
閱讀筆記:pg085 AXI4-Stream infrastructure
Introduction
- 前言:pg085-axi4stream-infrastructure.pdf 這篇文件,所介紹不僅僅是 AXI4-Stream Switch 一個IP核,而是分別對下圖所示的幾個IP核進行了說明,閱讀時需要區分。另外,在這些IP核中,資料傳輸的基本單位是傳輸(transfer),類似於資料包的概念,2個以上的 transfer 構成一個 transaction。
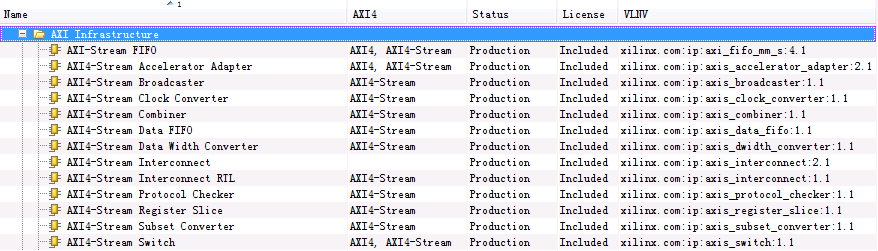
- AXI4-Stream Infrastucture IP 核們的主要功能是在 AXI4-Stream master/slave 系統 之間提供高速連線。這些IP核們的功能大概可以劃分三類:buffering,transform,routing。
- buffering 類的IP核有:
- AXI4-Stream Clock Converter:作用是連通兩個不同的時鐘域。
- AXI4-Stream Data FIFO:用來實現不同深度的BRAM/LUTRAM。
- AXI4-Stream Register Slice:Creates timing isolation and pipelining master and slave using a two-deep register buffer。
transform 類IP核有:
- AXI4-Stream Combiner:將位寬較窄的TDATA 資料流拼接成更寬的輸出。
- AXI4-Stream Data Width Converter:分兩種情況:①拓寬資料寬度:將數個TDATA 混合成更寬的流;②縮小資料寬度:將TDATA拆分為數個寬度較小的流。
- AXI4-Stream Subset Converter。
routing 類的IP核有:
- AXI4-Stream Broadcaster:將一個傳輸複製到多個輸出。
- AXI4-Stream Switch: 將多個master 和 slave 連線在一起,使用 TDEST 訊號將傳輸 路由到不同的輸出埠;或者利用可選的 control register 模式進行路由,這種模式需要AXI4-Lite介面進行控制。
- AXI4-Stream Interconnect:實際就是利用AXI4-Stream Switch 加上一些其他模組構成。
- 從上面可以看出,AXI4-Stream Switch 只是這個pg085 文件中的一個小分子。下面將著重總結AXI4-Stream Switch 相關的內容,對其他IP核的內容只是一筆帶過,或者一筆也沒有。
1. Overview
1.1 對 AXI4-Stream 介面協議的簡介
- AXI4-Stream 是一個開放標準介面協議,支援低資源消耗,高頻寬的單向資料傳輸。
- 對於AXI4-Stream 傳輸通路兩端而言,傳送方是master,接收方是slave。
1.2 AXI4-Stream Switch 的基本屬性
- 支援 1-16個slave,支援1-16個master;
- 支援三種仲裁依據:基於TLAST訊號;基於傳輸的數量(number of transfers);基於超時,即 對連續的 LOW TVALID計數,數量達到預設值則開始新的仲裁。
- 支援三種仲裁演算法:Round-Robin, True Round-Robin, 和 Fixed Priority arbitration 。
- 支援稀疏連線;
- 支援基於TDEST base/high 訊號對的路由,或者基於AXI4-Lite 介面控制的control register 路由。
2. Pruduct Specification
略過其他IP核的說明,直接總結第16頁的Switch的說明,主要是對兩種路由方式的說明。
- 兩種路由方式包括 TDEST routing 和 control register based routing。
2.1 AXI4-Stream Switch 的兩種路由方式
2.1.1 TDEST routing
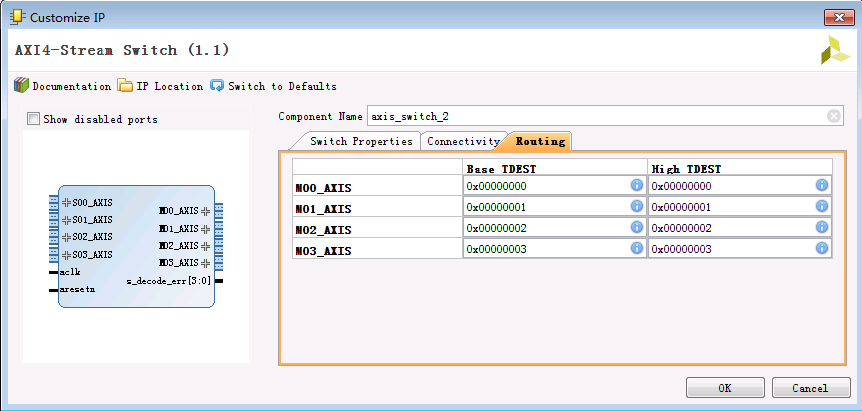
- 如上圖所示,在IP核定制階段,就要先配置各個master的TDEST base/high,從而得到一個解碼錶。在路由時,每個slave介面對輸入資料中TDEST訊號進行解碼,然後查詢解碼錶找到目的master 介面,之後向目標master 介面的仲裁器傳送一個請求。當仲裁器回覆一個“允許”後,slave 開始進行傳輸。
- Arbitration can be performed at the transfer level or at the transaction level. (A transaction is a series of two or more transfers.) ==> 仲裁可以在兩個層面上進行:可以對每個傳輸進行(transfer level),也可以對數個傳輸進行(transaction level)。如果是在transaction level,可以基於固定長度 或者 TLAST訊號 進行仲裁。還有一個可選的超時操作,就是:即使沒有達到固定長度限制 或者 沒收到TLAST 訊號,只要連線已經空閒太久了的話,也能終止這個transaction。這個措施在特定的系統拓撲上能夠避免死鎖。
- TDEST routing 要求TDEST 訊號線寬度至少是 log2( master介面數量 )。
注:此處原文是 log2(Number of Slave Interfaces)。文章中對於slave和master變化多端,因為對於AXI4-Stream匯流排而言,傳送者就是master,接收者就是slave。在switch內部,原來的相對於外部而言的slave介面是從外部接收資料,然後傳送給master介面,之後master介面傳送到外部。因為在內部,資料是從slave發給master,所以對於slave而言,master是它的slave,因此這裡公式中的slave,實際上是通常所說的master。文件中還有不少地方這樣倒騰slave和master。我們約定master和slave都是相對於外部而言的。
2.1.2 control register based routing
- control register routing 引入AXI4-Lite 介面來配置路由表。
- 每個master介面上有一個暫存器,用來控制選擇器。一旦這些暫存器們被程式改寫,會有一個提交暫存器(commit register)把這些暫存器們的值傳入switch。在這期間,AXI4-Stream 介面會保持在reset 狀態。
- 這個路由模式要求 master 和 slave 之間只有一條路徑。當企圖把同一slave 介面連線到多個master 時,只有編號最低的 master 能夠訪問這個slave。編號指的是每個介面的編號,比如slave 介面依次有 S01 S02 … S15,master 介面依次有 M01 M02 … M15。(前面的TDEST路由沒提到這個限制,或許允許多徑?)
- 未使用的master 介面可能會被置為disabled,任何未被連線到master的slave 介面都會被 disabled。
- 另外,對於兩種路由方式,支援 slave 和 master 之間的稀疏連線。當不需要或者要禁止某些連線時,在定製IP核階段可以點掉,從而節省開銷。如果使用的是control register based routing,則無效的路由會被停止;如果使用的是 TDEST 路由,則會丟棄傳輸。當傳輸被丟棄的時候,decode_err訊號 會被置為高。
2.2 Performance
2.2.1 最大頻率
- 在 Kintex®-7
FPGA (xc7k325tffg900-1.) 板子上,pg085文件中的各 AXI4-Stream IP核的最大頻率可以達到250 MHz。對於某些 -2 或者 -3 速度等級的元器件,最大頻率能夠提高 5% - 10%。但是對於 AXI4-Stream Switch,當配置超過大概 4 個master 或者 slave 時,支援的最大頻率會降低 20-25%。(所以,我們 8x8 的話,還能使用這個switch 嗎??)
2.2.2 時延
- 時延使用時鐘週期作計算單位。
- 時延的計算的始末:從slave 介面將 TVALID 訊號置高電平開始,到master 介面首次將 TVALID 訊號置為高電平。
- 延遲的計算基於 master 介面上的TREADY 訊號始終是高電平的假設。(這是因為只有TREADY 和TVALID 同時為高電平,傳輸才能開始)
- 如果要計算 背靠背 傳輸模式的時延,可以通過計算 當slave 介面接收到一個傳輸後,它的 TREADY 處於低電平的時鐘週期數。

- AXI4-Stream Switch 的時延如上圖所示。這是 TDEST 路由模式的時延,而 control register based routing 模式的時延在此未提及。由上圖可見,非背靠背傳輸的時延是 2 個時鐘週期,一個週期用來解碼TDEST訊號,另一個週期用來給仲裁器批准(前提是沒有衝突)。對於 背靠背 傳輸,對於一個已經被允許的transaction,其時延是0。背靠背傳輸的transactions 之間的仲裁會導致 1 個時鐘週期的時延。何哉?
2.3 Port Descriptions
- 具體可以查詢文件,此處僅僅介紹一些特殊訊號。
| 訊號 | 描述 |
|---|---|
| TSTRB | 修飾符,用來指示TDATA中的位元組們分別是data byte 還是 position byte |
| TID | data stream identifier,相當於stream ID,指示身份 |
| s_req_suppress | 置為高,則下個仲裁週期忽略這個匯流排。置為高時,這個bus不接收下一個仲裁;如果這個bus已經是被仲裁器允許的狀態了的話,它會保持被允許狀態直到仲裁週期結束 |
| s_decode_err | 表示剛接收到的傳輸中的TDEST值沒有匹配到任何一個master,然後丟棄這個傳輸;僅在TDEST模式中存在 |
- 另外,如果選擇 control register based routing 模式,會引入AXI4-Lite介面,介面訊號可查26頁表。
2.4 Register Space
- 當選擇control register based routing 模式時,switch 會有一張暫存器表,如下表2-8.
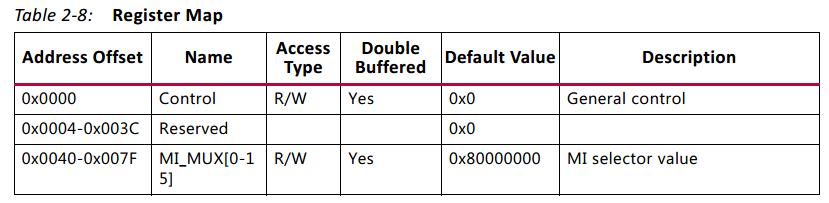
2.4.1 Control Register
- 上面表2-8中的第一行就是Control Register,共32位。這個暫存器的作用是 將master介面選擇器的值(也就是路由暫存器的值)提交給switch。該暫存器描述如下表2-9.

- 由上可知,該暫存器雖然是32位,實際有用的就 1 位。利用 REG_UPDATE 這一位指示更新,並促使 switch 轉入 reset 狀態並持續大概 16 個時鐘週期。(這是不是就是control register based routing 模式的時延??)
2.4.2 MI_MUX[0-15] Register
MI_MUX[0-15] 暫存器如表2-10所示。
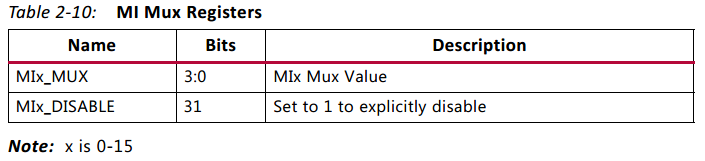
- 每個master 埠都有一個 MI_MUX 暫存器。每個 MIx_MUX 的值控制著 slave 介面的選擇。比如說,MI4_MUX 的值是 0x1 的話,意味以為著 slave 介面1 會被路由到 master 介面4。
- MIx_DISABLE 可以設為1,從而將該master 置為disabled。
- 每個slave 介面只能被選擇一次。如果有多於一個 MIx_MUX 的值被設定為選擇同一slave,那麼序號最低的master 獲得該slave 的控制權,其他master 們被置為disabled。
- 各個暫存器的地址偏移量是分配好的,MI0_MUX 的地址偏移是 0x40,MI1_MUX 的地址偏移是 0x44,…,MI15_MUX 的地址偏移是 0x7C.
2.4.3 control register based routing 模式使用示例
- 假設我們現在要配置一個 4x4 的 switch,slave介面 SI1 路由到 master 介面 MI0,MI1 未使用,SI3 路由到 MI2,SI0 路由到 MI3。則示例程式碼如下:

- 注意最底下 commit register 的時候,在地址偏移 0x0 處寫入 0x2。首先地址偏移 0x0,就是上面表2-8中第一行的control register,也就是表2-9中的暫存器。然後,寫入的數值是 2,從而第二位 REG_UPDATE 的值為1,觸發一次update,把更改過的 MI_MUX 的值傳入 switch,更新路由表。
3. Clock & Reset
3.1 Clock
- 沒什麼特別內容,摘錄兩句:
- An optional feature for clock enables (ACLKEN ports) allows an extra level of control for essentially gating clocks.
- The optional AXI4-Lite control register interface operates asynchronously from the AXI4-Stream clocks.
3.2 Reset
- reset 是有些講究的。reset 需要同步到 ACLK。為了確保在reset 期間不丟失資料,switch 會將所有的TREADY 和TVALID 輸出訊號都置為低電平,直到它們對應的源退出reset 狀態。對於外部的將TREADY 或者 TVALID 訊號輸入到switch 的終端們(比如MAC 核),也應該將這兩個訊號置為低電平,直到switch 內部退出 reset 狀態。
- 推薦:reset時,終端們將TREADY 和 TVALID 訊號置為低電平,應該保證在 8 個時鐘週期內。而ARESETn 訊號應該保持至少 16 個時鐘週期,從而確保系統內的其他介面們都能進入reset 狀態,並在reset 狀態結束前有時間去將它們的 TREADY 和 TVALID 輸出訊號置為低。
4.Design Flow Steps
4.1 AXI4-Stream Switch IP核的定製
- 各個基本訊號基本都在前面介紹過,下面主要介紹在選擇兩種路由方式(TDEST路由 和 control register based routing)時,所需要進行的不同配置。
4.1.1 Data Flow Properties
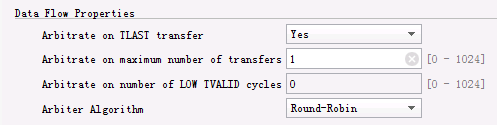
- 如上圖所示,當選擇TDEST路由方式時(也就是 Use control register routing 選項設為 NO),這時候才會出現Data Flow Properties 的選項們。
- Arbitrate on Maximum Number of Transfers:這個設定項表示仲裁器最多隔幾個傳輸就把前面的“允許”撤銷,進行新的仲裁。如果設為0,那麼傳輸數量就是無限的,這時候Arbitrate on TLAST transfer 選項必須設為 Yes;如果設為1,那麼每完成一次傳輸,switch 都會撤銷前面的仲裁結果,開始新的仲裁;如果設為大於 1 的值,比如設為 n,那麼每完成 n 次傳輸,就重新執行仲裁。
- Arbitrate on Number of LOW TVALID Cycles:這個選項允許在沒有傳輸的情況下重新執行仲裁。switch 持續對一個被仲裁器“允許”的從master 到slave 的連線進行監視,對它的連續的 LOW TVALID 訊號進行計數。如果計數值達到預設值,則重新執行仲裁。如果設為0,則不進行計數;如果有不止一個slave,不止一個master,而且Arbitrate on Maximum Number of Transfers 也設定為大於 1 的話,那麼這個選項就不能設為 0。這是為了確保不發生死鎖。
- Arbitrate on TLAST Transfer:如果設為 Yes,在switch 內部,會有一個從 slave 介面傳送到 master 介面的 TLAST 訊號,用來指示一個 transaction 的完成。然後仲裁器可以開始新一輪仲裁。這裡TLAST應該和 slave 介面以及 master 介面上顯示的 TLAST訊號區分開,那些TLAST 訊號是用來和外部裝置通訊的。
- 仲裁演算法:有三種,如下:
- True Round-Robin 演算法:對於所有出於活躍狀態的slave 介面賦予同等的權重;而且如果一個slave 介面緊跟著一個已經被允許的slave 介面的話,那麼新一輪仲裁中它擁有最高優先順序。這種演算法確保了每個活躍的slave 擁有同等的頻寬資源。
- Round-Robin演算法:類似與前者,不過新一輪的仲裁中每個slave 介面的優先順序一致,而不是緊跟著一個剛被允許的介面的優先順序最高。這種演算法的頻寬分配有可能不均勻。
- Fixed-Priority 固定優先順序演算法:slave介面 S00 擁有最高優先順序,S01次之,…,S15 擁有最低優先順序。這種演算法中,低優先順序的介面可能餓死。
- 為了區別以上三種演算法,舉個例子:比如對於一個有 4 個slave 介面,1 個master 介面的switch,其中 S00,S02 和 S03 在持續不斷地要求傳輸 large transactions。經過一番仲裁之後,最終,在True Round-Robin 演算法中,S00,S02 和 S03 都獲得了33% 的頻寬;而在Round-Robin演算法中,S00 和 S03 各獲得 25% 的頻寬,而 S02 獲得了 50% 的頻寬,這是因為 S02 繼承了 S01 的頻寬;而在Fixed-Priority 固定優先順序演算法 中,S00 獲得了100% 的頻寬,S02 和 S03 都餓死了。
- 另外,無論哪種演算法,如果Arbitrate on maximum number of transfers 選項設為 1 的話,仲裁器都是不支援來自同一slave 介面的背靠背傳輸的。這裡面有兩層意思:① 如果對於一個特定的master,只有一個slave 介面發來請求的話,則它們之間只能實現 50% 的頻寬,另外 50% 就浪費了; ② 如果加上上一段所描述的場景,使用 固定優先順序演算法 的話,那麼 S00 和 S02 會獲得 50% 的頻寬,S03 餓死。
4.1.2 Pipeline Registers
- 僅當Use control register routing設為 Yes 時,才有Pipeline Registers這些選項們。
- Enable Input Pipeline Register:When enabled, the slave interface side of the switch has register slices for each port at the IP boundary。
- Enable Output Pipeline Register:When enabled, the master interface side of the switch has register slices for each port at the IP boundary.
相關推薦
閱讀筆記:pg085 AXI4-Stream infrastructure
Introduction 前言:pg085-axi4stream-infrastructure.pdf 這篇文件,所介紹不僅僅是 AXI4-Stream Switch 一個IP核,而是分別對下圖所示的幾個IP核進行了說明,閱讀時需要區分。另外,在這些IP核中
mongodb官網文檔閱讀筆記:write concern
ava 節點數 edge 返回 post ase 執行c ans mman write concern保證了mongodb寫操作的級別,不同的write concern設置相應了不同級別的寫操作。設置的級別越高。那麽寫操作
閱讀筆記:ImageNet Classification with Deep Convolutional Neural Networks
時間 ica gpu ati 做了 alexnet 小數 而且 響應 概要: 本文中的Alexnet神經網絡在LSVRC-2010圖像分類比賽中得到了第一名和第五名,將120萬高分辨率的圖像分到1000不同的類別中,分類結果比以往的神經網絡的分類都要好。為了訓練更快,使用了
FreeRTOS程式碼閱讀筆記:heap_4.c
FreeRTOS中對於記憶體的管理當前一共有5種實現方式(作者當前的版本是10.1.1),均在【 \Source\portable\MemMang 】下面,這裡筆記下。 heap_4.c和第二種方式比較相似,只不過增加了一個和並演算法,將相鄰空閒記憶體合併為一個大記憶體,和方法一、
FreeRTOS程式碼閱讀筆記:heap_3.c
FreeRTOS中對於記憶體的管理當前一共有5種實現方式(作者當前的版本是10.1.1),均在【 \Source\portable\MemMang 】下面,這裡筆記下。 pvPortMalloc() 和 vPortFree() 的實現是基於 malloc()和 free
FreeRTOS程式碼閱讀筆記:heap_2.c
FreeRTOS中對於記憶體的管理當前一共有5種實現方式(作者當前的版本是10.1.1),均在【 \Source\portable\MemMang 】下面,這裡筆記下。 重要的引數: 使用方法: 標頭檔案:FreeRTOSConfig.h 配置引數: config
FreeRTOS程式碼閱讀筆記:heap_1.c
FreeRTOS中對於記憶體的管理當前一共有5種實現方式(作者當前的版本是10.1.1),均在【 \Source\portable\MemMang 】下面,這裡筆記下。 重要的引數: 使用方法: 標頭檔案:FreeRTOSConfig.h 配置引數: config
論文閱讀筆記:《Contextual String Embeddings for Sequence Labeling》
文章引起我關注的主要原因是在CoNLL03 NER的F1值超過BERT達到了93.09左右,名副其實的state-of-art。考慮到BERT訓練的資料量和引數量都極大,而該文方法只用一個GPU訓了一週,就達到了state-of-art效果,值得花時間看看。 一句話總結:使用BiLSTM模型,用動態embe
Linux核心完全註釋 閱讀筆記:3.3、C語言程式
By: Ailson Jack Date: 2018.09.14 本小節給出核心中經常用到的一些gcc擴充語句的說明。 1、C程式編譯和連結 使用gcc編譯器編譯C語言程式時,通常會經過4個處理階段,即預處理階段、編譯階段、彙編階段和連結階段
Linux核心完全註釋 閱讀筆記:3.4、C與彙編程式的相互呼叫
1、C函式呼叫機制 函式呼叫操作包括從一塊程式碼到另一塊程式碼之間的雙向資料傳遞和執行控制轉移。資料傳遞通過函式引數和返回值來進行。另外,我們還需要在進入函式時為函式的區域性變數分配儲存空間,並且在退出函式時收回這部分空間。Intel 80x86 CP
Linux核心完全註釋 閱讀筆記:3.5、Linux 0.11目標檔案格式
為了生成核心程式碼檔案,Linux 0.11使用了兩種編譯器。第一種是彙編編譯器as86和相應的連結程式(或稱為連結器)ld86。它們專門用於編譯和連結,執行在實地址模式下的16位核心引導扇區程式bootsect.s和設定程式setup.s。第二種是GNU的彙編器as
人臉識別網路mobilefacenet,的改進介紹 論文閱讀筆記:MobileFaceNets: Efficient CNNs for Accurate RealTime Face Verification on Mobile Devices
轉原 論文閱讀筆記:MobileFaceNets: Efficient CNNs for Accurate RealTime Face Verification on Mobile Devices
閱讀筆記:Inside NAND Flash Memory. Chapter 2.
2 NAND overview: from memory to systems 2.2 NAND memory 記憶體單元是以矩陣的形式排列的。在NAND string中,記憶體單元是32個或者64個一組序列連線的,兩個選擇電晶體放在string的兩個邊緣,以保
閱讀筆記:基礎知識(Java篇)
1. GC機制(垃圾回收機制) 找到垃圾的方法:引用計數法、可達性分析法 回收垃圾的方法:標記清除演算法、複製演算法、標記整理法、分代演算法 2. JVM記憶體劃分 執行緒私有:程式計數器、JVM虛擬機器棧、本地方法棧 執行緒公有:堆、方法區、執行時常量池 3. 會發生OOM的區域 堆:記憶體洩
《一個64位作業系統的設計與實現》閱讀筆記: 第一個作業系統的執行
廢話不多說,直接上boot.asm檔案程式碼 org 0x7c00 ;設定引導起始地址 BaseOfStack equ 0x7c00 ;設定常量BaseOfstack為0x7c00 Label_Start: mov ax, cs mov ds, ax mov es,
《一個64位作業系統的設計與實現》閱讀筆記:centos7下bochs安裝與環境搭建
折騰了兩天,才把這環境什麼的弄好,跟執行第一個系統。中途出現問題賊多,在這裡儘量回想總結。 具體步驟如下 環境:VMware下安裝的centos7.3 安裝bochs 0.輸入命令安裝以下幾個庫 sudo yum install gtk2 gtk2-devel
Tensorflow object detection API 原始碼閱讀筆記:RPN
Update: 建議先看從程式設計實現角度學習Faster R-CNN,比較直觀。這裡由於原始碼抽象程度較高,顯得比較混亂。 faster_rcnn_meta_arch.py中這兩個對應知乎文章中RPN包含的3*3和1*1卷積: rpn_box_pred
Tensorflow object detection API 原始碼閱讀筆記:架構
在之前的博文中介紹過用tf提供的預訓練模型進行inference,非常簡單。這裡我們深入原始碼,瞭解檢測API的程式碼架構,每個部分的深入閱讀留待後續。 '''構建自己模型的介面是虛基類DetectionModel,具體有5個抽象函式需要實現。 ''' o
Tensorflow object detection API 原始碼閱讀筆記:RFCN
有了前面Faster R-CNN的基礎,RFCN就比較容易了。 """object_detection/meta_architectures/rfcn_meta_arch.py The R-FCN
閱讀筆記:Time Series FeatuRe Extraction on basis of Scalable Hypothesis tests(Python package)
閱讀筆記:Time Series FeatuRe Extraction on basis of Scalable Hypothesis tests (tsfresh – A Python package) 摘要: 時間序列特徵工程是一個耗時的過程,因為科學家