
時間序列資料的處理
摘要: 隨著雲端計算和IoT的發展,時間序列資料的資料量急劇膨脹,高效的分析時間序列資料,使之產生業務價值成為一個熱門話題。阿里巴巴資料庫事業部的HiTSDB團隊為您分享時間序列資料的計算分析的一般方法以及優化手段。
演講嘉賓簡介:鍾宇(悠你) 阿里巴巴 資料庫高階專家,時間序列資料庫HiTSDB的研發負責人。在資料庫、作業系統、函數語言程式設計等方面有豐富的經驗。
本次分享主要分為以下幾個方面:
1. 時序資料庫的應用場景
2. 面向分析的時序資料儲存
3. 時序資料庫的時序計算
4. 時序資料庫的計算引擎
5. 時序資料庫展望
一,時序資料庫的應用場景
時序資料就是在時間上分佈的一系列數值。生活中常見的時序資料包括,股票價格、廣告資料、氣溫變化、網站的PV/UV、個人健康資料、工業感測器資料、伺服器系統監控資料(比如CPU和記憶體佔用率)、車聯網等。
下面介紹IoT領域中的時間序列資料案例。IoT給時序資料處理帶來了很大的挑戰。這是由於IoT領域帶來了海量的時間序列資料:
1. 成千上萬的裝置
2. 數以百萬計的感測器
3. 每秒產生百萬條資料
4. 24×7全年無休(區別於電商資料,電商資料存在高峰和低谷,因此可以利用低谷的時間段進行資料庫維護,資料備份等工作)
5. 多維度查詢/聚合
6. 最新資料實時可查
IoT中的時間序列資料處理主要包括以下四步:
1. 取樣
2. 傳輸
3. 儲存
4. 分析
二,面向分析的時序資料儲存
下面介紹時間序列資料的一個例子。這是一個新能源風力發電機的例子。每個風力發電機上有兩個感測器,一個是功率,一個是風速,並定時進行取樣。三個裝置,一共會產生六個時間序列。每個發電機都有多種標籤,這就會產生多個數據維度。比如,基於生產廠商這個維度,對功率做聚合。或基於風場,對風速做聚合等。現在的時序資料庫底層儲存一般用的是單值模型。因為多值模型也可以一對一的對映到單值模型,但這個過程可能會導致效能損失。但是,在對外提供服務時,單值模型和多值模型都有應用。比如,OpenTSDB就是用單值模型對外提供服務的,而influxDB則是多值模型。但這兩種資料庫的底層儲存用的都是單值模型。
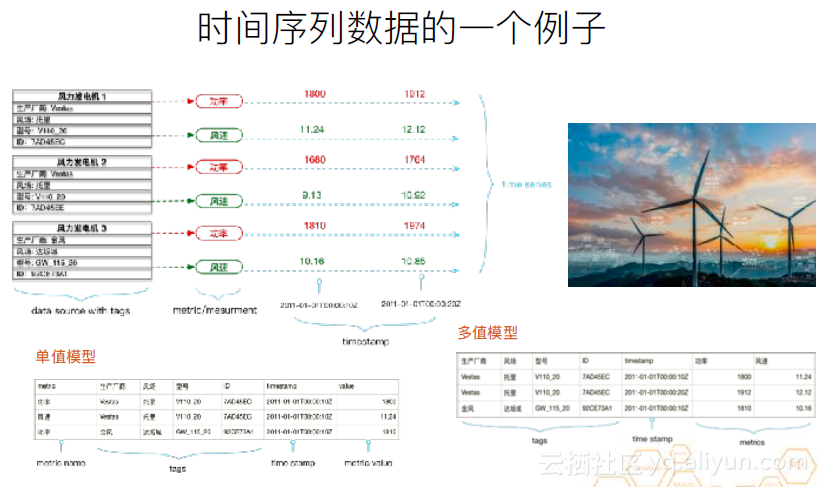
現實中的應用案例事實上會更復雜。像風力發電機這樣的案例,它的裝置和感測器的數量,我們可以認為是穩中有增的,不會發生特別劇烈的改變。它的資料取樣的週期也是嚴格的定期取樣。下圖是一個工業案例,以滴滴這樣的運營商為例。由於其業務特性,其車輛數量的增長和下降會出現暴漲暴跌。

總體而言,現實世界的複雜之處在於:
1. 未必是總是定時取樣。
2. 時間線可能是高度發散。以網際網路廣告為例,在對廣告進行取樣時,新廣告的增長和老廣告的下線速度很快,時間線就很有可能時高度發散的。
3. 主鍵和schema修改。前面例子中提到的Tag,可以對應資料庫的schema,在實際業務中可能會頻繁改動。現在一般的時序資料庫中,主鍵是會預設生成的,即所有tag的組合。因此,在新增tag時,主鍵就會改變,則變為了另一個物件。
4. 分散式系統和片鍵。由於資料量很大,因此需要對資料進行分片,片鍵的選擇也是一個難以抉擇的問題。
5. 資料型別。以剛才提到的單值模型為例。假設有一個三維的加速度感測器,同一時間點上會產生三個關聯的資料,這時的資料型別就應該是一個維度為3的向量,即一個新的資料型別。
6. 需要對每個資料點的值做過濾。假設每輛車上都裝有GPS感測器,假設要統計某一時間段內,一公里內,出現了哪些車輛,分別由哪些廠商生產。此時需要對地理位置進行過濾。
下圖是過去提出利用HiTSDB對時序問題的解決方案。在這種方案中,未解決發散問題,較高維資料和值過濾問題。用倒排索引來儲存裝置資訊,並把時間點上的資料存在高壓縮比快取中。這兩者結合,實際上將邏輯上的一個表分成了兩個表,用以解決多維度查詢和聚合的問題。但使用這種方案依然有很多問題無法解決。

下面是HiTSDB的一些優勢和不足:
1. 優勢:
倒排索引可以很方便的篩選裝置;
高壓縮比快取具有很高的寫入和讀取能力
方便的時間切片
無schema,靈活方便支援各種資料模型
2. 不足:
在非定時取樣場景下可能導致資料稀疏
值沒有索引,因此值過濾只能線性過濾
Schema改動導致時間線變動
廣播查限制了QPS
在此基礎上,進行了演進,如下圖。
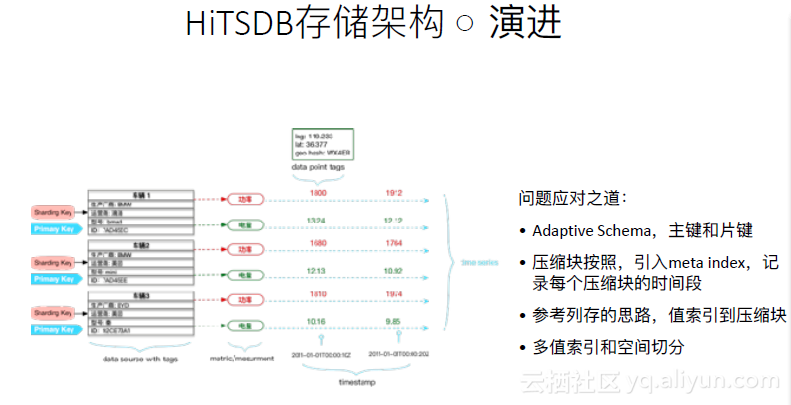
1. 引入了Adaptive schema,即如果未指定一個數據表的schema,則認為寫入的第一條資料中包含的TagKV即是片鍵也是主鍵,用以確定唯一性以及資料會被分片到哪一個節點上。
2. 壓縮塊也不再是按固定的時間切片了,引入了meta index,用以查詢每個資料塊的開始和結束時間。在一個時間段內攢夠了足夠的資料後,把整個資料塊進行壓縮。
3. 參考列存的思路,值索引到壓縮塊。值索引不再像傳統資料庫那樣索引到行。
4. 多值索引和空間切分。
三,時序資料庫的時序演算法
上面所述的儲存結構主要是為了方便進行時序資料的加工和分析。時序有一些特殊演算法。
1. 降取樣和插值:感測器取樣出的點可能特別密集,在分析趨勢時,會希望進行過濾。通過降取樣可以利用一段時間內的最小值/最大值/平均值來替代。
降取樣演算法:min/max/avg。
插值演算法:補零/線性/貝塞爾曲線
2. 聚合計算:由於取樣是精確到每個感測器的,但有時需要的資料並不僅是精確到某個感測器的。比如,希望比較兩個不同廠商的發電機,哪個在風場中產生了更多的電。那麼就需要對感測器資料進行聚合。
邏輯聚合:min/max
算術聚合:sum/count/avg
統計:histogram/percentile/Standard Deviation
3. 時間軸計算
變化率:rate
對時序資料進行加工的分析的重要目的是發現異常。下面介紹在異常檢測中如何定義問題。從異常檢測的角度來看時間序列資料,分為三個維度:time, object, metric。
1. 固定兩個維度,只考慮一個維度的資料。
·T: only consider time dim,單一物件單一metric即單個時間序列):spikes & dips、趨勢變化、範圍變化。
·M: only consider metric,找出不符合metric之間相互關係的資料。
·O: only consider object,找出與眾不同的物件。
2. 固定一個維度,只考慮兩個維度的資料。
·MT:固定物件,考慮多個時間序列(每個對應一個metric),並找出其相互變化方式不同的作為異常。
·MO:不考慮時間特性,考慮多個物件且每個物件都可以用多個metric表示,如何從中找出不同的物件。
·TO:多個物件單一metric,找出變化趨勢不同的物件。
在異常檢測中,面向問題有如下計算方法:
1. 內建函式
·高壓縮比快取直接作為視窗快取
·對於滿足資料區域性性的問題,直接在高壓縮比快取上執行
·結果直接寫回
·定時排程 vs 資料觸發
2. 外接計算
·定時查詢 vs 流式讀取
·使用同樣的查詢語言執行查詢或定義資料來源
·資料庫內建時間視窗
·資料流的觸發機制
針對時序資料,又可以將計算分為預計算和後計算。

預計算:事先將結果計算完並存儲。這是流計算中常用的方式。其特點如下:
·資料儲存量低
·查詢效能高
·需要手工編寫計算過程
·新的計算無法立即檢視結果
·靈活性差
·不儲存原始資料
後計算:先存資料,需要時進行計算。這是資料庫中常用的方式。其特點如下:
·資料儲存量大
·查詢/聚合效能瓶頸
·任何查詢都可以隨時獲得結果
·使用DSL進行查詢
·靈活性好
·儲存原始資料
四,時序資料庫的計算引擎
基於兩種計算的特點,在時序資料處理中,我們使用的是一種混合架構。有資料進來時,有預聚合規則,如果符合規則就進行預聚合,把資料寫入資料庫中。在查詢時,如果符合預聚合規則,就可以很快得到結果。對於不滿足預聚合規則的資料,會將其從資料庫中讀出,進行後聚合。中間的聚合引擎是一種類似流式計算的架構,資料庫或者資料來源都可以作為資料來源。資料來源的來源對於引擎是不可見的,它的功能是接收資料,計算併產生結果。因此,預計算和後計算都可以利用這一種邏輯進行,並放在同一個執行環境中。
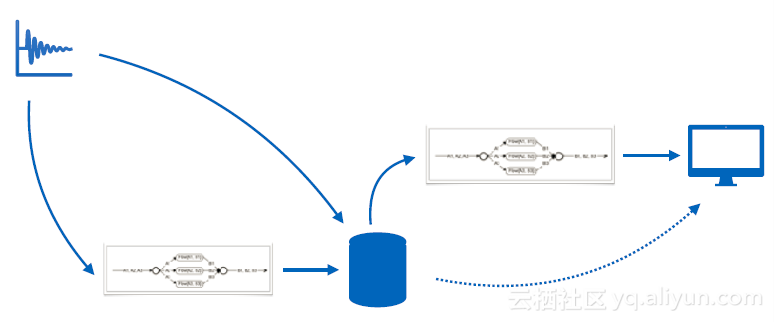
在邏輯上,上圖是可行的。但實際上,如果要用這種方式進行流計算,由於資料來源可能出現亂序等問題,就必須要利用視窗函式,將資料放入時間視窗中整理好,但這種快取的效率其實並不高,實際情況下,是按照下圖這種邏輯進行的。資料會被寫進資料庫,由於資料庫有高壓縮比快取,是專門針對時序資料的。當一個時間視窗結束時,利用持續查詢來進行預計算。它會將高壓縮比快取中的資料拿一部分出來做預聚合再寫回資料庫中。這樣,這個快取機制就替代了原來的時間視窗,節省了很多記憶體,降低了很多計算開銷。
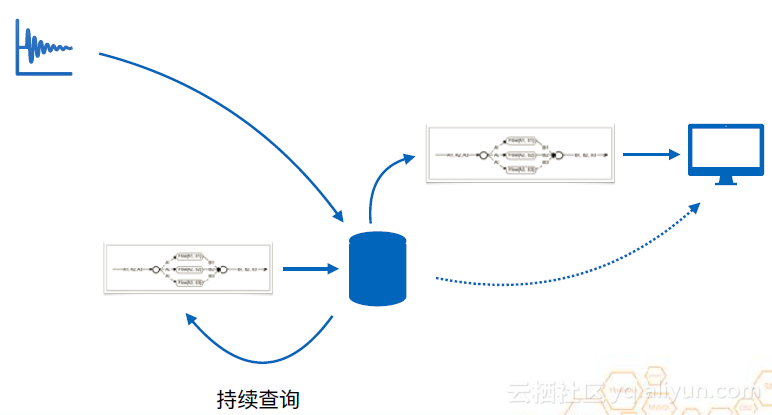
使用類似於流的架構的好處是可以將其很快的接入異構計算的環境中。正如大家熟知的,流計算可以轉化為一個DAG。結合前面提到的降取樣和聚合的例子。以一個加法為例,可以把資料切成三片放入不同的工作節點上計算,計算完後再進行一次聚合輸出資料。工作節點既可能是CPU也可能是GPU。接入異構計算的環境中,可以加速資料的計算。
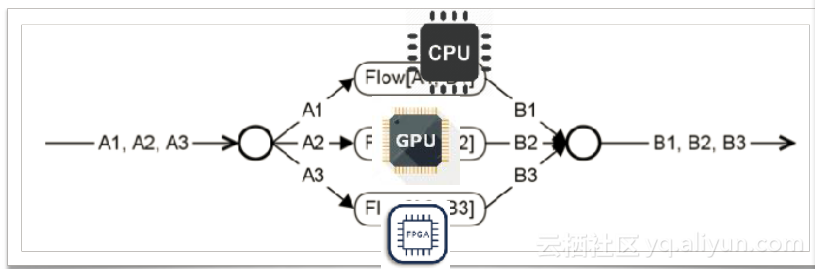
五,時序資料庫展望
下圖是對未來架構的展望。
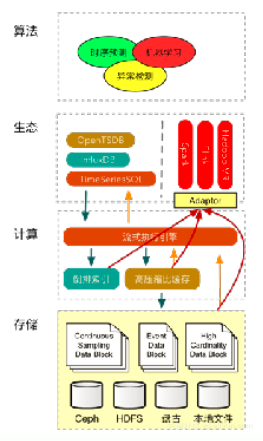
1. 儲存層
·類似lambda架構,基於一系列不可修改的檔案
·針對不同的場景提供不同的儲存格式
2. 計算層
·流式架構,基於記憶體的異構計算,自動填充熱資料
·資料分片,支援高QPS讀取
3. 索引
·全域性的索引 vs 檔案區域性索引
4. 大資料
·可以直接在大量的檔案上跑MR,也可以通過高壓縮比快取以流的方式訂閱資料
未來,這個資料庫將會演化成時序資料平臺。它可以相容SQL生態,一系列大資料平臺,以及融合邊緣計算。在部署時可以在雲和邊緣部署一整套的管理架構,同時把用SQL描述的規則下放到雲板和邊緣板上,形成一整套資料處理方案。

相關推薦
#python#DataFrame 時間序列資料處理常用操作
有X個機組以15分鐘為步長的長系列(年月日時分)出力的資料,想處理成每個機組的,以“年月日”為索引值,每行顯示1天96個點出力的形式。先利用df.head()把dataframe按96切割成Y份,然後將Y份的第x列(x號機組的出力)提取出來,放到list裡,再利用concat
[譯]在 Keras 中使用一維卷積神經網路處理時間序列資料
原文地址:Introduction to 1D Convolutional Neural Networks in Keras for Time Sequences 原文作者:Nils Ackermann 譯文出自:掘金翻譯計劃 本文永久連結:github.com/xitu/go
學習python處理時間序列資料
datetime模組 字串和datetime轉換 pandas資料處理操作 時間週期計算 時間資料重取樣 升取樣 滑動視窗 時序模型:ARIMA AR(Autor
python處理時間序列資料 丟包填充
轉載至:https://blog.csdn.net/u010197551/article/details/79618040 5. 資料缺漏的插補 資料格式是以一分鐘為步長的長系列負荷,從資料庫讀入excel後存在缺漏情況,即並不是每一天的資料都有1440個點。需要把資料處理成
時間序列資料的處理
摘要: 隨著雲端計算和IoT的發展,時間序列資料的資料量急劇膨脹,高效的分析時間序列資料,使之產生業務價值成為一個熱門話題。阿里巴巴資料庫事業部的HiTSDB團隊為您分享時間序列資料的計算分析的一般方法以及優化手段。演講嘉賓簡介:鍾宇(悠你) 阿里巴巴 資料庫高階專家,時間序
【tensorflow2.0】處理時間序列資料
國內的新冠肺炎疫情從發現至今已經持續3個多月了,這場起源於吃野味的災難給大家的生活造成了諸多方面的影響。 有的同學是收入上的,有的同學是感情上的,有的同學是心理上的,還有的同學是體重上的。 那麼國內的新冠肺炎疫情何時結束呢?什麼時候我們才可以重獲自由呢? 本篇文章將利用TensorFlow2.0建立時間序列R
SpringBoot的json序列化及時間序列化處理
urn G1 public nwr port 方法 als 前後臺 nconf 使用場景:前臺的多種時間格式存入後臺,後臺返回同時的時間格式到前臺。 1 在config目錄下配置jscksonConfig.java package com.test.domi.config
NLP之TFTS讀入資料:TF之TFTS讀入時間序列資料的幾種方法
NLP之TFTS讀入資料:TF之TFTS讀入時間序列資料的幾種方法 T1、從Numpy 陣列中讀入時間序列資料 1、設計思路 2、輸出結果 {'times': array([ 0, 1, 2, 3, 4, 5, 6, 7, 8,
表儲存時間序列資料儲存體系結構
隨著近年來物聯網(IoT)的快速發展,時間序列資料出現了爆炸式增長。根據過去兩年DB-Engines資料庫型別的增長趨勢,時間序列資料庫的增長是巨大的。這些大型開源時間序列資料庫的實現是不同的,並且它們都不是完美的。但是,這些資料庫的優點可以結合起來實現完美的時間序列資料庫。 阿里雲表儲存是由阿里雲開發
Keras之MLPR:利用MLPR演算法(3to1【視窗法】+【Input(3)→(12+8)(relu)→O(mse)】)實現根據歷史航空旅客數量資料集(時間序列資料)預測下月乘客數量問題
Keras之MLPR:利用MLPR演算法(3to1【視窗法】+【Input(3)→(12+8)(relu)→O(mse)】)實現根據歷史航空旅客數量資料集(時間序列資料)預測下月乘客數量問題 輸出結果 設計思路
Keras之MLPR:利用MLPR演算法(1to1+【Input(1)→8(relu)→O(mse)】)實現根據歷史航空旅客數量資料集(時間序列資料)預測下月乘客數量問題
Keras之MLPR:利用MLPR演算法(1to1+【Input(1)→8(relu)→O(mse)】)實現根據歷史航空旅客數量資料集(時間序列資料)預測下月乘客數量問題 輸出結果 單位為:千人 設計思路 實現程式碼
【統計學】【2017.05】時間序列資料預測與分析
本文為布拉格捷克理工大學(作者:Oleg Ostashchuk)的碩士論文,共78頁。 本文討論了時間序列分析和預測的問題。論文的目的是研究現有的時間序列預測方法,包括必要的資料預處理步驟。本文選取了ARIMA、人工神經網路和雙指數平滑三種有前景的預測方法。本文的主要工作是對所提供的資
時間序列資料預測
ts(data = NA, start = 1, end = numeric(), frequency = 1, deltat = 1, ts.eps = getOption(“ts.eps”), class = , names = ) start:第一次觀測的時間。單個數字或兩個整數的向量
PIE SDK開啟長時間序列資料
1. 功能簡介 時間序列資料(time series data)是在不同時間上收集到的資料,這類資料是按時間順序收集到的,用於所描述現象隨時間變化的情況。當前隨著遙感衛星技術日新月異的發展,遙感衛星的重訪週期越來越短,外加歷史資料的積累,產生了海量的遙
橫截面資料、時間序列資料和麵板資料
橫截面資料是在同一時間,不同統計單位相同統計指標組成的資料列。橫截面資料不要求統計物件及其範圍相同,但要求統計的時間相同。也就是說必須是同一時間截面上的資料。例如,為了研究某一行業各個企業的產出與投入的關係,我們需要關於同一時間截面上各個企業的產出Q和勞動L、資本投入K的橫截面資料。這些資料的統計物
深度學習應用於時間序列資料的異常檢測
本文關鍵點 神經網路是一種模仿生物神經元的機器學習模型,資料從輸入層進入並流經啟用閾值的多個節點。遞迴性神經網路一種能夠對之前輸入資料進行內部儲存記憶的神經網路,所以他們能夠學習到資料流中的時間依賴結構。 如今機器學習已經被應用到很多的產品中去了,例如,siri、Goog
時間序列資料探勘綜述
一、引言 時間序列是指按時間順序排列的一組資料,是一類重要的複雜資料物件。作為資料庫中的一種資料形式,它廣泛存在於各種大型的商業、醫學、工程和社會科學等資料庫中,如股票價格、各種匯率、銷售數量、產品的生產能力、天氣資料等。大量時間序列資料真實地記錄了系統在各個時刻的所有重要資訊,若能改進某種高效的資料處
CNTK API文件翻譯(10)——使用LSTM預測時間序列資料
本篇教程展示如何用CNTK構建LSTM來進行時間序列資料的數值預測。 目標 我們使用一個連續函式的模擬資料集(本例使用正弦曲線)。對於函式y=sin(t),我們使用符合這個函式的N個值來預測之後的M個值。 在本教程中我們將使用基於LSTM的模型。L
用ggplot2為時間序列資料繪圖
在R中用ggplot()函式為時間序列型別的資料繪圖時,發現ggplot()無法識別ts型別的資料,這時候就可以先將時間序列型別拆成資料框型別然後在繪圖。具體方法如下: 1. 示例資料集 library(TSA) library(ggplot2)
Python繪製時間序列資料的時序圖、自相關圖和偏自相關圖
時序圖、自相關圖和偏相關圖是判斷時間序列資料是否平穩的重要依據。 本文涉及的擴充套件庫numpy、pandas、statsmodels一般可以使用pip進行線上安裝,如果安裝失敗,可以到http://www.lfd.uci.edu/~gohlke/pythonlibs/下載相應的whl檔案進行離線安裝。 另