是運用了爬蟲的原理,自動登陸教務系統爬取的成績等內容。我覺得挺好玩的,於是自己也琢磨了一段時間,今天呢,我為大家分享一個爬蟲
Python資料爬蟲學習筆記(11)爬取千圖網圖片資料
需求:在千圖網http://www.58pic.com中的某一板塊中,將一定頁數的高清圖片素材爬取到一個指定的資料夾中。 分析:以數碼電器板塊為例 1.檢視該板塊的每一頁的URL: 注意到第一頁是“0-1.html”,第二頁是“0-2.html”,由
【Python 3 爬蟲學習筆記】使用Python3 爬取貓眼《西虹市首富》
轉自微信公眾號《資料森麟》 直接上程式碼: # 呼叫相關包 import json import random import requests import time import pandas as pd import os from pyecharts im
爬蟲學習筆記--用selenium 爬資料到Mysql
# -*- coding:utf-8 -*- from selenium import webdriver from selenium.webdriver.common.keys import Keys import MySQLdb; import sys import t
神箭手爬蟲學習筆記(二)
暫存 自動 表達 eve doc 常用 學習 數據 .sh 一,可以使用神劍手已經做好的爬蟲市場直接跑,不需要自己定義爬取規則 二,爬蟲市場裏沒有的網站,需要自己去定義規則來爬數據。 三,爬取的數據可以先存放在神劍手,也可以放到七牛暫存。(提醒下,網站需要數據備份如果數量不
python3爬蟲學習筆記
apple 搜索 logs exce header 索引 port exception 不能 Robot.txt Robots協議(也稱為爬蟲協議、機器人協議等)的全稱是“網絡爬蟲排除標準”(Robots Exclusion Protocol),網站通過Robots協議告訴
Scrapy爬蟲學習筆記 - windows下搭建開發環境1
ima 搭建開發環境 環境 navicat win pyc arm bsp mysql 一、pycharm的安裝和簡單使用 二、mysql和navicat的安裝和使用 三、wi